
 起点课堂会员权益
起点课堂会员权益DeepSeek正在内测多模态
DeepSeek的「识图模式」内测曝光,多模态能力即将迎来关键突破。从流出的测试案例来看,这款AI不仅能精准识别画面中的主体对象、细节与空间关系,还展现出罕见的自我校验能力。若视觉模块如期上线,将彻底改变DeepSeek在Agent时代的竞争格局——这不仅是功能补全,更是获取AI基建入场券的战略动作。

刚刚,有群友丢出一张DeepSeek官网的截图,不是Image2生成,是真的截图。
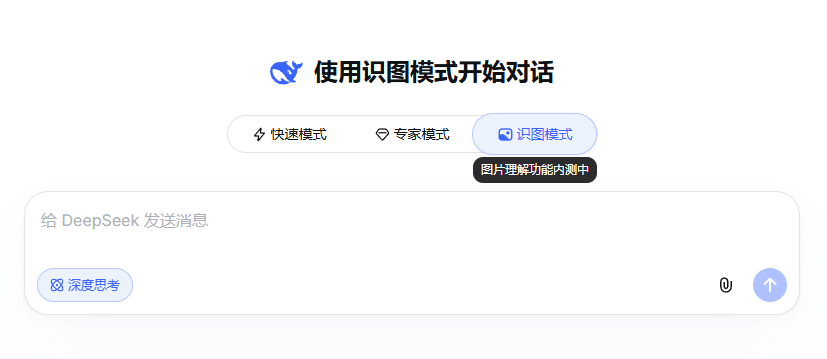
信息不多,但很关键,DeepSeek正在内测「识图模式」。注意,这不是OCR文字识别,而是真正的视觉理解。
从目前流出的体验case来看,它不仅能“看见”,还能“理解”。
画面主体对象、位置关系、肤色与着装细节、光影结构,甚至整体氛围,都可以被DeepSeek拆解分析。更重要的是,它还带有一定的反思能力——不只是给答案,而是会对自己的判断进行校验。

