
 起点课堂会员权益
起点课堂会员权益Skills不是高级MCP,他是给MCP擦屁股的…
MCP是必然产物,Skills却被调侃为“擦屁股的”。它们究竟是相互成就,还是彼此掣肘?这篇文章试图拨开迷雾,直击AI Agent架构背后的逻辑冲突。
最近看了一篇长文:《Skills explained: How Skills compares to prompts, Projects, MCP, and subagents》
这篇文章出自Anthropic官方,也许他自己也总是在疑惑:Claude Skills 和 MCP、Project 的区别到底是?
我们重点聊聊MCP和Skills,争取能从本质上把他说清楚,先说MCP:
一、MCP
Model Context Protocol (MCP) 是Anthropic提出的一种开放标准协议,它可以让AI模型能够与外部数据和工具发生交互。
与http协议类似,就是一个约定俗成的标准,只要大家遵守即可。
MCP出现的缘由很简单,大模型要真正的解决问题,一定需要与各种外部接口做交互,包括浏览器、数据库、文件系统…
在MCP提出之前,我们如果需要外部信息是怎么玩的呢?答案是定制化。
写一个中间程序,直接去调用大模型(获取请求),拿到大模型请求后、再调用API进行数据库读写、或者通过大模型返回的一些参数,再进行API调用,总而言之,用户访问的其实是中间程序,中间程序完成了大模型能力扩展的弥合。
但是有个人不爽:觉得不应该存在中间程序这种奇葩存在,于是他先在模型底层实现了固定格式的API调用,于是后续用户便可以直接访问大模型,而大模型可以自动调用该API进行数据库读写。
后续又衍生出文件读写、浏览器读写等需求,为了提升效率就沿用了之前的标准,最后发现挺好用,就形成了协议。
有了MCP后,AI与外部世界的交互有了统一标准,使 AI 应用能够无缝集成外部数据源和工具。
以上是相对粗暴的描述,如果我们想更多的挖掘可以看这张图:
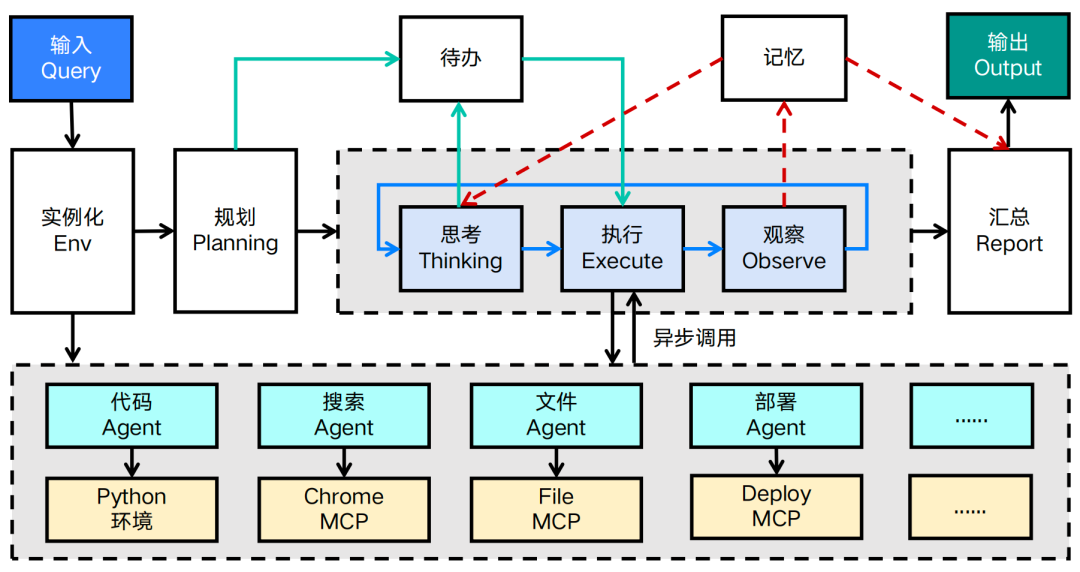
MCP是Agent发展过程中必然的产物,尤其是最开始这段时间,怎么解释呢?
