
 起点课堂会员权益
起点课堂会员权益产品经理的知识图谱入门实操
知识图谱概述知识图谱的构建,用户可以使用自然语言来查询相关的信息,更加符合人的思维方式,从而更快速的帮助用户找到所需的信息。目前除了搜索引擎之外,知识图谱还广泛应用于社交、金融、教育、医疗等多个领域。接下来,我们分别详细介绍一下知识图谱的技术要点。

1. 知识图谱概述
1.1 什么是知识图谱
人工智能的终极目标,是让计算机可以使用人类思考问题的方式来解决问题,达到智能化从而解放人类的脑力,让人们的生活更加便捷,更加有效率。虽然自90年代以来互联网技术已经蓬勃发展了30年,但是计算机的能力还远远达不到人们期望的智能化水平,根本的原因在于目前计算机对于数据的存储和使用方式,与人脑思考问题的方式还有着本质上的区别。
目前以网页为主要载体的互联网信息,都是以字符串、数组等半结构化的数据类型组合而成的超文本链接。对于计算机而言,任何一个以文字来表示的信息都是0和1组成的二进制字符串,其中的差异只是文本存储空间所占大小的不同,文字所表示的语义信息并不能被计算机所理解。
而人却可以从不同的文字中解读不同的信息,这是因为人可以理解不同的文字所指代的不同含义,并且可以根据一些规则,对文字之间的关系进行推理。
举个简单的例子来说,当看到“他儿子今年出生了”这段文字时,我们可以推断出文中的“他”应该有个妻子,也就是“儿子”的母亲,并且儿子的年龄是现在是0岁。虽然文字中并没有明确的表达这些信息,但可以根据常识推断出这些信息,这些常识或者规则我们称之为“知识”。
那么,有没有可能让计算机可以理解这些文字所代表的真实含义,做到像人一样通过知识对这些信息进行理解和推理呢?
万维网之父蒂姆·伯纳斯·李(Tim Berners-Lee)曾说过:“我有两个梦想:第一个是连接世界上的每个人,现在这个梦想已经通过互联网实现了,第二个梦想是连接世界上的每个事物,这个光荣的使命交给了语义网。”
时至今日,这项技术已经经历了语义网络、本体论、语义网、链接数据、知识图谱几个阶段。
在2012年,谷歌首次将知识图谱技术应用在搜索引擎中,以提升搜索的能力。在过去没有使用知识图谱技术时,用户搜索某些信息,搜索引擎会将搜索的关键词与网站的文本做匹配,根据匹配度来展示对应的网页信息,所以如果用户想知道一个问题的答案,但却不知道答案的关键词应该搜什么的时候,往往会搜不到自己想要的结果。
但引入知识图谱之后,引擎会根据知识图谱来展示相关信息,用户可以使用自然语言来进行搜索,搜索引擎分析用户的问题之后根据知识图谱来查询对应的结果,自此正式开始了知识图谱在产品中的应用。
现在各大搜索引擎也都会根据知识图谱来展示搜索的内容,例如在百度中搜索“中国的首都”,搜索的结果会直接显示“北京市”相关的百度百科信息,如图所示。
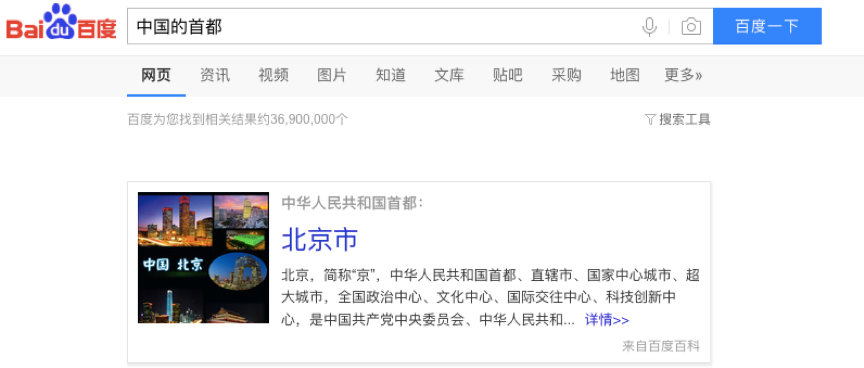
通过知识图谱的构建,用户可以使用自然语言来查询相关的信息,更加符合人的思维方式,从而更快速的帮助用户找到所需的信息。目前除了搜索引擎之外,知识图谱还广泛应用于社交、金融、教育、医疗等多个领域。接下来,我们分别详细介绍一下知识图谱的技术要点。
1.2 对象、实例与RDF知识表示
首先,我们需要了解一下如何描述一个“知识”。在之前的章节,我们提到过数据分为三种类型,分别是名义数据、登记数据和连续数据。但是日常生活中不是所有的事物都可以用这三个数据类型来被描述,比如一个人、一张图片、一段视频,这些东西应该怎么描述呢?这里要用到面向对象的概念。
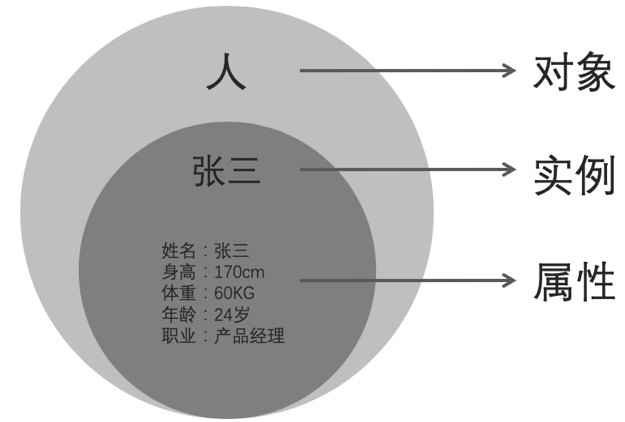
什么是对象呢?我们刚说的一个人、一张照片、一段视频,都可以称之为一个对象,对象中包含了各种各样的属性,例如人有名字,年龄,身高这些属性,每个人都会有这些属性,但属性的值可能不一样,当我们把属性的值具象化之后,就可以定义到一个具体的人,例如张三,那么张三就称之为人这个对象的实例。
如图所示:
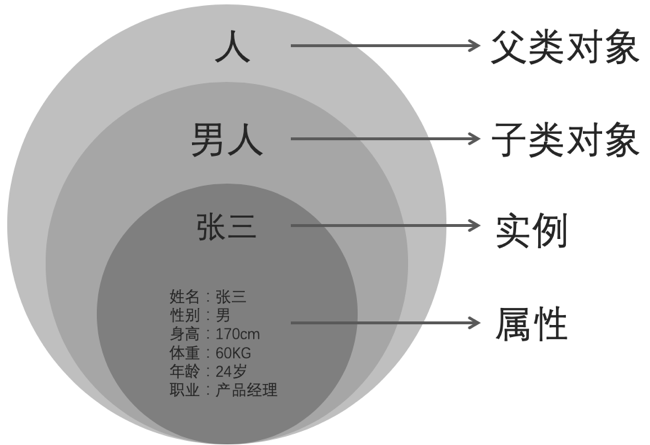
对于对象而言,如果互相之间存在包含关系,则称之为父类对象和子类对象。例如把人作为一个对象,这个对象其实可以进一步细分为男人和女人,那么人就是男人的父类对象,男人是人的子类对象,张三则是男人这个子类对象的实例。如图所示:
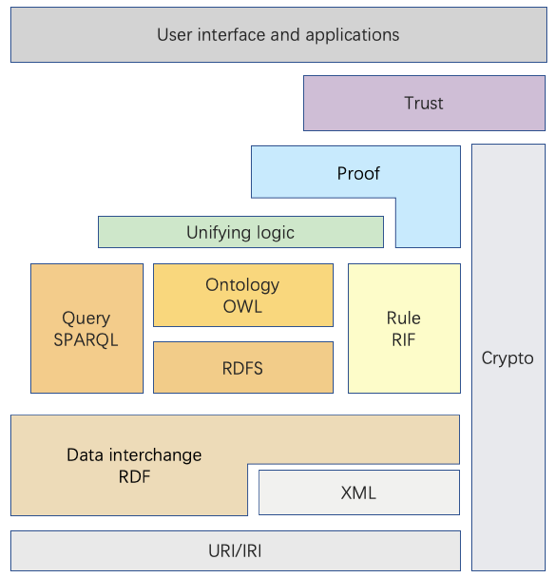
了解了对象、类与实例之间的关系之后,我们就可以进入到知识图谱的正题——知识表示了。根据Web技术领域权威标准机构W3C指定的知识图谱描述标准,所有的知识应该用资源描述框架(Resource Description Framework,RDF)进行描述,并对其他与知识图谱相关的技术进行了定义,如图所示:
RDF中的R表示页面、图片、视频等任何具有统一资源标识符(Uniform Resource Identifier,URI)的资源,D表示属性,即特征和资源之间的关系,F表示模型以及描述的语法。简单来说,每一条RDF知识表述都可以以一个主谓宾的语句形式出现,例如{中国,首都是,北京},其中“中国”“北京”是两个实体,而“首都是”则表示两个实体之间的关系。
在RDF中总是两个实体,以及两个实体之间的关系三者构成,所以RDF又简称三元组,如图所示:

需要注意的是,每个RDF的实体都要有一个唯一的URI进行标识,但RDF也是允许空白节点存在的,同时实体资源也可以允许匿名资源的存在,即不标识具体的资源,只标识资源的类型,作为连接别的实体的桥梁。
虽然RDF是知识图谱的基石,但其本身对于事物的描述能力非常有限,根据RDF的定义我们可以发现,组成RDF的三元组中,两个实体都具有唯一标识,因此缺乏泛化抽象的能力,无法对同一个类别的事物进行定义和描述。举个例子来说,我们可以通过RDF来描述中国的首都是北京,但如果希望归纳出所有国家与首都之间的关系以及他们的属性,仅仅用一条实例的RDF是无法实现的。
知识的泛化能力对于知识图谱实现智能化而言非常重要,只有具备归纳出抽象知识的能力,才能覆盖更广泛的知识。那么要如何做才能解决RDF的这个问题呢?
