
 起点课堂会员权益
起点课堂会员权益评测驱动开发:AI产品经理驾驭大模型时代的核心法则
在大模型时代,产品经理的角色正在被重新定义。评测驱动开发不仅是一种方法论,更是一套帮助 AI 产品经理驾驭复杂系统、提升决策质量的核心法则。

引言:你的AI产品,正在“盲飞”吗?
在大模型(LLM)时代,AI应用的开发正面临前所未有的挑战。我们过去习惯的开发模式——依赖预设用例测试、部署后再观察验证——如今就像在风云变幻的空中“盲飞”,难以为继。
为什么这么说?因为基于大模型的AI应用,其行为具有高度的随机性和不可预测性。
一个LLM Agent在处理复杂任务时,可能这次表现优异,下次却谬以千里。
在多Agent协作的流程中,每一步的微小误差都可能被放大、累积,最终导致整个系统的准确率断崖式下跌。
这种根植于技术底层的不确定性,正是AI产品经理面临的核心困境。
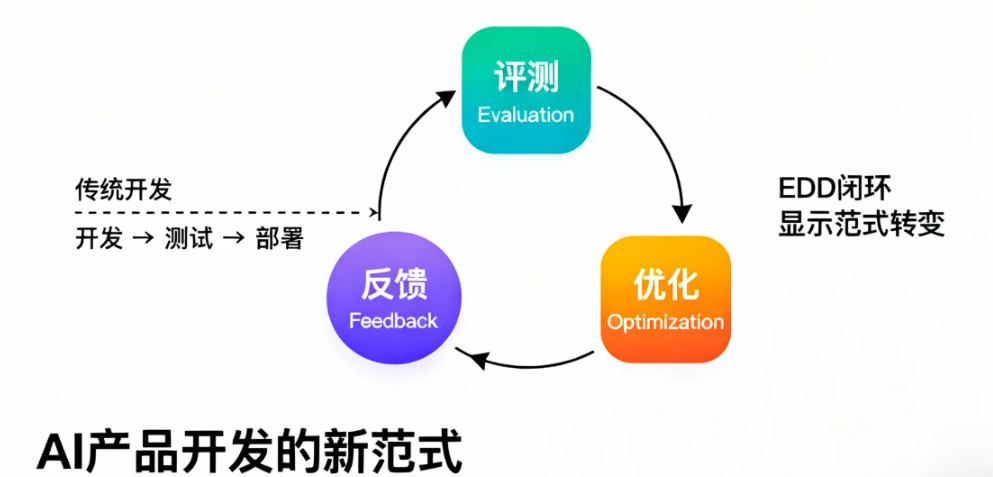
正因如此,一种新的研发范式——评测驱动开发(Evaluation-Driven Development, EDD)——正迅速成为确保AI应用成功的关键。EDD通过将系统性评测深度嵌入开发全流程,形成“评测-反馈-优化”的闭环,为驾驭复杂的AI系统提供了质量保障、系统稳定和建立用户信任的导航塔。
本文将从理念、工具、流程到文化,为你提供一套完整的EDD实践指南,帮助你和你的团队告别“盲飞”,精准导航,真正驾驭AI产品的未来。
一、基石篇:EDD的核心价值与三层评估框架
要用好EDD,必先理解其道。本章将深入阐明EDD的理论基础,解释其核心思想、重要性及基础框架,为后续实践奠定坚实的认知基石。
1.1 EDD:从“验证后置”到“评测牵引”的范式革命
传统软件开发,如测试驱动开发(TDD),其核心是通过精确的测试用例,确保每个代码单元的行为符合确定性预期。这就像校准一台精密的工业机械。
然而,AI应用,特别是基于大模型的Agent,其本质是概率性的,决策逻辑是隐式的。我们面对的不再是一个输入输出关系明确的系统,而是一个行为呈现概率分布、边界模糊且动态变化的“黑盒”。
EDD(Eval-Driven Development)正是为应对这一转变而生的新范式。*它是一种以持续评测为核心驱动力,通过系统性验证和优化AI智能体能力与行为逻辑的方法论。
其本质区别在于,EDD不再是开发完成后的“产物检验”,而是贯穿始终的“能力认证”。
它将评测前置并融入开发全流程,从“验证后置”转变为“评测牵引”,通过持续的反馈循环来把握AI系统的能力边界与风险,从而指导优化方向。这标志着软件工程从应对确定性逻辑,向驾驭概率性输出的根本性转变。
