
 起点课堂会员权益
起点课堂会员权益企业如何使用模型微调(SFT)定制化调优大模型?
现在各个公司都在做自己的大模型,或者是用大模型进行调优以符合企业的要求。这种情况下,我们如何是用模型微调定制化调优大模型呢?本文介绍了模型微调的训练步骤,并给出了相关案例参考,希望能帮到大家。

上次我们聊完指令工程调优大模型,有朋友说它很初级,解决不了实际的业务问题。
那我们今天聊的模型微调(SFT)可以在一定程度解决你的困惑,本次依然将我在实际应用中的具体效果、适用场景、示例以及详细的训练步骤来分享。
话不多说,开整~
01 模型微调的定义与效果
在大模型的调优策略中,模型微调是一个关键步骤。它存在两种策略:
- 全参数微调(Full Parameter Fine Tuning)
- 部分参数微调(Sparse Fine Tuning)
全参数微调涉及到调整模型的所有权重,使之适应特定领域或任务,这样的策略适用于拥有大量与任务高度相关的训练数据的情况。
而部分参数微调则是只选择性地更新模型中的某些权重,特别是当我们需要保持大部分预训练知识时,这种方法能减少过拟合的风险,并提高训练效率。
微调的核心效果是:在保留模型泛化能力的同时,提升其在某一特定任务上的表现。
02 模型微调适用和不适用的场景
适用的场景
- 在拥有大量领域相关标记数据时,适宜进行全参数微调。
- 当需要模型具有领域专一性,同时又要保持一定泛化能力时,部分参数微调是更佳选择。
不适用的场景
- 当训练数据有限,或者与原始预训练数据差异极大时,全参数微调可能导致过拟合。
- 如果任务需要模型具有广泛的知识背景和泛化能力,部分参数微调可能过于狭隘。
03 模型微调的训练步骤
三步法:
1)确定微调策略:基于可用的训练数据量和任务需求选择全参数微调还是部分参数微调。
2)准备数据集:按照微调的策略准备相关的标记数据。
3)微调训练:
- 对于全参数微调,通常需要长时间训练以及大量的数据。
- 对于部分参数微调,确定哪些参数需要更新,并在较短时间内完成特定层或模块的训练。
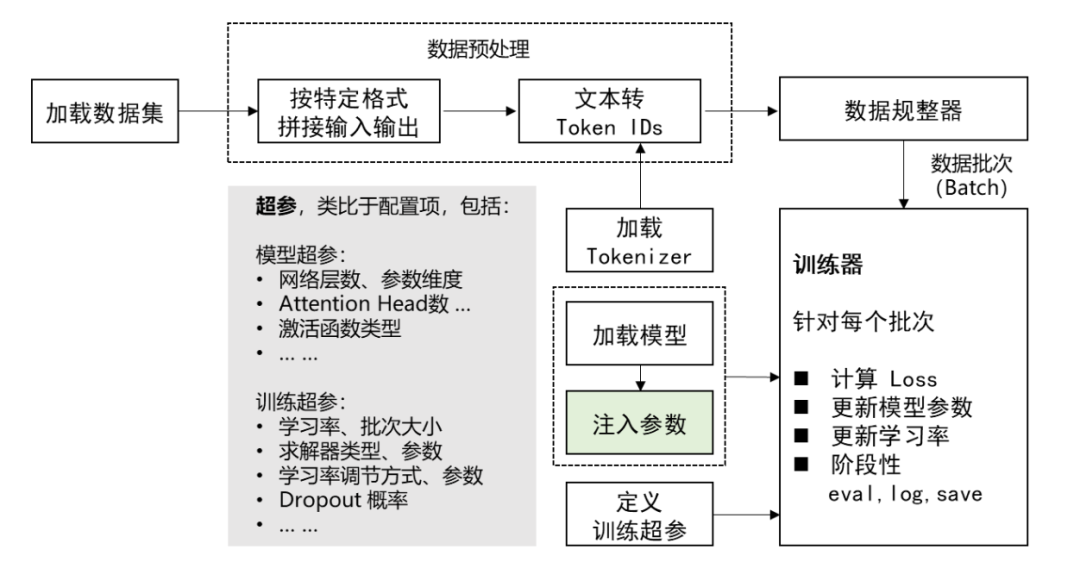
很关键的一步就是选择全参还是部分调参,简单来说,全参数微调通常在有大量标记数据和明确任务目标的情况下使用,以精细调整模型性能;
而在数据较少或需要保留模型原有广泛知识的场景,采用部分参数微调,以实现更高的效率和避免过拟合。
04 模型微调的示例:基于企业用户行为的政策推送
假设我们手头有一个企业用户数据库,记录了用户对各种政策通知的点击和反馈行为。
目标是微调一个语言模型,使其能够根据用户历史行为推测出用户可能感兴趣的新政策,并进行有效推送。
全参数微调的具体步骤
- 数据准备:整理出企业用户的行为数据集,每个样本包括用户行为特征和所对应的政策反馈。
- 数据预处理:对数据集进行清洗和预处理,将文本内容标准化,分类标签进行编码。
- 模型选择:选择一个适合文本分类任务的预训练模型,如国内的通义千问/文心一言大模型。
- 微调设置:配置微调的参数,如学习率、批量大小、迭代次数等。
- 微调执行:使用整理好的数据集对模型的全参数进行微调,这通常需要在有GPU加速的环境中执行。
- 性能监控与评估:通过验证集不断监控模型的性能,使用如精确度、召回率等指标来评估。
- 微调结果应用:将微调后的模型部署到政策推送系统中,测试模型在实际环境中的表现。
部分参数微调的具体步骤
- 数据采集:同样需要企业用户的行为和反馈数据,但可能更关注特定的行为模式或关键特征。
- 关键参数选择:分析哪些模型参数与用户行为关联更紧密,仅选择这些参数进行训练。
- 微调配置:配置微调时的参数设置,可能会有不同因为更新的参数较少。
- 有针对性的训练:将收集的数据用于模型的部分结构,如输出层或注意力机制部分的参数更新。
- 效果评估:使用一组小规模的测试数据来快速评估调整后模型的性能。
- 微调模型部署:将部分参数微调过的模型应用在政策推送系统中,并观察其实际效果。
我们实际上希望模型能够认出“当用户多次点击某类政策信息时,下次如果有类似的政策推出,系统应优先推送该类政策给用户”这样的模式。
为了实现全参数微调,我们会设立一个监督学习的框架,标注出用户行为与政策类别间的联系,并且在整个模型上执行梯度更新。
在部分参数微调中,我们则可能专注于模型的一小部分,比如说调整决策层,让算法学会基于用户行为的聚类来判断哪类政策最可能得到用户的点击,这意味着主要改变的是模型对行为类型的权重判断。
通过这样精细化的微调流程,模型能够以更高的准确率完成企业用户政策推送的任务,实现个性化服务与效率的提升。
05 最后的话
总得来说,模型微调的优势在于提高模型在特定任务上的性能和适应性,确保模型输出不仅准确,而且可靠和一致;劣势在于这是一个计算密集型过程,可能在有限的资源下难以进行,尤其对于大型模型。
那企业如何判断呢?
- 有私有部署的需求
- 开源模型原生的能力不满足业务需求
希望能带给你一些启发,加油。
作者:柳星聊产品,公众号:柳星聊产品
本文由 @柳星聊产品 原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自 Unsplash,基于 CC0 协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。









欢迎各位在成长路上的同行者们,留下您的思考,一起加油~