
 起点课堂会员权益
起点课堂会员权益A/B 测试 VS 灰度,目的大不同
AB测试与灰度测试在产品迭代中常被混淆,但它们的设计初衷和应用场景截然不同。本文用猫咪食堂的生动类比,清晰拆解两种测试方法的本质差异:AB测试是让同批猫同时品尝A/B碗猫粮的数据决策实验,而灰度测试则是新猫粮从1只猫到1000只猫的分批试吃计划。掌握这两种测试的正确使用姿势,才能避免产品迭代中的致命陷阱。

产品经理们,你有没有经历过这种场景?
运营总监:“这个新首页方案,我们做个AB测试,看哪个转化率高。”
你:“先灰度1%的用户测试下?”
运营总监:“可以,就是那个意思。”
有人听到这儿就懵了:到底是用AB测试,还是灰度发布?它们是一回事吗?
今天就给你彻底讲清楚。
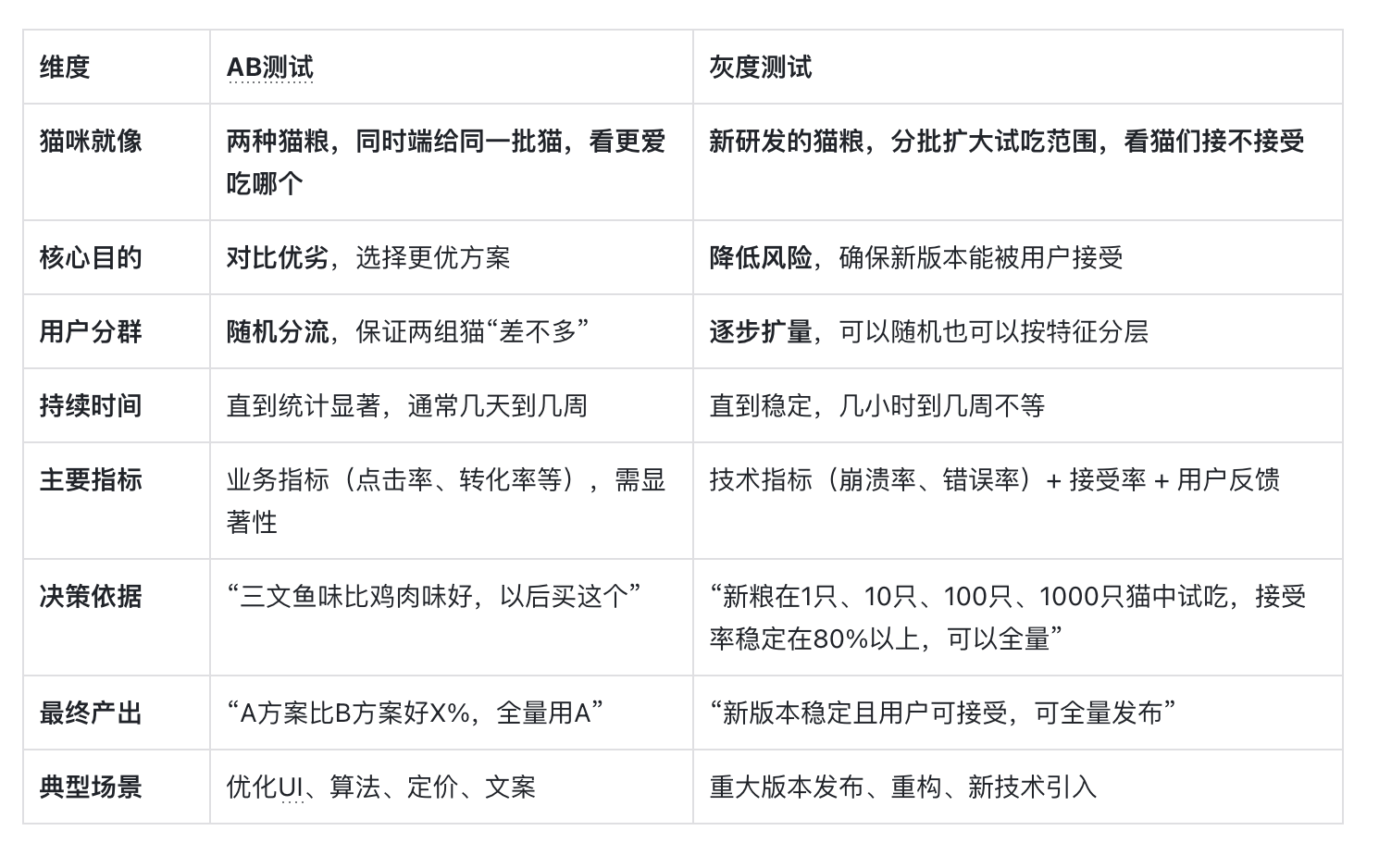
虽然它们都涉及“只给一部分用户看”,但核心目的、方法论、评估标准截然不同。
用一个猫咪的案例,你就能一辈子都记住。
AB测试:是猫咪食堂的科学实验。你同时摆出A碗(三文鱼味)和B碗(鸡肉味),看同一批猫更爱吃哪个。结果是“三文鱼味胜出,以后就买这个”。
灰度测试:是新猫粮的“分批试吃”计划。你研发了一款全新口味的猫粮(就像“金枪鱼松露味”),但不确定猫们喜不喜欢。
于是你先找自己家的1只猫试吃,没问题;再找邻居家的2只猫试吃,也没问题;再找小区里的10只流浪猫试吃;再扩大到隔壁小区的100只猫……逐步扩大试吃范围,确认不同群体都接受后,才正式推向所有猫。
AB测试——用数据做“猫粮选择题”
定义:AB测试(也叫分流测试、对比实验)是一种将用户随机分为两组(或多组),分别展示不同版本(A组为对照组/原方案,B组为实验组/新方案),通过统计方法判断哪个版本在核心指标上表现更优的决策方法。
