
 起点课堂会员权益
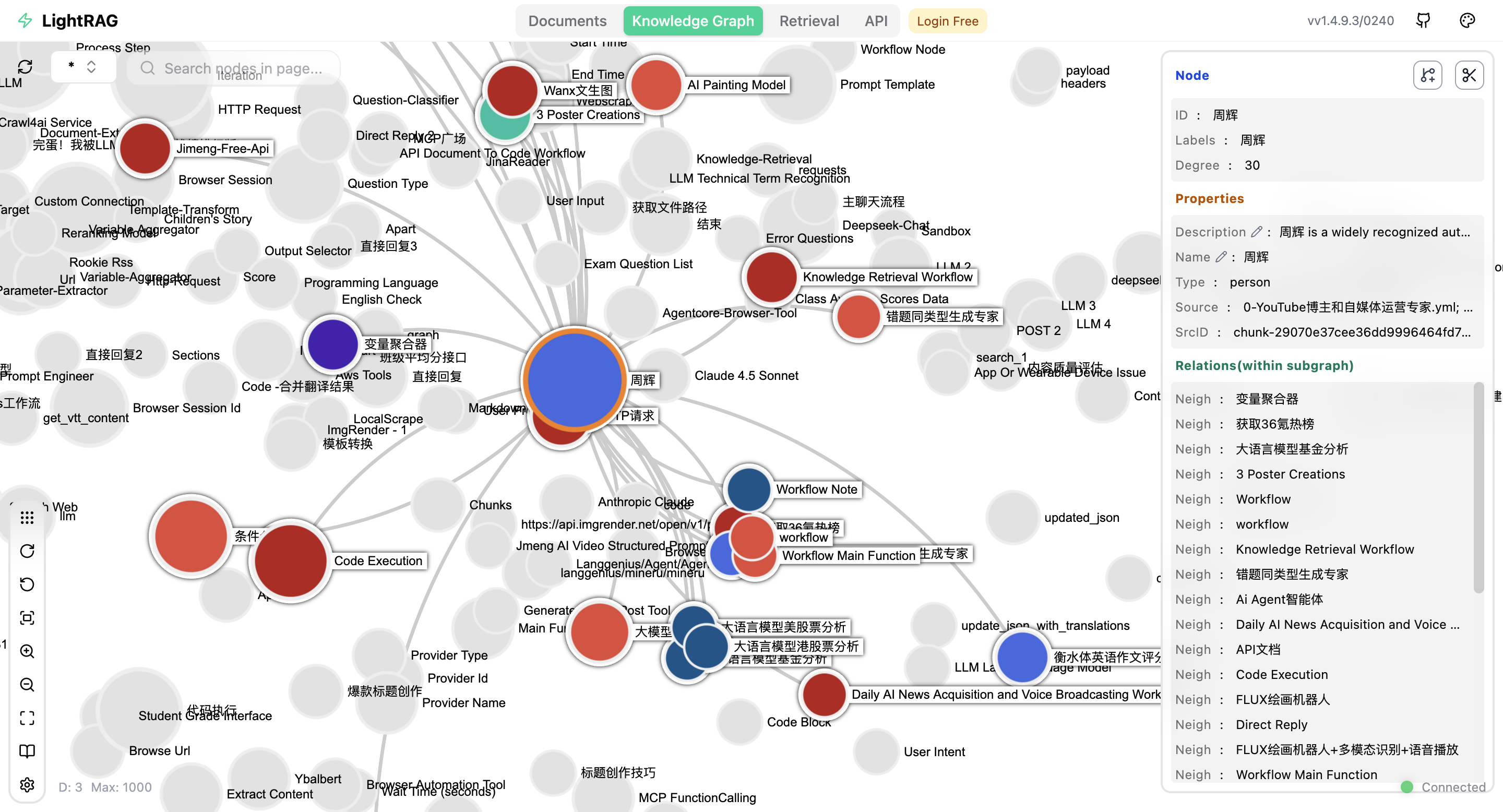
起点课堂会员权益LighRAG与Dify的集成与基本检索原理
RAG应用正在进入“工程化落地”阶段,而工具之间的协同能力成为关键变量。本文以LighRAG与Dify的集成为例,系统梳理其底层检索原理与集成逻辑,帮助产品人、AI工程师理解如何构建高效、可控的智能问答系统,为Agent化应用打下坚实基础。

0. 效果演示
1. LightRAG简介
LightRAG是一款轻量级知识图谱增强检索框架,由香港大学的研究团队开发。它与传统RAG系统的根本区别在于,将图结构集成到文本索引和检索过程中,解决了单纯向量检索中遇到的关系缺失、语义模糊等问题。
LightRAG具有以下几个显著特点
- 轻量高效:最小化知识图谱存储和计算开销,确保系统不会因为引入图结构而大幅增加资源消耗。
