
 起点课堂会员权益
起点课堂会员权益AI产品经理必懂算法:决策树
决策树(Decision Tree)是一种以树形数据结构来展示决策规则和分类结果的模型,它是将看似无序、杂乱的已知实例,通过某种技术手段将它们转化成可以预测未知实例的树状模型。

时隔半月,已近年关。AI产品经理必懂算法的第三篇终于来了,今天想和大家聊的是决策树,闲言少叙,切入正题。
先上定义,决策树(Decision Tree),又称判断树,它是一种以树形数据结构来展示决策规则和分类结果的模型,作为一种归纳学习算法,其重点是将看似无序、杂乱的已知实例,通过某种技术手段将它们转化成可以预测未知实例的树状模型,每一条从根结点(对最终分类结果贡献最大的属性)到叶子结点(最终分类结果)的路径都代表一条决策的规则。
说完了拗口的定义,老规矩,我们还是用比较通俗易懂的例子,来讲述决策树算法的原理。
决策树也是一种监督学习的分类算法,要求输入标注好类别的训练样本集,每个训练样本由若干个用于分类的特征来表示。决策树算法的训练目的在于构建决策树,希望能够得到一颗可以将训练样本按其类别进行划分的决策树。
案例:假设现在我们想预测的是,女性到底想要嫁什么样的人?我们现在手里拥有一些未婚男性的数据,其中包括了收入、房产、样貌、学历等字段。
提示:在构建决策树时,每次都要选择区分度最高的特征,使用其特征值对数据进行划分,每次消耗一个特征,不断迭代,直到所有特征均被使用为止。
- 如果还未使用全部特征,剩下的训练样本就已经具有相同类别了,则决策树的构建可以提前完成。
- 如果使用全部特征后,剩下的训练样本中仍然包含一个以上的类别,则选择剩下的训练样本中占比最大的类别作为这批训练样本的类别。
利用决策树的思想,首先我们要考虑的是,上述哪些条件在女性选择男友时最重要的考量指标?好了,假设我就比较在意收入、比较在意物质好了,那么我构建的决策树应该是什么样的呢?来张图大家就明白了。
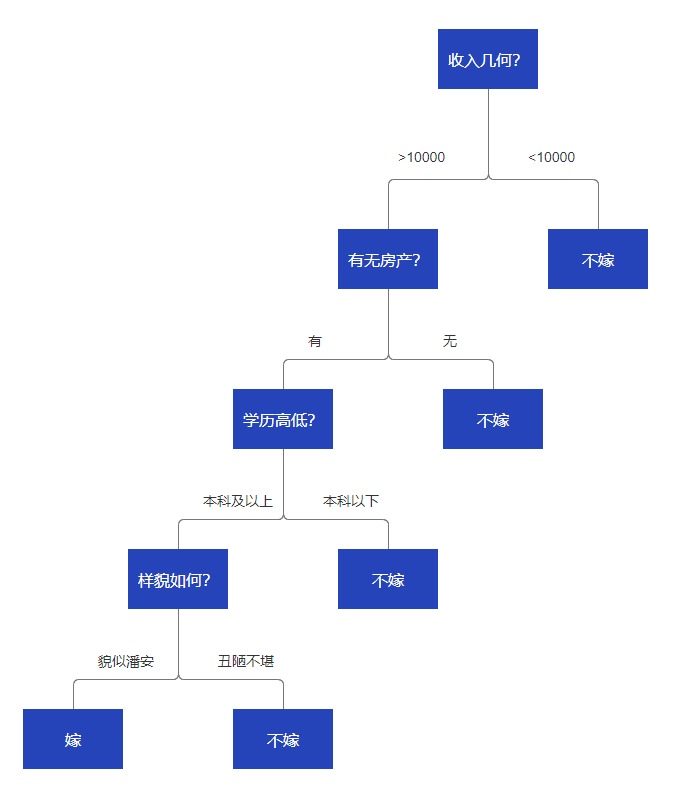
释义:这张图想表达的意思就是说,我们从如下几个方面去判断,是否要嫁?首先,看其收入是否达到1w元,未达标的不嫁,从已经合格的人群中继续挑选,是否有房产,没有的不行,以此类推,我们将所有的重要指标都过滤一遍以后,就构建出一个完整的决策树了,在此之后,有任何男青年放在这儿,我们都能通过决策树,轻松预测出,此人是否可嫁?
我们来出个题试试,某男,风流倜傥、风度翩翩,但是没有独立房产,收入不固定、学历本科,那么到底要不要嫁呢?
