
 起点课堂会员权益
起点课堂会员权益当文与图的界限开始模糊:聊聊自回归与扩散模型的「串台」趋势
在人工智能领域,自回归模型和扩散模型分别在文字和图像生成任务中占据主导地位。然而,随着技术的发展,两者之间的边界似乎开始模糊。本文将深入探讨这两种模型的核心差异,分析它们为何适用于不同的信号类型(离散信号与连续信号),并探讨如何通过技术路径实现自回归模型在图像生成任务中的应用。

为何文字与图像生成模型分道扬镳?
你是否会有这样的疑问,为什么主流的文字模型用的都是自回归模型,而主流的图片视频生成模型却偏爱扩散模型呢?
最近的一些项目也让这个事情慢慢地变得微妙了起来啊。
比如说 Gemini 的这样的一个自回归模型,由于良好的图片一致性惊艳了整个圈子。
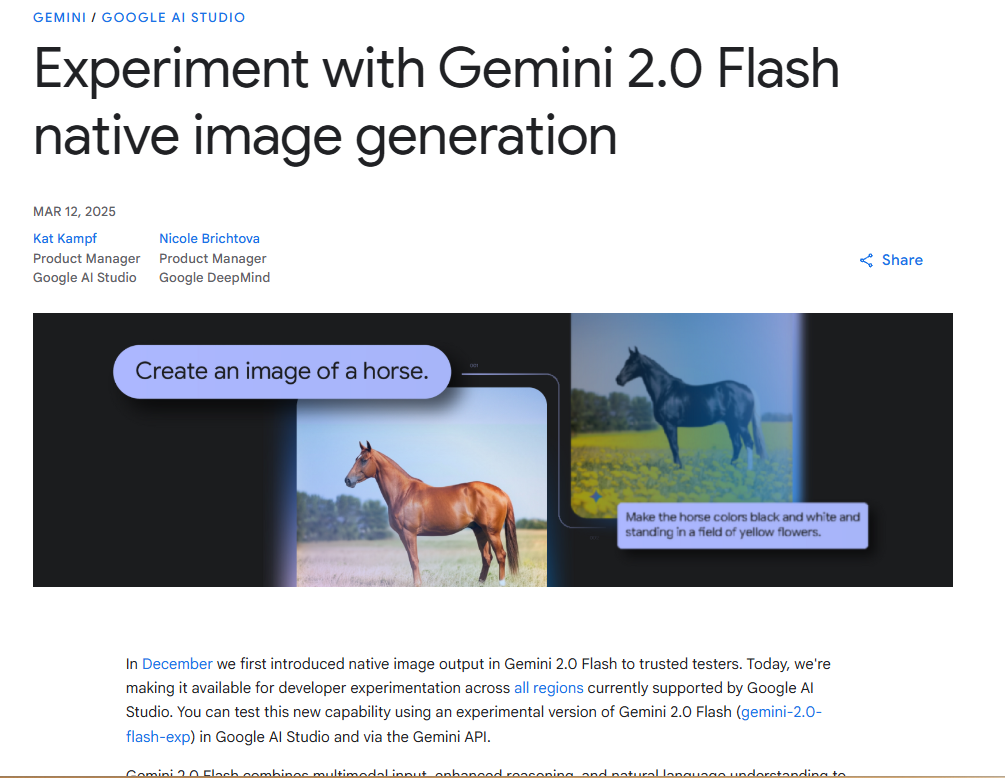
而前段时间扩散大语言模型项目 Mercury 也因为它超快的这种文本生成速度引发了大量的关注。