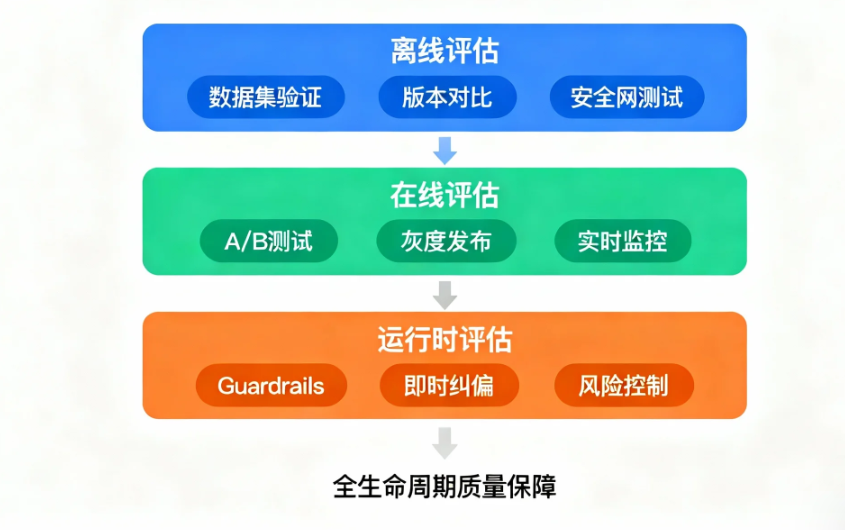
1.2 保障质量的三大支柱:离线、在线与运行时评估
为了全面实施EDD,我们需要建立一个覆盖AI应用全生命周期的评估框架。该框架主要由三种核心评估形式构成,它们相辅相成,共同保障产品质量。
1)离线评估(Offline Evaluation):发布前的基线把关
离线评估是在模型或应用部署前,基于静态、预先标注的数据集进行的验证。它如同传统软件测试中的回归测试,为新版本提供了一个可重复、可控的“安全网”,能在新版本上线前筛查大部分已知问题。例如,巴西金融科技巨头**Nubank**在开发其客服与转账Agent时,会由人工和LLM共同对不同模型版本的输出进行逐样本比对,并结合统计检验来确定是否存在显著改进。尽管离线评估难以完全模拟真实世界的复杂场景,但它在发布前质量控制中的基石地位无可替代。
2)在线评估(Online Evaluation):真实世界的试金石
在线评估发生在模型实际运行环境中,通过A/B测试、灰度发布或对线上真实流量的持续监控来考察模型表现。这是检验模型在“真实世界动态条件”下表现的终极试金石,能够有效捕获离线测试无法覆盖的长尾问题和真实的用户偏好。业界领先的LLM应用开发与监控平台LangSmith,就提供了强大的线上监控功能,允许开发团队持续观察应用的延迟、错误率及输出质量等关键指标,从而快速发现性能衰退或模型漂移问题。
3)运行时评估(Runtime Evaluation):高风险输出的即时纠偏
运行时评估是一种在系统推理过程中实时介入、评估并干预模型输出的机制,充当着“最后防线”的角色。它通常被设计为守护或监督模块(Guardrails),用于即时纠偏高风险输出。一个典型案例是专为法律行业设计的AI平台Harvey,它在生成法律文书后,会实时调用一个引证检查Agent来验证所有引用的法规或判例是否准确,一旦发现错误,便会反馈并要求重新生成,从而显著提升了输出的可靠性与安全性。这类评估对于在金融、法律等高风险领域建立用户信任至关重要。
1.3 PM的第一课:设计场景化的评估指标体系
评估的有效性,始于科学的指标设计。对于AI产品经理而言,首要任务是确保评估指标与具体的业务场景和用户价值紧密绑定,而非盲目追求通用技术分数。
脱离业务场景的评估指标,即便得分再高,也可能与线上实际效果脱节。
Nubank的实践为我们提供了绝佳范例。
在构建其客服聊天机器人时,除了“准确性”,他们还量身定制了“同理心(Empathy)”这一关键指标,用以衡量AI是否能以恰当的语气和态度与用户沟通。
然而,在处理转账任务的Agent时,评估的重心则完全转移到了“准确性(Accuracy)”上,确保金额、收款人等关键信息万无一失。
