
 起点课堂会员权益
起点课堂会员权益实测 mimo-v2.5-pro:它适合做什么,不适合做什么
mimo-v2.5-pro在贴近产品落地的任务中展现了怎样的实力?评测显示,它擅长写作、逻辑推理和框架搭建,但在设计交付、深入研究和应用开发等需要真实产出的领域仍有局限。本文将深入剖析其能力边界,并给出三层使用建议,帮助团队最大化利用这款AI工具的价值。

这是一篇关于 mimo-v2.5-pro 的能力评测,主要看它在贴近产品落地的任务上表现如何。
先说结论:它很会写、会拆、会解释,但还不能替代工具链本身。 当草稿机、原型机、解释器很好用;要它独立交付设计、研究和工程,就会高估它。
一、这次评测怎么做的
这次评测用的是LLM-as-judge的方式,打分标准是简单的DCG 0–4(0 没用 / 1 难用 / 2 有点用 / 3 可用 / 4 好用)。
但这里有个我特意做的处理:原始题里有不少”纯文本解题型”方向,比如人文、编程、数学、信息抽取,这类任务模型分数普遍偏高,容易把整体观感拉上去,却不太能反映产品真正会踩坑的地方。所以我把这四类去掉了,只保留 31 道更贴近产品落地的样本——设计、研究、应用开发、写作、角色扮演、逻辑推理和科学问答。
