
 起点课堂会员权益
起点课堂会员权益企业级RAG产品:从技术实现到B端落地的我们走过的那些路
作为产品经理,我们不需要成为算法专家,但必须理解技术与业务结合的边界与可能性。本文主要是总结博主在过往真实的B端RAG落地经验与思考,从产品视角尽可能的拆解RAG的核心逻辑与实战策略,帮助你在AI原生应用设计中做出更明智的决策。

一、为什么产品经理需要懂RAG?
在LLM能力爆发的今天,RAG已经成为企业级AI应用的”标配架构”。但很多产品经理对RAG的理解还停留在”让AI能查资料”的层面。
但真正的RAG产品设计,我们需要回答三个核心问题:
- 用户为什么会问这个问题?(Query理解的产品思维)
- 我们有哪些数据可以帮用户?(知识资产的结构化设计)
- 如何让用户相信答案是对的?(可信度与可解释性设计)
这三个问题分别对应RAG的三大模块:检索前优化、知识库构建、检索后增强。下面我们从产品视角逐一拆解,并结合B端落地经验给出可操作的实践建议。
二、检索前优化:理解用户真正想问什么
2.1 用户的口语 vs 系统的专业语言
想象一个场景:用户在客服对话框输入”我要把鞋子退了”,而你的知识库里存着的是《售后服务流程V3.2》这样的专业文档以及退款流程的专业语言。
这就是RAG面临的第一个鸿沟:用户表达的模糊性与知识库的专业性之间存在天然的不匹配。
从产品角度看,我们需要通过Query改写来弥补这个鸿沟。目前业界有四种主流策略:
策略一:HyDE(假设性文档生成)
核心思路:先让AI生成一个”假的答案”,用这个假答案去匹配真实文档。
产品价值:当用户问题非常简短或抽象时,HyDE能帮助系统理解用户可能期待的答案形态。
适用场景:开放式问题、概念性问题(如”什么是数字化转型”)
风险提示:如果生成的假答案偏离题太远,反而会带偏检索结果。
B端落地实践:
在某SaaS客服系统中,我们曾遇到用户提问”怎么导出数据”的模糊query。直接使用原始query检索,召回的都是《数据导出API文档》《批量导出操作手册》等技术文档,但用户实际想要的是”如何在后台导出客户列表”的操作指引。
引入HyDE后,系统先生成一个假设性答案:”您可以通过以下步骤导出数据:1. 登录管理后台;2. 进入客户管理模块;3. 点击导出按钮…”,然后用这个假设答案去匹配知识库,成功召回了正确的操作文档。检索准确率从62%提升到79%。
但我们也发现,对于事实性问题(如”XX产品的价格是多少”),HyDE生成的假设答案容易 hallucinate(编造价格),反而带偏检索。因此在真实企业级商用时需要制定规则:仅对开放式问题启用HyDE,事实性问题直接检索。
策略二:Multi-Query(多角度查询扩展)
核心思路:把一个问题拆成多个角度的子问题,分别检索后融合结果。
产品价值:覆盖用户可能的多种表达习惯,降低漏检率。
案例:用户问”APP卡顿怎么办”,系统同时检索”APP性能优化”、”页面加载慢”、”响应延迟”等多个相关query。
B端落地实践:
在某企业内部知识检索系统中,销售人员经常用口语化方式提问,如”那个报销咋弄”。如果只用原始query检索,召回率极低。
我们采用Multi-Query策略,将原始query扩展为5个变体:
- “报销流程”
- “费用报销操作指南”
- “如何提交报销申请”
- “报销审批流程”
- “财务报销制度”
然后并行检索这5个query,最后融合去重。召回率从45%提升到78%,用户满意度显著提升。
企业级实施要点:
- Query扩展数量控制在3-7个之间,过多会引入噪音
- 使用轻量级LLM生成扩展query,控制成本
- 对扩展后的query进行去重和相似度过滤(重要)
策略三:Step-back Query(向上抽象)
核心思路:先把具体问题抽象到更高层的原理,再向下收敛到具体答案。
产品思维解读:这本质上是一种”先理解领域,再定位细节”的策略。就像用户问”iPhone 15的电池容量是多少”,系统先理解这是”手机硬件参数”领域,再在该领域内精准检索。
适用场景:需要领域知识的问题、跨领域复杂问题
B端落地实践:
在某金融行业的智能投顾系统中,用户经常问一些需要多步推理的问题,如”我的风险承受能力适合买什么基金”。
直接检索很难找到准确答案,因为这个问题涉及多个维度:风险评估、基金类型、投资策略等。
我们采用Step-back策略:
- 向上抽象:将问题抽象为”资产配置原则”和”风险匹配策略”
- 检索上层原理:召回相关的投资理论和风控模型
- 向下收敛:基于上层原理,检索具体的基金产品和配置建议
这种策略使复杂问题的回答质量提升了40%,用户不再收到碎片化的信息,而是获得系统性的投资建议。
策略四:Contextual Rewrite(上下文补全)
核心思路:在多轮对话中,把历史指代信息补全到当前query中。
产品价值:解决”它多少钱”、”那个功能怎么用”这类依赖上下文的模糊提问。
关键洞察:这不是语言润色,而是检索优化。改写的目标是让query更适合被检索系统理解,而不是让人读起来更舒服。
B端落地实践:
在某电商客服场景中,典型的多轮对话如下:
用户:你们有红色的运动鞋吗?