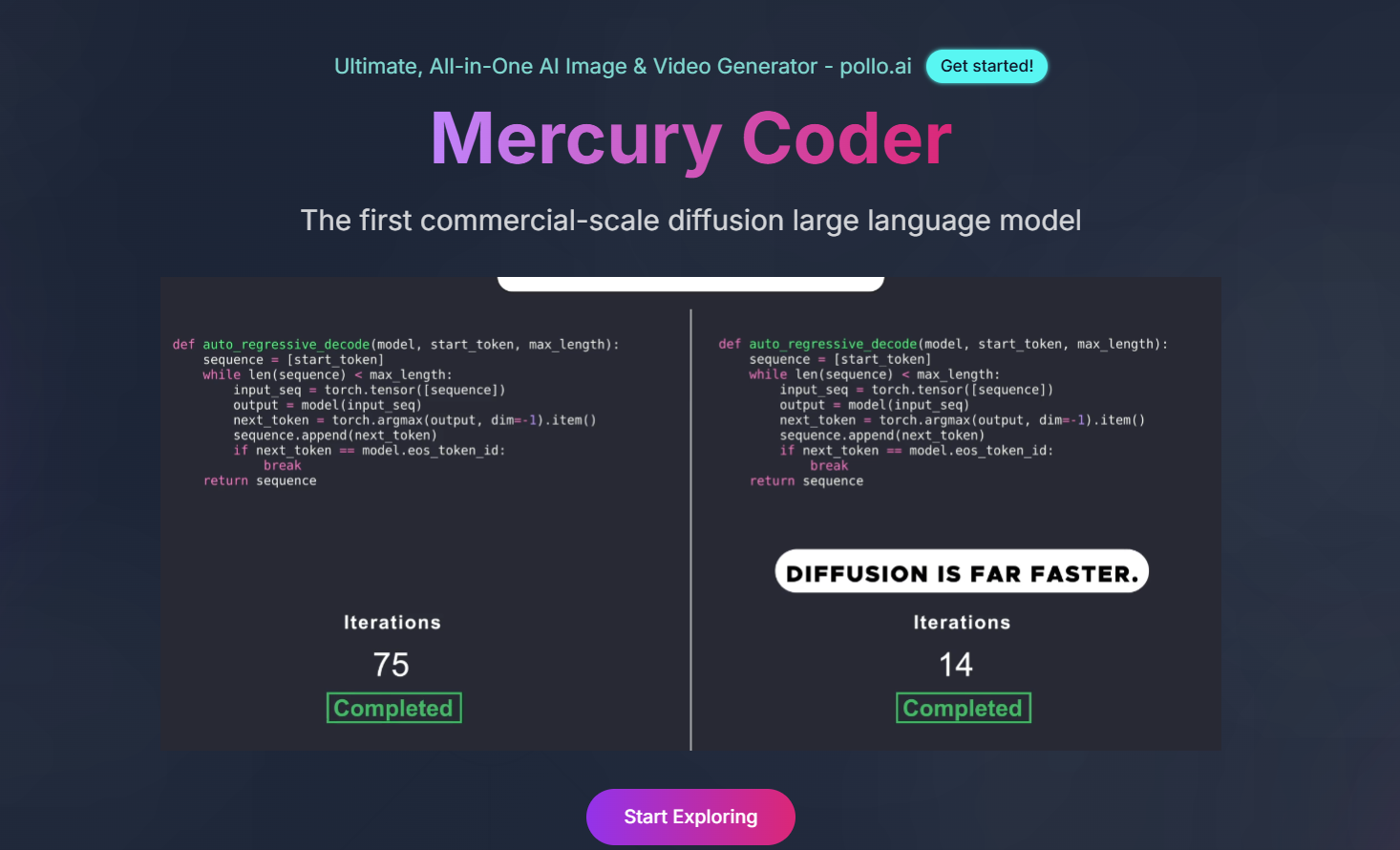
难道说模型的这个边界正在被打破吗?
自回归模型和扩散模型,它们之间到底有着什么样的区别呢?
核心差异:离散信号与连续信号的本质
其实这个问题的核心是要追溯到为什么最早人们开始选择这个技术路线的时候,用自回归模型去生成文字,用扩散模型去生成图片。
这背后其实隐藏的是文字和图像自身的最根本的区别,也就是离散信号和连续信号。
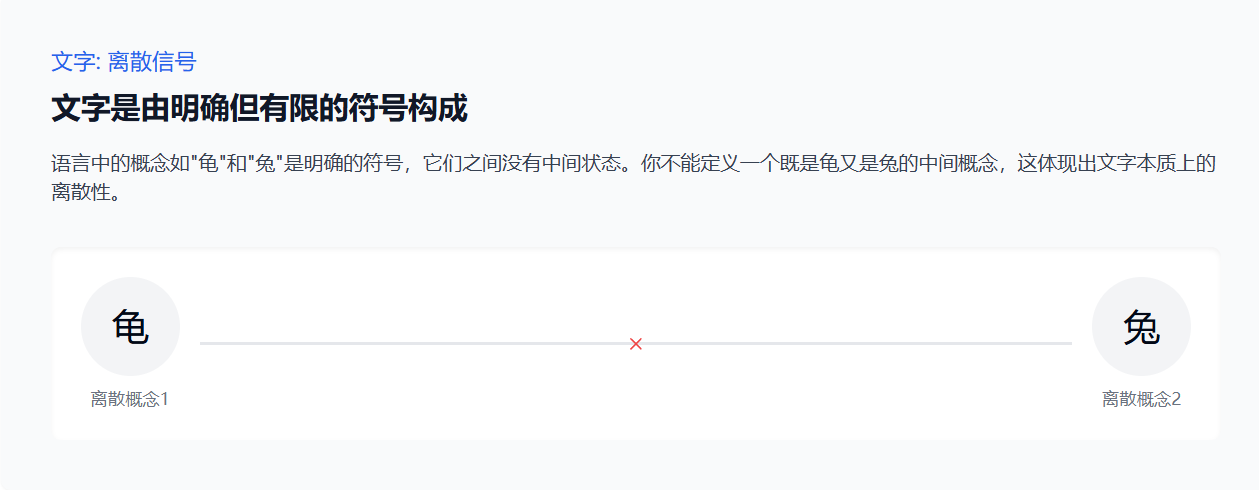
文字是一种离散信号,有一系列明确的、有限的这种符号构成。
就比如说我们的语言中有龟和兔这两个明确的符号概念,但是你不可能在龟和兔之间找到一个中间状态,就是我们没有办法定义一个既是龟又是兔的中间符号,这其实体现出来的就是文字本质上的离散性。
那图像就是一种连续的信号,它是平滑无限的啊。
举个简单例子,就是你观察这个红色和黄色之间,其实可以找出无数个不同的橙色啊。
这些中间状态都是连续存在的,所以它不是有限的离散符号。