目的很简单:不看它”会不会解题”,而看它在真实产品链路里,到底能干到哪一步。
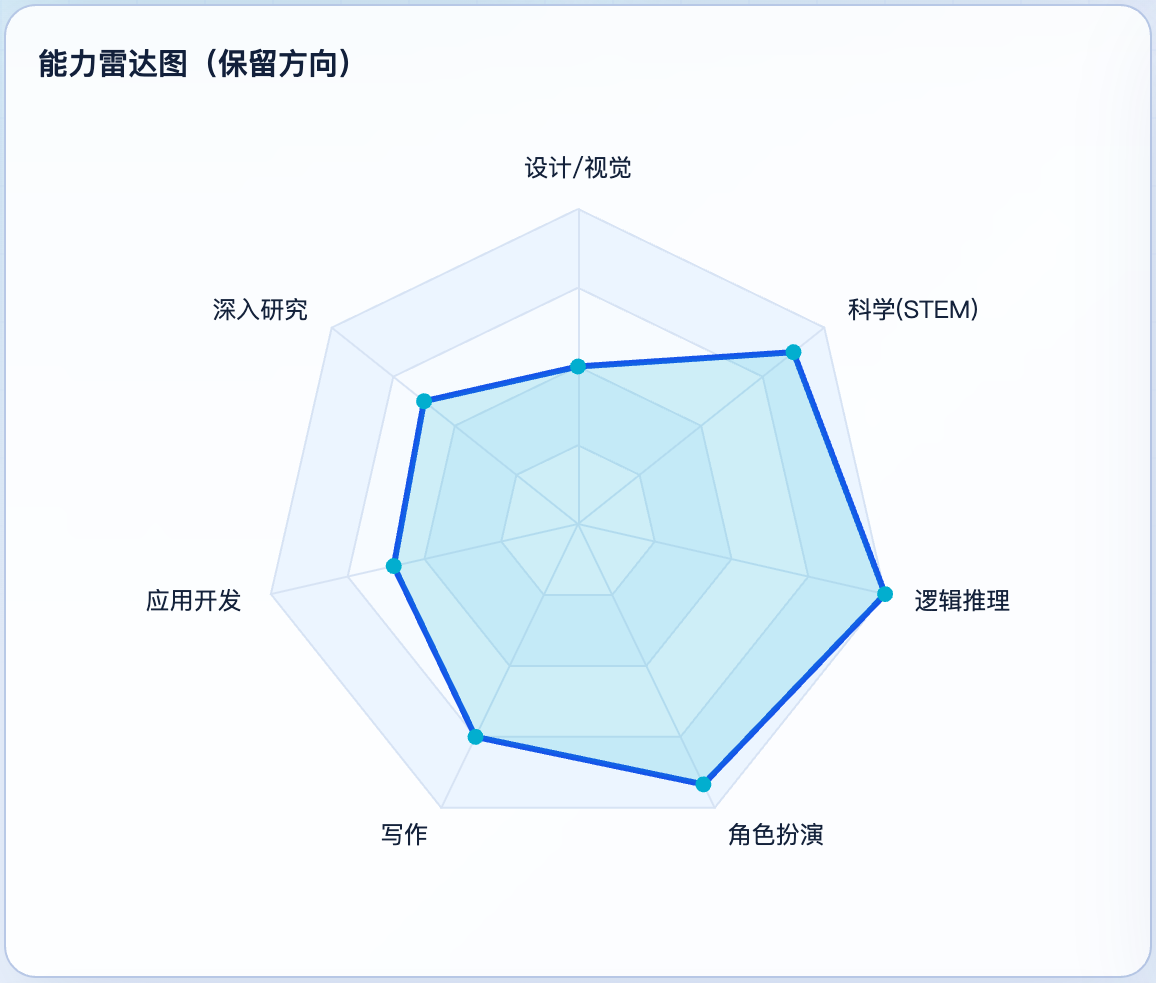
保留后的31题,整体平均DCG是 2.77 / 4,大致落在”有点用”和”可用”之间。这个分数其实不难看,但它也提醒我们:把它当成能独立交付的工具来用,落差会很明显。
二、评测看了哪些方向
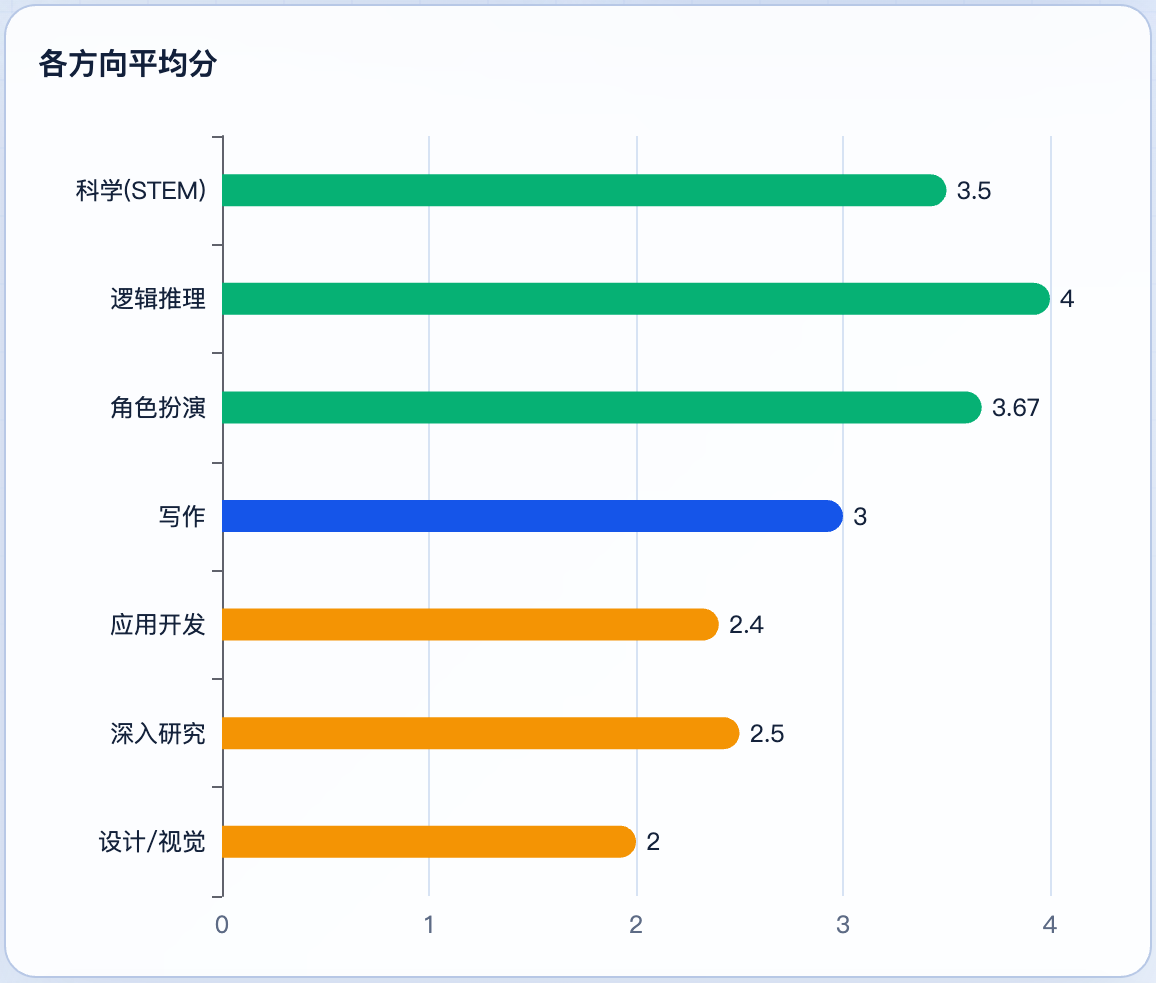
这张图最重要的信息不是”分高分低”而是:它不是平均弱,而是能力分层非常明显。 越靠近”纯文本、纯逻辑、纯结构”的任务,它越稳(逻辑推理 4.0、角色扮演 3.67);越要求”真实产物”或”实时证据”,分数掉得越快(设计 2.0、应用开发 2.4)。
再看一下分数档位的分布,规律就更清楚了:
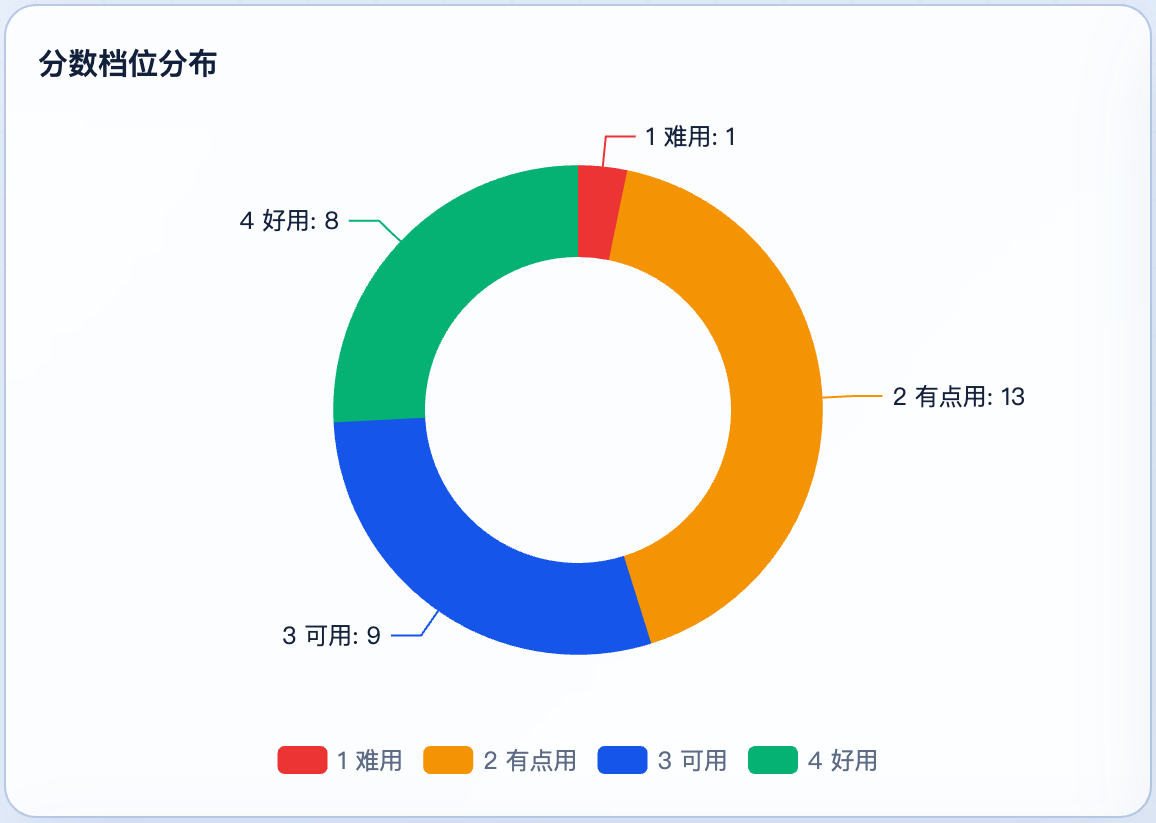
重点落在”有点用(13 题)”和”可用(9 题)”,”好用”有 8 题,”难用”只有 1 题,”没用”是 0 题。换句话说:它几乎不会乱来,但也很少给你惊艳。 这恰恰是一个适合做草稿、不适合直接交付的模型该有的形状。
三、Mimo的能力和边界在哪
能力:
写作 / 角色扮演:进入语气快,改写精准,多语言、角色口吻都比较自然,初稿、润色、客服话术、活动脚本基本可以放心交给它。
逻辑推理 / 科学问答:赛跑排名、家庭关系、停车位谜题这类答案可自洽、推理路径清楚的任务,它能给出正确结论并讲清易错点。
搭框架的能力:研究提纲、竞品分析维度、设计 brief、页面交互逻辑,它都能给出读起来不错的结构化初稿。
边界:
设计/视觉:能写出完整的视觉规范和设计 brief,但用户要的是图片、表情包、IP 形象,它最终交付的是文字说明——能写 brief,不能交图。
深入研究:框架可读,但需要联网搜索、实时数据、出处核验时,它没有真正完成证据采集——骨架能搭,研究闭环做不了。
应用开发:纯前端、规则明确的小工具能做出比较完整的单文件 Demo;一旦涉及后端、数据库、真实模型调用或实时检索,往往只剩界面和示意逻辑,有些答案更像一份优秀 PRD,而不是可运行产品。
写作的硬约束:遇到非常硬的形式约束(比如每句首字拼音要满足特定规则),它可能用看似聪明、其实并不达标的方式绕过去。
问题到底集中在哪?看这张标签图最直接:
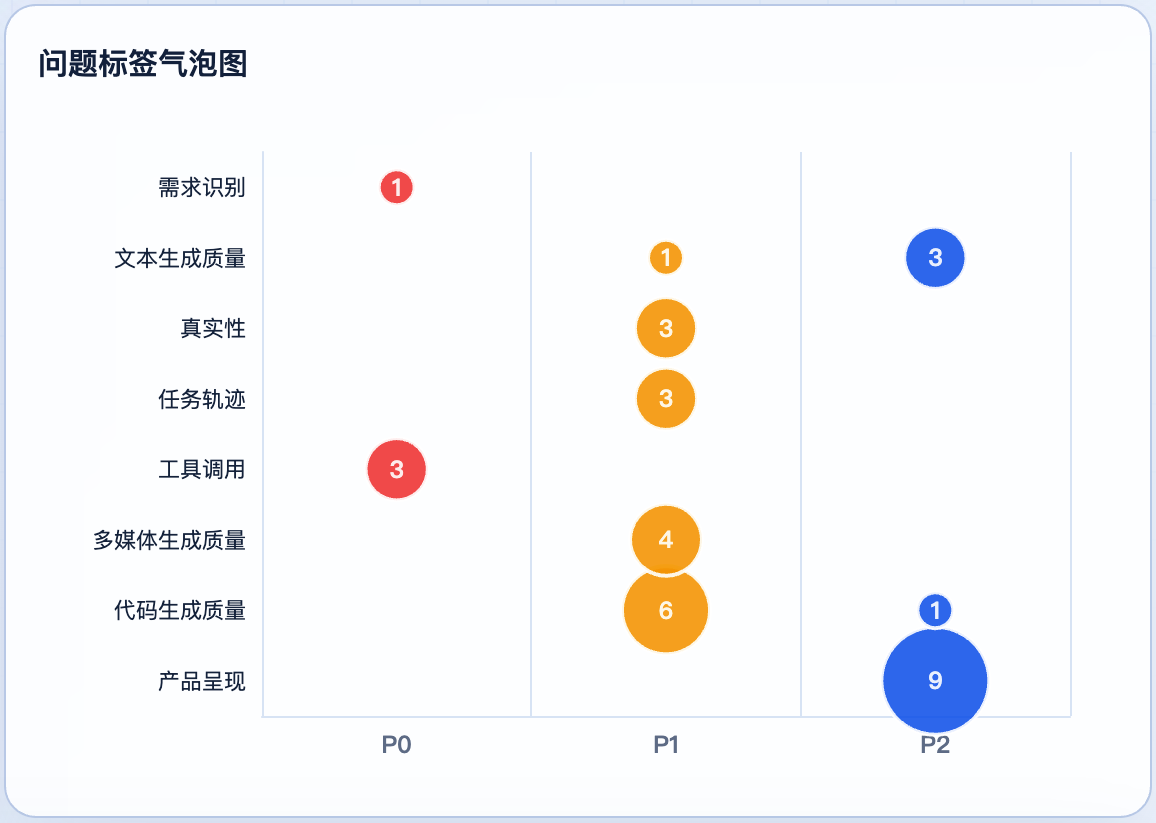
最值得警惕的是 4 个 P0 级问题,全部落在”工具调用”和”需求识别”上。而出现最多的 P2 问题是”产品呈现”——也就是它习惯性地把”做一个东西”变成”描述应该怎么做”。
