
 起点课堂会员权益
起点课堂会员权益AI Agent 进入性价比时代:产品经理该如何重新选择大模型?
2026年6月30日,Anthropic 发布 Claude Sonnet 5;随后,Claude Fable 5 和 Mythos 5 在出口管制解除后恢复访问。单看这是一条模型更新新闻,但如果站在产品经理视角,它真正释放的信号是:AI Agent 的竞争正在从“谁能力最强”,转向“谁能以更低成本稳定完成任务”。

过去做 AI 产品,大家很容易盯着榜单、参数、上下文长度和最强模型。
但当 Sonnet 5 这类模型开始接近高端模型能力,同时价格更低、工具调用更强、可以执行更长链路任务时,产品经理要重新思考一个问题:模型选型到底是在选“智商”,还是在选“任务交付能力”?
不要只看最强模型,要看产品需要哪种执行层
AI 产品不是永远需要最强模型,而是需要一个能稳定承接核心任务的执行层。
在很多产品场景里,用户并不关心模型是不是行业第一。他们关心的是:任务能不能完成,结果能不能用,等待时间能不能接受,失败后有没有补救机制。比如一个销售助手,用户要的是自动整理客户信息、生成跟进邮件、更新 CRM;一个数据分析助手,用户要的是读懂指标变化、找到异常原因、给出下一步动作。这些任务未必每一步都需要最强推理模型,但需要模型能持续执行、调用工具、检查结果,并且不轻易中途停下来。
Sonnet 5 的意义就在这里。它不是简单地用“更强”来讲故事,而是把中端模型推向了 Agent 执行层:能规划、能用浏览器和终端、能跑更长任务,还能在一些任务上用更低成本接近高端模型表现。
对产品经理来说,这意味着模型选型不能再只问“哪个模型最好”,而要问“哪个模型最适合承接这个产品里的高频任务”。

模型成本不是 token 单价,而是单位任务成本
真正决定 AI 产品能否商业化的,不是模型单价,而是完成一次有效任务的总成本。
很多团队算模型成本,只看输入输出 token 价格。但在 Agent 产品里,这个算法会失真。因为一次任务往往包含多轮规划、工具调用、网页读取、代码执行、结果校验和失败重试。一个模型单价便宜,如果总是跑偏、反复重试、需要人工兜底,最后未必便宜。另一个模型单价更高,但一次就能完成任务,反而可能更适合关键场景。
更合理的公式应该是:
单位任务成本 = token 成本 + 工具调用成本 + 重试成本 + 人工审核成本 + 失败补救成本 + 用户等待成本。
这也是为什么 Sonnet 5 这类模型值得产品经理关注。它不是单纯便宜,而是试图在“能力接近高端模型”和“成本更低”之间找到平衡点。对于高频、标准化、可容错的任务,中端高性价比模型可能比顶级模型更适合作为默认选择。

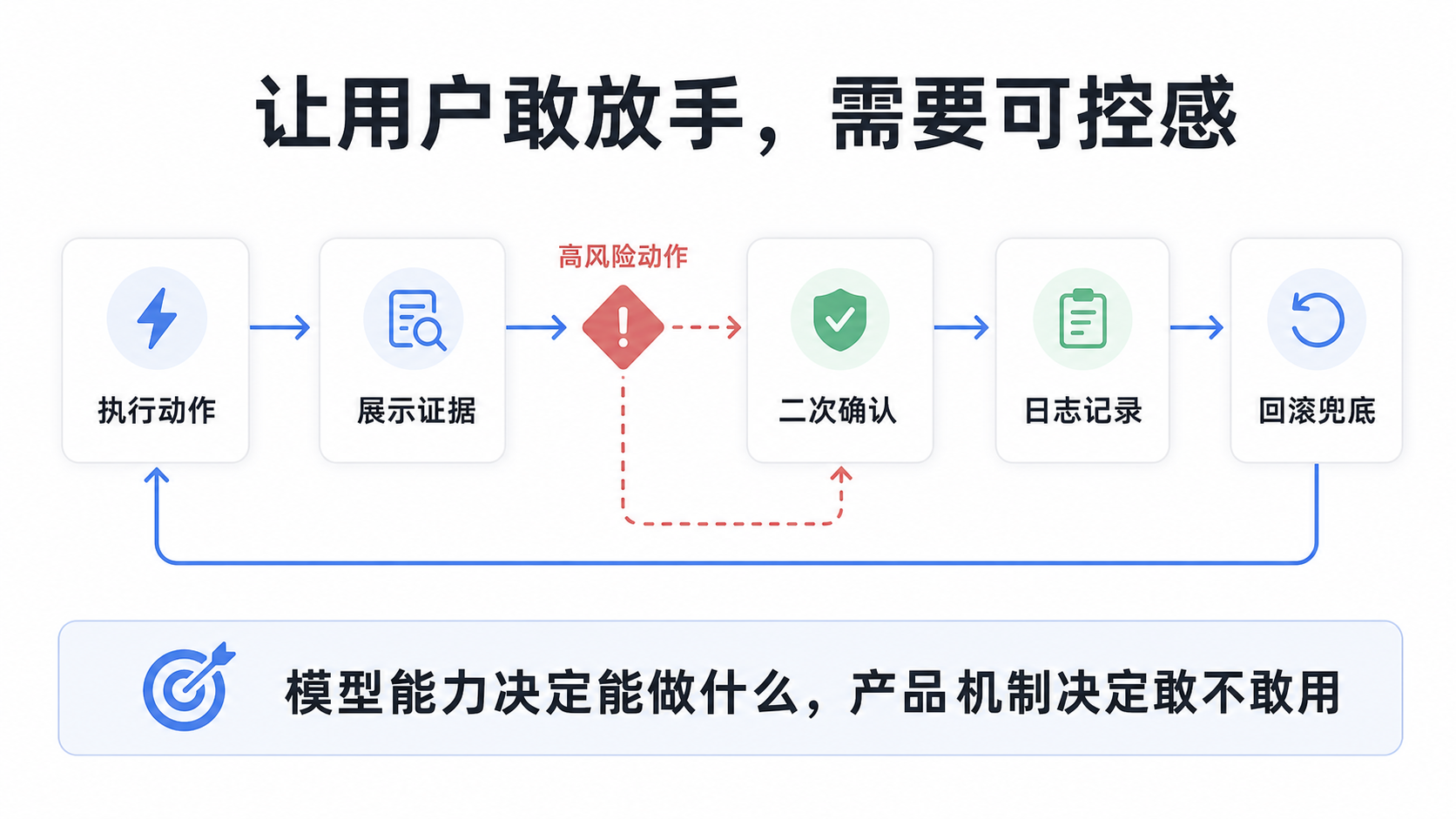
Agent 产品最难的不是让模型动起来,而是让用户敢放手
AI Agent 的产品难点,不只是自主执行,而是建立可控感。
用户当然希望 AI 能替自己完成任务。但一旦 AI 真的开始操作浏览器、调用终端、改代码、发邮件、更新系统,用户又会立刻担心:
- 它会不会删错文件?
- 会不会发错消息?
- 会不会把一个错误结论自动推进到业务流程里?
所以 Agent 产品的关键,不是让模型“更主动”就完了,而是要设计好边界。
- 哪些动作可以自动执行?
- 哪些动作必须二次确认?
- 哪些结果需要展示证据链?
- 哪些失败要自动回滚?
- 哪些高风险操作要交给更强模型或人工审核?
这也是产品经理比单纯技术选型更重要的地方。模型能力决定 Agent 能做什么,产品机制决定用户敢不敢让它做。
未来不是一个模型包打天下,而是多模型分层调度
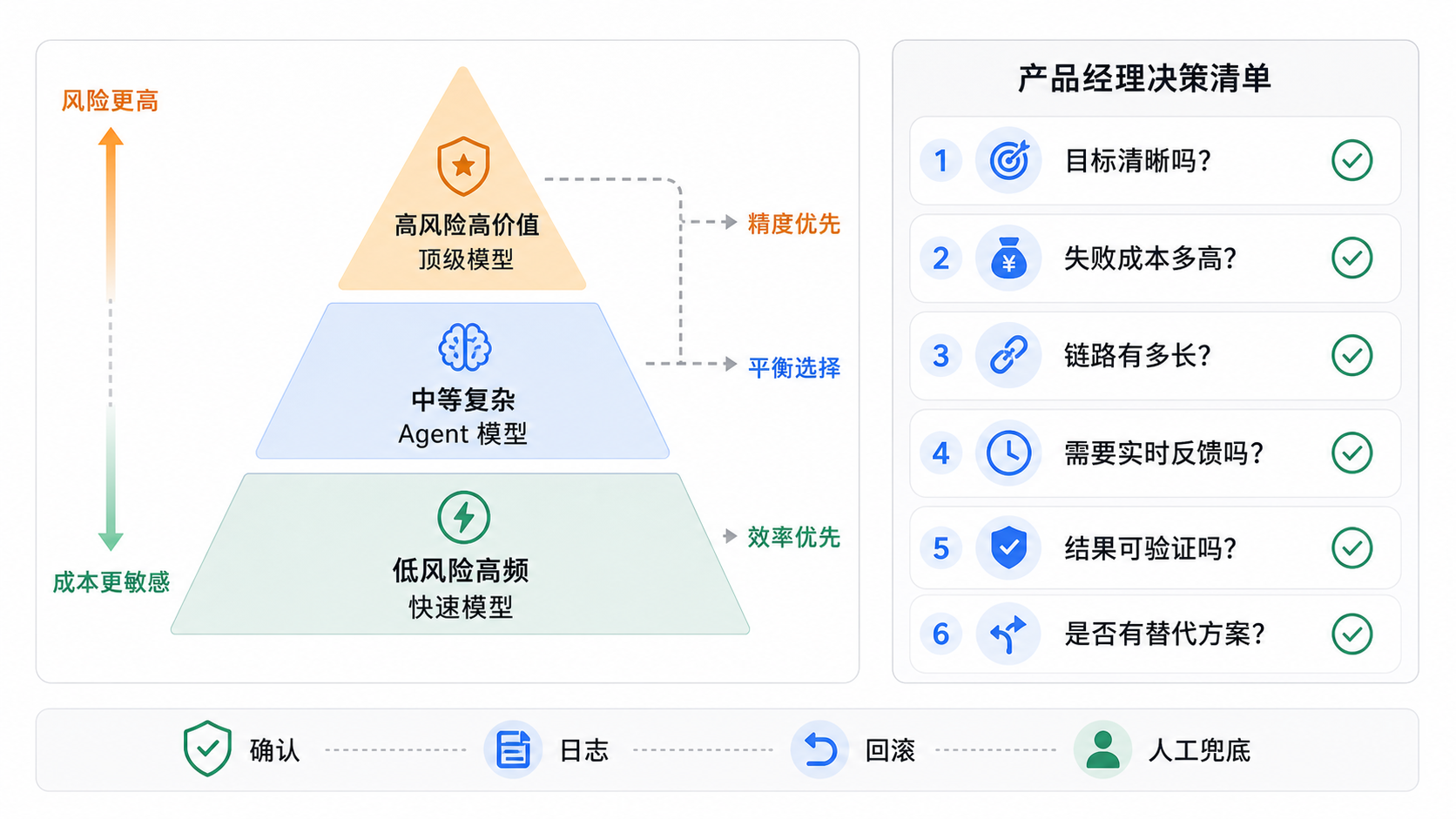
成熟的 AI 产品不会只依赖一个模型,而会根据任务风险和成本做分层调度。
一个合理的 AI 产品架构,可能会长成这样:
- 低风险、高频任务,用便宜、快速、稳定的模型处理,比如分类、改写、摘要、格式转换。
- 中等复杂任务,用高性价比 Agent 模型处理,比如信息收集、表格整理、代码修改、报告生成。
- 高风险、高价值任务,用顶级模型处理,比如复杂决策、关键客户回复、金融法务判断、核心代码变更。
- 涉及外部系统写入、删除、发送、付款、权限变更的动作,则必须加入确认、日志、回滚和人工兜底机制。
这套思路比“接入最强模型”更接近真实产品。
因为用户场景不是单一的,成本结构也不是单一的。
产品经理真正要做的,是把任务拆开,然后为不同任务配置不同能力、成本和风险等级的模型。
Fable 5 解禁提醒我们:模型可用性也是产品风险
AI 产品不能只评估模型能力,还要评估供应稳定性、政策风险和安全策略变化。