产品经理的核心目的:验证假设,做出“哪种方案更好”的数据驱动决策。
- 新按钮颜色是否让更多人点击了“购买”?
- 新推荐算法是否让人在App里多刷了几分钟?
- 新定价策略是否让更多人付费了?
举例:你同时端出A碗:三文鱼味猫粮和B碗:鸡肉味猫粮,让同一批试吃猫同时品尝。观察它们先吃哪个、吃得多、吃完还舔碗的是哪个。
第二天换一下左右位置,排除“猫就是习惯吃左边那碗”的干扰。
连续测试一周,发现三文鱼味每次都吃得更干净。
结论:三文鱼味胜出,以后就买这个。
关键特征:
- 随机分流:用户被随机分配到A组或B组,保证两组“猫”在统计学上是同一群猫(年龄、品种、挑食程度相似),排除其他因素干扰。
- 同时运行:两组方案在同一时间段内运行,避免“今天猫心情好”这种时间效应影响结果。
- 指标明确:事先定义好成功指标(如点击率、转化率),并设定统计显著性水平。
- 结果导向:根据实验结果,决定全量上线哪个方案。
常见误区:
- 只试了3只猫就下结论:你家3只猫都爱吃鸡肉味,不代表全世界猫都爱吃鸡肉味。样本量太小,结果不可信。
- 只盯着“第一口”:猫第一口选了鸡肉味,但吃完就跑了;三文鱼味虽然第二口才吃,但整碗舔光。只看短期指标会误判。
- 忽略“挑食猫”:新猫粮在整体猫群中表现一般,但在“挑食猫”群体中表现极好。需要把用户进行分层分析,不能一刀切。
灰度测试——新猫粮的“分批试吃”计划
定义:灰度测试(也称灰度发布、增量发布)是一种逐步扩大用户范围上线新功能的方式,先对极小部分用户开放,观察稳定性、用户反馈、核心指标变化,没问题再逐步扩大范围,直到全量。
产品经理的核心目的:
降低风险,确保新功能能被用户接受,而不是一次性“吓跑”所有人。
- 新功能有没有隐藏的bug?
- 用户喜不喜欢?
- 有没有人强烈反对?
- 系统能不能扛住?