我们在之前讲解了父类、子类与实例之间的关系,对于RDF而言也可以通过类似的结构来对知识进行泛化的描述,这就是我们接下来要讲到的本体语言——RDFS和OWL。
1.3 RDFS与OWL本体语言
RDFS是最基础的本体语言,其中的S表示Schema,可以表示某些实例的抽象属性。具体而言,包括的核心词汇如表所示:
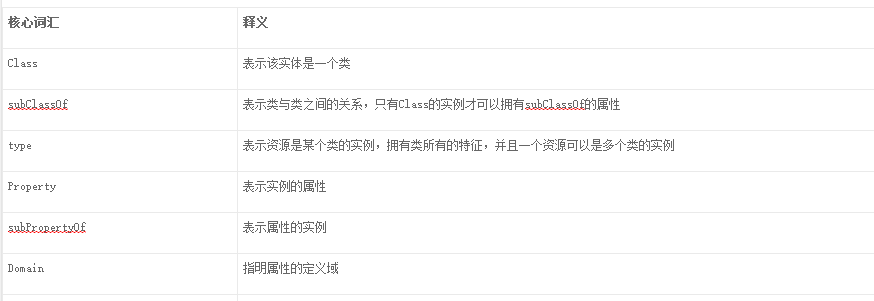
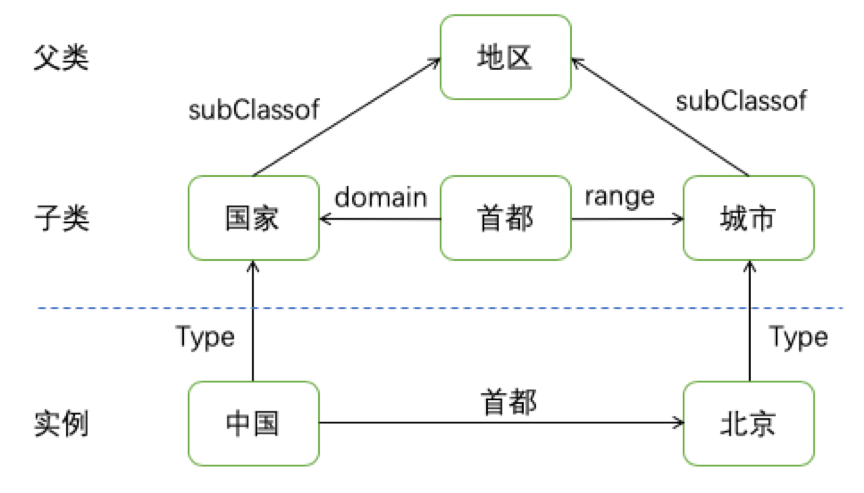
举例来说,我们可以通过<rdfs:subClassOf>来表示父类与子类之间从属的关系。如图所示,中国是国家这个类的实例,北京是城市这个类的实例,而城市和国家又都是地区这个父类的子类,通过RDFS可以清晰的划分出类与实例之间的层次关系,并通过类之间的关系连接来推理出更多的知识。
在本例中我们可以推断一个国家的首都是某一个城市这样的知识,这样就可以泛化的涵盖所有国家与首都城市之间的关系连接,这种对于知识的泛化在语音智能问答产品中是非常重要的技术,我们会在后续的文章中对智能问答产品做详细讲解。
虽然通过RDFS可以表示一些简单的语义,但在更复杂的场景下,RDFS语义表达能力显得太弱,在表达知识的能力上依然存在缺陷,缺少诸多常用的特征。
例如对于局部值域的属性定义:RDFS中通过rdfs:range定义了属性的值域,该值域是全局性的,但无法表示该属性应用于某些具体的类时具有的特殊值域限制;无法表示多个类、实例和属性之间是等价还是不等价;无法表示多个类之间是相交关系还是互斥关系;无法对某些属性值的取值范围进行约束;无法表示某些属性具有传递性、函数性等特性等。
因为RDFS无法很好的满足知识的表示需求,W3C在2002年发布了OWL本体语言(OWL,Web Ontology Language)作为RDFS的扩展,并将其作为语义网中表示本体的推荐语言,目前OWL已经迭代至OWL2版本,最初的OWL又称之为OWL1。
相较于RDFS,OWL扩充了非常多的描述属性,弥补了RDFS的不足之处,例如增加了等价性声明、传递关系声明、对称性、数值约束等。以下为主要的核心描述词汇:
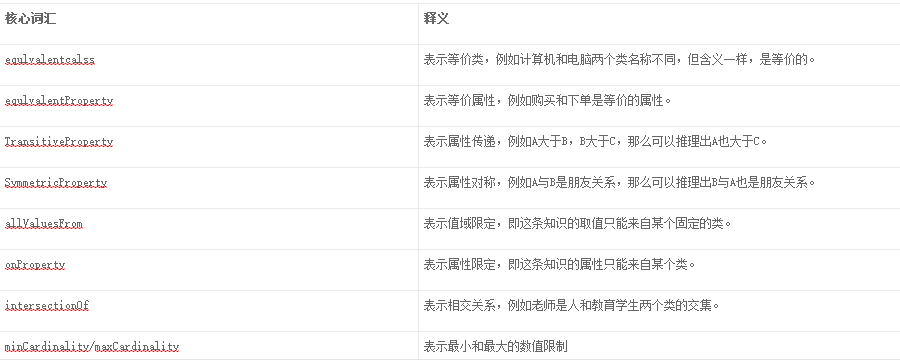
除了以上列举的几种之外,OWL还有非常多的属性描述词汇,在构建知识图谱时需要了解这些属性词汇,并具备相关领域的专业知识才能正确的描述出知识的特征,如果需要了解更多的OWL相关描述,可以通过W3C的官方文档查看。
2. 知识图谱构建流程
2.1 知识建模
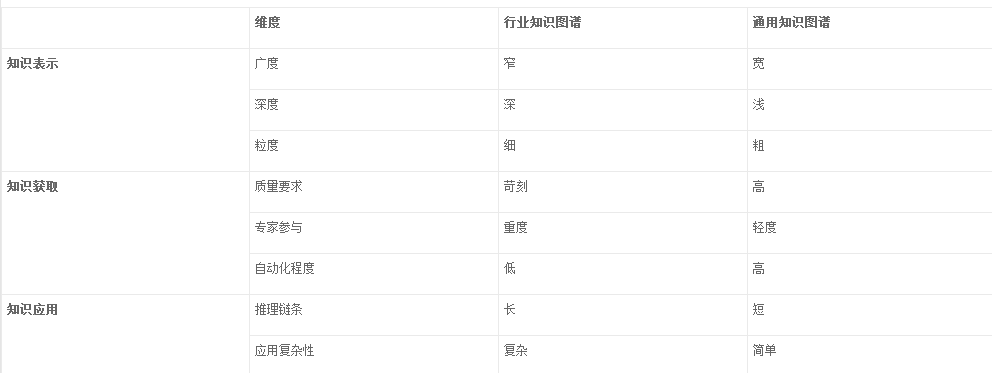
知识图谱从覆盖的知识面来分,可以分为通用知识图谱(General-purpose Knowledge Graph,GKG)和行业知识图谱(Domain-specific Knowledge Graph,DKG)两种类型,行业知识图谱因使用的场景是面相特定的领域,故又称领域知识图谱。虽然他们都是知识图谱,但在知识表示、知识获取和知识应用层面来看,两者又有很大的区别,如表所示。
第一是从知识广度来看,通用知识图谱覆盖的知识面较宽,主要涵盖的是日常生活中的常识性问题,例如Google搜索引擎的知识图谱就是面相全领域的通用知识图谱,在2012年发布时就包含了5亿多个的实体,10亿多条的关系,中文的典型通用知识图谱有复旦大学知识工场实验室研发并维护的大规模通用领域中文百科知识图谱(CN-Dbpedia),该项目包含900多万的实体信息以及6700多万的三元组关系,已在问答机器人、智能玩具、智慧医疗、智慧软件等领域产生了3.5亿次API调用量。
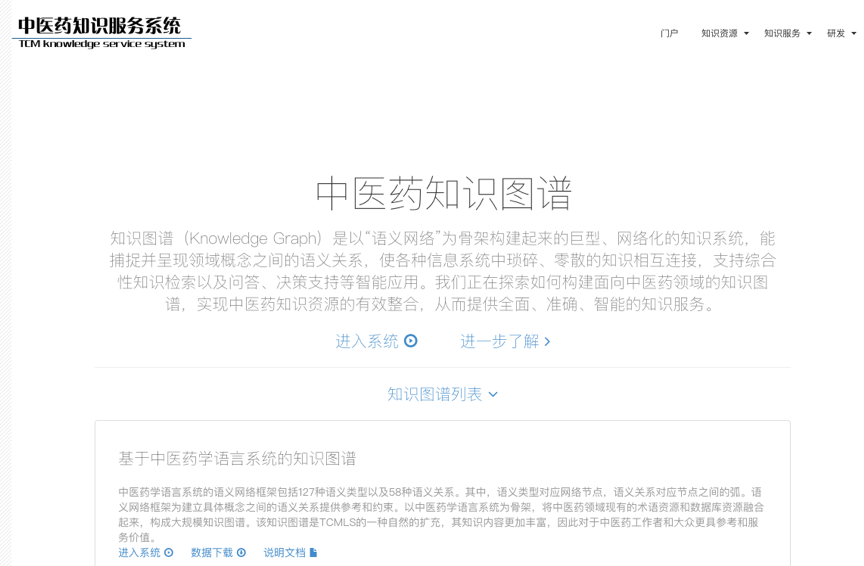
行业知识图谱的广度通常较窄,一般只涵盖某一个专业领域的相关知识,目前除搜索引擎和语音助手使用的知识图谱外,大多数的知识图谱项目都是行业知识图谱。典型的应用例如美国帕兰提尔(Palantir)公司的政务领域知识图谱, GeoNames的全球地理知识图谱(该数据库包含了近200种语言的1100万个地名和200万种别名),以及国内包含了中医养生、中医美容等内容的中医药知识服务系统(TCM knowledge service system)等,如图所示。
第二是从知识深度来看,通用知识图谱的层级体系一般较浅,对于知识的泛化而言通常没有太多的归纳,这与通用知识图谱获取知识的方式有关,也跟通用知识图谱的使用场景有关,对于通用知识图谱而言多数的使用场景都是基于某个具体的实体。而行业知识图谱的层级体系一般较深,例如在电商领域的商品分类中,关于服装的分类就不仅仅只是上衣和下装这么简单,各种风格、时尚元素、款式、材质都有可能构成不同的类。
第三是从知识颗粒度来看,通用知识图谱的颗粒度一般比较粗,而行业知识图谱一般颗粒度较细。在通用知识图谱中,组成知识的基本单元一般是一个完整的文档或者资源,例如一篇文章,一首歌,一个视频等。但是对于行业知识图谱而言,需要的颗粒度根据业务的不同要划分为更细的颗粒度,以教育领域的知识图谱为例,一个数学公式、一篇语文课文中的一句话、一个英文单词都有可能构成独立的知识实体,才能满足学生对于个性化学习的需求。
正因为通用知识图谱和行业知识图谱的应用场景有很大的不同,让这两种知识图谱的知识获取方式有着显著的区别,对于知识获取方式而言可以根据人工参与度的不同划分为自顶向下和自底向上两种方法。
具体来说,行业知识图谱大多采用自顶向下的知识获取方法,这种方法是通过领域专家手工将知识进行整理和归纳,编辑为知识图谱的数据结构。
该方法的优点在于可以满足产品对于知识专业性的及权威性的要求,例如医疗领域的知识图谱对于知识的专业性就有着严格的要求,必须由具备相关能力的专家来进行编辑。同时,手工编辑也可以将知识图谱设计的概念和范围限定在可控的范围内。
例如“古龙”这个实体如果是在文学知识图谱上,代表的是一个作家,但如果放在美妆知识图谱中,代表的则是一款香水,如果不对知识图谱的应用范围进行限定则很有可能出现歧义。
专家参与编辑让行业知识图谱具有相对较高的准确性,但同时也带来了很多的弊端,首先是高昂的人力成本,通常编辑一个知识图谱需要成立一个专家团队,团队中的成员需要同时具备领域知识以及计算机知识,人力市场上能满足条件的人非常稀少,人工成本居高不下。
