
 起点课堂会员权益
起点课堂会员权益你的大模型很强大,但它吃的是垃圾数据
国家'模数共振'行动正在重塑AI产业竞争格局。工信部与国家数据局联合出台硬性指标,要求20个重点行业在2026年底前完成数据-模型-场景的闭环建设。这场数据革命直指AI落地最大痛点:高质量行业数据短缺。本文深度解析政策背后的产业逻辑,以及企业如何在这场数据竞赛中找到自己的生态位。

工信部与国家数据局2026年4月联合启动”模数共振”行动,面向20个重点行业,以”数据-模型-场景应用”良性循环为目标。行动带硬性KPI:每行业≥5个通识数据集、≥1个行业模型、≥30个高价值场景;每省≥3个”模数共振空间”;企业可通过数据供给方、场景定义方、加入创新联合体三种方式切入。AI落地的瓶颈已从模型能力转向数据质量。

你的大模型很强大,但它吃的是垃圾数据
有个残酷的事实,很多AI企业不愿意承认。
过去两年,企业砸了几千万甚至上亿训练大模型。算力租了、框架搭了、参数调了、提示词工程也做了——但一到业务场景落地,效果就是不行。生成的内容不准确,行业知识一知半解,决策建议脱离实际。
症结在哪?
换个角度想想:你用全球顶级的烹饪设备,往锅里倒的全是发霉的食材。做出来的菜能好吃吗?
AI行业正在经历同样的困境。算力不缺、算法不差、框架成熟——缺的是高质量的数据。
2026年4月24日,工业和信息化部办公厅、国家数据局综合司联合印发通知,正式启动2026年”模数共振”行动。(来源:工信部官网,工信厅联科函〔2026〕193号)一个多月后的6月3日,国家数据局又印发了《关于推进行业高质量数据集建设行动的实施方案》。
两份文件前后呼应,指向同一个信号:AI的竞争,下一阶段不再是模型之争,而是数据之争。

一、”模数共振”在做什么:不是喊口号,是定KPI
和很多政策文件不同,”模数共振”行动的通知写得非常具体——具体到了每个数字、每条截止日期。