模型诞生快3年了,从去年开始,无论推理能力还是上下文长度都得到了不小的加强,确实已经到了L2的地步,于是以Manus为标杆的Agent架构开始流行:
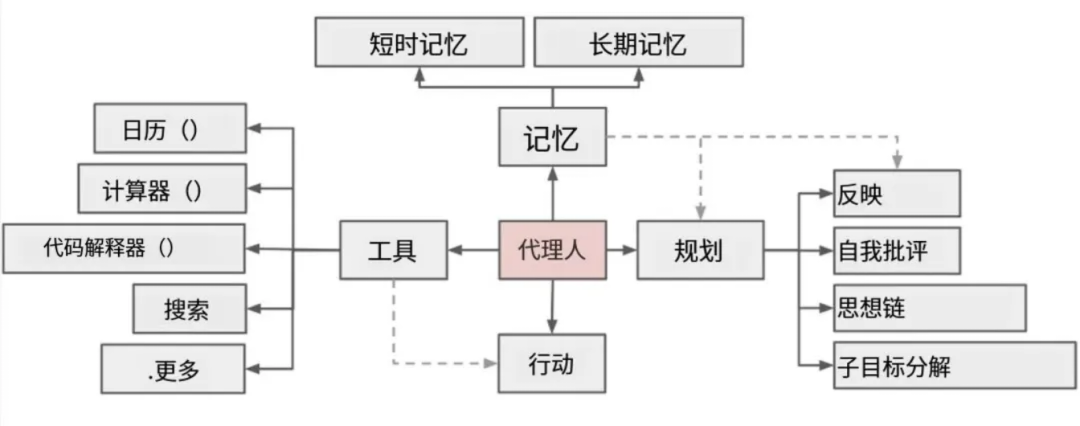
这个架构得以流行的前提一个是新技术突破(模型增强)、一个是互联网多年的各种积累,很多贴心的小工具他已经存在了,就等着我们去调用,比如我在微信与朋友聊天的时候:
- 朋友问我最近天气情况,我不用额外查询了,AI就直接给了我答案;
- 朋友发了个论文过来,我可以在微信中阐述翻译/解读的意图,而后微信就自然将论文翻译/解读了。
Agent架构、或者模型是没办法穷举我们无尽的意图的,但他可以提供有限的服务,如果我的某类意图命中了服务,那么就调用,这会让我们感觉很贴心:

这里所谓无限的意图、有限的实现也是我个人在做Agent项目时候的一个心得,我并不关心开放场景下Agent聊得怎么样,但如果命中了我的意图部分,那么其质量就必须严格保障。
举个实际工作中的案例,如果一个公司业务正常,那么他们一定会有BI看板,但老板一般缺少耐心去认真阅读数据,但善于面向老板编程的我们一定会实现很多MCP服务,等待着老板各种意图调用:
老板BI案例
首先是传统模式:
老板想了解:”上月华东区销售Top 3产品”
→ 打开BI系统 → 选择日期范围 → 筛选华东区 → 按销售额排序 → 看前3名
→ 整个过程5-10分钟
→ 巨婴老板失去耐心,开始骂人
MCP模式:
老板直接问AI:”上月华东区销售Top 3产品”
→ AI调用【BI工具.查询销售排行(区域=华东, 时间=上月, 数量=3)】
→ 10秒后给出答案
→ 老板很开心,我们吃鸡腿
接下来说下简单实现,首先是预制MCP工具包(相当于告诉AI,你有这些工具可以用):
# 这些工具在后台等着被老板”召唤”老板专用工具包 = {
“销售分析”: {
“区域销售排行”: “按区域查Top N产品”,
“同比分析”: “对比同期销售数据”,
“趋势预测”: “预测下月销售情况”
},
“客户分析”: {
“大客户清单”: “找出消费最高的客户”,
“流失预警”: “识别可能流失的客户”
},
“运营分析”: {
“库存预警”: “检查库存不足的产品”,
“成本分析”: “分析各产品成本结构”
}
}
因为,“服务员提供了这些菜单”,所以AI在做完意图识别后,会自己去进行工具匹配,生成调用指令:
{
“tool”: “sales_analysis.regional_ranking”,
“parameters”: {
“region”: “华东”,
“time_period”: “last_month”,
“top_n”: 3
}
}
# 这里对应着每个MCP服务都有详细说明书:
销售分析工具 = {
“功能”: “分析销售数据”,
“能回答的问题”: [
“哪个区域卖得最好?”,
“Top N产品是什么?”,
“同比环比增长多少?”