根据相关资料,Google编辑一条RDF三元组的人工成本平均需要0.8美金。如何能做到项目兼顾成本与效果是每个做知识图谱的产品经理要思考的问题。
另外一个不足之处是行业知识图谱可能有多个数据编辑者或数据来源,导致数据的格式不统一,这种数据术语称之为多源异构数据,如何制订相关的规则,将不同格式的数据转化为统一的格式也是产品经理在定义数据处理规则时需要考虑的问题。
通用知识图谱多采用自底向上的方法获取知识,这种方法是基于行业现有的标准数据库进行转换,或从现有的高质量数据源中提取知识本体以及本体之间的关系,主要应用于搜索、推荐、问答等业务场景。
因其强调知识的广度,数据主要来自于互联网上的公开信息,所以很难生成完整的全局性的本体层进行统一的管理。但因为知识获取的自动化程度较高,所以对于一些新的概念和新的关系可以很好的涵盖。
从知识的应用层面来看,通用知识图谱的知识相对稀疏,所以知识推理链条较短,通常来讲推理操作都是基于上下文的一到两步的推理,如果超出这个很容易出现语义漂移(semantic drift)现象,让推理的结果答非所问,人工智能秒变人工智障。而行业知识图谱的推理链条可以较长,更适合需要进行复杂推理和计算的场景。
2.2 结构化与半结构化知识获取
从不同的来源、不同结构的数据中进行知识提取存入到知识图谱,这一过程我们称之为知识获取。从知识的来源大致可以分为三类,分别是结构化数据转换、半结构化数据提取和非结构化文本数据提取。
(1)结构化数据转换
语义网的目标是建议以RDF为标准数据模型的数据网,但当前大多数Web数据源是由关系型数据库(RDB)驱动的,因此如何将RDB数据集向RDF数据集进行映射一直是语义网领域的研究热点。
结构化数据转换就是指将关系型数据库数据,转换为RDF结构知识图谱的知识获取方式。W3C在2012年专门为此制定了一个标准R2RML(Relational database to RDF Mapping Language)。这是一种可以用于表示从关系型数据库到RDF数据集的自定义映射的语言,通过这种映射关系,我们可以将关系型数据库中的数据转换为自定义的知识图谱结构。
虽然这种转换并没有直接生成真正的RDF数据集,仅仅只是在数据库和知识图谱的本体中间做了一重映射关系,但是通过表示映射关系的mapping文件,系统可以将对RDF三元组的查询等操作翻译成对应的SQL语句,快速将企业过去积累的数据转化为知识图谱,这种转化后的数据本身以及数据之间的关系都符合业务的需要,可以让产品快速落地进行迭代。
(2)半结构化数据
半结构化的数据是指没有按照RDF格式,但是却有着一定规律的网络数据,通过网络爬虫爬取完整的网页信息之后,再通过包装器(wrapper)将其转换成知识图谱数据。
半结构化的数据来源主要有两个,一是维基百科、百度百科这类百科网站的信息表格(infobox),另外则是来源于各类网页中的文本、列表数据,如图所示。
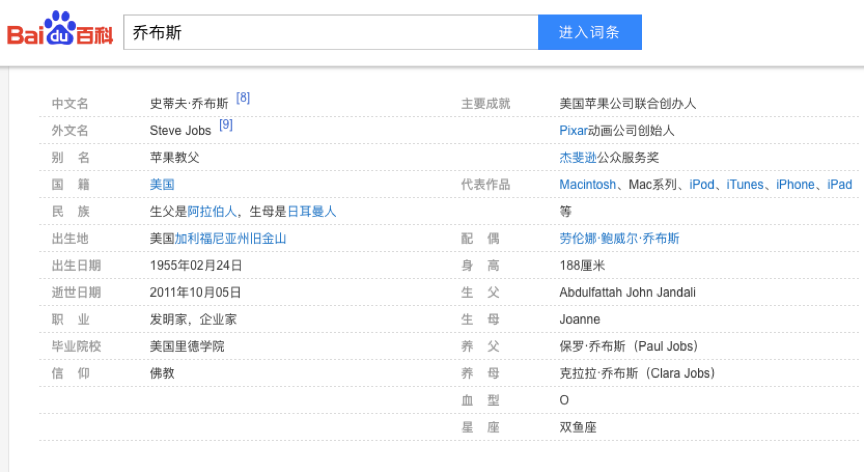
在百度百科中搜索乔布斯的相关词条会发现这样一个表格,表格中详细记录了乔布斯与其他实体之间的关系,与搜索的词条之间形成了一个完整的 RDF三元组,例如乔布斯的国籍是美国。通过对百科网站的infobox进行信息抽取,可以快速获得高质量的知识实体。但是,通过infobox只能抽取到实例层数据,对于类层面的关系还需要通过别的方式来进行构建,例如自顶向下由领域专家构建。
对于其他的网页信息而言,抽取数据时需要过滤掉网页中含有的广告、外链等冗余信息,只保留有实际需要的知识信息,这需要根据网页的HTML代码标签构建专用的网页包装器。
如果给每一个网页都开发一个专门的包装器,不仅需要投入大量的开发人力,而且通用性会比较差,为了解决这个问题,可以先对需要爬取的网页进行聚类,针对聚类来设计包装器会大幅提高知识获取的速度。
通过爬虫和包装器抽取互联网的公开信息会面临一个问题,就是随着网站的更新迭代,网页的信息结构可能会发生改变,既是一个微小的变动也可能会导致原本构建的包装器失效无法再继续工作。对于这个问题最简单的办法是重新创建一个新的包装器以适应网站的升级,但是如果爬取的网站数量非常多,这种做法不但效率很低而且会给开发人员带来很重的工作负担。
为了能维持包装器的正常工作,我们可以对需要采集的数据进行数据标注,用机器学习的方法对数据的特征进行学习并构建出模型,进而在整个网页站点下使用模型自动生成新的包装器进行数据的抽取。
2.3 非结构化知识获取
与整个互联网的数据相比,百科类网站的知识库只是沧海一粟,除了网页中半结构化的数据之外,还存在着海量的无结构网页文本数据。如何将这些文本数据中的知识抽取出来是很多计算机科学家的研究方向。
例如华盛顿大学Oren Etzioni教授主导的开放信息抽取(open information extraction,OpenIE)项目,该项目从1亿个网页中抽取了5亿条数据,如图所示。还有卡耐基梅隆大学Tom Mitchell教授主导的永不停止的语言学习(never ending language learning,NELL)项目,这个项目从公开网页中抽取了5千万条数据。
(1)实体抽取
从无结构的文本中抽取知识,首先需要识别文本中的实体,这个过程称之为做命名实体识别(Named Entity Recognition,NER),命名实体识别属于自然语言处理中的一项基础任务,同时也是关系抽取、事件抽取、机器翻译、问答系统等多个NLP任务的基础工作,其目标是从文本中抽取出具有特定意义的实体,一般包括实体类、实践类、数字类三个大的类别,以及人名、地名、组织机构、时间、日期、货币、百分比。
除此之外,也可以根据项目的需要指定特定领域内的实体,例如书名、疾病名、事件名等,只要是业务目标需要的实体,都可以做为实体抽取对象。
在中文文本数据中进行实体抽取相比英文文本数据而言难度更大,首先是因为英语中的实体命名有非常明显的形式标志,每个单词之间用空格隔开,并且实体的每个词第一个字母是大写,所以识别的难度相对容易。而中文没有类似英文文本中空格之类的边界标识符,所以要做命名实体第一步是要确定词与词之间的边界,将词与词之间间隔开来,这个过程称之为分词。
