
 起点课堂会员权益
起点课堂会员权益从 RAG 底层原理拆解:“RAG 已死” 是典型的技术伪命题
“RAG已死”并非技术终结,而是认知误区。本文将从底层原理出发,系统解析RAG的本质机制、适用边界与演进方向,揭示为何当前的质疑多源于误解与滥用,并构建一套判断RAG价值的技术认知框架,帮助产品人厘清“死”的真正含义。

近期,AI 圈子里悄然兴起一种论调 “ RAG 已死 ”。
理由听起来颇具说服力:
随着大模型上下文窗口(Context Window)动辄达到百万甚至千万级别,我们似乎可以直接将整本书、整个知识库喂给大模型,让它自己去阅读理解,何必再费劲地搞“ 检索-增强-生成 ”这套流程?
然而,作为技术从业者,我们必须警惕这种线性思维 带来的误判。
在深入剖析了 RAG 从基础到前沿的完整技术图谱后,我得出一个清晰的结论:
所谓“ RAG 已死 ”,不过是混淆了RAG与上下文工程(Context Engineering)的概念,并把 RAG 的“ 童年形态 ”当成了它的全部。
事实上,RAG 非但没有死,反而在不断进化,其生命力远超想象。
基础 RAG:舆论的「 靶子 」
首先,我们必须承认,批评者们并非无的放矢。他们瞄准的「靶子」,是 RAG 最原始、最基础的形态——基础 RAG(Naive RAG)。
这个版本的流程非常经典,可以概括为三步:
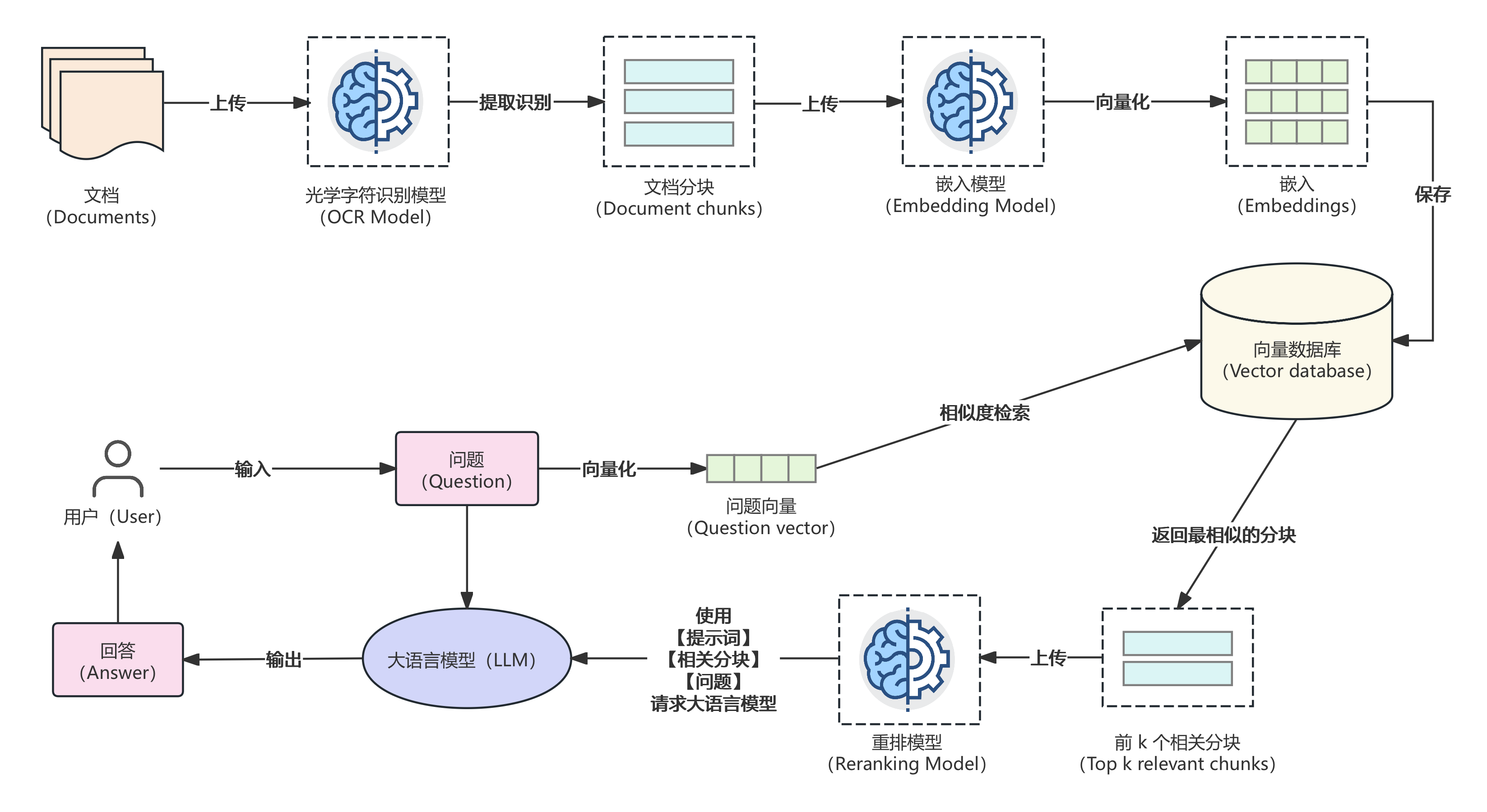
- 索引(Indexing):将你的私有文档(如PDF、Word)切分成小块,通过嵌入模型将其转化成向量,存入向量数据库。
- 检索(Retrieval):当用户提问时,将问题也转化成向量,去数据库里寻找语义最相近的几个文本块。
- 生成(Generation):将找到的文本块和原始问题一起打包,交给大模型,让它基于这些参考资料来回答。
这套流程的优点是简单直接,能快速让大模型具备回答私有知识的能力。