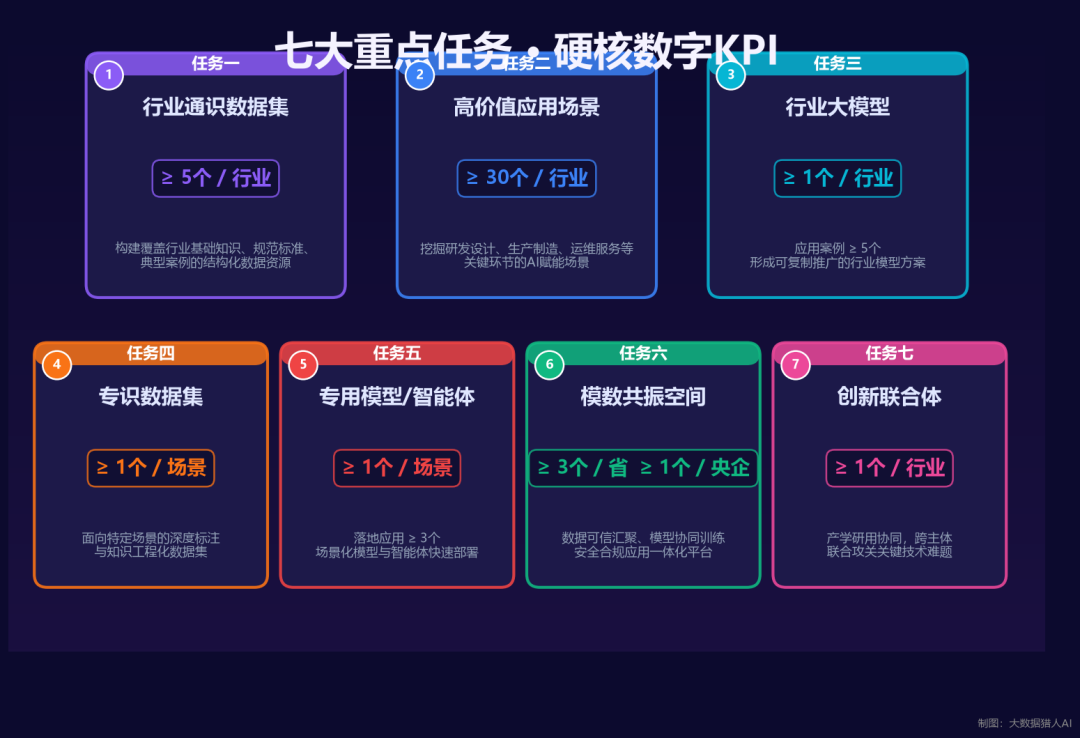
面向钢铁、石化化工、汽车、医疗装备、航空航天、软件、信息通信等20个重点行业,明确了七个重点任务,每个任务都带着硬性数字指标:
每个行业梳理不少于5个通识高质量数据集、研发不少于1个行业模型、行业模型应用案例不少于5个。每个行业凝练不少于30个高价值应用场景、每个场景构建不少于1个专识数据集、打造不少于1个专用模型或智能体。每个省级地区打造不少于3个”模数共振”空间、每个央企不少于1个。每行业打造不少于1个”模数共振”创新联合体。
注意这个”不少于”的用词——不是”力争”、不是”推动”、不是”探索”。是有明确下限要求的执行目标。
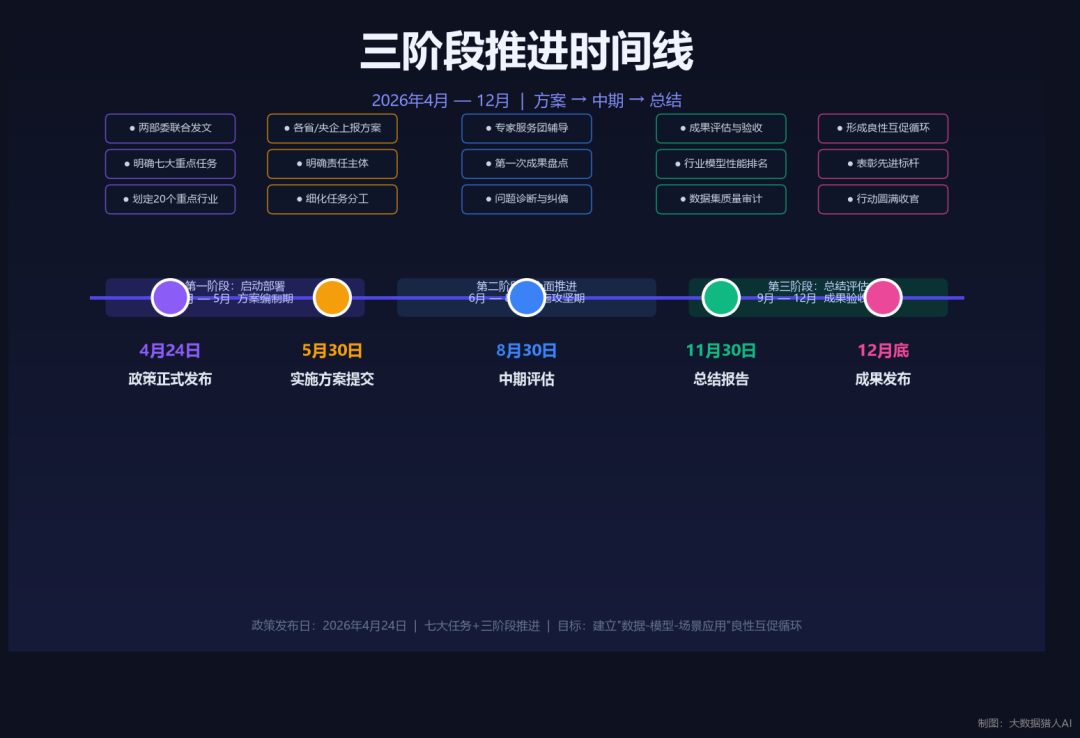
截止日期同样清晰:2026年5月30日前提交实施方案,8月30日前中期评估,11月30日前总结评估。到2026年底基本形成”数据-模型-场景应用”良性互促循环。
政策文件的措辞往往是”温柔的”。但当一份文件开始定数字、定Deadline——说明它不是在征求意见,是在下任务。
二、为什么是现在:AI在集体”断粮”
“模数共振”不是凭空想出来的,它是对一个真实产业困境的回应。
2025年国务院部署”人工智能+”行动以来,大量企业涌入AI赛道,”+AI”和”AI+”的产业应用遍地开花。但一个普遍的问题是:通用大模型有知识广度、缺乏行业深度。它读过整个互联网上的文本,但不懂某一条生产线的工艺参数;它能写八股公文,但不理解某个行业的质量控制标准。
解决”行业深度”的方法不是把模型做得更大——而是在行业专识数据上做精调训练。而问题恰恰出在这里:大多数行业的专识数据根本不在互联网上。它们在工厂的PLC控制器里、在医院的HIS系统里、在航司的维修工单里——没有标准化、没有标注、没有打通。
这就是”模数共振”要解决的核心问题:把散落在各行业的碎片化知识,转化为可用于AI训练的结构化高质量数据集。