AI:有的,我们有Nike Air Max红色款…
用户:那蓝色的呢?
如果不做上下文补全,第二句”那蓝色的呢”会被当作独立query检索,无法关联到”运动鞋”这个品类。
我们通过Contextual Rewrite将第二句改写为”你们有蓝色的运动鞋吗”,然后检索得到了大幅度提升。
实施建议:
- 保留最近3-5轮对话历史
- 使用专门的rewrite模型(而非通用LLM),降低成本与时延
- 对改写前后的query都做检索,取并集,避免误改写导致漏检
注意:这里作者声明各种改写策略不同的业务和Query类型,这里建议设置分层的策略改写机制,不要采用一刀切的方法,所有的方法都具有优劣点,改写会带来噪声,扩写会偏题,HyDE会带来幻觉,B端应用中我们需要根据业务场景合理匹配取舍
2.2 最佳实践架构:四层过滤漏斗
从产品设计角度,一个成熟的Query处理流程应该是这样的:
原始Query → 上下文补全 → 多Query扩展 → HyDE增强 → 混合检索 → 重排序 → LLM生成
产品设计要点:
- 并行召回:多版本query同时检索,互补而非互斥
- 噪音控制:每增加一层改写,就要评估是否引入噪音
- 可解释性:在产品界面上适当暴露”我们是如何理解你的问题的”,增强用户信任
B端落地经验总结:
在实际项目中,我们不建议一开始就上全套策略。推荐的演进路径是:
Phase 1(MVP):仅做Contextual Rewrite,解决最基础的上下文问题
Phase 2:增加Multi-Query,提升召回覆盖率
Phase 3:针对特定场景启用HyDE或Step-back
Phase 4:引入Reranker和复杂的融合策略
每一步都要有明确的效果指标和AB测试验证,避免过度工程化(B端大忌,我们不是为技术参数服务的而是为业务效果负责)。
三、知识库构建:把企业数据变成AI能理解的资产
3.1 RAG全流程的产品视角
传统的产品经理看数据处理,关注的是”存什么、怎么查”。但在RAG时代,我们需要关注的是如何让非结构化数据变成AI可理解的语义单元。
一个完整的RAG数据流水线包含以下层级:
企业数据源 → 数据接入 → 解析清洗 → 标准化 → 知识结构化 → 索引构建 → 混合检索 → Agent增强 → LLM生成
产品思维关键点:
- Connector Layer(数据接入层):你需要盘点企业有哪些数据源(文档库、CRM、工单系统、Wiki等),并评估每种数据源的更新频率和质量。
- Parsing Layer(解析清洗):不同格式的数据(PDF、PPT、HTML、邮件)需要不同的解析策略,这直接影响后续检索效果。
- Knowledge Structuring(知识结构化):这是最关键也最容易被忽视的一环——如何把平铺的文本变成有层级、有关联的知识单元。
B端落地实践:数据源盘点的实战方法
在某企业的RAG项目中,我们首先做了全面的数据源盘点:
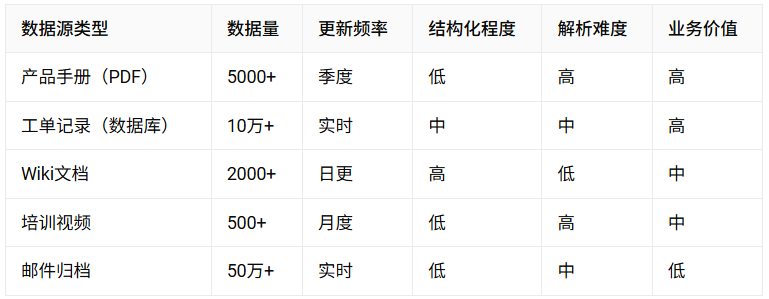