这种场景化的指标设计,要求产品经理深入理解用户需求,将模糊的用户体验拆解为可衡量、可优化的具体维度,从而真正驱动产品向着为用户创造价值的方向迭代。
二、利器篇:AI评测工具链选型与实践指南
理论的落地离不开强大的工具支持。本章将聚焦于主流AI评测工具,帮助产品经理理解其能力边界,并根据不同场景制定合理的选型策略。
2.1 主流平台全景图:LangSmith vs. 扣子(Coze)
当前市场涌现出众多LLM评估工具,其中LangSmith和字节跳动旗下的扣子(Coze)平台是两个具有代表性的选择。
LangSmith: 由LangChain团队打造,定位为“用于构建生产级LLM应用的平台”。它是一个以开发者为中心、功能全面的可观测性(Observability)与评估平台。虽然与LangChain生态无缝集成,但其设计是框架无关的,可与任何LLM框架配合使用。其核心功能包括详尽的Trace追踪、灵活的数据集管理、以及强大的评估器(Evaluators),尤其支持使用LLM作为裁判(LLM-as-a-Judge)进行自动化评估。
扣子(Coze): 作为一站式AI Bot和Agent开发平台的一部分,扣子的评测功能更侧重于AgentOps的闭环体验。它旨在帮助开发者快速验证和迭代Prompt或模型效果,其突出特点是能够建立自动化评测体系,并支持将线上反馈数据回流,形成持续优化的数据飞轮。这种设计与Agent的快速开发和运营流程紧密耦合。

2.2 按图索骥:不同场景下的工具选型策略
产品经理在选择工具时,应从实际业务场景出发,结合团队现状进行决策。
场景A:已有线上应用优化
对于已经上线、拥有稳定流量的AI应用,优化的关键在于利用真实用户数据发现问题并进行回归测试。在这种场景下,优先考虑具备强大线上数据采集、监控和自动化回归测试能力的平台。扣子(Coze)的评测体系,特别是其强调的将线上反馈数据无缝接入评测体系的设计,非常适合构建持续改进的数据飞轮。
场景B:从零开发新应用
在从零开始构建新应用时,灵活性、快速迭代验证和广泛的生态支持是首要考虑因素。LangSmith凭借其框架无关的设计、与LangChain生态的紧密结合以及灵活的评估器定义能力,为开发者提供了极大的便利,能够快速搭建原型并进行系统性评估。其详尽的追踪功能对于调试复杂的Agent行为尤为关键。
关键考量因素:
- 成本:LangSmith提供阶梯式定价,包括免费的开发者计划和付费的企业计划。而Coze平台目前主要以免费模式吸引开发者。成本是初创团队和个人开发者需要重点权衡的因素。