但它的缺点也同样致命:
检索质量差
常常找不准、找不全,检索回来的内容要么与问题无关(低精度),要么遗漏了关键信息(低召回率)。
上下文整合难
一堆杂乱无章、甚至相互矛盾的文本块丢给大模型,它也会“精神错乱”,难以生成高质量的答案。
如果 RAG 技术止步于此,那么“ RAG 已死 ”的论调或许还有几分道理。 因为它确实显得笨拙、低效,似乎很容易被一个拥有超长上下文窗口、能“ 暴力阅读 ”的模型所取代。
但现实是,RAG的进化从未停止。
进阶 RAG:RAG 的「文艺复兴 」
为了克服基础 RAG 的种种弊病,业界早已发展出一整套更精细化的方案,我们称之为进阶 RAG(Advanced RAG)。
它不再是一条僵化的流水线,而是一个可以灵活组装、高度优化的模块化系统。
(进阶 RAG 常见流程图)
相当于给原来那座简易的图书馆来了一场工程级的精装修,引入了不少新家具和新布局:
重排序 ( Reranking )
在初步检索出一批候选文档后,引入一个更专业的重排模型进行二次筛选。它会仔细比对问题和每一篇候选文档,确保最后送给大模型的都是优中选优的精华内容。
查询转换 ( Query Transformation )
如果用户的提问很模糊,系统会先让大模型揣摩一下用户的真实意图,把问题优化得更清晰、更适合机器检索,甚至分解成多个子问题分头查找。
混合搜索 ( Hybrid Search )
将理解语义的向量搜索和匹配关键词的文本搜索(如 BM25 )结合起来,使得其既能理解你的言外之意,又不会错过任何一个关键术语。
父子文档索引 ( Parent-Child Indexing )
用小颗粒度的文本块做精准定位,但给大模型看的是包含这个小块的、更完整的段落或章节。这解决了“只见树木不见森林”的问题。
至此,进阶RAG已经是一个高度工程化的精密系统,它追求的是在有限成本内,为大模型提供最高质量、最低噪声的上下文。
上下文工程正在杀死 RAG?