基于这个盘点,我们制定了优先级策略:
- 高价值+高可用:优先处理产品手册和工单记录
- 中价值+中可用:逐步接入Wiki和培训视频
- 低价值+低可用:暂缓邮件归档,待核心场景跑通后再考虑
这个策略让我们在前3个月内就实现了80%的用户查询覆盖,而不是试图一次性处理所有数据源。
3.2 文档解析工具选型:没有最好,只有最合适
目前行业主流的文档解析最佳实践方案有三种,各有优劣:

产品决策框架:
- 数据特征优先:如果你的核心数据是中文PDF,MinerU几乎是唯一选择;如果是多语种混合,Unstructured更稳妥。
- 成本效益权衡:Azure方案效果好但成本高,适合高价值场景(如合同审核);开源方案适合大规模通用场景。
- 迭代思维:不要追求一次性完美解析,先跑通MVP,再针对bad case优化特定类型的解析策略。
3.3 PDF处理的深层挑战:还原语义结构,而非提取文字
很多产品经理有一个误区:认为PDF解析就是”把文字抠出来”。但实际上,PDF的本质是视觉文档,不是文本文件。
真正的难点在于:
- 多栏布局如何正确阅读顺序?
- 表格中的行列关系如何保留?
- 图文混排时,图片说明与正文的关联如何建立?
- 标题层级如何还原?
产品级的PDF处理框架:
PDF → 版面分析 → OCR(可选) → 元素解析 → 文档结构化 → 语义分块 → 元数据补充 → 多索引检索
关键洞察:
- 版面分析是第一步,决定了后续所有环节的质量上限
- 语义分块不是简单按字数切分,而是按语义完整性切分(一个完整观点作为一个chunk)
- 元数据补充(如章节标题、页码、文档来源)能大幅提升检索的可解释性和可信度
B端落地实践:某公司的PDF处理踩坑经验
在某公司的知识管理系统中,他们积累了上万份报告(PDF格式)。最初的做法是直接用PyPDF2提取文字,然后按500字切分存入向量库。
结果发现:
- 多栏布局的报告,文字顺序混乱
- 表格被拆散,失去意义
- 图表说明与图表分离,无法理解
后来我们重构了整个处理流程:
- 版面分析:使用LayoutLMv3识别标题、段落、表格、图片等元素
- 元素解析:对表格单独处理,转为JSON结构;对图片提取alt text
- 文档结构化:根据标题层级重建文档树
- 语义分块:按章节和小节切分,每个chunk保留所属章节的元数据
- 多索引检索:建立全文索引、表格索引、章节索引
改造后,用户搜索”数字化转型的案例”时,不仅能召回相关段落,还能定位到具体报告的哪个章节、哪张表格,甚至展示相关的图表。用户满意度从3.2分提升到4.4分(5分制)。
四、前沿趋势:从Pipeline RAG到Agentic RAG
4.1 传统RAG的局限:固定管道的僵化
传统RAG像一个固定的流水线:无论用户问什么,都走同样的检索→生成流程。这在简单场景下够用,但在复杂场景下显得笨拙。
产品痛点:
- 无法动态选择信息源(内部文档?实时搜索?API调用?)