- 数据安全与私有化部署:对于处理敏感数据(如金融、医疗)的企业,数据安全是红线。LangSmith的企业计划支持私有化部署(Self-Hosting),允许企业在自己的基础设施上运行平台。产品经理需评估业务数据敏感性,确认所选工具是否满足合规要求。
- 团队技术栈与社区支持:如果团队深度使用LangChain或LangGraph,选择LangSmith会获得最平滑的集成体验。同时,LangSmith拥有活跃的社区和丰富的文档,便于解决开发中遇到的问题。
2.3 赋能业务:PM如何利用工具提升效能
选对工具只是第一步,产品经理更需要思考如何利用工具赋能业务,提升整个团队的研发效能。
构建可复用的评估资产
评估数据和评测脚本是宝贵的核心资产。借鉴法律AI公司Harvey的实践,他们将评估方法制度化,构建了包含定制评估标准(Rubrics)的内部基准测试集。产品经理应推动团队利用LangSmith等工具的数据集管理功能,将有价值的测试用例、失败案例进行版本化管理,沉淀为可复用的“黄金测试集”,用于新版本的回归测试,防止性能退化。
实现数据驱动的快速迭代
工具提供的可视化看板和评估结果分析,是产品经理进行数据驱动决策的有力武器。Nubank以其“每两分钟一次部署”的高频迭代而闻名,这背后离不开强大的自动化测试和评估体系支持。产品经理可以利用LangSmith的实验对比视图,直观比较不同Prompt或模型版本的性能差异,快速验证改进效果,从而缩短“假设-验证-发布”的周期,驱动产品快速迭代。
三、协作篇:评测驱动下的团队文化与流程重塑
EDD的成功不仅依赖于先进的工具,更需要组织文化和团队协作模式的深刻变革。产品经理作为跨职能团队的核心,必须主动推动这种变革,将评测理念融入团队的DNA。
3.1 构建透明、敏捷的协作文化
在AI开发的不确定性面前,开放透明的沟通和拥抱变化的敏捷文化至关重要。AI产品开发更像是一场持续的探索,而非按图索骥的工程。团队需要建立一种心理安全区,鼓励成员快速试错、分享失败并从中学习。
AI项目中的许多问题源于团队成员之间的认知偏差。通过建立“一切问题群聊”的沟通机制,可以强制对齐信息,确保每个人都在同一上下文环境中思考。同时,“拥抱变化随时打脸”的心态,鼓励团队基于新的评测数据快速调整方向,而不是固守最初的假设。
这种文化让评测数据成为团队沟通的“共同语言”,所有讨论都基于客观事实,而非个人直觉,从而提升决策质量和迭代效率。
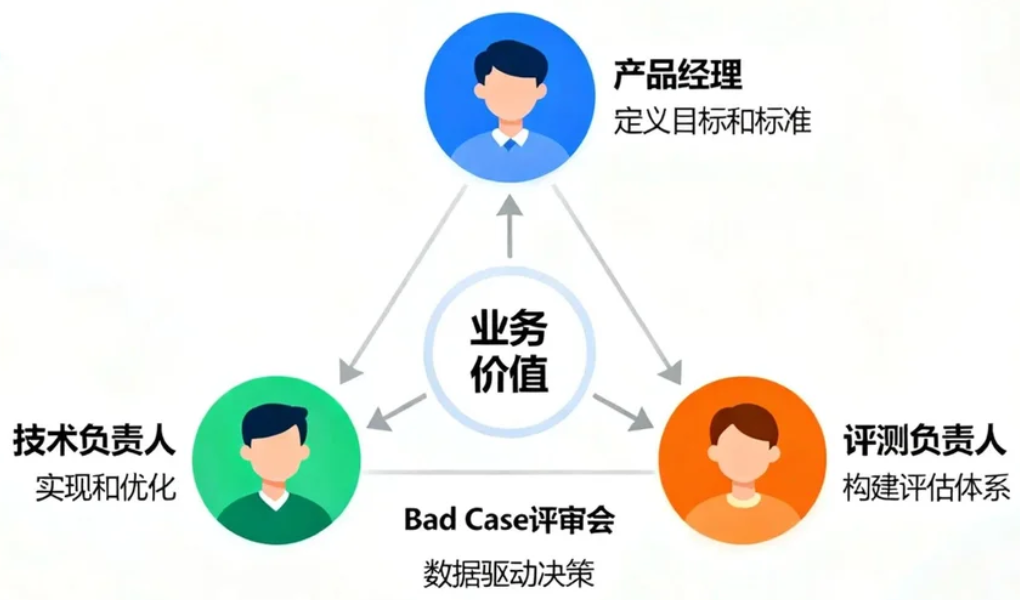
3.2 明确角色边界:产品、技术与评测的铁三角
在评测驱动的模式下,传统的角色分工需要重塑,形成一个目标一致、权责清晰的“铁三角”协作模型。
