
 起点课堂会员权益
起点课堂会员权益计算机视觉的三部曲
计算机视觉目前已经被应用到多个领域,如无人驾驶、人脸识别、文字识别、智慧交通、VA/AR、以图搜索、医学图像分析等等,是人工智能(AI)目前最火的领域之一。那计算机视觉是什么?完整链路是怎样的?有哪些技术点?本文将跟大家一起探讨。

计算机视觉(Computer Vision),就是用机器来模拟人的视觉获取和处理信息的能力。它主要研究的内容是通过对图片或视频的处理,以获得相应场景的三维信息,另外其研究很大程度上是针对图像的内容。
本文主要参考了商汤科技CEO徐立老师的分享,将计算机视觉分为三部分:成像、早期视觉和识别理解。本文也是围绕这三部分进行讨论。
一、成像(Image)
成像就是计算机“看”的能力,是计算机视觉的输入,相当于人的眼睛。影响计算机成像(看),主要有几个因素:光、物体不全、模糊。
当然计算机看到的东西可能不仅只是人眼看到的那样,甚至可以是人眼能力的延伸。
这个怎么说呢?后面将为会你解密。
1.1 光
(1)光线不足
光线不足是常见的问题之一,特别是在晚上。

比如说以上左图可能是人眼看到的,但是通过对图像做增强或者其他算法的处理,就可以变成了像以上右图那样,能看清物体了。这就是我们前面说的,机器成像也可以是人眼能力的延伸。
(2)曝光过渡
曝光过渡也比较容易出现在晚上,为什么呢?比如说你所拍摄的物体被车灯或其他强灯光照射,就容易出现曝光。

曝光的话,也可以通过一些简单的算法处理,来还原图像的样子。
1.2 物体不全
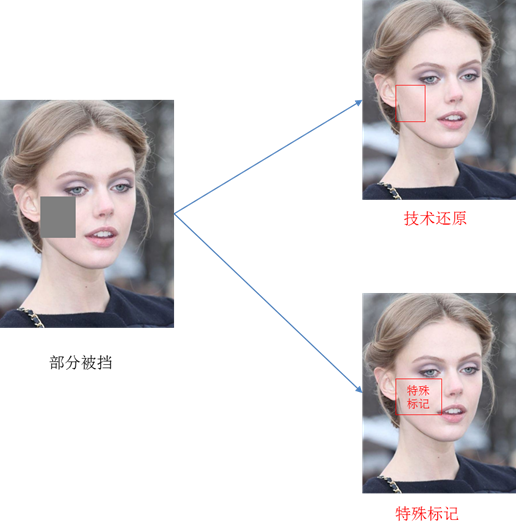
物体不全,主要表现有两方面原因:被拍物体部分被遮挡住了、只拍了被拍物体的一部分。

那出现这种场景的时候,我们机器需要怎么处理呢?可以尝试考虑的方向有两点:
- 机器能不能根据拍得清晰的那部分的特征,自动去补全被遮挡的部分呢。
- 机器能不能对被挡住的部分做一些特殊的标记,传送到下一层的时候,下一层就知道这个地方是异常的,需要特殊考虑。这样就可以避免挡住的部分给下一层的传达错误的信息。
1.3 模糊
造成模糊的原因可能有几种:
- 运动模糊
- 对焦模糊
- 分辨率低(图片质量差)
- 待识别物体过小
- 雾霾、烟气等因素
那出现模糊的情况,计算机能做什么呢?
比如说拍照的时候,手一抖,就拍成了如下左图,是可以通过一些算法,恢复成如下右图的样子。

或者说雾霾很严重的时候,拍出来的照片如下左图,经过机器成像后,可以变成如下右图的样子,把图片还原成了没有雾霾的样子。

那是不是一定要还原成物体最真实的样子呢?也不见得,我们还可以做一些更加有情怀,更加有艺术感的处理。比如说把雾霾的图片,变成油画的样子,就相当于给我们戴上了墨镜,或者说戴上了3D眼睛去看电影。