那更进一步,其实文字本身就是人发明的,对这个连续世界的一种抽象,或者说是采样。
就比如说我们看到不同品种的龟,对吧
无论是中华草龟还是猪鼻龟,它们都被我们统一成了一个离散的概念龟。
并且用龟这个字这个符号来进行一个表示,所以正是由于有这样的差异,决定了早期的生成任务会选择不同的模型方向。
生成机制对比:从人类行为到模型逻辑的仿生学映射
自回归模型:契合人类语言生成的逐字预测机制
那在这个地方其实我们首先要去了解人是怎么样去生成文字的,就是人在说话的时候是一个什么样的过程。
那人说话时是一个逐字逐句、循序渐进的过程,就是我讲一个字或者说表达一个字的时候,其实都是根据前面说的话,是吧?

举个例子就是我现在想喝,你要预测下一个这个字是什么的时候,你可能会说我想喝奶茶,我想喝可乐,但是大概率不会说我想喝自行车,我想喝混凝土,就是语言,它有一种天然的基于上下文的推进逻辑。
那自回规模型的工作机制其实和人说话的这个过程高度相似,自回规模型就是根据已生成的离散符号去预测下一个符号的概率,在每一步的这种预测之中,是吧?。
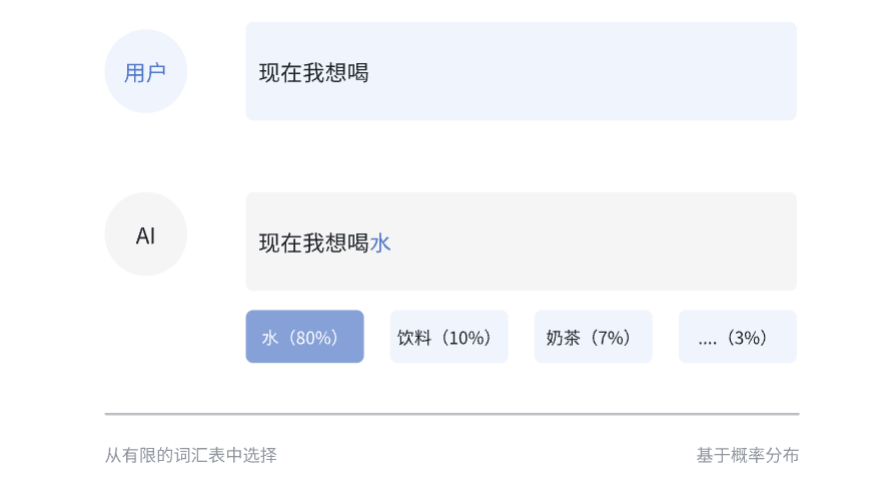
我就从这个有限的符号集里面去判断哪一个符号的概率最大,你可以理解成本质上它是一个分类任务。
所以自回规模型和语言生成的这种内在习惯是相似的,导致它非常适用于文字生成的任务相对应的。

