
 起点课堂会员权益
起点课堂会员权益策略产品经理实践:主观评估的方法论
 产品经理软技能是指如逻辑分析、文字表达、语言表达、学习能力、总结能力、创新力、好奇心、情绪态度和团队合作等。
产品经理软技能是指如逻辑分析、文字表达、语言表达、学习能力、总结能力、创新力、好奇心、情绪态度和团队合作等。编辑导语:策略产品经理在工作过程中往往离不开主观评估,在科学的评估方式指导下,主观评估可以和客观数据指标互为补充,同时辅助业务决策。本文作者将以此为出发点,主要介绍了一些主观评估(平台视角)的相关方法论。

一、主观评估的三条关键准则
在摸索出以下三条关键准则之前,笔者在工作早期的主观评估项目多数以失败告终。失败的原因往往是主观评估数据无法取得广泛的认可,也就无法使用该数据推动决策。
通常项目失败的原因如下:
1. 稳定性差
在没有做大调整的情况下,上个评估周期的主观评估数据与这个评估周期的数据相差甚远,从而不知道应该相信哪一份数据。
2. 其他团队对指标不认可
策略产品经理做了一份主观评估结果并发送邮件给相关人员,但被其他团队质疑数据有效性。
比如,对于某个通用分类器的召回率数据,算法工程师认为是90%,而策略产品经理评估只有70%。
当然这两个数值是随意杜撰的,但这件事情背后往往是不同团队KPI压力导致的,需要一种切实有效的手段来统一所有人的认知。
二、分析
1. 对于第一种情况
往往是抽样方法或者评估标准导致的,如果在上一次评估周期中抽取了小样本,而在下一次评估周期中抽取了大样本,两次结果的置信区间宽度差距较大,那么结果差异大。
如果两次评估的抽样采用了不同的过滤策略,则抽取的样本实际数据分布不同(比如,第一次抽样过滤了无效状态,而第二次抽样并未过滤)。
另外,两次评估的评估员不是同一人或者评估标准不清晰,数值也会有差异。但以上问题都可以通过相应的手段解决。
2. 对于第二种情况
相信做过主观评估项目的人一定非常熟悉,由于团队内有多个“手表”产生了“手表效应”,不同视角数据(上例中的算法工程师和策略产品经理各执一词的两份数据)的增加,不仅没有为团队带来收益,反而导致团队内部变得更加混沌。
主观评估数据不被信任有多方面的原因,一个最大的原因是对于同一个事物,每个人的主观标准难以实现精准的“调和”。
毕竟大多数人来自不同的省市,接受了不同的教育,在走上工作岗位时已经形成了完整的世界观,此时很难去统一不同人根深蒂固的底层认知,这也是主观评估项目的最大挑战。
所以在汇报主观评估项目时,尤其考验策略产品经理的推动能力和汇报技巧,他们必须推动更多的人支持该方案。
三、总结
经过对多方的广泛复盘和经验沉淀,笔者总结出了以下三条关键原则,如图3-2所示:
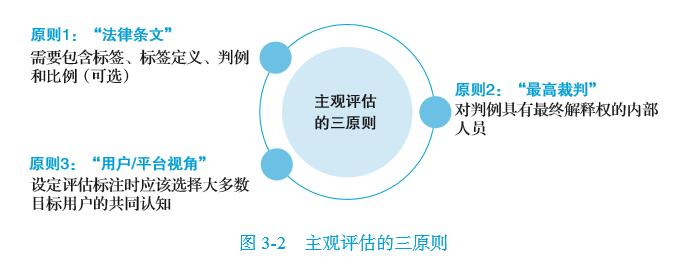
1. “法律条文”—“主观评估标准”的四要素
主要作用是使用客观清晰的语言统一团队内部所有人的认知,即对于任意的主观评估标准而言,必须具备完整的“法律条文”.