- 产品经理 (Owner):作为产品的最终负责人,核心职责是定义业务目标和评估标准。他们需要将模糊的用户需求转化为清晰、可衡量的评测指标(KPIs),并确保这些指标与最终的商业价值对齐。他们是“做什么”和“好坏标准”的定义者。
- 技术负责人/工程师 (Implementer):负责技术方案的设计与实现,以及根据评测结果进行性能优化。他们的目标是在产品经理定义的框架内,找到最优的技术路径,实现功能并满足性能要求。他们是“怎么做”的执行者。
- 评测负责人 (Evaluator):这是一个在新模式下愈发重要的角色,负责构建和维护评估体系,包括设计评测流程、开发评测工具、管理评测数据,并提供客观、公正的评测报告。他们是“如何衡量”的保障者,确保评估过程的科学性和可信度。
这三者通过定期的Bad Case评审会等机制紧密协同。在会上,团队共同分析失败案例,产品经理从业务角度判断问题严重性,工程师从技术角度剖析根源,评测负责人则思考如何将该案例转化为新的回归测试用例,从而形成高效的协作闭环。
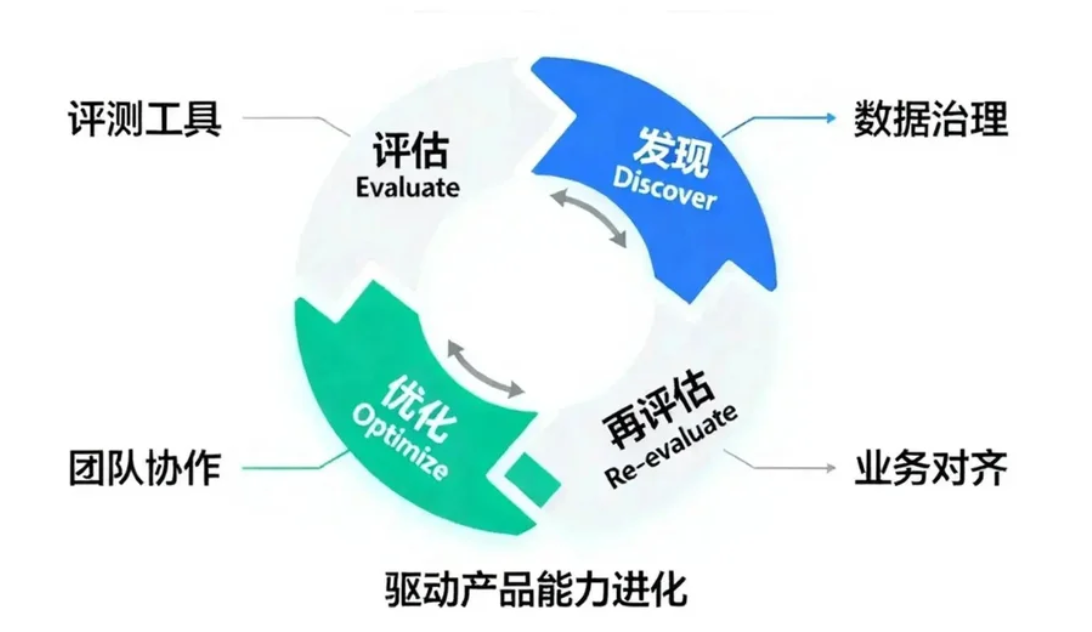
3.3 飞轮效应:构建“评估-发现-优化”的持续改进闭环
EDD的精髓在于构建一个自我强化的持续改进系统,即“AI原生飞轮”。这个飞轮通过将评测、问题发现和系统优化紧密连接,驱动产品能力不断进化。
这个闭环的运作流程如下:
1. 评估 (Evaluate): 通过离线、在线和运行时评估,系统性地测试AI应用的表现,并收集性能数据。
2. 发现 (Discover): 分析评估结果,特别是失败案例(Bad Cases)和用户负反馈,识别出模型的短板或流程的缺陷。例如,通过LangSmith等工具追踪线上异常,或通过人工标注发现不满足预期的输出。
3. 优化 (Optimize): 将发现的问题转化为具体的优化任务。这可能包括:
- 将失败案例添加至“黄金测试集”,作为未来版本的回归测试用例。
- 针对性地进行提示词工程(Prompt Engineering)、模型微调(Fine-tuning)或调整RAG策略。
- 改进业务流程或Agent的工具调用逻辑。
4. 再次评估: 优化后的新版本进入下一轮评估,验证改进效果。
通过不断转动这个飞轮,团队能够将每一次的“问题”都转化为驱动产品成长的“燃料”,实现研发效能和产品质量的螺旋式上升。
四、燃料篇:评测数据的设计与治理策略
如果说评测是驱动AI应用迭代的引擎,那么评测数据就是引擎的燃料。高质量、高相关性的数据是评估有效性的根基。产品经理必须将评测数据作为产品的核心资产来设计和治理。
4.1 黄金法则:评测集先行于训练集
在AI开发中,一个常见的误区是优先投入大量资源收集和标注训练数据。然而,EDD理念强调“评测集先行”。其背后的逻辑是:
一个清晰定义了“好”与“坏”的评测集,比海量的、未经定义优劣的训练数据,更能为产品指明正确的优化方向。
在项目启动初期,产品经理应与团队优先构建一个小的、高质量的“黄金评测集”。这个评测集代表了产品的核心应用场景和必须满足的质量底线。它就像一把标尺,后续所有的模型选型、Prompt优化和算法迭代,都应以在该评测集上的表现作为衡量标准。
4.2 从真实流量中挖掘“宝藏”用例
静态的评测集虽然可控,但往往无法覆盖真实世界中千变万化的用户行为和边缘场景。因此,从线上真实流量中持续挖掘有价值的测试用例,是丰富和完善评测集的关键。
加州大学伯克利分校(UC Berkeley)的研究者在构建数据处理Agent时,提出了一套行之有效的方法:他们利用工具自动从线上日志中提取“并聚类失败模式”,从而高效地生成新的评估数据集。产品经理可以借鉴这种思路,推动技术团队建立类似机制:
- 监控用户负反馈信号(如点“踩”、重写查询、对话提前中断等)。
- 对低评分或被运行时Guardrails拦截的交互进行聚类分析。
- 定期从线上流量中抽样,进行人工审查,发现意料之外的失败案例。
通过这种方式,团队可以主动地将“未知”的风险转化为“已知”的测试用例,持续提升评测集的覆盖度和挑战性。
4.3 质量与效率的平衡:人机协同的标注策略
高质量的评测数据离不开精准的标注,但纯人工标注成本高昂且效率低下。采用人机协同的标注策略成为必然选择。
法律AI公司Harvey的实践堪称典范,他们采用了“法律专家制定评估标准 + LLM自动评估 + 人工抽样复核”的混合模式。具体流程如下:
- 专家定标: 由具备深厚领域知识的法律专家设计详尽的评估标准(Rubrics),明确定义每个任务的评分细则。
- 机器初评: 利用强大的LLM(如GPT-4)作为“法官”,根据预设标准对模型输出进行初步打分和评估。
- 人工复核: 最后由人类专家对LLM的评估结果进行抽样审查和校准,确保评估质量的可靠性。
这种策略充分利用了LLM的规模化处理能力和人类专家的深度判断力,既保证了评估结果的专业性,又极大地提升了标注效率。
4.4 数据治理:将评估数据视为核心资产
积累的评测数据集将成为公司最宝贵的核心资产之一。因此,必须建立一套完善的数据治理策略来管理它们,确保其质量、可追溯性和安全性。产品经理需要推动建立以下治理机制:
- 版本控制: 像管理代码一样,对评测数据集进行严格的版本控制(如使用DVC),确保任何一次评测实验都是可复现的。
- 元数据记录: 为每个数据集和测试用例附加丰富的元数据,如来源、标注者、难度等级等,以便进行更细粒度的分析。