],
“需要的参数”: [“区域”, “时间范围”, “产品类别”]
}
AI在微调时候,专门做过这种工具描述训练,知道什么工具能解决什么问题,包括最简单的关键信息提取:
“上月华东区销售Top 3产品”
↓ 提取出
区域 = “华东”
时间 = “上月”
数量 = 3
最终会组装起来供AI使用,比如:
# 老板:上月华东区销售Top 3产品?
# MCP返回{
“data”: [
{“product”: “iPhone 15”, “sales”: 12500000, “growth”: 0.15},
{“product”: “MacBook Pro”, “sales”: 9800000, “growth”: 0.08},
{“product”: “AirPods Pro”, “sales”: 5600000, “growth”: -0.05}
],
“period”: “2024-05”,
“region”: “east_china”
}
接下来AI如何分析,就是他的事了,具体Server端实现就不展开了,就是个API调用,AI帮助抽取参数,没撒好看的…
接下来我们说说另一个主角Skills:
二、Skills
其实我们在使用MCP过程中,大家应该也发现一个问题,其中存在一个黑盒:
MCP虽然能够返回数据,但是这个数据,大模型是怎么使用的,他其实是不可控的
并且这其中天然具有不可调和的矛盾,模型/Agent是我的产品,MCP是各种人提供的服务,我怎么可能将模型/Agent底层的调用逻辑给他,这里可是有知识产权和安全问题的!
为了补足缺漏,Skills应运而生,并且两者定位就很清晰了:
- MCP解决触达问题。MCP的定位是让AI与之前的互联网庞大工具库/数据发生交互;
- Skills解决使用问题。Skills不关心怎么拿到数据的,他关心数据拿到后怎么处理;
所以,其实可以调侃一句:Skills出身是为擦之前MCP的缺漏屁股的。具体来说:
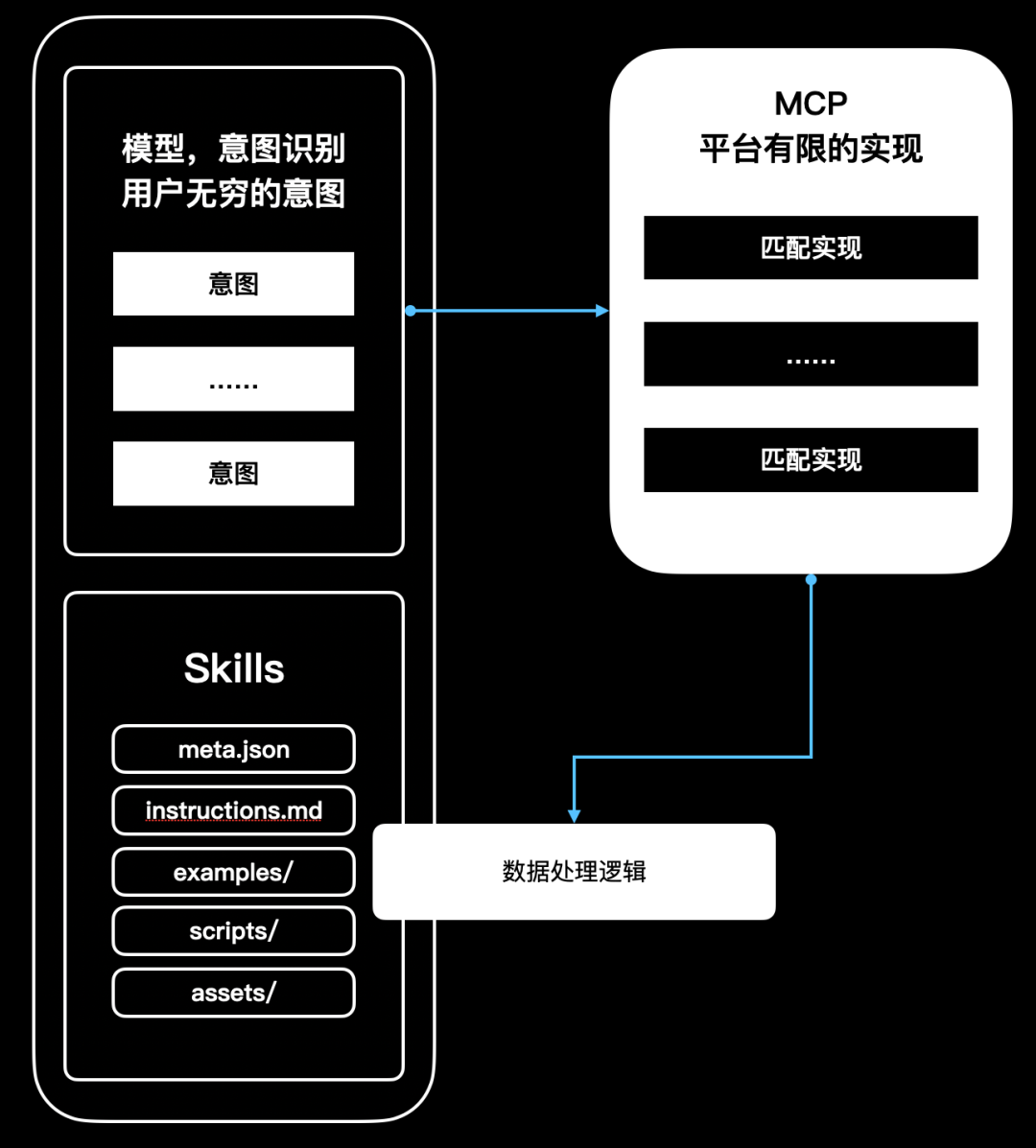
Skill = 一份可反复调用的专业SOP+说明书,由模型自己按需加载