具体包含以下4个关键要素:
1)标签
标签可以是连续的,也可以是离散的。体育分类的内容、美术分类的内容等属于离散标签,豆瓣上的电影评分属于连续的标签,标签的设定完全是由主观决定的。
2)标签定义
需要满足“形容词+名词”的组合:标签定义是为了让大多数人理解标签含义的重要手段,所选择的形容词和名词必须是有实际含义的“{形容词}的{形容词}的{名词}”。
比如豆瓣电影评分为9分的电影指的是“值得多次回顾的(形容词)、立意深远(形容词)的电影内容(名词)”,1分的电影指的是“浪费时间的(形容词)、毫无主题(形容词)的电影内容(名词)”。
3)判例
通常以关键词或该标签的示例给出,和“法律条文”接近,在给出主观评估标准时需要给出非常具体的实例作为判例,数量越多越好,一般不少于5个,比如豆瓣评分9分的电影(标签)的判例为《肖申克的救赎》《这个杀手不太冷》等。
判例是对标签和标签定义的具体补充,大多数情况下团队内部往往对于标签和标签定义不会有较大分歧,而对于判例的分歧一般较大。
所以对于主观评估标准而言,判例是最重要的部分。请选取团队内部讨论通过的,并经由“最高裁判”确认的标志性示例作为判例,这是主观评估流程中一个非常重要的步骤。
4)标签的比例要求
对于离散型标签而言,往往没有比例要求。比如对于体育分类的内容,策略产品经理往往并不要求一定要保证体育分类的内容要占到全体内容的何种比例,而是顺其自然地符合自然分布即可。
而对于连续型标签,往往需要对不同等级的标签设定预期比例,比如金字塔形分布(10分电影所占比例不超过1%,9分电影比例不超过6%,8分电影比例不超过12%等数值要求)或者纺锤形分布(即两极的占比低,中部的占比高)。
2. “最高裁判”—主观评估的必要角色
主观评估项目中常见的现象是平台内部对于最终的主观评估数据结果各执一词,造成这一现象的根本原因是平台内部缺乏一个对于标准有最终解释权的“最高裁判”的存在。
关于“最高裁判”,笔者有以下经验可分享:
1)谁来推动
由于职场中大多数人对于主观评估的经验不足,一般来说“最高裁判”的选择需要策略产品经理推动相关角色选举产生,如果民主选举无法产生“最高裁判”,此时策略产品经理应该召开标准讨论会议,并邀请项目中职位最高的管理者参加。
会议中推动项目最高管理者指定主观评估标准的“最高裁判”人选。该人选对于主观评估标准负责,具有最终解释权。
2)谁作为“最高裁判”
第一个条件是“最高裁判”应是对于主观评估标准制定最资深、最权威的人员(内容型产品中一般由运营经理负责)。
第二个条件是“最高裁判”应是避免与该评估数据有直接利益关系的人(比如某NLP分类器模型,“最高裁判”的评估人员不应该是该NLP算法工程师,而应该是第三方中立的业务人员),杜绝“既当运动员,又当裁判员”的现象。
3)产生争议怎么办
当平台内部对于主观评估结论存在多个质疑的声音时,双方评估的人员、“最高裁判”可以在会议室内当场校对标准(以笔者的经验看,对于争议的实例,一般60分钟的会议即可完成双方标准的统一),并由“最高裁判”对主观评估结论给出终审判决。
3. “主观评估标准”的用户视角和平台视角
对于标签定义而言,应当尽量贴合用户视角,设定评估标注时应该选择大多数目标用户的共同认知。
以《火影忍者》的漫画分类举例来说,从平台价值观和用户价值观两个角度来看是不一样的:
1)平台价值观
《火影忍者》是“热血分类”动漫,其中“热血分类”是主观评估标准中的一个标签。
2)用户价值观
用户A可能会认为“火影挺好玩的,看着挺刺激的”,用户B可能会认为“火影好热血啊,是一个热血动漫”,而女性用户C可能会认为“火影是一部彩虹漫画,鸣人、佐助太甜了”。
可见,在本例中用户A和用户B脑中的第一反应都是“热血分类”,而用户C的第一反应是“彩虹漫画”,而此时的主观评估标准应该选取大多数人的认知。
在进行主观评估标准设定时,策略产品经理应该考虑到用户的认知水平差异。
为了让大家更直观地理解主观评估标准的设计方式,下表给出了漫画属于何种漫画分类的主观评估标准示例:
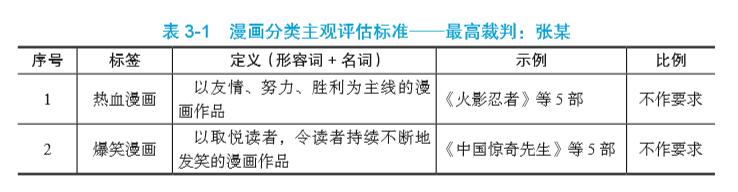
上述的主观评估标准示例是为了便于理解而杜撰的,在实际工作中,主观评估标准要细致得多,可以增加对于该标签与其他标签的区别(比如增加一列备注)。
该标签的正例和反例都可以沉淀到公共文档上,方便团队所有相关人员查阅,对于以上三条主观评估原则的实例应用。
作者:韩瞳,文章选自《策略产品经理实践》,2020年7月出版。
未经出版社或作者书面授权,禁止转载,违者追究法律责任
题图来自 Unsplash,基于 CC0 协议


















主管决策往往需要个人影响力来推动,这文章讲得都是怎么推动议程,对于如何做决策没什么干活。
用户A可能会认为“火影挺好玩的,看着挺刺激的”,用户B可能会认为“火影好热血啊,是一个热血动漫”,而女性用户C可能会认为“火影是一部彩虹漫画,鸣人、佐助太甜了”。———–我怀疑你在歧视女性hhh