扩散模型:模拟图像绘制的渐进细化与特征概率分布
相对应的,我们要去了解人是怎么画画的。
假设你想画一只长颈鹿,你可能会先从一个简单的草图开始,然后逐步添加细节,使它越来越接近你脑海中的长颈鹿形象。
我们脑海中对「长颈鹿」这个概念有一些典型特征,例如长长的脖子和身上独特的斑纹。因此,当我们绘制长颈鹿时,就会有意识地加入这些特征,因为它们是代表「长颈鹿」这一概念的典型标志。

然后我们从数学的角度去看,像长长的脖子、身上独特的斑纹这样的特征组合。
在我们去设想的这个长颈鹿的图案,或者说我们看到的长颈鹿图案里面出现的概率是很高的,所以这块体现出来就是长颈鹿这个概念背后其实都是特征的概率分布特征的这样的一种集合。
所以当我们用扩散模型去生成图片的时候,在做的一件事情就是试图让图像中的这些特征尽可能地向我们想要表达的那个概念的高概率区域去靠拢。
比如说在连续的这个空间中,我不断地把这个脖子画长,画的像长脖子,不断地去增加这个斑纹的质地,让它看起来像是一个长颈鹿斑纹,那么最终的图像由于我在不断地去把这些特征给它进行一个强化,就会导致我们画出来的长颈鹿就真的很像一个真实的长颈鹿。
所以扩散模型就是在找一种概率分布,找的是从模糊草图到细节逐渐变清晰的这样的一个过程,和人们去绘画的这种思维方式是吻合的,所以扩散模型就天然的适合图像生成的任务。
但是这个还要再多说一句,就是当我们用扩散模型生成长颈鹿的图像的时候,虽然我们有长脖子、独特斑纹这种明显的典型特征的预设,但由于图像信号本身是连续的信号,所以我们截取到的这个特征自然也是连续的,这种连续的特征导致我们很难明确地去找出哪些维度是具体对应这个长脖子,哪些维度是具体对应这个独特斑纹,因为他们这些特征之间其实是没有明确的边界的,所以扩散模型生成图的过程算是比较直观的。
但是你很难地具体地去判断,诶,每一个特征或者说这多个维度特征的组合表达的到底是什么样的一种含义?
所以扩散模型在学习这些特征的时候,其实学到就是一种整体的、抽象的、无法用语言表述的感觉,其实就跟人在第一次看到一个非常宏伟的建筑的时候,你不会具体去分析这个画面里面的哪些细节让它变得宏伟,像你不会说这个设计语言是什么,其实很多时候我们就是直观地感受到这个宏伟的这样的一个整体的美感,或者说是一种直觉,画面之所以能够有效地传递这种直觉或者说是美的这样的一种概念。
是因为审美本身就是难以表述的,难以用明确的这种边界去进行一个定义,它依靠的就是大量的微妙特征,它们相互融合、相互作用,然后让人们感受到这是一种美的概念,所以这个是为什么扩散模型有的时候的确能够生成一些让人觉得很惊艳的作品,我就把这个叫做扩散模型 AI 的一种想象力。
所以我们可以看到其实人们在使用这个自回归模型和扩散模型生成文字和图像的时候,是符合人们自己去使用文字绘制图像的方式的,这背后有一种类似于仿生学的概念,就是人怎么做,我就让模型去怎么做。
他们虽然有着不同的技术方案,有着不同的模型,但其实都是解决相对应问题的这样的一种,最短的这样的一种路径。
边界的突破:自回归模型处理图像的技术路径
那第二个问题就是像 Gemini或者说 Grok -3 的这样的模型,为什么现在又能够去完成多模态的任务?
既能生成文字,又能生成图像呢?
这地方说一句就是Gemini其实并没有公开它的任何技术资料,所以我们只能去找类似的开源项目,然后弄清楚这背后的秘密。
这方教大家一下怎么找。
首先我们到这个 hugging face 的模型界面,然后我们要去找到多模态的模型,就是这里的 Any to Any
众所周知,Deepseek 的开源工作做得非常的完善,所以我们后面所说的关于自回归模型的一些讨论,其实基本上都是来源于 Janos 的这样的一个技术报告啊。