第二点是命名实体本身的构成比较复杂,不断会有新的实体名称出现,例如新的人名,地名,物品名等,而且命名实体的长度也没有限制,不同的实体可能会有不同的结构,例如少数民族人名或者翻译的外国人名,难以建立大而全的实体数据库,分词技术对于这部分的实体识别相对来说难度会高很多。
第三点是在不同的文本资料中,命名实体之间可能会出现嵌套的情况,互相交叉以及相互包含,需要根据上下文才能推断出命名实体真实的意思。例如“北京大学的学生参加了运动会”,可以划分为“北京大学/的/学生/参加/了/运动/会/”,也可以划分为“北京/大学/的/学生/参加/了/运动会”,不同的划分方法会造成实体识别的不同。
关于分词,我们会在后续的自然语言处理章节详细讲解。这里仅对命名实体的常用技术方法做一个概述。目前对于命名实识别的主要方法分为三种:基于规则和词典的方法、基于统计和机器学习的方法以及前两者混合使用的方法。
基于规则和词典的方法是由语言学家或业务专家手工构造规则模板,定义好需要抽取的命名实体,以字符串的匹配作为主要的手段,这是命名实体抽取最早使用的方法,提取的结果非常精准,但是这类系统大多依赖于知识库和词典,系统的泛化性不高,对于不同的系统需要重新编写规则,而且人力投入过大,建设的时间周期也较长,只适合于那些不会有太多新实体的领域知识图谱构建。
基于统计和机器学习的方法主要包括隐马尔可夫模型(HMM)、条件随机场(CRF)、长短期记忆网络(LSTM)、最大熵模型(MaxEnt)等方法。这类实体抽取的方法对于特征的选择要求较高,需要从文本中选择对该项任务有影响的各种特征,并将这些特征加入到特征向量中。
依据特定命名实体识别的特征,考虑选择能有效反映该类实体特性的特征集合。主要做法是通过对训练预料所包含的语言信息进行统计和分析,从训练预料中挖掘出特征。有关特征可以分为具体的单词特征、上下文特征、词典及词性特征、停用词特征、核心词特征以及语义特征等。
基于统计的方法对语料库依赖比较大,但可以用来建设和评估命名实体识别系统的大规模通用语料库又比较少,一般是使用维基百科或主流纸媒的标注作为基础训练语料,这类语料库虽然在权威性和正确性上有保障,但是在时效性上交叉,对于新词的识别能力较差。
实体识别技术经历了多次迭代,从早期的基于规则和字典的方法,到传统的机器学习方法,再到深度学习方法,以及近期的迁移学习和半监督学习方法。
目前,将神经网络与CRF模型结合的CNN/RNN-CRF是实体识别的主流模型,基于神经网络结构的实体识别方法,继承了深度学习方法的优点,无需大量人工特征,只需词向量和字向量就能达到主流水平,加入高质量的词典特征能够进一步提升效果,而在未来,迁移学习和半监督学习进行实体识别技术方向研究的重点。
(2)实体消歧
不论是英语还是汉语,构成文本的基本单位都是词,但是同一个词在不同的上下文中可能代表不同的含义,例如英语的“play”就有玩、扮演、播放、比赛等含义,而汉语的“打”字除了用作介词和量词之外,用作动词时就有25个不同的意思。实体消歧就是明确多义词在文中具体指代意思的技术,通过实体消歧,就可以根据当前的语境,准确建立实体链接。
实体消歧可以看做是基于上下文的分类问题,同其他自然语言处理的任务一样,早起的实体消歧也是采用基于规则和词典的方法。但这种方法的局限性太大,后续逐渐被机器学习的方法取代。我们知道机器学习分为有监督学习和无监督学习,应用在实体消歧上也分为有监督的实体消歧方法和无监督的实体消歧方法。
基于有监督的学习实质上是通过建立分类器,通过划分多义词的上下文类别的方法来区分多义词的词义,常见的方法有基于互信息的消歧方法,基于贝叶斯分类器的消歧方法以及基于最大熵的消歧方法。
举例来说,“苹果”一词有时指水果,有时指科技公司,但如果与“吃”组成上下文,那么就可以根据贝叶斯概率计算出这个词应该是指水果而不是科技公司。
无监督的实体消歧主要采用聚类算法进行,先对每个实体不同的意思抽取其上下文的特征组成特征向量并进行聚类,当遇到需要进行实体消除的文本时,让文本与之前构建好的特征向量聚类之间的相似度计算来辨别实体的意思。
在一项测试实验中,采用KNN(k=1)方法进行实体消歧的相似度计算,最终取得了平均正确率83.13%的结果。这种方法本质上还是基于词袋模型(bag of words),并没有考虑上下文之间的联系,所以对于一些复杂的实体辨别上效果不佳。
不论是采用有监督的学习还是无监督的学习,实体消歧最终的结果都依赖于训练集数据的完整性和准确性,所以目前在这一领域还未形成非常完善的解决方案,如何能够提高实体消歧的准确度有待专家学者的进一步研究。
(3)指代消解
在我们日常用语中大量的存在指代词,用来简化语言增加沟通的效率。例如有这样一段文本:“乔布斯在2007年发布了第一代iPhone,他表示这款手机领先其他手机五年”,在这句话中的“他”指代的是“乔布斯”,而“这款手机”指代的是“第一代iPhone”。
明确这些代词所指代的具体含义,将这些指代项关联到正确的实体对象中的技术过程就是指代消解,又称共指消解或参照消解。为了让知识抽取更加准确且不遗漏文本中的相关信息,必须对文本中的指代词进行指代消解。代消解不仅在知识抽取中起着重要的作用,而且在机器翻译,文本摘要等自然语言应用中最基础的一项技术。
根据北京大学的王厚峰教授的研究,指代一般分成两种回指(Anaphora,也成指示性指代)和共指(Coreference,也成同指)两种情况,回指是表示当前的指示代词与上文出现过的词存在语义关联性,而共指则是两个实体名字指向的真是世界中的同一实体,可以独立于上下文存在。例如“阿里巴巴集团首任董事长”和“马云”就是共指。
在汉语中的指代主要有一下三种典型的形式:
人称代词(Pronoun)
例如:【李明】怕高妈妈一个人待在家里寂寞,【他】便将家里的电视搬了过来。
指示代词(Demonstrative)
例如:【很多人都想创造一个美好的世界留给孩子】,【这】可以理解,但不完全正确。
有定描述(Definite Description)。
例如:【贸易制裁】仿佛成了美国政府在对华关系中惯用的大棒,然而,【这根大棒】果真如美国政府所希望的那样灵验吗?