如果把这些 case 提炼成三条边界:
1. 没有真实工具链时,它只能给方案,不能交付结果。 出图、搜索、后端、模型预测,缺了真实工具接入,它最多给到设计稿说明、研究框架或代码雏形。
2.它倾向于把复杂任务文本化。 让它做产品、查数据、出视觉,它经常转成”我来描述怎么做”。对前期讨论有用,但不能替代执行。
3. 它的诚实度不错,但诚实不等于可用。 不少回答会主动说明限制、不硬编数据,这是好事;可是”没胡说”和”能直接用”之间,仍然隔着一段距离。
四、真实场景怎么用:分三层就够清楚了
如果要把 mimo-v2.5-pro 放进真实工作流,我建议按三层来用,越往下越要谨慎。
第一层草稿层(大胆用,收益最高) 需求拆解、竞品分析框架、页面文案、客服话术、活动脚本。这一层它反应快、产出稳,是性价比最高的用法。
第二层原型层(快速验证想法,但别当工程交付) 让它生成可交互 Demo、流程图、规则说明、字段结构、页面布局,用来快速验证一个想法成不成立。但默认它只完成了”原型”,工程化的服务端、数据层、真实 API 还得工程师补齐。
第三层决策层(必须配工具 + 人工复核) 行业判断、投资分析、商业结论、产品路线。这一层一定要接入搜索、数据源和人工核验,否则风险很高——它给的是框架,不是依据。