图中的收入、房产、学历等都属于特征,每一个特征都是一个判断的节点,那些不可再向下延伸的就是叶子节点。可再分的称之为分支节点。
接下来了解下决策树算法的演进历史,这其中就包含了主流的几种决策树算法,顺便我们也可以了解一下这几种决策树的差别。
1. ID3(Iterative Dichotomiser 3)
J.R.Quinlan在20世纪80年代提出了ID3算法,该算法奠定了日后决策树算法发展的基础。ID3采用香浓的信息熵来计算特征的区分度。选择熵减少程度最大的特征来划分数据,也就是“最大信息熵增益”原则。它的核心思想是以信息增益作为分裂属性选取的依据。
存在的缺陷:该算法未考虑如何处理连续属性、属性缺失以及噪声等问题。
下面来介绍两个与此有关的概念:
信息熵是一种信息的度量方式,表示信息的混乱程度,也就是说:信息越有序,信息熵越低。举个列子:火柴有序放在火柴盒里,熵值很低,相反,熵值很高。它的公式如下:
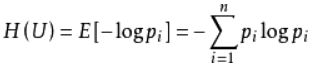
信息增益: 在划分数据集前后信息发生的变化称为信息增益,信息增益越大,确定性越强。
2. C4.5
J.R.Quinlan针对ID3算法的不足设计了C4.5算法,引入信息增益率的概念。它克服了ID3算法无法处理属性缺失和连续属性的问题,并且引入了优化决策树的剪枝方法,使算法更高效,适用性更强。
后续,在1996年Mehta.M等人提出了C4.5算法的改进算法SLIQ算法,该算法采用属性表、分类表、类直方图的策略来解决内存溢出的问题。
同样介绍一下信息增益率:在决策树分类问题中,即就是决策树在进行属性选择划分前和划分后的信息差值。
3. CART(Classification and Regression Tree)
Breiman.L.I等人在1984年提出了CART算法,即分类回归树算法。CART算法用基尼指数(Gini Index)代替了信息熵,用二叉树作为模型结构,所以不是直接通过属性值进行数据划分,该算法要在所有属性中找出最佳的二元划分。CART算法通过递归操作不断地对决策属性进行划分,同时利用验证数据对树模型进行优化。
CART中用于选择变量的不纯性度量是Gini指数,总体内包含的类别越杂乱,GINI指数就越大(跟熵的概念很相似)。
2000年Rastogi.R等人以CART算法为理论基础,提出了PUBLIC(A Decision Tree Classifier that Integrates Building and Pruning)算法,剪枝策略更加高效。
当我们了解了决策树的大概情况之后,接下来就学习一下,如何构造决策树?
第一步:特征选择;第二步:决策树的生成;第三步:决策树的剪枝。
我们来着重介绍一下剪枝。
剪枝的目的:决策树是充分考虑了所有的数据点而生成的复杂树,有可能出现过拟合的情况,决策树越复杂,过拟合的程度会越高。考虑极端的情况,如果我们令所有的叶子节点都只含有一个数据点,那么我们能够保证所有的训练数据都能准确分类,但是很有可能得到高的预测误差,原因是将训练数据中所有的噪声数据都”准确划分”了,强化了噪声数据的作用。剪枝修剪分裂前后分类误差相差不大的子树,能够降低决策树的复杂度,降低过拟合出现的概率。
如何剪枝?
- 先剪枝:当熵减少的数量小于某一个阈值时,就停止分支的创建。这是一种贪心算法。
- 后剪枝:先创建完整的决策树,然后再尝试消除多余的节点,也就是采用减枝的方法。
注意事项:
决策树的生成对应模型的局部选择,决策树的剪枝对应于模型的全局选择。决策树的生成只考虑局部最优,决策树的剪枝则考虑全局最优。
说了这么多,我们来总结一下决策树算法的优、缺点,以便了解的更为深入。
优点:
- 决策树易于理解和实现.人们在通过解释后都有能力去理解决策树所表达的意义。
- 计算复杂度不高,输出结果易于理解,数据缺失不敏感,可以处理不相关特征。
缺点:
- 容易过拟合。
- 对于各类别样本数量不一致的数据,在决策树当中信息增益的结果偏向于那些具有更多数值的特征。
本文由 @燕然未勒 原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自 Unsplash ,基于 CC0 协议。










太好了,将常用算法进行了总结,支持续更
这种决策有瑕疵,最后产生的是矛盾化。解决方法还是要根据事态性质来偏向化的。
我想知道某男是否可嫁?
“某男,风流倜傥、风度翩翩,但是没有独立房产,收入不固定、学历本科,那么到底要不要嫁呢?”
到没房子的地方,就被“卡”了,sorry,一个悲伤的故事 ➡
那就只有所有条件都满足才能嫁了?这样的决策树如何体现出AI?
看不懂!