指代消解的基本原理是先构造一个先行语候选集,然后再从候选集中做多选一的选择。代表的方法是1998年Hobbs提出的朴素Hobbs算法,这是一种基于句法分析树的搜索,通过遍历桔子的语法数来判断词语词之间是否可以互相替换,另一种指代消解方法是1983年Grose和Sidner提出的中心理论(Center Theory)。
这种方法认为文本中的描述是应该是连贯的,而通过语义的连贯性就可以找到文本中受关注的实体。但这种两种方法只适用于指代词与被指代词距离较近的回指情境,在实际应用上有一定的局限性。
目前指代消解最新的研究成果是2017年的端到端神经共指消解算法(End-to-end Neural Coreference Resolution),其基本原理是找到一个句子中所有出现过的命名实体和代词,并对他们所在的句子进行特征向量构造,计算词与词之间的特征向量,然后将代词和实体进行两两匹配计算共指匹配得分,以此来实现指代消解。
虽然指代消解问题已经经历了多年的研究和发展,但到目前为止,多数的研究成果还是在回指的研究上,对于共指还没有较好的全自动指代消解技术和方法,有待专家学者的进一步研究。
(4)关系抽取
识别实体与实体之间的语义关系是知识抽取中的一项核心任务,只有将实体之间通过关系联系起来构建成RDF三元组,才能形成知识网络。例如:王思聪是万达集团董事长王健林的独子,可以抽取出(王思聪,父子关系,王健林)、(万达集团、董事长、王健林)两组三元组实例。
最早的关系抽取任务可以追溯至1998年,当时是根据触发词作为关系识别的依据,然后填充关系模板槽抽取文本中特定的关系,例如“董事长”这个关键词构造为X的董事长是Y这样的模板,而随着机器学习算法和深度神经网络算法的发展越来越多的研究把关系抽取做成分类任务处理。
例如采用半监督学习的bootstrapping方法,按照“模板生成→实例抽取”的流程反复迭代,先给定一个种子实体的文本集合,例如<中国,北京>,接着从文本中抽取出包含种子实体的文本,例如<中国的首都是北京>,从而将<首都>这个关系抽取出来,然后用新发现的关系模板抽取更多新的三元组实例,匹配出所有X的首都是Y这样的格式。在这个过程中会发现X与Y除了首都这个关系实体之外,还有可能出现其他的关系,通过反复迭代不断抽取新的实例和模板直至无法再发现符合条件的关系位置。
这种方法的优点是构建成本较低,适合大规模的知识库构建,同时可以发现一些未经人工定义的隐含关系。但在实际使用中也面临着很多的问题,最常见的问题是在迭代的过程中容易出现噪声实例和模板,出现语义漂移的现象,结果的准确率较低。
另外一点是因为没有经过人工定义关系,导致关系语义没有归一化,同一种关系可能会有多种不同的表达方式,例如“首都是”也可以表达为“首都位于”、“设为首都”等,这些表述实际上是同一种关系,如何将这些自动发现的关系进行聚类规约是目前还未解决的问题。
关系抽取的好坏决定了知识图谱中知识的规模和质量,除了上述的基于模板匹配和半监督学习的方法之外,采用监督学习的Pipeline、LSTM-RNN的算法也是比较热门的方案。
(5)事件抽取
事件抽取可以视为关系抽取的强化版,是将文本中的事件以结构化的形式呈现出来。事件抽取的第一步是识别事件及其类型,其次要识别出事件所涉及的属性,最后需要确定每个元素在事件中与事件本身的关系。
以金融领域构建投融资的领域知识图谱为例,实践抽取的流程是先定义事件的触发词,即一个事件指称中最能代表事件发生的词,一般是动词或名词。然后定义事件的主体元素及其对应的属性。再根据属性找到对应的值。如图所示。事件的触发词是“融资”,事件的主体是“自如”,与事件相关的属性融资轮数、募集资金、领投方、跟投方和投前估值。

事件的主体和其他的属性之间其实可以构建出一对多的多元关系,如上图的自如与其他属性构成的多元,其本质是6个三元组,每个三元组的主语都是触发词这个事件,谓语分别是融资事件的属性,而宾语分别是抽取出来的值。
我们知道知识图谱分为通用知识图谱和领域知识图谱,事件抽取也可以分为适用于通用知识图谱的开放域事件抽取,以及适用于领域知识图谱的限定域事件抽取。上文例举的金融领域融资事件抽取就是一个限定域的事件抽取。