简单的判断标准:任务停在”文本、结构、逻辑”里,他就是你最信任的伙伴就放心用;任务一旦需要”真实产物”或”实时证据”,就一定要给它配工具链,并保留人工兜底。
最后
mimo-v2.5-pro 不是一个能独立”从需求到上线”的产品 Agent,它更像一个反应很快的产品助理:能把混乱想法变成结构,把空白页面变成草稿,把讨论变成可推进的文档。
它的价值不在替代团队,而在缩短团队从”想不清楚”到”可以开始做”的时间。
用它写初稿、拆方案、做原型,它很有帮助;用它直接承担设计、研究和工程交付,就需要给它配上真实工具链,并守住人工这道关。









对用户来说,真正感受到价值不是“模型多聪明”,而是能不能减少等待时间、减少沟通成本。mimo-v2.5-pro在写草稿上能缩短“从想法到框架”的时间,这部分体验提升是实打实的。
风险在于团队可能高估它的“诚实”——它不编数据不代表数据准确。在需要引用数字或统计结论的任务里,即使它说“我不确定”,用户也可能忽略这种不确定性。
随着模型能力分层越来越明显,以后工具链的集成会变成关键。谁能把这种“能写框架”的模型和真实API、数据库打通,谁就能抢到产品落地的效率红利。