
 起点课堂会员权益
起点课堂会员权益保险AI进入下半场:能做Demo不等于能上线,关键在“可解释、可追溯、可交付”
保险AI赛道正在经历从炫技到落地的关键转折。当客户不再关心模型参数,转而追问系统稳定性、可解释性与业务指标时,这场竞赛的规则已然改变。本文将深度剖析保险AI项目中的三大关键断点,并分享如何通过构建'可信链路'实现从实验室到生产环境的跨越。

场景说明:本文基于真实项目经验做脱敏复盘,不涉及企业敏感信息。
过去一年,我明显感觉到保险AI项目在“变速”。
前两年大家讨论的关键词还是“大模型能力”“功能炫不炫”;现在客户最常问的已经变成:
- 这套系统能不能稳定上线?
- 出问题时能不能解释清楚?
- 被抽查时能不能拿出完整证据链?
- 三个月后业务指标有没有变化?
说白了,保险AI已经从“演示竞争”进入“交付竞争”。
这篇文章我想分享一个核心结论:
2026年,保险AI项目的分水岭,不在谁的模型参数更大,而在谁能把“可解释、可追溯、可交付”做成产品基础设施。
一、为什么我说“下半场”已经开始
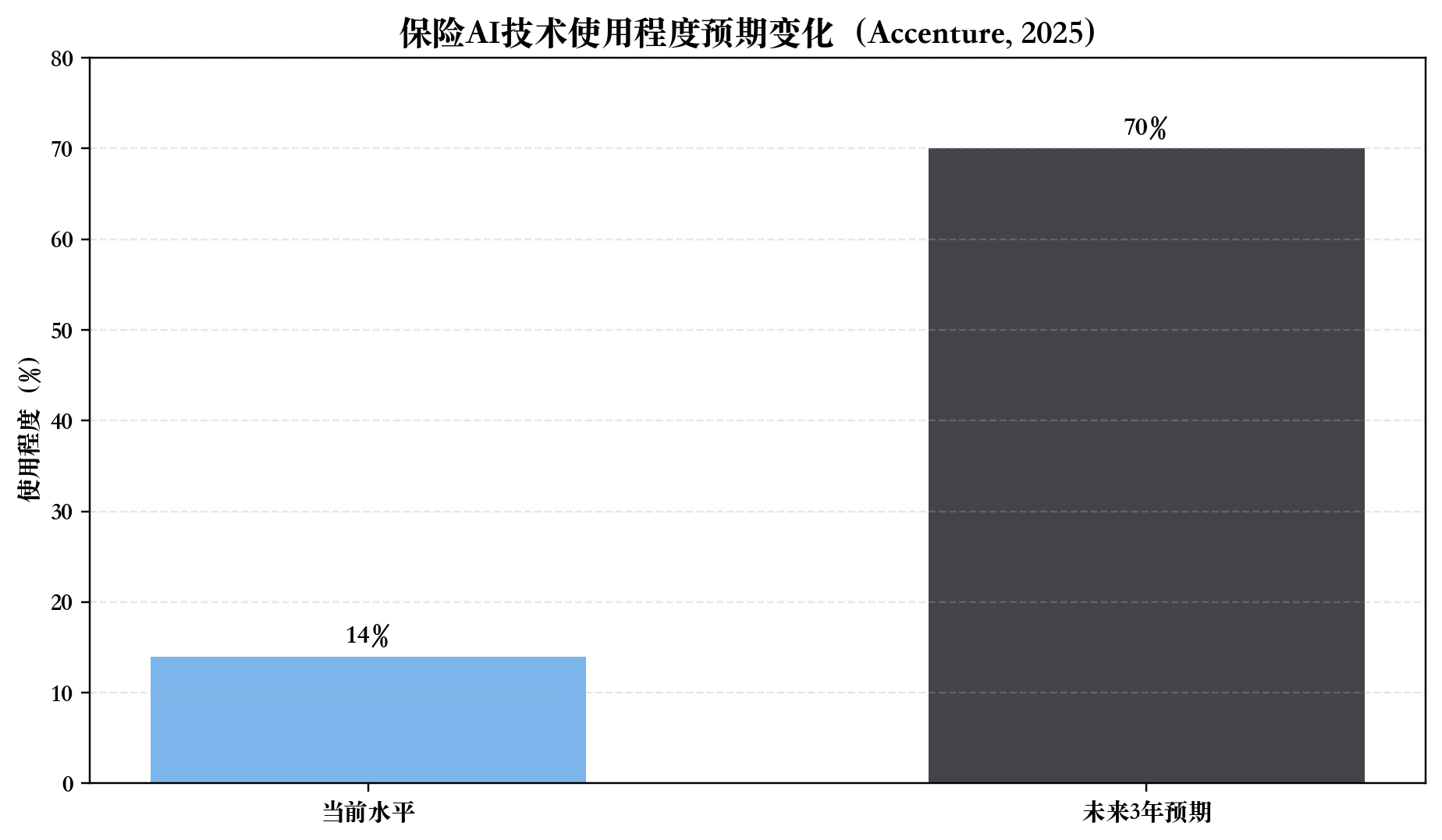
图2 保险AI采用趋势(公开信息整理)
1. 采用在加速,但约束也在加速
外部公开信息很清楚:
- 保险机构对AI的采用预期在快速上升;
- 同时,监管机构对治理、记录、可解释、人工监督的要求也在持续细化。
这意味着一件事:
保险AI不是“先上再说”的游戏,而是“边上边管”的系统工程。
如果只看模型效果,不看治理能力,项目前期会很快,后期会很痛。
2. 保险行业的本质是信任行业
在保险场景里,效率当然重要,但“被信任”更重要。
我们在项目里最常见的情况是:
- 模型判断有时候是对的;
- 但业务人员看不懂“为什么对”;
- 最终选择“按经验做”,系统被边缘化。
所以真正影响上线成败的,不是“模型有没有结论”,而是“结论能不能被团队共同理解和复核”。
二、我们在项目里看到的3个断点
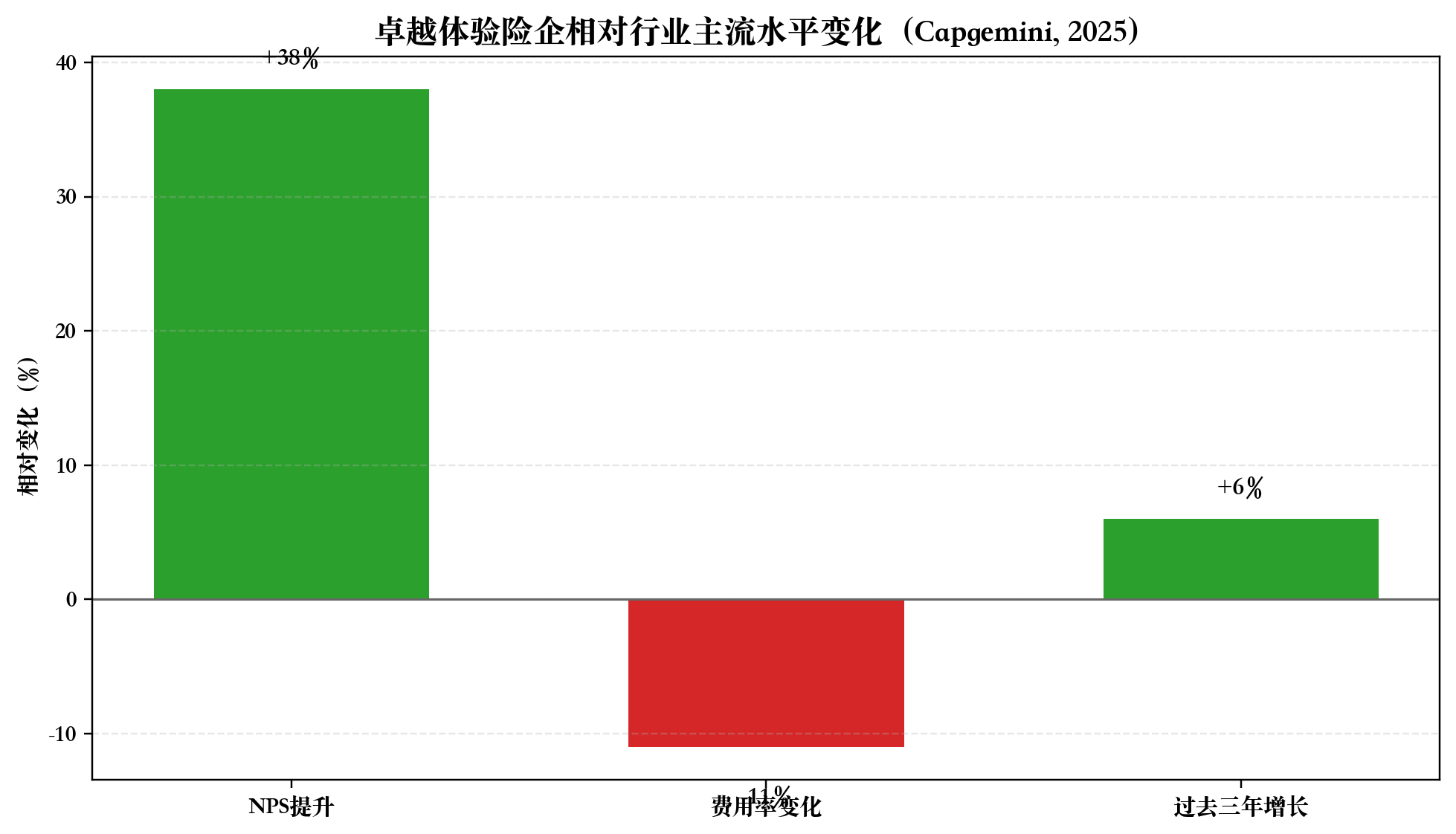
图3 客户体验与经营指标关系(公开信息整理)