2026年6月9日发布的《行业高质量数据集建设行动方案》提出了三个阶段性目标:到2028年底,建成一批覆盖重点领域的行业高质量数据集,打造一批数据驱动AI创新发展的典型应用场景,培育一批创新型数据企业和专业人才,形成一批工具和标准。(来源:中国经济网,2026-06-09)
三、”模数共振空间”到底是什么:打破数据孤岛的工程学方案
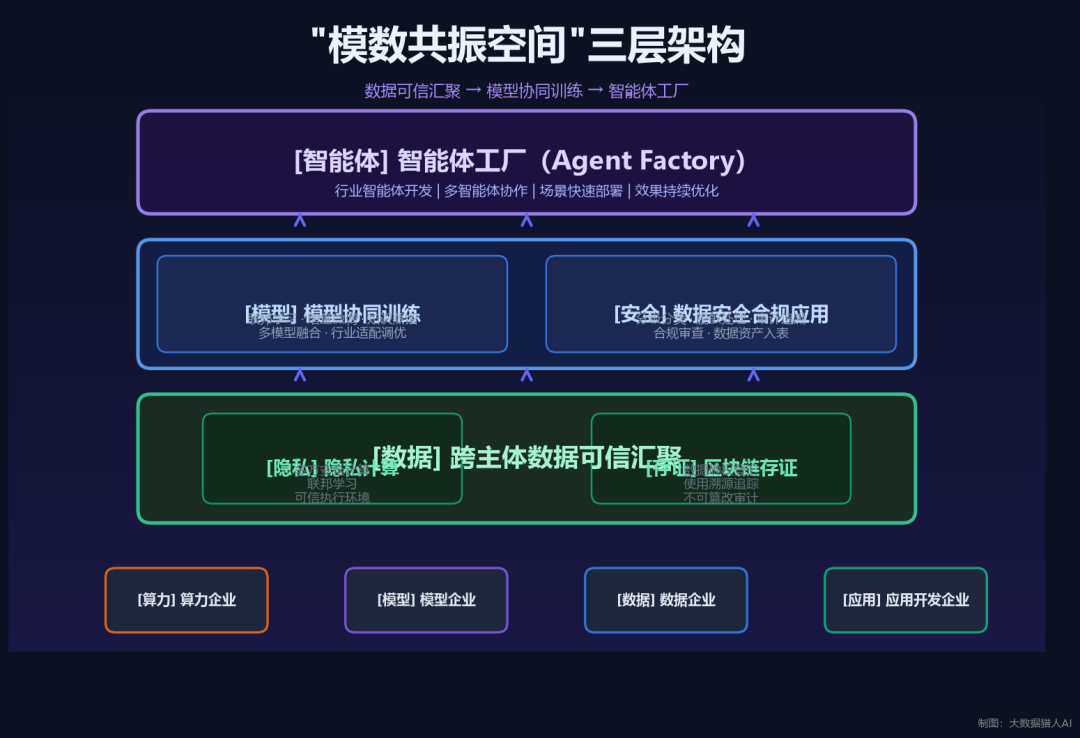
“模数共振”行动中,最具工程创新性的概念是”模数共振空间”。
它不是一个物理空间,而是一套软硬件基础设施+一套管理机制的组合体。核心能力有三层:跨主体数据可信汇聚——不同企业的数据可以在不暴露原始数据的前提下协同使用;模型协同训练——多家企业可以在同一个”空间”里共同训练行业模型,数据不出域、模型可共享;安全合规应用——所有操作可审计、可追溯,满足数据安全和隐私保护要求。
政策鼓励”模数共振空间”与国家数据基础设施互联互通,逐步打造为”智能体工厂”——一个能够批量生产行业智能体的”生产线”。
全国要求每个省份打造不少于3个、每家央企不少于1个。考虑到央企通常总部在北京,这意味着全国至少会落地数百个空间。这不是小范围试点,是规模化部署。
四、企业怎么玩:三条落地切入点
“模数共振”不是只有大央企和龙头企业才能参与的”上层游戏”。不同体量的企业有不同的切入口。
切入点一:做”数据供给方”——把行业专识变成可卖的资产
如果你是一家在某个垂直行业深耕多年的企业——不论大小——你手里很可能有一套别人没有的行业知识体系:工艺参数库、故障案例库、质检标准库、客户画像库。这些东西对别人没有价值,但对AI训练来说是黄金。
你需要做的不是自己训练大模型,而是把这些知识”结构化”——通过数据标注、知识图谱等技术手段,把它变成可被AI使用的行业专识数据集,然后通过”模数共振空间”或数据交易平台提供给模型企业。你卖的是”数据燃料”,不是”AI引擎”。