对于限定域的事件抽取,因为目标明确,所以通常都是预先定义好目标事件的类型以及每种类型包含的具体事件元素,并给出一定数量的人工标注数据作为训练集特征,后续采用模式匹配的方法或采用机器学习的方法进行事件抽取。
开放域的事件抽取因为在事件识别之前对于可能的事件类型和事件结构都是未知的,所以这类事件抽取主要是基于无监督的方法和分布假设理论。即如果候选事件触发词或者候选事件元素具有相似的语境,那么这些候选事件触发词倾向于触发相同类型的事件。
总之,对于无结构的文本数据进行知识抽取虽然已经经历了多年的发展,但目在各个子任务中依然存在很多未解决的问题有待专家学者的进一步研究。
小提示:在部分自然语言处理的研究报告中,实体抽取和实体消歧会合并称之为实体链接(Entity Linking),或称实体链指任务。
2.4 知识融合
我们在上文介绍了知识图谱的多种数据来源,但是这些数据源中抽取的知识来源广泛,知识的质量可能良莠不齐,也可能存在数据重合的部分,所以需要对知识进行融合,将不同数据源的知识统一规范,形成高质量的知识库。在不同的文献中,知识融合可能有不同的叫法,如本体对齐,本体匹配,实体对齐等,本文统一称之为知识融合。
知识融合主要包含有三种类型:
- 第一种是同一个实体有多种不同的表达方式,例如鲁迅原名是周树人,字豫才,对于这些不同的名称都需要规约到同一个实体下。另
- 一种是同一种表达在不同的语境下可能指代的是不同的实体,即一词多义,例如“苹果”有可能是指美国苹果公司,也有可能是指水果。
- 第三种是跨语言的知识融合,同一个实体在不同的语言或地区可能有不同的命名,例如腾讯公司的英文是Tencent。
在实际工作中,知识融合是数据预处理不可或缺的一部分,知识融合的好坏直接决定了知识库的质量,也决定了知识图谱项目的成功与否。
最基本的知识融合方法是知识卡片融合,即上文提到的百科类网站infobox信息,不同的百科网站对于同一个实体的描述可能有差异,所以可以将同一个实体在不同的百科类网站中进行搜索查询,将查询信息合并成为一个归一化之后的知识卡片,即可完成知识融合。
但是对于绝大多数的知识融合而言并不会像知识卡片的融合这样简单,我们知道不同的本体实例是由他们所拥有的属性决定的,如果两个不同的实体,属性都是相同或者近似的,那么我们就可以根据一定的规则将实体进行融合。所以要判断实体是否是同一个实体,是实体的属性是否相似来判断,属性的相似度决定了实体的相似度。
知识融合的流程通常分为四步,分别是数据预处理、数据预分组、属性相似度计算和实体相似度计算。
- 数据预处理
将不同数据源的数据统一格式,例如去除标点符号,洗掉脏数据等,这一步通常需要人工进行,相关的方法可以参考前面章节的数据预处理部分。
- 数据预分组
这一步主要是为了加快知识融合的效率,降低计算的难度。如果不进行分组的话,那么后续的实体比较过程就需要庞大的计算量。常用的数据分类方法可以采用产品经理指定类型进行分组,也可以使用机器学习的方法进行无监督聚类分组或有监督的分类进行分组。
- 属性相似度计算
根据不同的数据类型,需要采用不同的方法。如果融合的数据对象是纯字符串类型的数据,可以使用编辑距离(levenshtein distance),这是一个度量两个字符串之间相似度的算法,指两个字符串之间,由字符串A转换到另一个字符串B所需要最少的插入、删除、替换等操作的次数,操作次数越少意味着两个词越相似。
如果要融合的是集合类型的数据,可以通过jaccard相似系数进行计算,公式如下:
![]()
当两个集合A和B交集元素的个数在A与B的并集中所占比例,称之为jaccard系数,jaccard值越大说明相似度越高,如果完全一致的两个集合则相似度为1。类似的余弦相似度也可以用来计算集合类型的数据。
如果是整篇文档类型的数据,可以线通过TF-IDF算法找出文档的关键词,再通过余弦相似度计算关键词集合的相似度,以此判断文档的相似度。另外,使用词袋模型也可以用来计算文档的相似度,这两个方法我们会在后续章节详细讲解。
- 实体相似度计算
这是知识融合的第四步也是最后一步,常用的方法是聚类和聚合两种。聚类算法在之前的章节详细讲过K-means聚类,在计算实体相似度的时候,K-means聚类常常和Canopy聚类配合使用,Canpy聚类最大的特点是不需要事先指定K值。除了这两种聚类方法外,层次聚类和相关性聚类也可以用于实体相似度的计算。