所以,具体需要“看”成什么样,也是根据我们的最终目的调整的。
二、早期视觉(Early Vision)
在徐立老师的定义里,早期视觉可以理解为视觉系统处理的中间结果,相当于我们人视觉感知系统的某一层。
就像我们的视觉感知系统那样,虽然我们不太容易直观的描述它做了什么处理,但它确实是有处理了一些信息,然后传给了大脑的其系统。早期视觉也是这样,充当一个中转站的角色。
早期视觉主要包括的内容有:图像分割、边缘检测、运动和深度估计等。
下面我们给大家介绍下图像分割和边缘检测(运动和深度估计不太懂就不在这瞎说了,感兴趣的同学可以自行研究)。
2.1 图像分割
图像分割指的是根据灰度、 颜色、 纹理和形状等特征把图像划分成若干互不交迭的区域, 并使这些特征在同一区域内呈现出相似性,而在不同区域间呈现出明显的差异性。

比如说上图,根据颜色区分出了不同的模块,路是路,车是车,树是树。
图像分割经典方法有:边缘法和阈值法,但也可以用深度学习处理出很好的效果。
图像分割在图像处理中非常经典,也经常用到。比如说抠图,首先进行图像分割,取出我们目标部分,就可以把背景去掉了,最后还原。

还有表情包的合成:

2.2 边缘检测
边缘检测的目的就是找到图像中亮度变化剧烈的像素点构成的集合,因此表现出来往往是事物的轮廓。

如果把“图像分割”比喻成油画的话,那“边缘检测”就是素描。
如果图像中边缘能够精确的测量和定位,那么,就意味着实际的物体能够被定位和测量,包括物体的面积、物体的直径、物体的形状等就能被测量。
以下4种情况会表现在图像中时通常可以形成一个边缘:
- 深度的不连续(物体处在不同的物平面上);
- 表面方向的不连续(如正方体的不同的两个面);
- 物体材料不同(这样会导致光的反射系数不同);
- 场景中光照不同(如被树萌投向的地面)。
2.3 小结
早期视觉目前还有很多问题,还是不能做到很精准,因此现在端到端的训练方法是个很好的解决方案,比如说我们用深度学习来做图像分割。
三、识别理解(Recognition)
识别理解相当于人的大脑对信息的处理,经过处理后并给出反馈结果。
比如说人脸识别:

我们输入一张人脸的图片,机器就与人脸数据库中人脸进行比对,然后机器就可以告诉你这个图片的人是谁。
就像我们的大脑,看到一个人,我们就会去回忆,之前有没有见过这个人,在哪里见过,他叫什么名字等等一些信息。
从这个例子中,我们可以看出,机器识别理解的两个重要因素:
(1)数据库(人的记忆)
只有你数据库的数据足够多,也就是说你见过足够多的人,再给你看一个人的时候,你才知道这个人是谁。
(1)标签(特征点)
你是根据什么辨识这个人的,他的肤色、发型、眼睛、鼻子、嘴巴等等,也就是说我们需要给这些数据打上足够多的标签,识别的时候,就可以拿这些标签特征进行对比了。
徐立说:只要把图片和这种标签定义得足够好,数据量足够大,数据够完善的话,它有非常大的可能在垂直领域上,能够超越现有人类的识别准确率。
小结:
其实我们现在缺的不是数据,想要数据很简单,装足够多的摄像头,没日没夜的拍,数据就够多了。但是这些数据意义不大,没有标签,或者说场景不够丰富,因此我们缺乏的是高质量的数据,高质量表现在标签足够丰富和完善。
此文章主要参考了徐立老师的演讲内容,感兴趣可以去看下,徐立老师讲得更加哲学和情怀。
附参考文章:
- 《商汤徐立:计算机视觉的完整链条,从成像到早期视觉再到识别理解》
- 《看AI产品经理如何介绍“计算机视觉”(基于实战经验和案例)》_Jasmine
- 《从0开始搭建产品经理的AI知识框架:计算机视觉》_蓝风GO
- 《边缘检测》_Ronny
- 《闲聊图像分割这件事儿》_言有三
- 《图像分割》_古路
本文由 @Jimmy 原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自Unsplash,基于CC0协议。






- 目前还没评论,等你发挥!