切入点二:做”场景定义方”——你比技术公司更懂你的行业
“模数共振”要求每行业凝练不少于30个高价值场景。谁最懂水泥厂的生产优化?肯定不是AI公司,是水泥厂的总工。谁最懂手术室的工作流?不是模型工程师,是外科主任。
政策需要行业专家来定义场景——你的AI改造需求是什么、数据在哪里、期望的效果是什么。定义场景就是把”行业经验”变成”AI需求规格说明书”。做这件事不需要你有AI团队,但能让你在”模数共振”生态中从”旁观者”变成”需求方”——需求方是最稀缺的角色。
切入点三:加入”创新联合体”——搭车上路比造车更快
“模数共振”行动明确要求每行业组建不少于1个创新联合体,成员包括算力企业、模型企业、数据企业和应用开发企业。如果你是数据企业(有行业数据)或应用企业(有业务场景),找到本行业的联合体、明确你的贡献点、以成员身份加入——这比你自己单独申请项目更高效,而且联合体的成果天然享受政策支持。

五、结语
过去两年的叙事是”大模型改变一切”。现在叙事正在转向:高质量数据集决定大模型能改变什么。
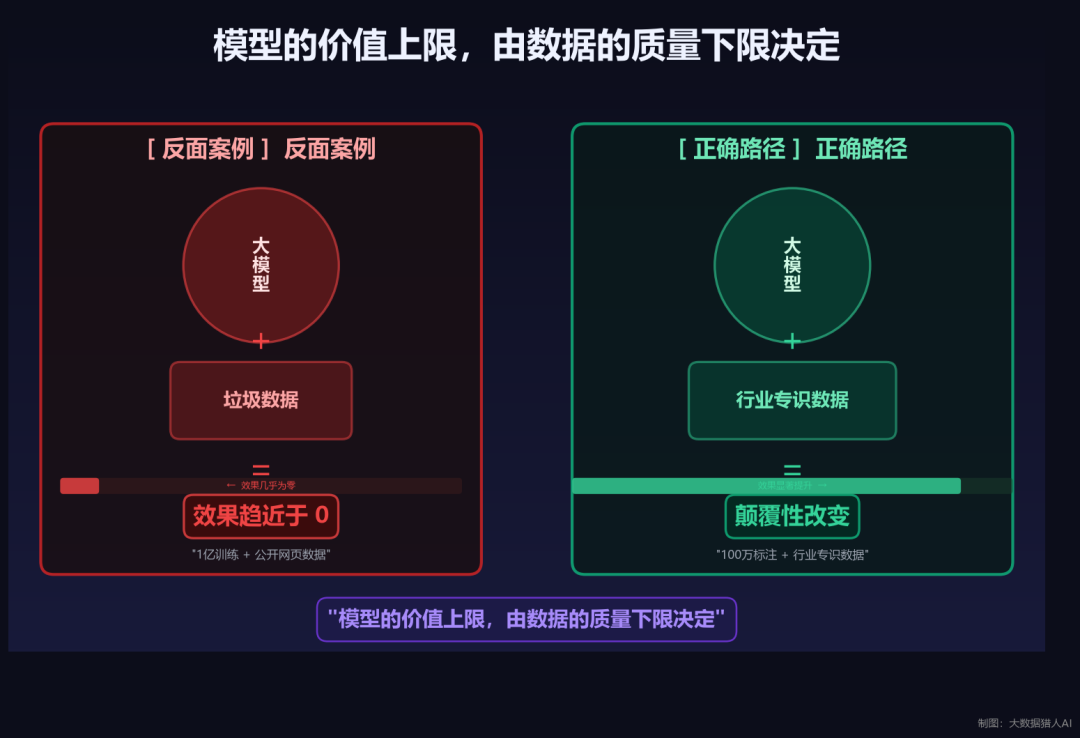
一个花了1亿训练的大模型,如果喂进去的数据全是公开爬取的网页文本,它对行业的帮助几乎为零。一个花了100万做数据标注的行业专识数据集,如果喂给正确的模型架构,它对行业的改变可能是颠覆性的。
“模数共振”的核心逻辑就是这个:模型的价值上限,由数据的质量下限决定。
如果你的企业还在犹豫”要不要做AI”,建议先换一个问题:你手里有哪些数据,是AI企业做梦都想要的? 找到这个答案,你就找到了自己在”模数共振”时代的生态位。
本文由人人都是产品经理作者【大数据猎人】,微信公众号:【大数据猎人】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。






- 目前还没评论,等你发挥!


