
 起点课堂会员权益
起点课堂会员权益亲测阿里Qwen最新闭源模型+夸克最全工具箱,王炸组合强得可怕!
在AI时代,如何选择一个真正能解决复杂问题的智能助手?这篇文章通过作者亲身测试,对比了GPT和夸克的“对话助手”,发现夸克在处理复杂的健康问题时表现出了惊人的专业性和深度。

最近我动了个心思,想多拍点视频,好好做个人IP。毕竟AI时代,真人出镜的价值和信任感是不可替代的。但上周参加活动,朋友随手拍了几张照片,拿到手一看,心里咯噔一下——我这脸怎么这么大?!
我身高187,体重76公斤,好多朋友见面都说原来你这么高,但我不算胖,只不过这“大饼脸”一上镜,就显得特别“发福”。
这一下戳中了我的焦虑。我这情况还挺复杂:42岁,尿酸偏高,有轻度脂肪肝,日常还久坐办公。我隐约觉得这些问题是关联的,但又说不清。
我也问了GPT,老实说,给的答案不大满意。正好夸克的朋友和我说,他们10月23日刚上线了“对话助手”。我之前参加过他们的活动,知道夸克在“健康大模型”上积累很深,这次又有“Qwen最新闭源模型”支撑,于是决定,把我这个“要命”的复杂问题,扔给它试试!
一个复杂的“中年调理”实战
我打开夸克APP,点了“助手”,把我所有的情况原封不动地输了进去:
Prompt: “我今年42岁,男性,身高187,76公斤,尿酸偏高,同时有轻度脂肪肝,然后脸明显发福,应该是脂肪型脸,希望能瘦脸,想做个人IP需要出镜,同时日常坐着办公,久坐。请帮我分析一下这三种情况的关联性,并从饮食和运动两方面,给出一份可执行的、有科学依据的调理方案。”


参考了23篇资料后,夸克给出了内容非常详细和专业,我把它几乎完整地贴在下面



这个回答的质量,坦白说,和GPT完全不在一个层面。
首先GPT的DeepResearch给的答案是“通用废话”,并且又臭又长,排版上就已经看不下去了:


而夸克的方案,光看目录就赢了:它不仅有“饮食”和“运动”,还有“问题关联性分析”和“生活习惯与监测”。
它给出的“可执行方案”真正让我信服:
1.饮食方案: 不是泛泛的“少油少盐”,而是明确的“低嘌呤饮食”、“护肝减脂饮食”(控糖控脂、关键营养素),甚至给出了详细的“参考食谱”。
2.运动方案: 它没有只说“多运动”,而是针对我“久坐”的痛点,给出了“全身减脂”、“针对性瘦脸训练”和“久坐办公调整”的组合拳。
这已经是一份非常出色的方案了。但真正让我震撼的,是当我仔细阅读第一部分时…
Aha! Moment:在医疗问题上,“专业洞察”是1
如果说GPT的回答是60分的“通用知识”,那夸克这份回答就是95分的“专业洞察”。
真正的“Aha! Moment”,就藏在它回答的第一部分:“1. 代谢综合征关联”。
GPT只会把我“尿酸高”和“脂肪肝”当成两个孤立的问题来回答;而夸克则凭借其深厚的“健康大模型”知识库,一针见血地指出了两者共同的根源——“胰岛素抵抗”。
这就是“专业”和“通用”的根本区别!
它瞬间帮我建立了一个清晰的认知:我的目标不该是“瘦脸”,而是“调理代谢”。这一点还确实挺厉害了!
在医疗健康问题上,“可信赖”是那个1,其他所有体验都是后面的0。
GPT给不了我这个“1”,它只是“通用知识”的搬运工。而夸克的“可信赖”,体现在它回答的专业深度和医学逻辑上。它不是在“猜”答案,而是真的在像一个专业顾问一样,“基于医学知识库和交叉验证”来“生成”诊断和方案。
专业推理能力
一个好的助手,还要能“举一反三”。我决定再“刁难”它一下,测试它在复杂场景下的推理能力。
Prompt : “这个方案很专业。但我久坐,很难执行。请你结合我“日常久坐办公”的特点,给我一个非运动时间的“微习惯”调整方案,并且帮我查一下‘间歇性禁食’(比如16:8)对我的情况(尿酸和脂肪肝)是否安全?”
这个问题很“要命”,它同时考验:
1.对“久坐”场景的个性化理解。
2.对“间歇性禁食”这种热门但有争议方案的深度检索和辨析。
3.对“高尿酸”和“脂肪肝”这两个冲突限制条件的专业判断。