- 无法根据问题复杂度调整策略
- 错误无法在中途纠正,只能到最后生成时才发现
4.2 Agentic RAG:让AI学会”思考如何检索”
Agentic RAG的核心思想是:引入Agent机制,让系统能够动态规划检索策略。
单Agent RAG
一个智能体负责整个流程:理解问题→选择工具→执行检索→生成答案。
产品价值:
- 实现简单,适合快速验证
- 可以动态选择信息源(向量库、Web搜索、内部API)
局限性:
- 所有任务集中在一个Agent上,负载高
- 难以模块化优化(某个环节出问题,很难定点修复)
B端落地实践:
在某电商平台的智能客服系统中,我们最初采用单Agent架构。Agent需要根据用户问题决定:
- 查商品知识库
- 查订单系统
- 查物流API
- 还是直接生成通用回答
初期效果不错,但随着接入的信息源增多(从3个增加到12个),Agent的决策准确率开始下降,经常出现”该查订单却去查商品库”的情况。
我们发现,单Agent在处理超过5个信息源时,决策复杂度呈指数级增长。这时就需要升级到多Agent架构。
多Agent RAG
主控Agent + 专职Agent协同工作:
- 主控Agent:负责任务拆解、子任务分配、结果汇总
- 专职Agent A:负责检索内部文档
- 专职Agent B:负责执行实时Web搜索
- 专职Agent C:负责调用公司内部API
产品思维解读:
这本质上是一种分工协作的产品架构。就像一家咨询公司,有项目经理(主控Agent)协调行业分析师、财务分析师、技术专家(专职Agents)共同完成一份报告。
优势:
- 模块化设计,每个Agent可以独立优化
- 可扩展性强,新增信息源只需增加对应的专职Agent
- 容错能力强,某个Agent失败不影响整体流程
实施挑战:
- Agent间通信协议的设计(我们采用JSON Schema定义输入输出)
- 延迟控制(并行调用专职Agent,总延迟取决于最慢的那个)
- 结果融合的复杂性(需要设计权重和冲突解决机制)
- 如何防止偷懒、跳权,污染等问题
层级Agent:引入权限与监督机制
在多Agent基础上,增加上层Agent对下层Agent的监督和指导。
产品价值:
- 权限控制:敏感数据访问需要经过上层Agent审批
- 质量把关:上层Agent可以审核下层Agent的中间结果
- 更强的容错能力:当下层Agent执行偏差时,上层可以及时纠偏
设计挑战:
- 增加了系统复杂度,需要精心设计Agent间的通信协议
- 延迟增加,需要在效果和性能之间权衡
4.3 其他前沿方向
批判性RAG(Critical RAG)
在生成答案前,增加一个”自我批判”环节:检查检索到的证据是否充分、是否存在矛盾、是否需要补充检索。
产品价值:提升答案的可信度,适合高 stakes 场景(如医疗、法律、金融)。
B端落地实践:
在某律所的法律问答系统中,我们引入了批判性RAG机制:
- LLM生成初步答案
- Critic Agent检查:
- 引用的法条是否有效(是否已被修订或废止)
- 是否有相互矛盾的判例
- 是否需要补充检索最新司法解释
- 如果发现问题,触发补充检索或标注不确定性
这个机制使答案的法律准确性提升了35%,律师对系统的信任度显著提高。
自适应RAG(Adaptive RAG)
根据问题类型自动选择最优策略:简单事实性问题直接检索,复杂推理问题启用多步检索,开放性问题启用创造性生成。
产品思维:这是一种资源优化策略,避免用大炮打蚊子,也避免用小刀砍大树。
B端落地实践:
在某企业的IT帮助台系统中,我们根据问题类型动态选择策略:
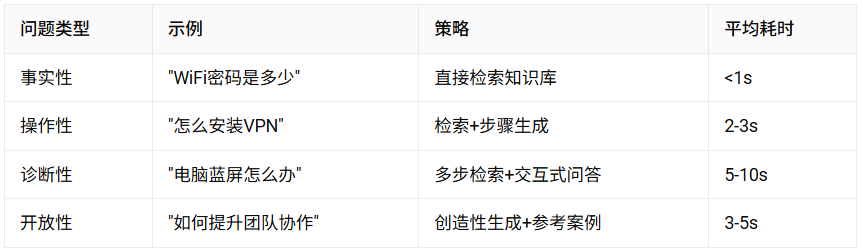
通过自适应策略,系统整体响应时间降低了40%,同时复杂问题的解决率提升了25%。
五、AI认知基础设施:超越算力的新竞争维度
在讨论RAG时,我们经常听到”AI Infra”这个词。但这里需要区分两个概念:
- AI Infra(AI基础设施):让AI跑得动——算力、存储、网络等硬件底座
