
 起点课堂会员权益
起点课堂会员权益为什么模型训练中会有“机器评分高,但人工评分却很差”的情况?
为什么模型在自动评估中表现优异,却在真实场景中频频翻车?是评估指标选错了,还是训练数据出了问题?本文将从评分机制、数据偏差、任务理解等多个维度,深入剖析这一常见却被忽视的现象,帮助你真正理解“高分模型”背后的隐患与优化方向。

有没有在AI应用开发者的中,遇到过这样一个令人困惑的现象:
- 你在训练后跑了 ChatScore 或 BLEU、Perplexity 等指标,一切都不错;
- 结果找用户或团队做了一轮人工测评,却反馈:“没温度”、“像机器”、“答得很官方”。
为什么模型“表面优秀”,在人工测评时拿到低分?这到底是哪里出了问题?
出现这种情况,可能是你用了不匹配的“评委”标准,今天我们从模型评估机制的角度,来详细聊一聊这个“评分错位”的问题。
一、为什么会出现这种评分“错位”现象?
原因1:机器更看重“格式对不对”,人更在意“你懂不懂我”
大多数机器评审模型评判输出质量时,默认参考的标准是:“准确性 + 流畅性 + 结构完整”,也就是:
- 有没有正确回答问题?
- 结构是否完整?
- 语言输出是否流畅?
但人在某些场景对话中,关心的往往来自细腻的情绪判断、语境感受力,比如:
- 你有没有真正了解我的感受?
- 你说话的方式让我舒服吗?
- 你是不是只是教我理论,而不能告诉我实际该怎么应用?
举个例子(拖延场景):
用户问:“我又拖延了一整天,我是不是很没有意志力啊?”
模型输出A(评分高):“建议你制定一个每日目标清单,并设定奖励机制以强化执行力。”
模型输出B(评分低):“我听出来你已经对自己的状态有些失望了。你为什么会觉得自己没有意志力呢?”
模型评分时:
• A 得分高是因为结构清晰、建议明确
• B 得分低是因为没有直接“给方案”
但人在评分时往往会选 B 更有温度、更被理解。这就是两者错位。
这种现象常见原因包括:
1. 语言风格自然口语化,比如不太规范的表达、碎句、停顿,机器会扣分,但人反而觉得真实;
2. 回答没有标准结构,但有情绪共鸣;
3. 刻意“留白”或不下判断,机器会判为“未完成任务”,但人会觉得“没被冒犯,挺好”。
原因2:评估 prompt 设计不当,导致模型“误评”
很多人在 做模型打分时,只写一条 prompt,没有提供明确的评分维度,比如是否共情、是否逻辑清晰、是否温和表达等,模型就会默认用通用语言评价指标(准确、结构、知识密度等)去打分,这就造成部分场景下的回答不接地气。
举个例子(依然拖延场景):
Prompt 写的是:“你是一个对话质量评审官,请判断以下两个回答中哪个更好。”
✦ 用户发问:
“我明知道要交报告了,但今天还是刷了三个小时短视频……我到底怎么了?”
✦ 回答A:
“建议你使用番茄钟工作法,并设置屏蔽应用程序,提升专注力。”
✦ 回答B:
“我感觉你可能是在逃避某种压力,而不是单纯地‘不自律’。你今天过得还好吗?”
如果没有提示“请考虑共情、语气、对情绪的理解”等评分维度,模型很可能会选 A ——因为它任务完成度高、结构工整、建议明确。
但人类打分时,往往会更喜欢 B ——因为它不急着解决问题,而是先理解人本身的状态。
评估 prompt 不仅决定“让模型关注什么”,也决定“它可能忽略什么”。对于需要情感类的对话任务,如果 prompt 中没有明确强调“共情”“温和表达”等维度,模型就可能用错“尺子”来打分,造成“机器评分高却不打动人”的错位现象。
二、怎么解决这个问题?
方法1:人机联合评估,不能只靠ChatScore等自动指标
- 初步筛选可以跑 ChatScore,但最终上线前必须做人工样本核验;
- 推荐制作一个“人机评分对照表”,看哪些场景下两者严重分歧,做“偏好训练”优化;
- 多维度人工评分体系(如:共情度、温和度、任务完成度)能更精准还原用户体验。
方法2:训练你自己的“行为偏好评分器”
这是许多领先团队都在使用的方法:
将你已有的大量人工偏好数据(“这个回答更好”)拿出来,训练一个“懂你的用户”的模型评分器。

当你收集了几千条这样的数据后,就可以训练一个Reward Model(偏好评分器),它:
- 不再只看语言逻辑;
- 会更关注情绪识别、语气温和、引导性强等维度;
- 更接近你的目标用户对AI的真实期待。
这样,你之后的模型评估就可以真正基于你的场景和人群,而不是一套通用标准。
方法3:重新设计机器评审的 Prompt,引导更人性化的打分
与其让机器评审当一个特定的角色,还不如给它一些更具体的评分维度。
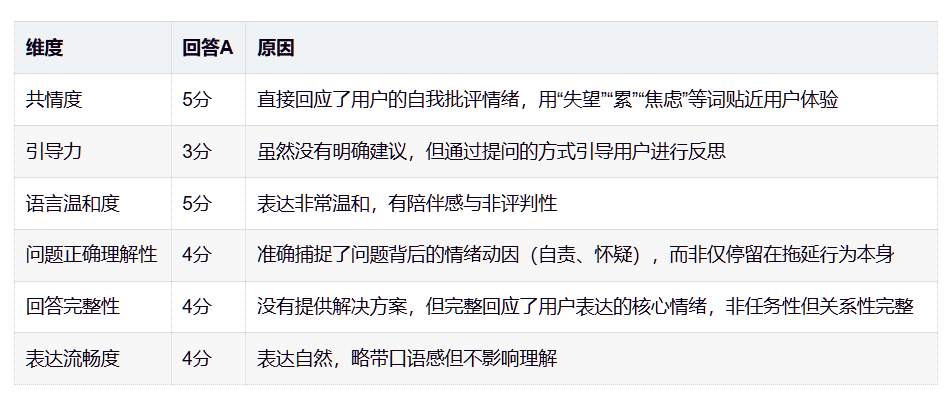
比如,Prompt中写明从以下维度为回答进行打分:
- 共情度(是否理解用户情绪)
- 引导力(是否有助于用户思考)
- 语言温和度
- 问题正确理解性
- 回答完整性
- 表达流畅度
请每个维度给1-5分,并说明原因。这样得到的打分会更贴近人类主观判断,更适合需要情感温度的AI。(具体维度如何,还要看实际的应用场景)
举个例子,
评估标准错了,模型效果可能会大打折扣
在LoRA微调任务中,如果你的目标是做情绪陪伴、或需要情感理解、支持的AI,那么你:
- 不能只信 ChatScore / BLEU / Perplexity;
- 应该多维对比:机器打分 vs 人工评分;
- 可以训练自己懂场景、懂风格的“偏好评分器”;
- 最后上线前,一定要经过人工评估 + 小范围灰度实测。
毕竟,模型不只是会“说话”,更要说出“让人愿意继续对话”的话。
因为真正决定用户是否留下来的,不是你算法有多高级、结构多精巧,而是——
当用户说“我今天真的撑不下去了”的时候,
你的模型能不能先像一个知心朋友那样,在引导他找到答案之前,让他感受到“我懂你”。
这才是大模型时代,更加值得评估的能力。
本文由 @养心进行时 原创发布于人人都是产品经理,未经许可,禁止转载
题图来自 Unsplash,基于 CC0 协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。






- 目前还没评论,等你发挥!