看到这个答案,我彻底服了。
如果说第一个回答是“专业”,这第二个回答就是“专家级推理”。
高光时刻在于它对“间歇性禁食”的安全性评估。它没有泛泛的聊16:8,而是精准地抓住了我的“高尿酸”和“脂肪肝”这两个“冲突限制条件”:
1.指出风险: 它明确警告我,禁食产生的“酮体”会与“尿酸”竞争排泄通道,可能导致血尿酸升高。这是一个救命的专业建议!
2.平衡利弊: 它同时肯定了禁食对“脂肪肝”的积极作用。
3.给出方案: 它没有一刀切,而是给出了“安全建议”(如先尝试14:10)和“替代方案”(如定时多餐)。
特别是提到了尿酸>500可能会有更多影响,黄叔之前应该是400多,今年不知道涨了没,正好过段时间要去做体检,所以这个最好是等我体检完之后,知道了最新的数据再去执行。
这种表达可以发现夸克更多是“可信知识”,给了我一种“中国版ChatGPT”的感觉。
多说一句,助手还能做非常多的事
核心还是夸克有着全网最全的工具箱,然后背后再加上前面强悍的模型能力。
我们随便举个例子,很多大学生都需要四六级的学习资料:


秒出,还能直接保存到自己的网盘,也可以快速查看具体的资料,不要太方便哦!
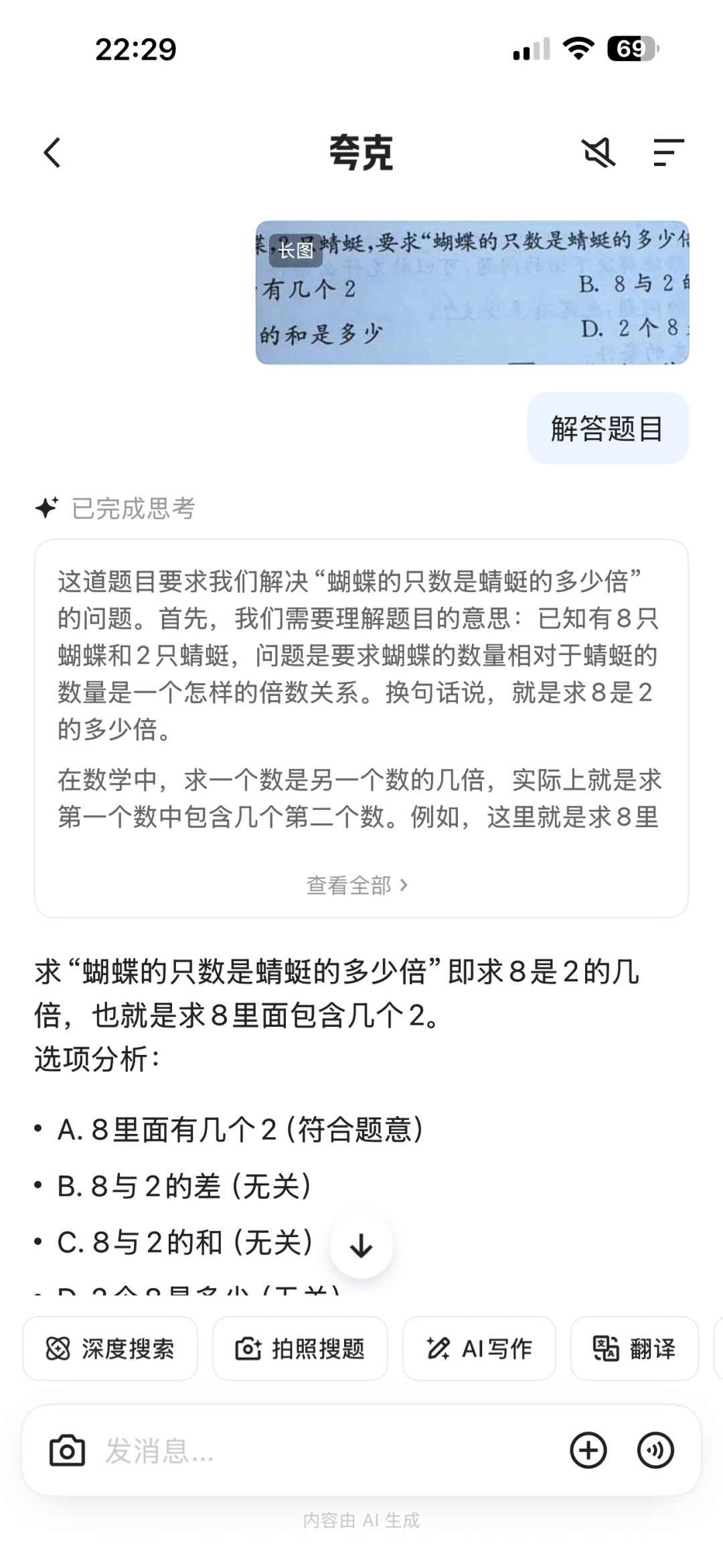
以及写作、相机解题等等,效果都非常好:

为何对话助手现在这么强了?答案请往下看:
为什么夸克能做到?模型才是AI助手的灵魂
其实发展到现在,大多数场景下,模型即产品,夸克的对话助手的表现这么好,很重要就是模型能力够强。
这次实测,让我深刻体会到“通用AI”和“专业AI”的鸿沟。
GPT之所以“不大满意”,因为它是一个“通用”模型。而夸克“对话助手”之所以能给我“处方级”的方案,是因为它完美践行了阿里“模型即应用”的战略,采用了“模型+系统”的双轮驱动:
1.顶级的模型发动机(Qwen最新闭源模型)
夸克助手背后,用的是阿里Qwen最新的闭源模型,很可能是“比Qwen3-Max更Max”的存在。
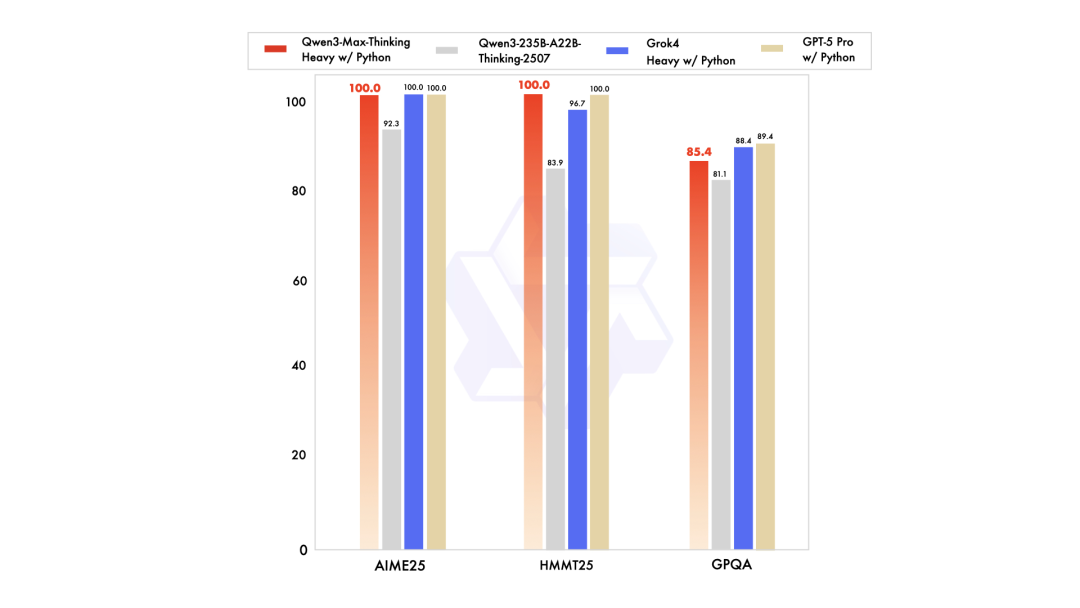
为什么我能体验到“ChatGPT级”的复杂病理关联和“专家级推理”?因为底座的模型能力就在那里。 就以其家族标杆Qwen3-Max为例,预训练数据量达36T tokens,总参数超过万亿。
Qwen3-Max在聚焦Agent工具调用能力的Tau2-Bench测试中,取得了超过Claude Opus4的74.8分;其推理增强版本,更是在聚焦数学推理的AIME 25和HMMT测试中,均达到突破性的满分100分——这是国内首次! 这种在数学、推理、代码上的顶尖能力,被夸克用来做“健康调理”以及多个领域的复杂推理,这才是真正的“降维打击”。
2.可信赖的系统保障(专业知识库+最全工具箱)
如果说Qwen最新闭源模型是F1引擎,夸克自研的“健康大模型”专业知识库就是“专业赛道图”,而“实时检索、信源追溯、交叉验证”系统,就是“导航和刹车”。
阿里打通了“模型即应用”的最后一公里:顶尖的模型能力,通过夸克这个“最全工具箱”和“可信系统”,精准地赋能到了我这个“中年发福”的真实需求上,哈哈哈。
我的体验也印证了市场的选择。
根据AIGRank在9月的《中国AI应用排行榜》,夸克的平均日活领跑市场。