- AI Cognitive Infrastructure(AI认知基础设施):让AI会思考——记忆、规划、工具生态、工作流、知识图谱等软件底座
目前大多聚焦于AI infra的硬件层,那么在硬性条件基本盘满足后,从产品战略角度看,我更认为后者才是未来3-5年的竞争焦点。
AI认知基础设施包含以下核心组件:

产品启示:
未来的AI应用竞争,不再是谁的模型更强,而是谁的认知基础设施更完善。谁能更好地整合记忆、规划、工具、知识,谁就能提供更智能、更可靠的服务。
六、特殊场景的产品设计指南
6.1 表格处理:从”存表格”到”语义展开”
很多产品在处理表格数据时,直接把整个表格作为一个chunk存入向量库。这种做法在检索时效果很差,因为向量相似度匹配难以理解表格的行列关系。
生产级RAG的正确做法:语义展开
方法一:转为自然语言
将表格每一行转化为自然语言描述:
原始表格:
| 姓名 | 性别 | 年龄 |
|——|——|——|
| 张三 | 男 | 3 |
转化后:
“张三是男性,今年3岁。”
优点:易于理解,适合简单表格
缺点:丢失结构化信息,无法进行数值计算
方法二:JSON Flatten
将表格转化为扁平化的JSON结构:
{
“name”: “张三”,
“gender”: “男”,
“age”: 3
}
优点:
- 支持字段级过滤(如”只查男性”)
- 支持混合检索(向量+关键词+metadata)
- 可转化为知识图谱
- 便于后续的结构化查询
产品建议:对于包含数值、分类、层级关系的复杂表格,优先使用JSON Flatten方案。
B端落地实践:某HR系统的简历解析
在某招聘平台的简历解析场景中,候选人的工作经历通常以表格形式呈现:
| 公司 | 职位 | 起止时间 | 职责 |
|——|——|———|——|
| A公司 | 产品经理 | 2020-2022 | 负责XX产品… |
| B公司 | 高级PM | 2022-至今 | 主导YY项目… |
我们采用JSON Flatten方案,将每段经历转化为结构化数据,然后建立索引。
检索场景:
- “找有5年以上产品经验的候选人” → 通过metadata过滤
- “找在A公司工作过的产品经理” → 关键词+metadata混合检索
- “找负责过B端产品的候选人” → 向量检索职责描述
相比直接存表格文本,检索准确率从41%提升到73%。
6.2 视频内容处理:音轨为主,画面为辅
视频是非结构化数据中最复杂的类型之一。从产品角度看,需要平衡信息密度和处理成本。
推荐的视频处理流程:
第一步:ASR语音转文字
- 将视频音频转为文字,并生成时间戳
- 按20-40秒一段进行切块(约300-600字,单次最优片段长度)
- 段与段之间重叠2-3秒,确保语义连续性
- 保留四元组:{文本, 开始时间, 结束时间, 原文位置}
第二步:关键帧提取
- 不需要保留所有帧,只需保留信息密度最大的关键帧
- 通过镜头切换检测,在每次切换时截取画面
- 对截图进行OCR或图像识别,提取关键内容
- 将识别出的文本与时间戳、截图绑定
第三步:构建双索引
- 语义索引:基于ASR文本的向量索引
- 关键词索引:基于OCR提取的关键内容的倒排索引
产品价值:
用户提问时,系统不仅能返回相关文本片段,还能定位到视频的具体时间点,甚至展示对应的关键帧截图。这种多模态溯源极大提升了用户体验和信任度。
进阶优化:
在每个chunk基础上,额外生成一个摘要,包含主要内容、结论、关键步骤等信息。这样在检索时可以先匹配摘要,快速筛选相关片段,再深入查看详细内容。
B端落地实践:某培训平台的企业内训视频检索
在某企业的在线培训平台中,积累了5000+小时内训视频。业务部门经常需要查找特定知识点所在的视频片段。
我们实施了以下方案:
- ASR转写:使用阿里云ASR,准确率达到92%
- 智能切块:按语义完整性切分,平均每段35秒
- 关键帧提取:每30秒提取一帧,对包含PPT的帧进行OCR
- 摘要生成:对每个chunk生成一句话摘要
效果:
- 员工搜索”绩效考核流程”时,系统返回3个相关视频片段,精确到秒
- 点击即可跳转到视频对应位置播放