- 权限管理与安全: 对包含用户隐私或商业机密的数据,实施严格的访问控制和脱敏处理,确保数据安全合规。
- 数据目录与发现: 建立统一的数据目录(Data Catalog),让团队成员可以方便地查找、理解和复用已有的评测数据,避免重复造轮子。
通过有效的数据治理,评测数据才能真正成为驱动产品持续进化的、可信赖的“燃料”。
五、目标篇:让评测指标与业务价值同频共振
所有技术层面的评测,最终都是为了驱动业务成功。本章将探讨产品经理如何穿透技术指标的表象,确保评测体系始终与真实的产品价值和商业目标对齐。
5.1 穿透技术指标:与产品成功挂钩
准确率、召回率等技术指标固然重要,但它们往往无法直接回答“产品是否为用户创造了价值”这一核心问题。AI产品经理的核心职责之一,就是建立从技术指标到业务指标的映射关系,让团队的每一次优化都能对最终的商业成功产生可衡量的贡献。
以知名工作管理平台Monday.com为例,他们在构建其“数字劳动力”时,更关注AI Agent如何影响核心业务指标,例如:
- 任务处理效率提升:AI的介入是否缩短了用户完成特定工作流(如项目规划)的时间?
- 用户活跃度增长:引入AI功能后,用户的DAU/MAU或特定功能的使用频率是否提升?
- 用户满意度(CSAT):用户对AI辅助功能的满意程度如何?
通过将AI评测与这些顶层业务指标关联,产品经理能够清晰地展示AI项目的投资回报率(ROI),并确保技术团队的努力始终聚焦于最具商业价值的方向。
5.2 A/B测试:验证业务影响的终极武器
要科学地验证AI模型的迭代是否真正带来了业务价值的提升,A/B测试是无可替代的“终极武器”。它通过在真实环境中将用户随机分流,对比不同版本在核心业务指标上的表现,从而提供具备统计学意义的因果结论。
Nubank在优化其Agentic转账系统时,就广泛应用了A/B测试。他们不仅关注模型的技术准确率,更通过A/B测试直接衡量对“用户转账成功率”、“平均处理时长”和“用户求助人工客服的比率”等核心业务指标的影响。一个新模型版本,即便在离线评测中表现更优,也必须在A/B测试中证明自己能带来真实业务指标的显著提升,才会被全面推广。
对于产品经理而言,设计和解读A/B实验是关键技能。你需要与数据分析师紧密合作,确定实验的OEC(首要评估指标)、样本量、实验周期,并对结果进行科学分析。
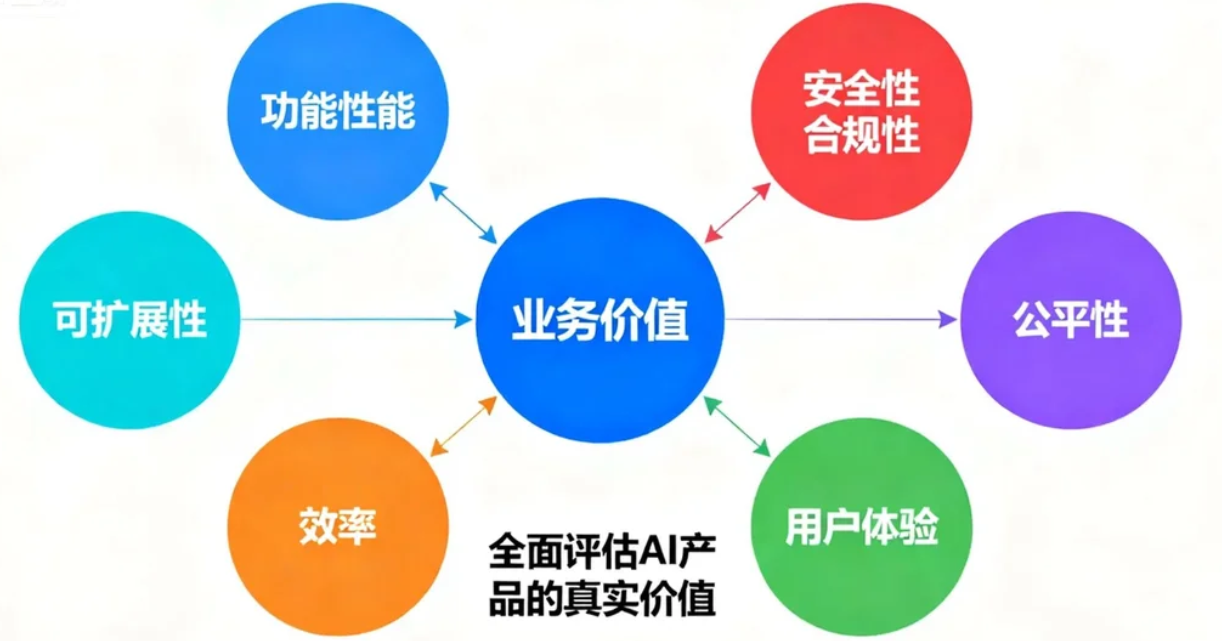
5.3 设计多维评估体系:超越准确率
一个成功的AI产品,其价值是多维度的。产品经理必须超越单一的准确率指标,构建一个全面的价值评估网络。这个评估体系应至少涵盖以下几个维度:
1)功能性能 (Functional Performance)