举例:你研发了一款全新口味的猫粮(就像“金枪鱼松露味”),但你不知道猫们喜不喜欢。直接推向所有猫?万一猫都不吃,你就亏大了。
所以你制定了分批试吃计划:
- 第1批:先找自己家的1只猫试吃。观察:吃不吃?有没有拉肚子?吃完还想要吗?——猫吃得很香。✅
- 第2批:扩大到邻居家的2只猫。它们也吃得很香。✅
- 第3批:扩大到小区里的10只流浪猫。其中8只吃得很香,2只闻了闻走开了。你记下来:可能有个别猫不喜欢。
- 第4批:扩大到隔壁小区的100只猫。发现有15只不喜欢,但整体接受率85%。你判断:可以接受。
- 第5批:扩大到全市的1000只猫。接受率稳定在82%,没有出现大规模拒食或不良反应。✅
- 最终:正式推向全国所有猫猫。
在这个过程中,你观察的不仅是“吃不吃”,还有:
- 有没有猫吃了拉肚子?(系统稳定性)
- 有没有猫吃了还想要?(用户满意度、复购意愿)
- 有没有猫在网上发帖骂这个新粮?(舆情监控)
不同大小的功能更新,灰度的“节奏”不同:
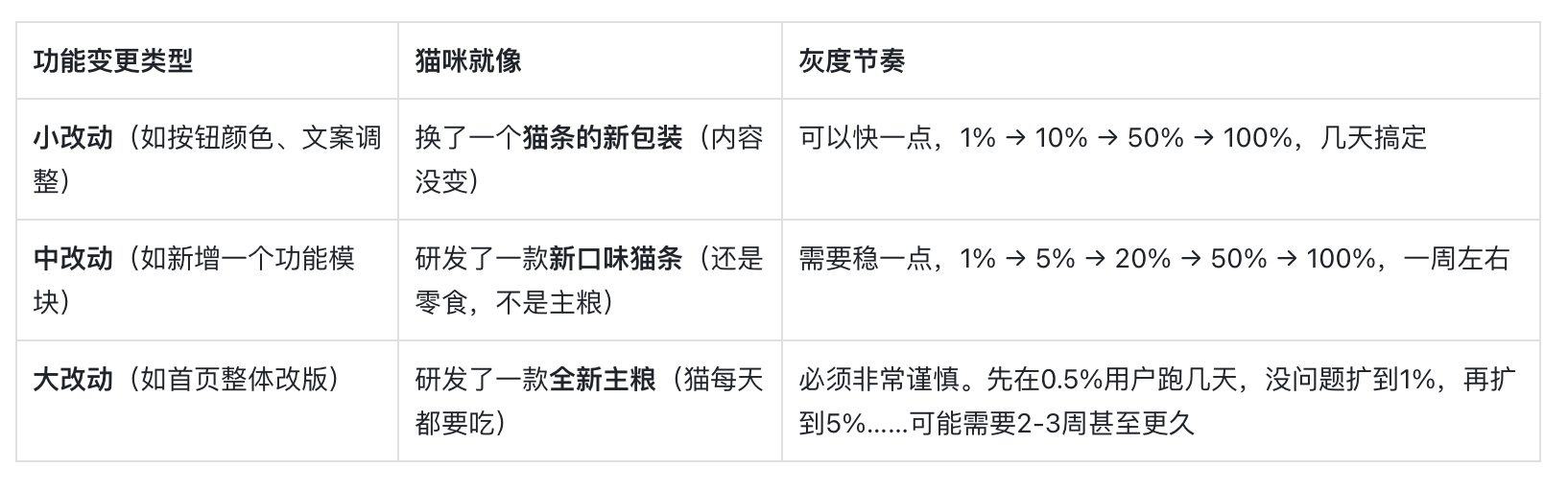
关键特征:
- 逐步扩大范围:从极小比例开始(1%的猫先试吃),验证没问题后,扩大到更大范围的猫。
- 关注接受度与稳定性:主要监控接受率、崩溃率、错误率、用户反馈、核心指标异常波动。目的是发现“问题”,而非“对比优劣”。
- 可快速回滚:一旦发现问题(就像某批次猫吃了集体拉肚子),立即停止扩大,甚至退回到上一阶段,影响范围可控。
- 不同改动不同节奏:功能变更越大、越核心,灰度周期越长,放量阶梯越细。
常见误区:
- 在灰度期做AB测试的结论:第一批1只猫试吃新粮后吃得很香,不代表所有猫都喜欢。可能你家猫本来就是“垃圾桶胃”。不能拿灰度数据当AB测试结论。
- 放量太快:从1只猫直接跳到1000只猫,如果新粮有问题,1000只猫同时拒食就惨了。
- 忽略“不同猫的差异”:橘猫爱吃的不代表布偶猫也爱吃。灰度时要考虑覆盖不同品种、不同年龄、不同饮食习惯的猫,才能全面评估。
深度对比——一张表看懂所有差异
实战组合——产品经理的一天
在实际工作中,AB测试和灰度测试常常组合使用,但顺序和目的不同。
场景1:优化首页详情页(已有功能)
先做AB测试,验证新详情页是否真的比旧的好。实验结果证明新页面转化率高。
然后,将新页面灰度发布,先放5%的用户,观察有没有兼容性问题、加载慢不慢,没问题逐步扩到全量。
场景2:上线“AI智能搜索”功能(全新功能)
步骤:先灰度发布,因为功能全新,用户接受度未知。放1%的猫,监控:
- 用户有没有用?(功能使用率)
- 用户有没有骂?(用户反馈、差评率)