很多团队把问题归结为“成交率低”“话术不行”“顾问能力差”。
但从产品视角看,更关键的是三个链路断点。
断点1:信息断点——客户信息存在,但不成资产
常见现状:
- 通话里说了很多关键信息;
- 系统里却只有碎片化记录;
- 跨人、跨轮次沟通时无法复用。
结果是重复提问、跟进跑偏、客户体验下降。
断点2:决策断点——资源分配靠经验,不靠证据
销售团队普遍很忙,但忙不等于有效。
当“先跟谁”主要靠主观判断时,最容易出现:
- 高意向客户跟进不及时;
- 低意向客户投入过多;
- 团队效率被平均掉。
断点3:推荐断点——有结果,无理由
推荐系统如果只给“推荐A产品”,不解释“为什么是A、为什么不是B”,业务会天然不信任。
尤其在保险场景,推荐不仅要“看起来合理”,还要“说得清楚、留得下证据”。
三、我们的产品化做法:先做可信,再做智能
围绕这三个断点,我们最后沉淀出一条简单原则:
先把“可信链路”做出来,再追求“智能上限”。
1)KYC自动提取:从“散信息”到“结构化资产”
我们没有先做推荐,而是先做了KYC结构化:
- 固定字段schema;
- 字段级置信度;
- 证据句绑定(可回放到原始对话)。
这样做的价值不是“炫技术”,而是让团队有共同事实基础。
2)意向评分:从“分数输出”到“动作输出”
我们把意向评分从单一分值改成“队列+原因+下一步动作”:
- A类:优先跟进;
- B类:继续培育并补关键信息;
- C类:低频维护。
关键变化是:顾问拿到的不只是判断结果,而是可执行建议。
3)产品推荐:从“给答案”到“给边界”
推荐模块先做约束,再做候选:
- 先判断哪些方案不该推;
- 再给2-3个候选;
- 每个候选都附“推荐原因+不推荐条件+信息缺口”。
这一步把“黑盒结论”变成“可讨论的建议”,采纳率提升明显。
四、为什么“可解释、可追溯、可交付”必须一起做
很多项目会把这三件事拆开处理:
- 先上线,再补解释;
- 先跑业务,再补审计;
- 先验证价值,再补治理。
在保险场景里,这种节奏很容易出问题。
我的经验是:这三件事必须并行设计。