“RAG 已死”论调的另一个核心,是将 RAG 等同于「 向 Prompt 中填充信息 」这个动作,并认为随着上下文窗口变大,这个动作可以被简化为全部填充。这其实是一个巨大的误解。
我们必须厘清一个概念:
上下文工程泛指所有在生成前对输入给大语言模型的上下文进行组织、优化和管理的技术。
而 RAG是一种动态、实时的信息获取机制,是上下文工程的一种高级实现方式。它的核心是检索这个动作,而不是增强这个结果。
把长文本一股脑塞进上下文窗口,我们称之为“ In-Context Learning ”。
这确实能让模型在当前对话中学习到新知识,但它面临着大海捞针的困境:
精度问题
在数百万字的文本中,LLM的注意力是有限的,关键信息很容易被淹没在海量无关内容中,导致Lost in the Middle(中间淹没现象)。
成本问题
处理超长上下文的计算成本和时间成本是巨大的。对于每次查询都重复处理整个知识库,无异于杀鸡用牛刀。
动态性问题
如果知识库更新了,你需要重新将整个新知识库塞入上下文。这在实时应用,特别是许多企业级场景当中几乎不可行。
而 RAG,恰恰是解决上述问题的优雅方案。 它不做暴力填充,而是做精确制导 。
未来趋势:Agentic RAG
如果说进阶 RAG 是对基础 RAG 的精装修,那么目前走在前沿的智能体RAG(Agentic RAG)则是对其进行了范式革命 。
在这个架构中,RAG 的身份发生了根本性的转变:它不再是整个系统的核心,而是被降级为一个可供调用的工具 。
真正的主角,变成了智能体(AI Agent)。
当 AI Agent 接到一个复杂任务,比如「 分析并对比 A、B 两家公司最新财报中的AI战略 」
它会开始以下动作:
规划
“我需要先找到A公司的财报,再找到B公司的财报。”
调用工具
“调用 RAG 工具,在内部文档库中查询「 A公司最新财报 」。” 然后,“再次调用 RAG 工具,查询「 B公司最新财报 」。”
反思与整合
AI Agent 会评估 RAG 返回的内容是否准确。如果信息不足,它甚至可能决定调用「 网页搜索工具 」去网上查找。最后,它将所有收集到的信息进行整合、对比,并生成最终的分析报告。
在这个模式下,RAG和长上下文窗口的协作关系变得无比清晰:
RAG负责输入
作为最高效的信息获取工具,它将为 AI Agent 提供精准、可靠、可追溯的外部知识。
长上下文负责工作台
广阔的上下文窗口成为了 AI Agent 进行多步推理、整合不同来源信息、维持对话记忆的工作内存。
RAG 负责从庞大的知识海洋中精确钓鱼,而长上下文则提供了足够大的甲板 来处理这些鱼。你不能因为甲板变大了,就认为不再需要好的鱼竿和声呐探测器了。
写在最后
回顾 RAG 的演进之路,并理清其与上下文工程的关系:
- 基础RAG解决了从无到有的问题。
- 进阶RAG作为高级的上下文工程技术,解决了从有到优的问题,在成本、效率和精度上远胜于暴力填充。
- AgenticRAG则将其升维,使其成为智能体进行复杂任务时,不可或缺的知识获取工具,与长上下文窗口形成完美的协作。
“RAG 已死”的论调,源于一种将手段与目的混淆 的误解。
RAG 的本质,是一种让模型在可控、可靠的范围内动态利用外部知识的设计哲学。
只要大模型自身知识的实时性、准确性和私有性问题依然存在,只要我们追求的不仅仅是「 能回答 」,而是「 回答得又好又快又经济 」,这种哲学就不会过时。
所以,RAG 不仅没有死,它正在以更加成熟和强大的形态,深度融入未来的 AI 技术栈。它不再仅仅是一个“ 外挂配件 ”,而是正在成为构建高阶AI应用不可或缺的“ 内置工具 ”。
长文撰写不易,如果屏幕前的伙伴认为内容对你有帮助,欢迎点赞、转发、推荐和关注,「 真知灼见 」 专栏也将持续更新一些我对这个行业的理解。
作者:周乾镇 编辑:周乾镇 公众号:快速通道Fastrack
本文由 @快速通道Fastrack 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议









RAG的知识可以是海量的“试题”吗,还是说应该是课本的内容?