- app有没有bug?(崩溃率、错误率)
稳定后:如果想进一步优化,可以在灰度用户中再做AB测试,就像测试不同的引导文案。
场景3:首页整体改版(大改动)
步骤:这堪称研发新主粮级别的改动,因为所有用户都会被影响,所以灰度节奏要非常保守:
- 第1阶段(0.5%用户,3天):监控崩溃率、加载速度、用户反馈。如果差评率飙升,立即回滚。
- 第2阶段(1%用户,3天):继续监控,同时观察核心业务指标是否有异常波动。
- 第3阶段(5%用户,5天):如果一切正常,扩大范围,开始收集用户行为数据。
- 第4阶段(20%用户,5天):确认无问题。
- 第5阶段(50%用户,5天):最后确认。
- 第6阶段(100%):全量上线。
为什么“灰度”不能替代“AB”?——兼谈两者的本质区别
很多老板会问:“既然我们灰度放了10%的猫,数据显示它们吃新粮吃得很香,为什么不直接全换?”
这里有个致命陷阱:灰度告诉你“这批猫接受”,但没告诉你“新粮是不是比旧粮好”。
举个真实例子:
某猫粮电商测试新首页,灰度10%的猫,发现点击率提升了3%。团队很高兴,准备全量。
但产品经理坚持做AB测试,结果全量后发现点击率反而下降了1%。
为什么?
因为灰度期间恰逢“国际爱猫日”,猫主人们本来就爱买猫粮;同时灰度用户是随机选中的,但样本量太小,刚好选中了一批“本来就爱买猫粮”的猫。
AB测试通过更长时间、更严谨的分流和统计检验,排除了这些干扰,给出了真实的结论。
AB测试的核心价值就在于“因果推断”——它能告诉你,这个改动真的让猫更爱吃了,而不是因为今天刚好是爱猫日。
灰度测试的核心价值是“风险控制”——它能保证新猫粮上线时,不会因为一个隐藏的“导致猫拉肚子”的问题,让大量猫受害。
结语:它们是战友,不是替代品
AB测试帮你回答“哪种猫粮猫更爱吃”,灰度测试帮你回答“新猫粮分批试吃后,猫们能不能接受”。
优秀的产品喵,会把两者结合成一套完整的发布流程:
- 实验阶段:用AB测试筛选出最优方案(哪种猫粮最好吃)。
- 验证阶段:用灰度测试验证方案的接受度(新猫粮分批试吃,猫们喜不喜欢)。
- 发布阶段:全量上线,并持续监控。
下次运营总监再说“先灰度一下当AB测试”时,你可以优雅地提问:“我们是想验证哪种设计更好,还是想确认新功能接不接受?如果是前者,建议我们走AB测试流程;如果是后者,那就灰度。”
两者都用,才是真正的产品高手。
(注:本文基于行业通用实践和个人养猫经验梳理。如有不准确之处,欢迎评论区喵一声讨论。)
本文由 @陆地燃烧 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