那话说回来,大家可以去思考一下,图片是连续的,自回归擅长处理离散的信号,那我们怎么样能够让自回规模型去生成图片或者说处理图片呢?
那这个地方我们其实可以加一个模块去做一种转换,我先把图片的这种连续信号转成离散信号,之后再用自回规模型去进行处理。
这个地方 Janus 其实做的就是这样一件事情,我们可以看到在自回归的这个模型里面引入了一个新的模块,叫做 VQ Tokenizer,这个 Tokenizer 就明确实现了连续特征到离散特征的一个转换,VQ Tokenizer 会构建一个称为这个 Code book 的东西,叫做离散的特征集合,就把原本的连续特征就映射到这样的一个集合里啊。

举个例子,我们还是一张长颈鹿的图片,在经过了 VQ tokenizer 之后,它就会变成,那这个长颈鹿的轮廓是什么样的?
这个长颈鹿的透视关系是什么样的?
这个长颈鹿它的纹理是什么样的?
这个长颈鹿头上面有什么?
所以这样的方式把原本难以直观表达的这种影视的连续的特征变成了一种更加明确、更加可控的显示的特征啊。
虽然 code book 中的这种特征维度其实不是人直接去定义的,比如说长脖子或者独特斑纹,不是说我想要这两个特征,它就出现在这个 code book 里面,但是相比于扩散模型而言,我们能够通过这样的一个 code book 更清晰地理解这个图像的生成过程。
那既然如此,对吧。
我们就可以去猜为什么 Germini或者说 Grok-3在图像编辑的任务上比扩散模型要强。
首先,既然每一个维度都可以清晰地解释,当我们想明确地把这个长脖子改成短脖子的时候,我们只需要针对那个特征维度的区域进行一个精准的修改就可以了,我们不需要担心这种修改会影响到这个图的其他区域。
所以这种明确的特征表示是为图像的编辑任务提供了很大的便利的,而且它能够最大程度上去保持图像的一致性。
但是它也有相对应的劣势,当我们引入了这个 VQ tokenizer 之后,就意味着你这个多出来的这个模块,这个 code book 是需要去维护的,是吧?

我怎么样保证 code book 的这个训练过程和优化是足够准确的。
我只有这样的一个模块不出错,我才能生成更高质量的内容。
那除此之外,就是当我把无限的信号映射到有限的离散特征之中,肯定会有信息损失,而且这种损失就尤其体现在复杂的、精细的场景上。
我们之前说了连续的特征能够更好地表达美学直觉这种艺术性的抽象概念。
那当这些连续性的信号被强行离散化之后,就很有可能造成细节或者说整体美感的这样的一种下降,所以自回归模型很有可能在高度复杂的图像生成任务上遇到瓶颈,毕竟有一些美的东西你真的没有办法用显示的或者说用语言去进行一个精确的描述。
那最后其实就是自回规模型,现在来看在图像的分辨率上其实还是有一定的劣势,就基本上是不太赶得上现阶段的扩散模型的。
那相对应的这个扩散模型的优点就是算法更直接,图像更细腻、分辨率更高,是吧?
小结
那综上所述,其实自回模型和扩散模型虽然有的地方有交叉,但是整体而言它们都有自己的适用领域,并且很有可能联合起来使用,嗯,会有更好的思路,所以我们没有必要去讨论这个谁会取代谁啊。
那相比于模型本身,我觉得更重要的是只有当我们真正去理解这个技术背后的原理和它的发展的这种脉络的时候,我们才能在现在这个 AI 的时代浪潮之中,准确地选择最适合自己产品的技术方案,真正地做出属于自己的判断。
掌握了这个知识,其实你就已经比别人站得更高、看得更远了,以未来也会走得更稳,这个才是我认为的,要知其然,更要知其所以然。
作者:Easton ,公众号:智子观测站
本文由 @Easton 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务









标题写错了吧。。。。还是要严谨一些
抱歉