case链接:https://chat.deepseek.com/share/ablc57vmv2ompm3vy6
再往前串一下时间线,就更有意思了。
昨天,DeepSeek多模态团队研究员@Xiaokang Chen 在 X 上发了一句:“Soon, we see you. 👀”。
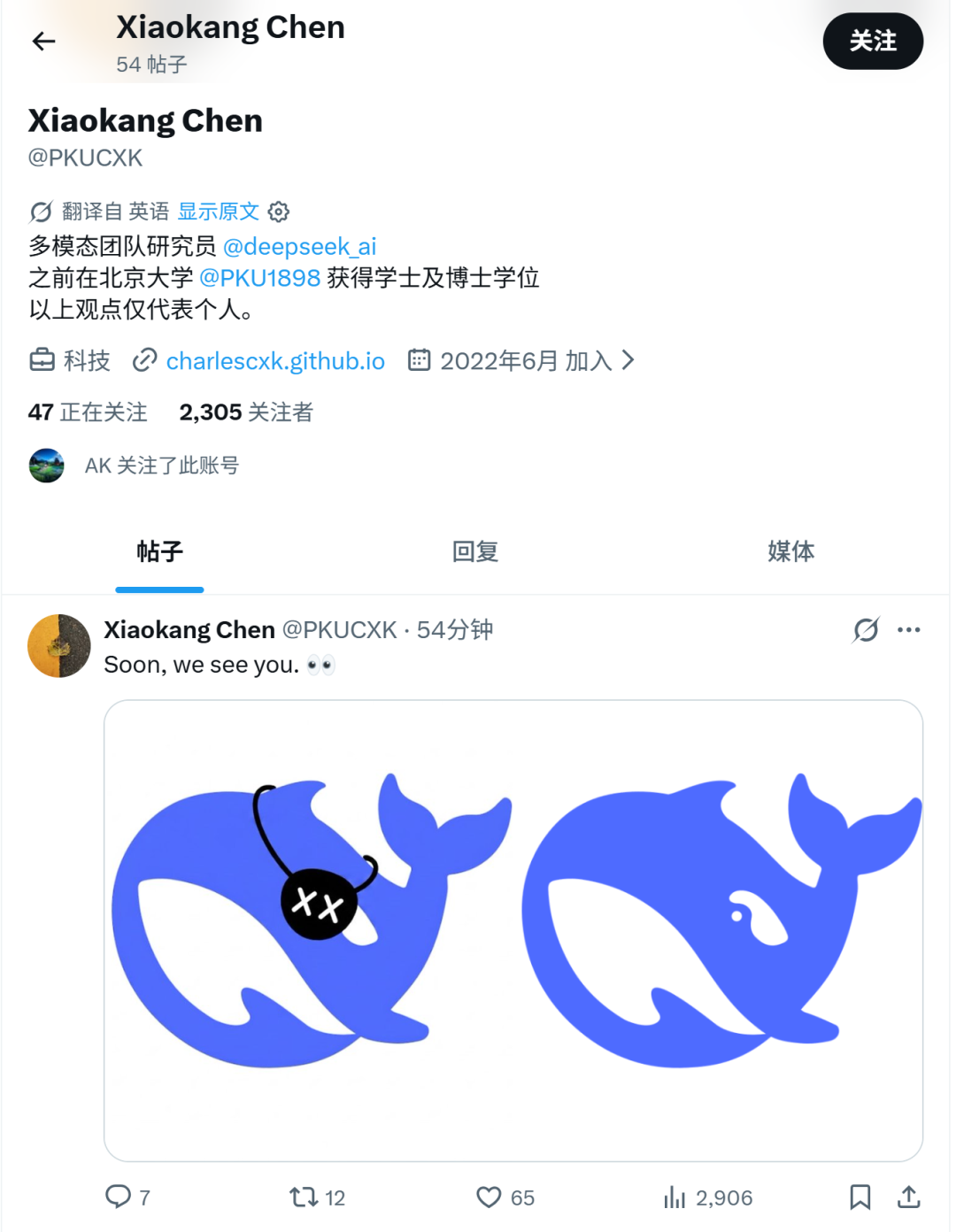
但这条动态很快又被删除。
结合这两条线索来看,一个相对清晰的判断是:DeepSeek的多模态能力,很有可能会在五一前上线。
如果这个节奏成立,那意义其实不小。
因为在过去很长一段时间里,多模态一直DeepSeek最明显的一块短板。因为先天能力的缺失,它在很多场景上始终落后于一线模型。
此前,我们已对DeepSeek V4做过多篇横评,结论很直接:DeepSeek V4的1M上下文能力很强,但一旦进入视觉维度,就会出现明显断层。
如果这次视觉理解能够补齐短板,那DeepSeek的使用场景将会明显丰富。
更关键的是,这不是一个锦上添花的功能。
在Agent越来越普及的今天,“看懂世界”的能力,正在变成基础设施。没有视觉,多数真实场景都无法闭环。
所以,这一波,不只是补短板,更像是补齐入场券。
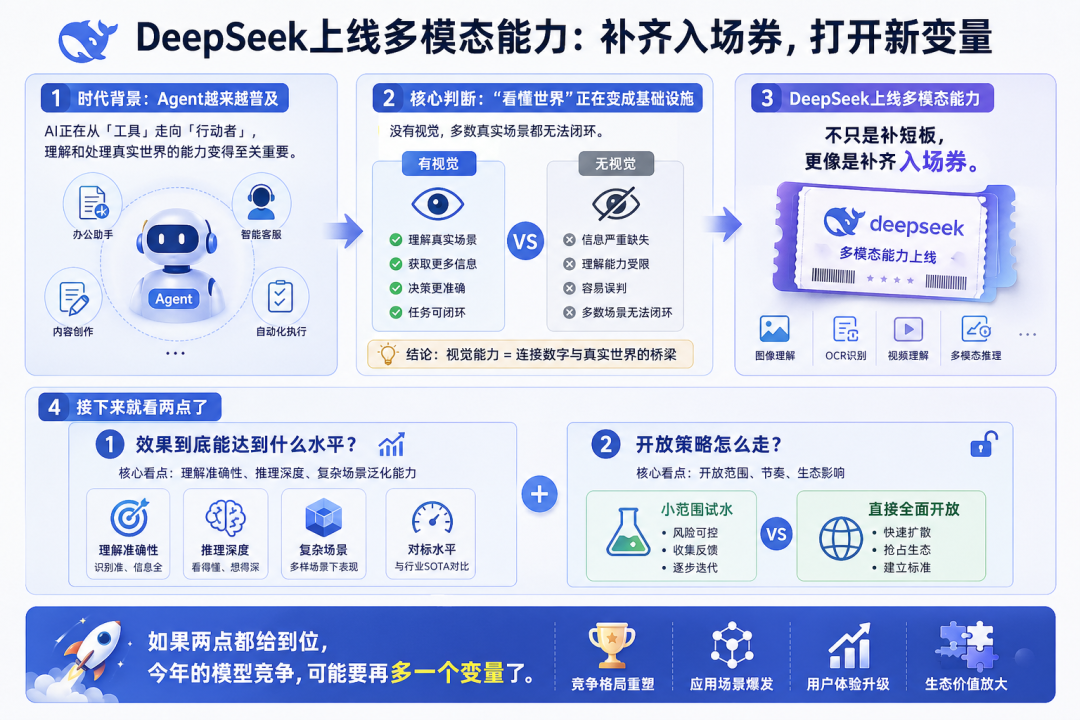
接下来就看两点了:
一是效果到底能达到什么水平;
二是开放策略,是小范围试水,还是直接全面开放。
如果两点都给到位,那今年的模型竞争,可能要再多一个变量了。
本文由人人都是产品经理作者【沃垠AI】,微信公众号:【沃垠AI】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。






- 目前还没评论,等你发挥!