即模型完成特定任务的效能,包括准确性、相关性、简洁度、事实性(Groundedness)等。例如,法律AI Harvey会专门评估其RAG流程中检索、改写、生成等各个环节的性能。
2)安全性与合规性 (Safety & Compliance)
评估模型是否会产生有害、偏见或不合规的内容。这需要引入专门的“红队测试”(Red Teaming)和安全护栏(Guardrails)机制,如NVIDIA的NeMo Guardrails框架。
3)公平性 (Fairness)
评估模型对不同用户群体(如不同性别、地域、族裔)是否表现出一致的性能,避免产生歧视性结果。
4)用户体验 (User Experience)
这是一个综合性维度,包含:
- 有用性 (Usefulness):AI提供的功能是否真正解决了用户的问题?
- 满意度 (Satisfaction):用户在使用过程中的主观感受如何?(如Nubank关注的“同理心”)。
- 鲁棒性 (Robustness):在面对非标准输入或边缘情况时,系统是否能优雅地处理?
产品经理的职责就是统筹这些维度,根据产品阶段和业务目标确定不同维度的权重,从而全面、客观地评估AI产品的真实价值。
结语:成为驾驭AI的“飞行员”,而非“盲飞”的乘客
在大模型技术引领的AI原生时代,软件开发的范式正在经历一场深刻的认知革命。面对AI系统固有的概率性和不确定性,过去依赖确定性逻辑的开发与测试方法已然失效。沿用旧地图,我们只会在新世界中“盲飞”,最终成为被技术浪潮裹挟的乘客。
评测驱动开发(EDD)为我们提供了新的导航系统。它不仅是一套技术方法或工具集,更是一种全新的思维方式和工作流程。它要求我们将评测从流程的末端提升至战略的核心,将质量把控从“事后验证”转变为“事前牵引”和“全程护航”。
通过构建离线、在线、运行时三位一体的评估框架,善用LangSmith等评测利器,重塑跨职能团队的协作文化,像治理核心资产一样管理评测数据,并最终将所有评测指标与真实的业务价值紧密对齐——这便是AI产品经理在不确定性时代中,精准驾驭产品航向、确保其安全抵达商业成功彼岸的核心法则。
拥抱并主导这场变革,将评测内化为团队的核心竞争力。如此,我们才能真正从“盲飞”的乘客,转变为胸有成竹、手握罗盘的“飞行员”,自信地驾驭AI的力量,开创前所未有的产品价值。
本文由 @学不会AI 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议








可以分享下测试集具体如何构建吗,我目前也在做相关项目,这块构建的人力成本不少,特别是还有用户数据的保护政策限制,执行落地起来还会更难