另一种计算实体相似度的方法是采用聚合算法,根据属性相似度的结果计算出相似度的得分向量,然后根据机器学习的分类算法,例如逻辑回归、决策树以及支持向量机等。
3. 实操案例:Protégé构建漫威英雄关系图谱
知识图谱技术刚刚处于起步阶段,目前业内并没有一款通用的本体编辑工具,多数要进行知识图谱构建的项目,需要先开发一套知识图谱本体辑软件工具,然后再在这基础之上进行图谱的构建工作。
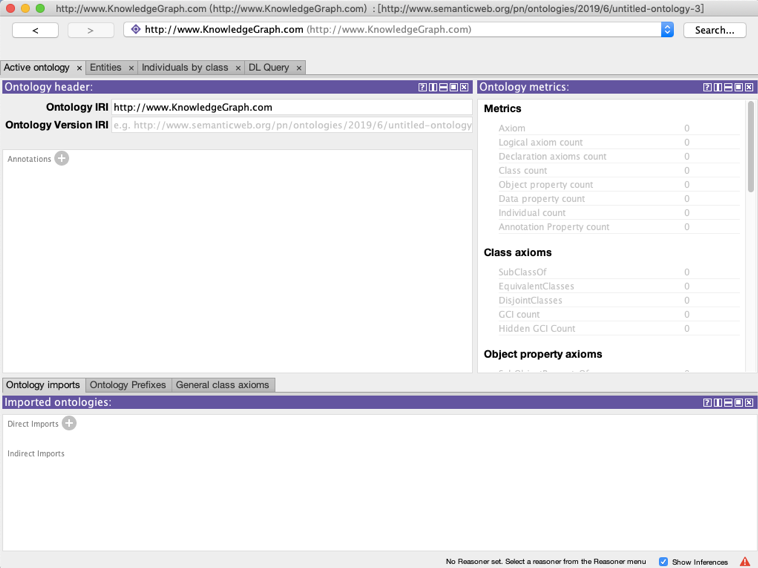
本章节的实操案例,我们将使用Protégé来进行,这是一款由斯坦福大学医学院生物信息研究中心基于Java语言开发的本体编辑和知识获取软件,主要用于语义网中本体的构建,虽然不支持多人协同编辑,但已经是目前比较成熟的开源知识图谱编辑工具,包含了整个图谱生成、可视化展现以及知识推理的过程。而且软件本身是开源的,所以可以基于源码对软件进行适当的改造,以符合公司项目需要。非常适合产品经理理解知识图谱的相关技术原理。Protégé的主界面如图所示。
3.1 构建本体
首先,我们需要构建本体,当打开Protégé软件时会默认打开“Active Ontology”菜单栏,在该菜单下的“Ontology IRI”输入项中,会有一个默认的本体前缀名,我们可以把它改为自定义的名称,就像给变量设置变量名一样,这里我将其设置为“http://www.KnowledgeGraph.com”,如图所示。
如果想要新建一个本体,点击File菜单栏下的New选项即可。

3.2 构建类
当我们构件好本体之后,点击“Entities”选项卡进行本体编辑,首先选择该选项卡下的“Classes”标签创建新的类。如图所示,在这个页面中,左侧是所有的类,用树形结构展示了类之间的对应关系,如果选中左侧的某个类,可以在右侧设置这个类的相关描述。我们会看到已经有了一个owl:Thing的类存在,这是系统默认的所有类的父类。
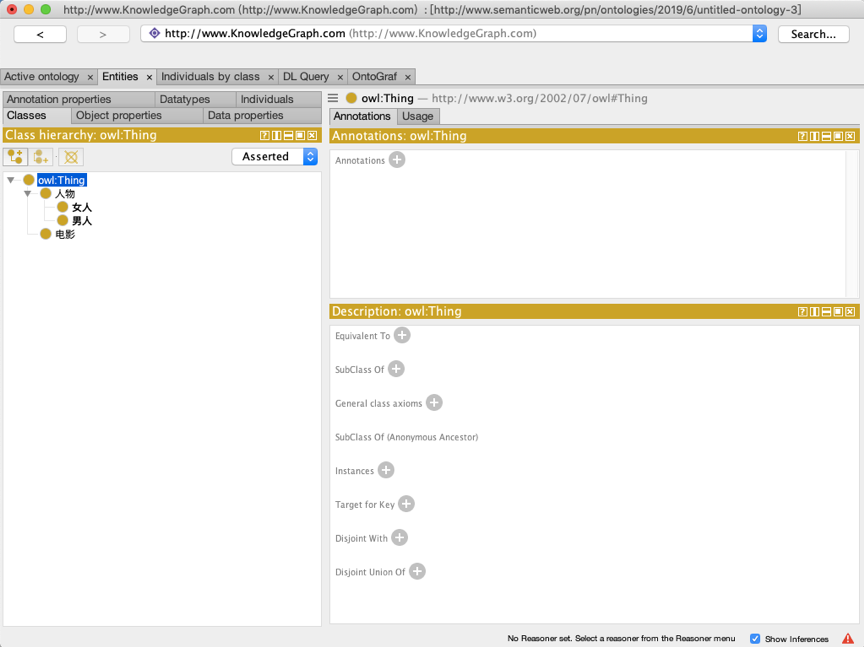
单击选中Thing,在其左上角点击图标可以创建子类,在弹出的菜单中的Name输入项中设置子类的名称,这里我们输入“电影”,然后点击确定。接着选中新创建的电影类,并点击中间的图标创建创建兄弟类,兄弟类的名称我们设置为“人物”,并在人物类下再构建两个子类,分别命名为“男人”和“女人”这样就完成了类的创建。
当然,也可以在相关的类上单击鼠标右键,在弹出的菜单中选择“Add subclass”以及“Add sibling class”来创建子类和兄弟类,效果和点击按钮是一样的。
如果想要删除某个类,只需要选中类之后点击最右侧的图标即可删除。
3.3 设置类之间的关系
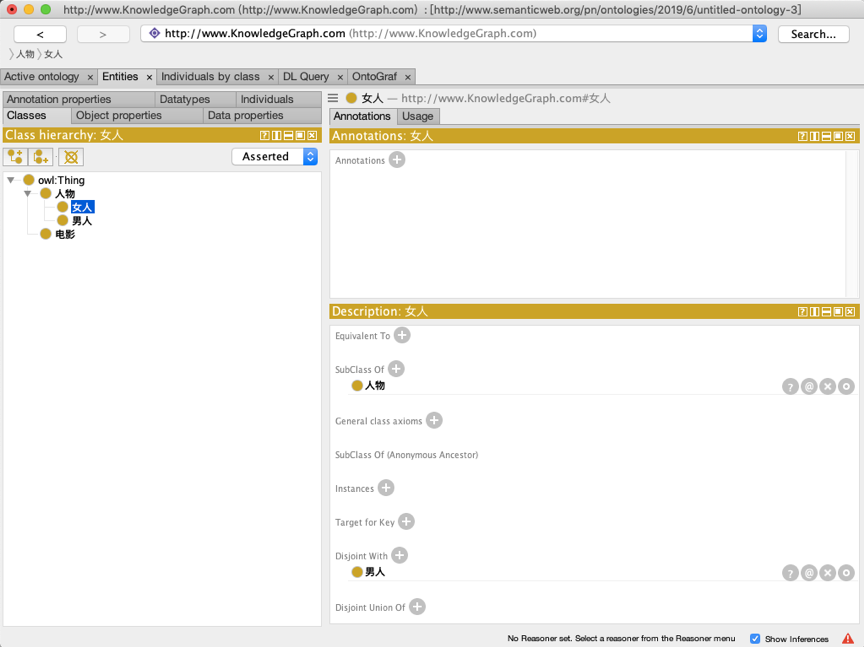
我们创建四个类,现在可以对这4个类设置一些属性了,在本例中,男人与女人是互斥关系,一个人的实例只能是男人或女人中的某一个,所以我们可以使用“Disjoint With”属性来进行描述。
选中女人类,然后点击右侧的“Disjoint With”属性右侧的加号按钮,在弹出的菜单中选择男人类,然后点击确定即可完成一个关系的创建。同样的操作我们可以设置人物和电影也为互斥的类,如图所示。
3.4 构建对象属性
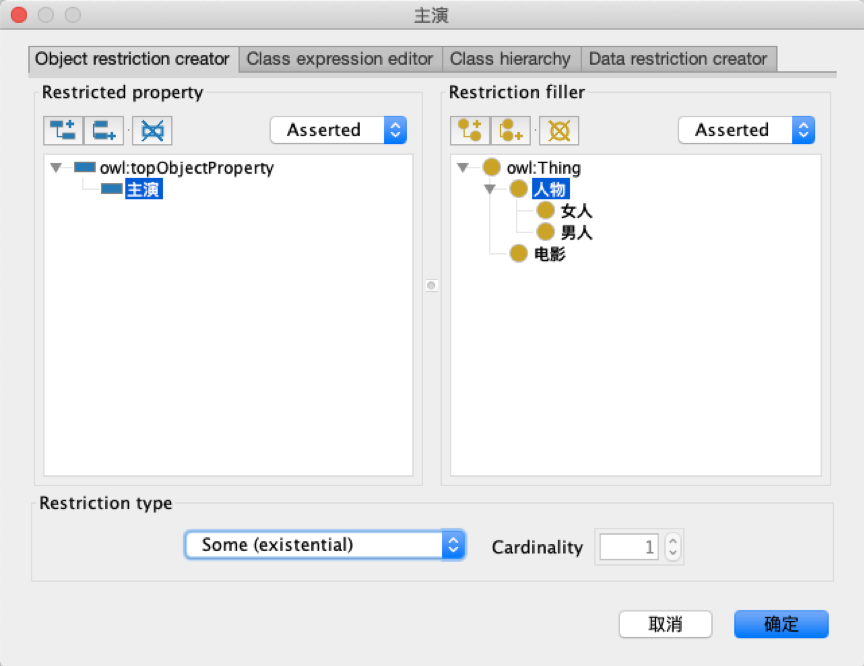
选择“Object properties”标签进入对象属性编辑的页面,与“Classes”页面非常类似,只是用主题颜色的不同加以区分。左侧已经有了一个系统默认的“owl:topObjectProperty”属性,点击左上角的按钮或者鼠标右键点击可以创建一个子属性,并在弹出的输入框中输入属性的名称。
我们可以创建一个“主演”的属性,创建完毕后,在右侧的“Description”中点击“Domains”选项右侧的加号按钮,在弹出的菜单中左侧是选择“主演”,右侧是属性对应的类,选择“人物”,然后点击确定按钮将主演和人物关联起来,表示主演的主语一定是某个人物,如图所示。
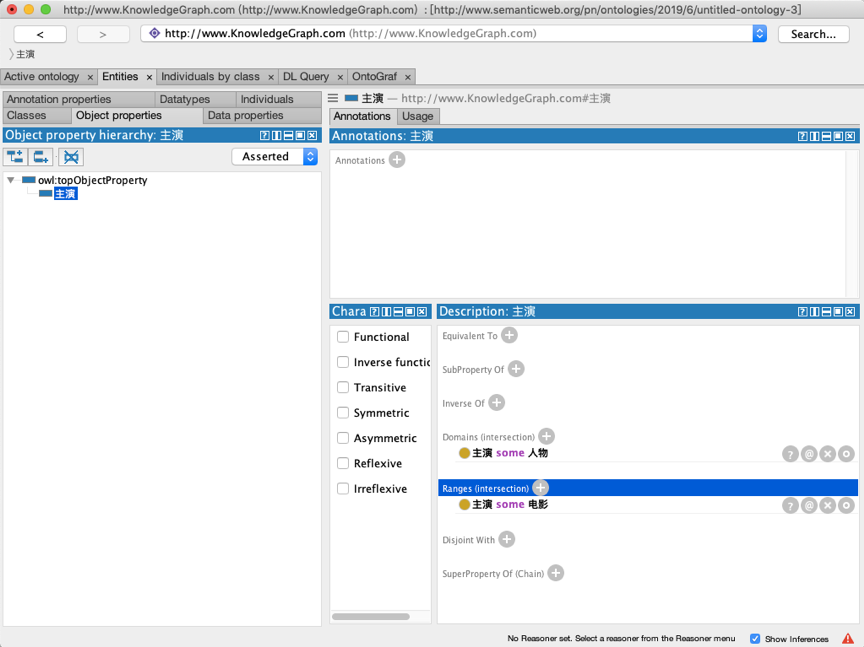
接下来设置属性的取值范围,点击“Ranges”选项右侧的加号按钮,将“主演”的取值范围设置为“电影”,点击确定即可。