Fable 5 和 Mythos 5 曾因出口管制被暂停访问,后来又恢复。
这件事对普通用户来说是新闻,对产品团队来说则是提醒:当你的核心功能依赖外部大模型时,模型可用性本身就是产品风险。
今天模型可能因为政策、合规、安全、供应商策略、价格调整而变化。
对产品经理来说,不能把模型当成一个永远稳定的底层能力,而要提前设计备选方案。比如是否支持模型切换,关键任务是否有降级路径,用户数据是否能迁移,企业客户是否需要明确 SLA,价格变化会不会影响产品毛利。
未来的 AI 产品经理,不只要懂需求和交互,还要懂模型供应链。
产品经理该如何重新做模型选型?
模型选型应该从“能力榜单”转向“场景评估”。
我建议产品经理用六个问题判断一个模型是否适合自己的产品:
- 这个场景的任务目标是否清晰?如果任务边界模糊,需要更强推理模型;如果任务规则明确,可以优先考虑性价比模型。
- 失败成本有多高?如果失败只是重新生成一次,可以用低成本模型;如果失败会影响客户、资金、权限或数据,就要提高模型等级和审核机制。
- 任务链路有多长?越长链路,越要关注模型的规划能力、工具调用能力和自我检查能力。
- 用户是否需要实时反馈?如果用户在等待结果,速度很重要;如果任务可以后台跑,稳定性和最终质量更重要。
- 结果是否可验证?可验证任务更适合 Agent 自动执行,不可验证任务要增加证据、引用、过程展示和人工确认。
- 这个模型是否具备替代方案?如果没有替代模型,产品商业化风险会更高。
AI Agent 的竞争,最后会落到产品交付能力
Sonnet 5 的发布和 Fable 5 的恢复访问,本质上都在说明一件事:大模型行业正在进入更务实的阶段。最强模型仍然重要,但产品经理更应该关心的是,模型能否在真实业务里稳定、低成本、可控地完成任务。
未来的 AI 产品竞争,不会只是谁接入了最强模型,而是谁能把模型能力拆成可交付的产品流程。
谁能把成本算清楚,把风险控住,把用户信任建立起来,谁才更可能把 Agent 从演示视频带进真实工作流。
本文由 @YF拾光机 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自作者提供









单位任务成本的公式把重试、人工审核、用户等待都算进去了,这个视角比单纯比价更接近真实ROI。尤其用户等待成本经常被忽略,等得久了用户可能直接弃用,对留存影响很大。