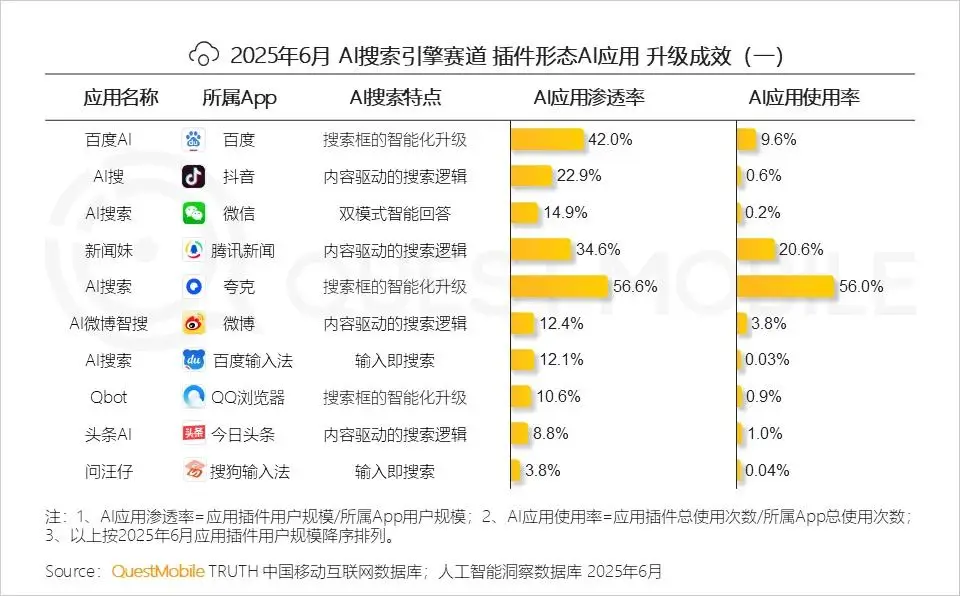
在QuestMobile的《2025年AI应用市场半年报》中,夸克AI搜索的渗透率和使用率双双领先,分别达到56.6%和56%:
当行业还在用花哨的功能“堆砌”AI时,夸克选择了一条更难的路:靠模型硬刚,做那个“说真话”的助手。
对于我们这些真正想用AI解决问题的人来说,这,才是AI助手该有的样子。
本文由人人都是产品经理作者【Super黄】,微信公众号:【AI产品黄叔】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。






- 目前还没评论,等你发挥!