这样我们就完成了一个对象属性的构建,在后续的知识推理中会用到这个属性,如图所示。
3.5 构建数据属性
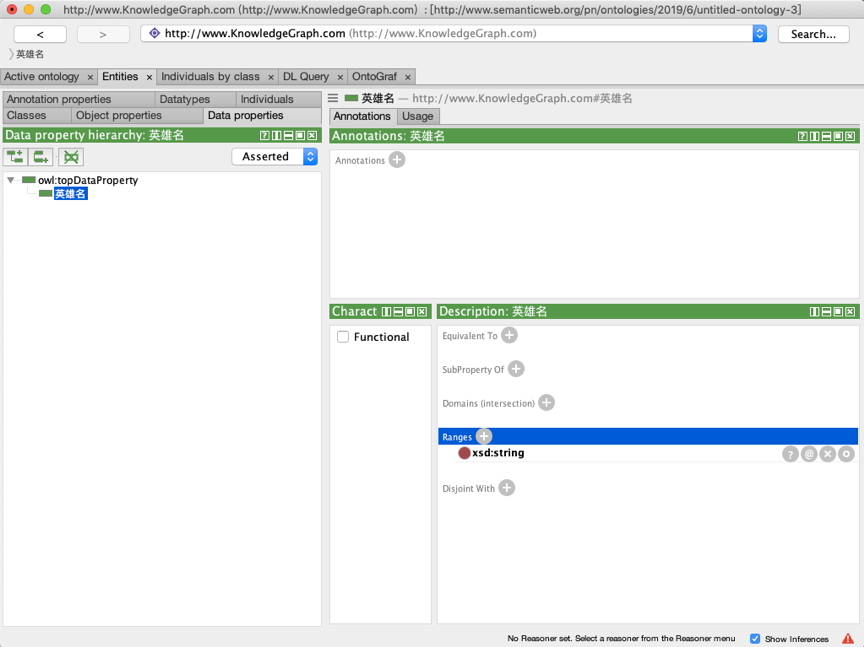
选择“Data properties”标签进入数据属性编辑的页面,在左侧已经有了一个系统默认的“owl:topDataProperty”属性,点击左上角的按钮或者鼠标右键点击可以创建一个子属性,并在弹出的输入框中输入属性的名称。
我们可以创建一个“英雄名”的属性,来表示超级英雄的称呼,创建完毕后,在右侧的“Description”中点击“Range”右侧的加号,并选择“Built in dataypes”选项卡,选择“xsd:string”然后点击确定,将这个数据属性的取值范围限定为字符串,设置完毕之后如图所示。
3.6 构建实例
点击“Individuals”选项卡进入实例编辑页面,点击左上角的图标创建一个新的实例,在弹出的菜单中输入实例名称“小罗伯特·唐尼”,点击确定即可完成实例的创建,我们用同样的方法继续创建“斯嘉丽·约翰逊”、“钢铁侠1”、“复仇者联盟1”三个实例。
选中“小罗伯特·唐尼”的实例,在右侧窗口中点击“Types”的加号按钮,在弹出的界面中选择“Class Hierarchy”标签,然后从类中选择“男人”,表示这个实例是属于男人这个类的。
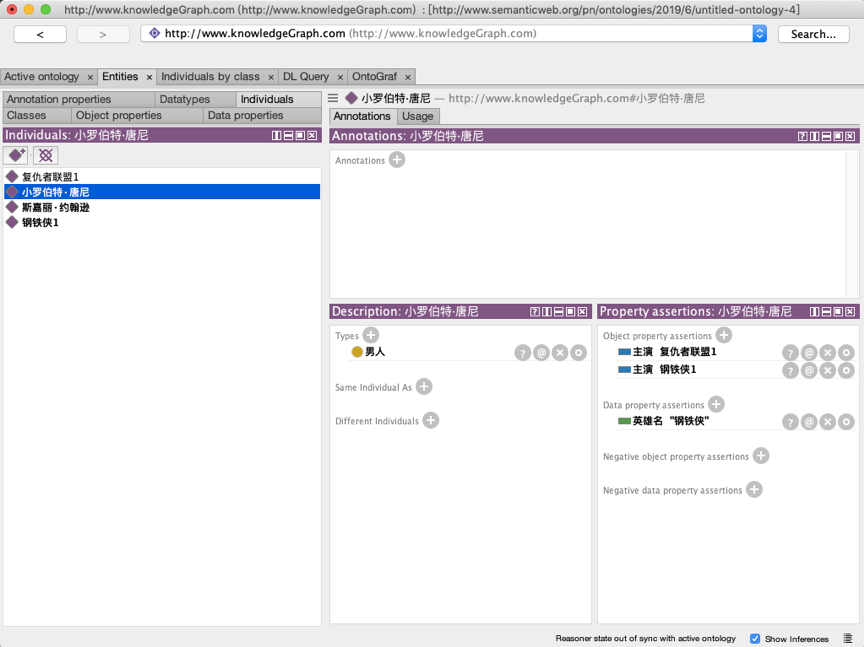
接着,在右侧的“Property assertions”设置窗口下,点击“Object property assertions”右侧的加号按钮,在弹出的菜单中会有两个输入框,左侧需要输入对象属性,右侧输入另外的实体,我们在左侧输入“主演”,右侧输入“钢铁侠1”,点击确定按钮即完成了一个三元组的创建。
之后需要设置实例的数据属性,点击“Data property assertions”右侧的加号界面,在弹出的菜单左侧选择英雄名的属性,然后在右侧填写具体的属性值,表示该人物在电影中的英雄名叫什么,这里我们填入“钢铁侠”并点击确定,最终的设置结果如图所示。
依照同样的操作流程将“斯嘉丽·约翰逊”的属性也设置完成,将“钢铁侠1”的Types设置为“电影”,但是先保留“复仇者联盟1”的type为空状态,看看如何让Protégé对这个实例的所属类进行自动判断,实现知识推理。
3.7 知识推理
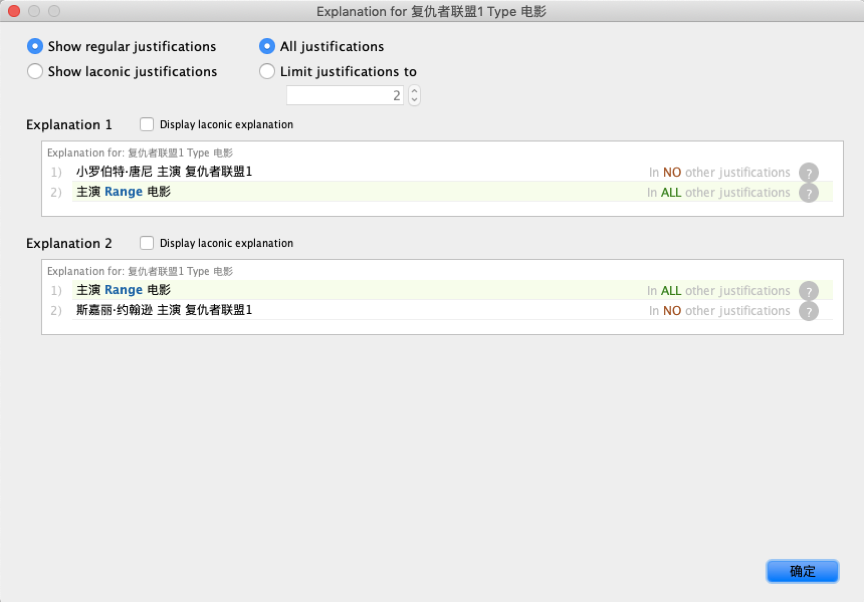
在顶部菜单中点击“Reasoner”菜单并选择“HermiT”选项,将其变为选中状态,然后再次点击“Reasoner”菜单,会发现“Stare Reasoner”变为了可选择状态,点击该按钮,系统会对知识进行自动推理计算,待计算结束之后,我们选中“复仇者联盟1”的实体,会发现它的Types已经设置为“电影”了,点击右侧的问号图标可以查看到推理的逻辑依据。
如图所示,之前我们定义了小罗伯特·唐尼和斯嘉丽·约翰逊主演了复仇者联盟1,而主演的Range取值范围是电影,所以可以就此推断出复仇者联盟1是一部电影。
3.8 图谱可视化
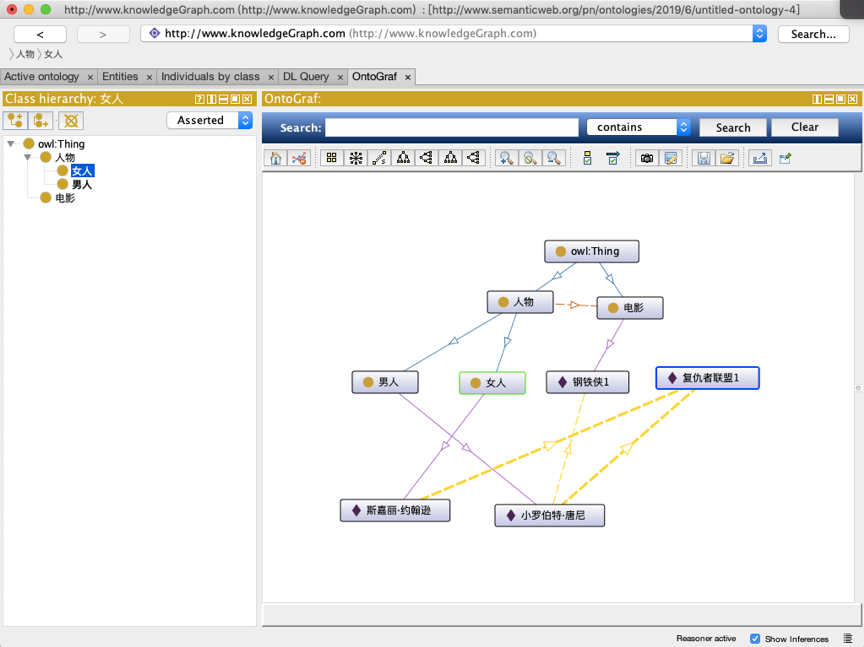
在顶部的“Windows”菜单下选择“Tabs”下的OntoGraf选项,顶部会增加“OntoGraf”菜单,切换到该菜单并点击左侧的类名称,即可在画布中显示类的图标,如果类有子类或者实例,则会在图标上出现一个加号,双击带加号的图标可以下钻展开查看所有的类和实例。鼠标移动到线上,就可以显示这条线代表的关系名称。通过鼠标拖动图标可以很直观的查看到本体之间的关系
本文由 @黄瀚星 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于CC0协议









请问,做一个AI产品经理,需要对技术这么了解的吗?还是说要对业务了解够深就好?
至少要知道技术的实现原理,能做什么以及不能做什么
即使是一个微小的改动
感谢指正,已修改
错别字 目前以网页为主要载体
我现也是智慧城市项目,想向您学习,方便留下联系方式吗?谢谢!
13077313888
嗯,已加您,麻烦您通过下,感谢