可解释:解决“敢不敢用”
如果一线看不懂系统逻辑,系统再准也会被绕开。
可追溯:解决“能不能复核”
没有证据链,合规和质检无法形成闭环,风险不可控。
可交付:解决“能不能长期跑”
没有稳定发布、监控、回滚机制,任何效果都可能是短期幻觉。
五、从产品经理视角,如何推进90天落地
下面这套节奏,我们在项目里验证过,适合资源有限但希望尽快出结果的团队。
第1阶段(1-30天):打通证据链
目标:让关键字段可回放。
重点动作:
- 定义KYC字段标准;
- 打通“字段-证据句-时间戳”链路;
- 对低置信字段建立复核机制。
验收标准:不是“模型多准”,而是“结论能不能回看”。
第2阶段(31-60天):打通决策链
目标:让团队先把排序做对。
重点动作:
- 建立意向分层和跟进队列;
- 强制输出推荐理由与下一步动作;
- 用规则层兜底高风险边界。
验收标准:看采纳率、跟进命中率,而不是只看离线AUC。
第3阶段(61-90天):打通治理链
目标:让系统具备长期运营能力。
重点动作:
- 补齐日志、权限、版本追踪;
- 建立灰度发布与回滚预案;
- 输出跨团队SOP(产品、运营、质检、合规共用)。
验收标准:系统能稳定迭代,而不是一次性上线。
六、我踩过的4个坑(给同行避坑)
坑1:过早追求“全自动”
正确做法:先做“人机协同”,再逐步提高自动化比例。
坑2:过度迷信模型分数
正确做法:业务侧先看“建议动作是否可执行”。
坑3:只存结论,不存证据
正确做法:关键字段必须可回放到原始片段。
坑4:忽略银发客群沟通语境
正确做法:系统输出要可理解、可确认、可复述,而不是只追求术语正确。
七、写在最后

图4 银发客群长期趋势(公开信息整理)
我现在越来越确信:
保险AI项目的核心竞争力,不是“把模型接进来”,而是“把模型变成组织能力”。
而组织能力最小闭环就是三件事:
- 结论可解释;
- 过程可追溯;
- 系统可交付。
这三件事做对了,模型升级会越来越轻松;
这三件事做不对,再好的Demo也很难撑过生产周期。
如果你也在做保险AI,欢迎交流你现在最卡的一步:
是数据链路、业务采纳,还是合规治理?
参考资料(公开信息)
McKinsey(2024-11-20)
https://www.mckinsey.com/industries/financial-services/our-insights/insurance-blog/the-potential-of-gen-ai-in-insurance-six-traits-of-frontrunners
Accenture(2025)
https://www.accenture.com/cr-en/insights/insurance/underwriting-rewritten
Capgemini《World Life Insurance Report 2025》
https://www.capgemini.com/insights/research-library/world-life-insurance-report-2025/
EU AI Act 官方页
https://digital-strategy.ec.europa.eu/en/policies/regulatory-framework-ai
EIOPA(2025-08-06)
https://www.eiopa.europa.eu/eiopa-publishes-opinion-ai-governance-and-risk-management-2025-08-06_en
NAIC(2023-12-04)
https://content.naic.org/article/naic-members-approve-model-bulletin-use-ai-insurers
WHO(2025-10-01)
https://www.who.int/news-room/fact-sheets/detail/ageing-and-health
图片与数据来源说明
配图为Pexels示意图与依据公开数据制作的图表
本文由 @Vvictor.ON 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