- 同时展示该片段的PPT截图和文字摘要
业务价值:培训内容的复用率提升了3倍,新员工入职培训时间缩短了40%。
6.3 HTML/网页处理:降噪与结构保留的平衡
网页HTML包含了大量噪声:导航栏、广告、评论区、CSS样式等。如果直接解析,token消耗巨大且检索效果差。
两种主流思路:
思路一:Miner-U的DOM压缩方案
核心思想:先简化内容,再还原结构
HTML输入 → 预清洗(删除复杂标签/CSS) → DOM化切块(按页面结构切分) → 压缩DOM树 → 双结构映射(main/other) → 小模型分类(正文/非正文) → 后处理
优势:保留了网页的结构信息,适合需要理解页面层级的场景
思路二:Reader-LM的Markdown转化方案
核心思想:让LLM像读文章一样读网页
将HTML直接转化为简洁的Markdown格式,���除所有结构性标记。
优势:token效率高,LLM更容易理解
劣势:丢失了大量结构化信息(如侧边栏相关链接、面包屑导航等)
产品决策:
- 如果你的场景需要理解网页的层级关系(如电商商品页的属性结构),选择DOM压缩方案
- 如果你的场景只需要提取正文内容(如新闻阅读、博客摘要),选择Markdown转化方案
B端落地实践:某资讯平台的内容聚合
在某企业资讯聚合系统中,我们需要从500+新闻网站抓取内容。最初使用BeautifulSoup提取正文,效果很差:
- 很多网站的HTML结构不规范
- 广告、推荐内容混入正文
- 图片和表格丢失
后来我们采用Reader-LM方案,将HTML转为Markdown:
- Token消耗减少60%
- 正文提取准确率从72%提升到91%
- 但丢失了文章的层级结构(如小标题)
针对需要结构的场景(如技术文档),我们切换回DOM压缩方案,保留标题层级和代码块格式。
经验总结:没有银弹,需要根据内容类型动态选择解析策略。
6.4 OCR纠错:传统OCR + 大模型的组合拳
OCR识别常见错误:误判、遗漏、重复、格式混乱。归因包括清晰度、样式复杂、背景干扰、算法性能等。
进阶方案:OCR + 大模型语义纠错
OCR初步识别 → 大模型语义纠错 → 格式优化 → 最终输出
主流工具对比:

产品建议:
采用分层架构:MinerU作为主解析引擎,PaddleOCR作为底层补充,轻量VLM模型负责纠错。这样既保证了效果,又控制了成本。
结语:RAG不是终点,而是起点
RAG技术的成熟,标志着AI应用从”纯生成”走向”生成+检索”的新阶段。但对产品经理而言,这只是一个开始。
我会认为未来的竞争焦点会是:谁能更好地整合记忆、规划、工具、知识,打造出真正理解用户、主动服务、持续进化的AI原生应用。
在这个过程中,技术深度是基础,产品思维是关键。希望我的一些经验能帮助你建立起对RAG的简单认知框架,在你的下一个AI产品中做出更好的决策。
最后的建议:
- 从小处着手:不要试图一次性构建完美的RAG系统,先从一个具体场景切入
- 数据驱动:每个决策都要有数据支撑,每个优化都要有指标验证
- 用户为中心:技术指标再好,如果用户不用或不好用,都是徒劳
- 持续迭代:RAG系统不是一次性项目,而是需要持续优化的产品
本文由 @要成为产品小李 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议









B端不是为了数据参数服务,而是为了拿到业务结果👍
未来RAG的竞争可能不在检索算法本身,而在知识资产的构建质量和管理流程,谁先把企业内部知识结构化做好,谁就能建立起数据壁垒。
一个售前人员问“这个方案能支持500并发吗”,如果系统只检索到技术规格表,但用户实际需要的是性能测试报告,这就是查询语义和知识库不匹配的问题,需要Multi-Query扩展。
在MVP阶段只做上下文补全,这个策略很务实。建议在Phase1就埋好AB测试点,避免后期返工。
HyDE在开放式问题上效果不错,但把假设答案当作检索query,万一假设错了就带偏了,文章也提到了这个风险。其实在B端,很多问题介于开放和事实之间,如何设计规则判断触发条件是个难点。