- 易于集成:提供简洁API,可与现有RAGpipeline快速整合,开发者可以轻松将其嵌入现有系统中。
- 多模态支持:能同时处理结构化与非结构化数据,适应多样化的数据源。
- 可解释性强:提供检索路径的透明解释,让用户清楚了解答案的生成过程。
与传统RAG的对比
- 传统RAG系统依赖于扁平化的数据表示,难以捕捉实体之间的复杂关联
- 上下文感知能力不足,导致回答缺乏连贯性。
LightRAG通过引入基于图结构的文本索引方法和双层检索机制,从根本上提升了信息检索和生成的效率与质量。
2. 如何集成到Dify
最简单的方式是直接通过HTTP Request节点,但为了更好的拓展性,我们将LightRAG封装为工具直接作为节点被调用。
Dify Console -> Tools -> Custom -> Create Custom Tool
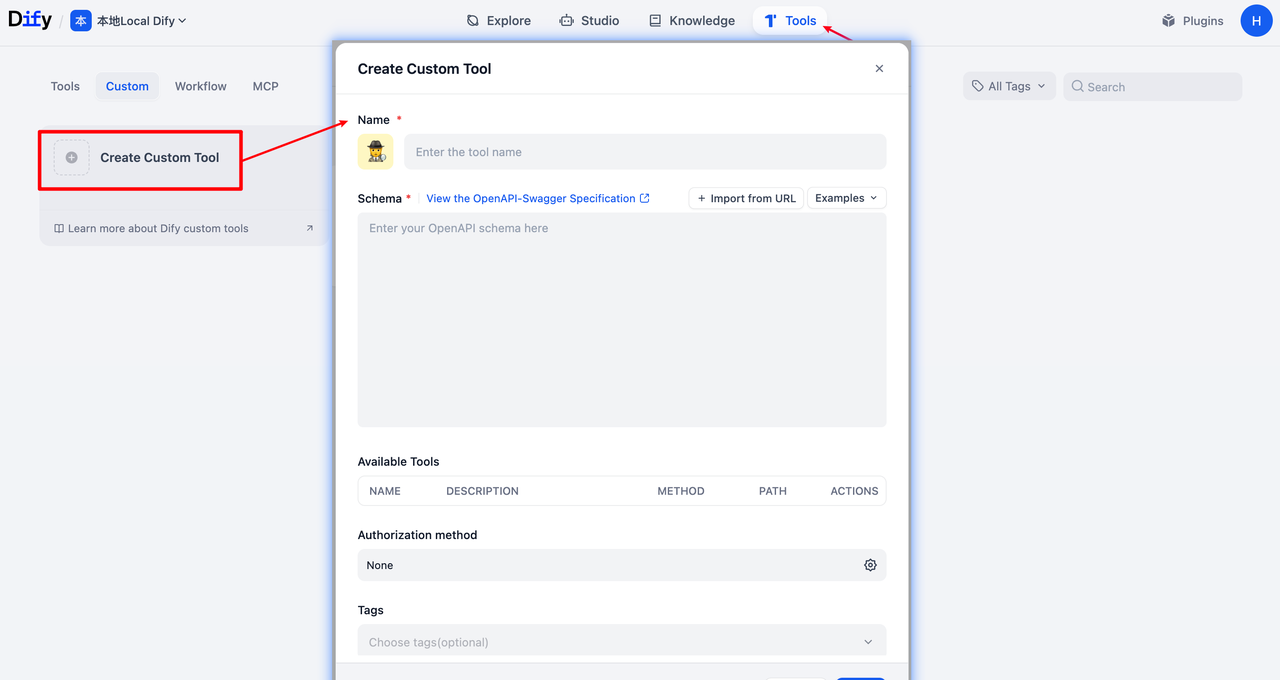
填入符合OpenAPI-Swagger规范的Schema,直接可以获取LightRAG提供的全部API工具
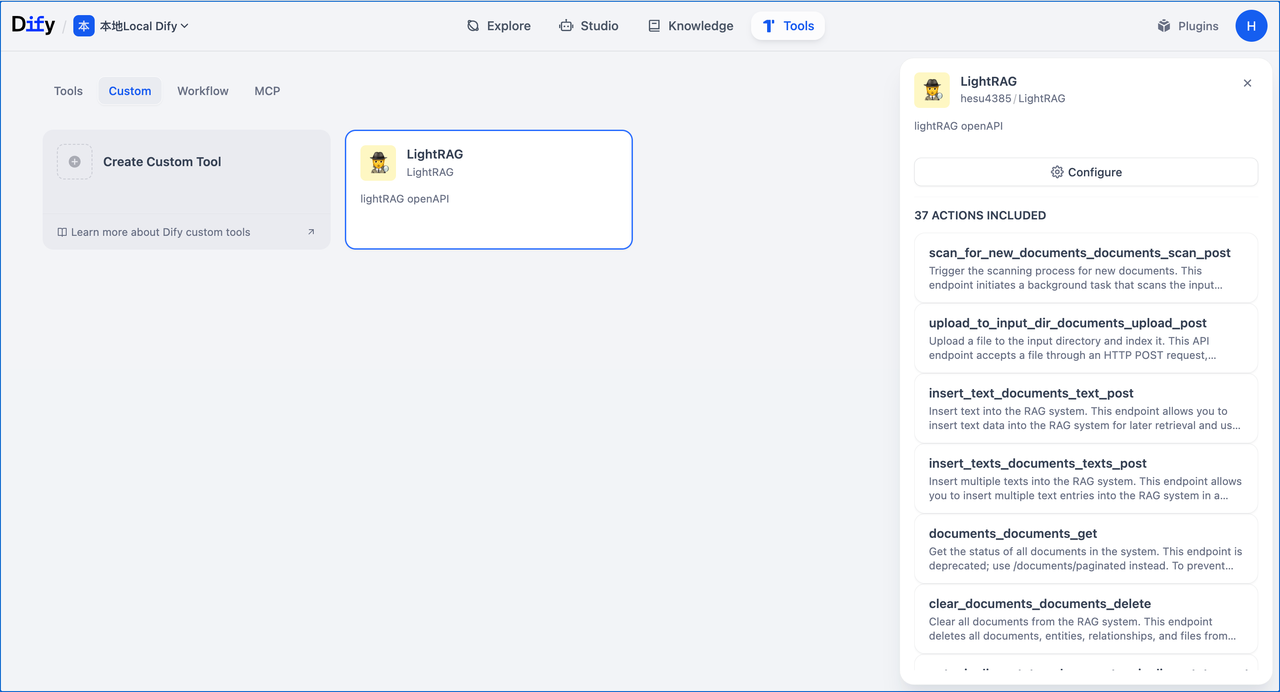
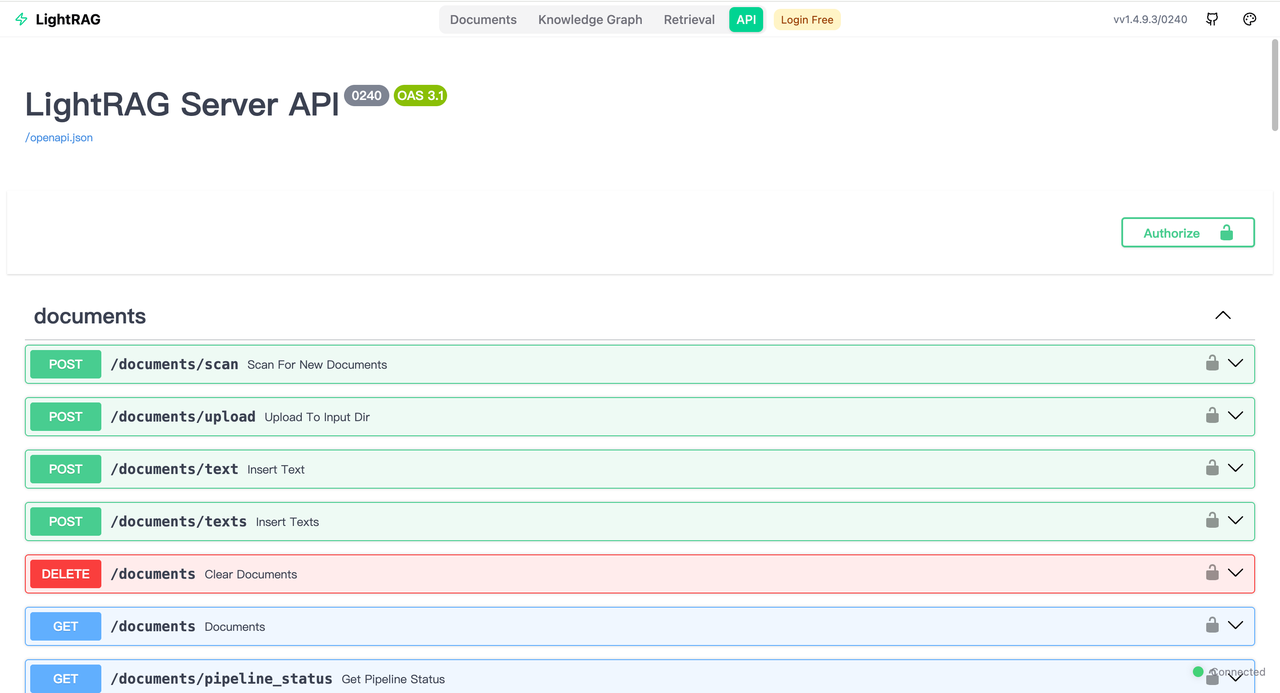
创建好后,就可以在Dify工作流里调用了。
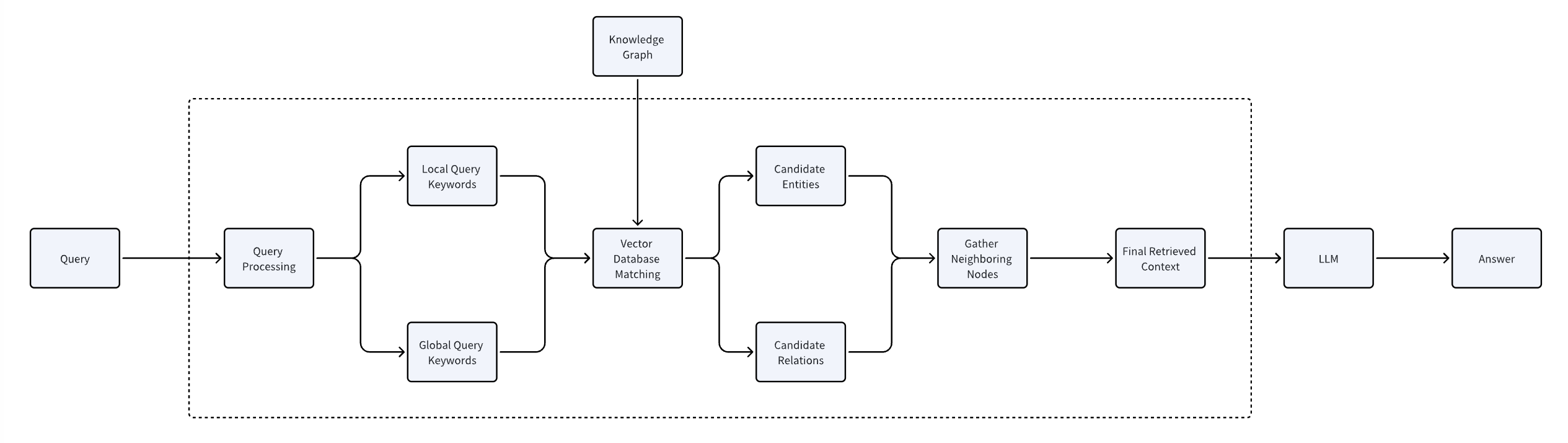
3. LightRAG的检索基本原理
LightRAG 目前对外暴露的查询接口只有两种:
1. naive_query
- 只做“纯向量”召回:把用户问题向量化,到文本向量库(chunks_vdb)里做相似度检索,取top-k段原文,直接送进LLM生成答案。
- 不涉及知识图谱,也不区分实体/关系,适合快速demo或事实性不强的闲聊场景。
2. kg_query(Knowledge-Graph Retrieval)
基于知识图谱的混合检索,在内部会根据参数走三条路径,调用时通过 QueryParam(mode=…) 指定:
- local–仅检索实体向量库(entities_vdb),定位与问题最相关的实体节点,再把实体描述及相邻文本块喂给LLM。
- global–仅检索关系向量库(relationships_vdb),拿到与问题最相关的关系三元组及其上下文,用于“主题性”“综述性”回答。
- hybrid–同时做local+global召回,把实体、关系、原文片段一并交给LLM,兼顾细节与全局。
本文由 @AIDT智享远方 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






评论
- 目前还没评论,等你发挥!