Anthropic 的定义是:Skill 是一个文件夹,里面装着说明文档、脚本和资源,Claude 在执行任务时会先扫一圈所有 Skills,觉得哪个对当前任务有用,就把完整内容拉进上下文来用。
你可以把 Skill 想成:给“AI 员工”写的一本 岗位说明书 + 培训手册;不用你每次在 Prompt 里“从零复述”。
以上,就是Skills为什么会出现的答案。再啰嗦一句就是,在没有Skills的时代,我们教一个模型做事是需要在提示词里面做文章的:
从现在开始你是一个 XX 行业专家,遇到文案要按 A/B/C 三种格式写,禁止使用某某词汇,优先引用公司白皮书…
抛开其中一套提示词用于不同应用的工程问题,乃至上下文增加引起的成本问题,最重要的还是那种做法太粗暴,AI表现不好,Skills的出现就是把这些反复用、专业性强、逻辑成体系的东西,从 Prompt / Project 里拆出来,做成一个个可组合的技能包。
解释清楚定位和原因后,我们来简单看看两个案例:
Skills的本质
官方有个词叫 渐进式加载(progressive disclosure),大概是这么个流程:
每个Skill有一段非常短的描述(meta),比如:
品牌写作技能:教你如何按照 XX 公司品牌规范写公众号文章和活动文案。
Claude 在接到一个任务时,会先用这些 meta 做 “技能检索”:看看当前任务跟哪些 Skills 相关、只选命中的那几个;
最后,只有确认相关的 Skills,才会把完整的 instructions.md、例子、甚至附带脚本拉进上下文。
所以,你可以给模型装很多技能,上下文不会撑爆,他主打一个“按需加载”。
Skills长什么样?
抽象一下,一个Skill看起来大概是这样(不是官方格式):
brand_style_skill/
meta.json # 很短的技能简介 & 什么时候用
instructions.md # 详细的写作规范、SOP、负面示例
examples/ # 正反例、few-shot 样本
scripts/ # 可选:比如检查用词的小脚本
assets/ # 品牌色、Logo 使用规范等资源
meta.json 里的东西会被优先加载:
{
“name”: “brand_style_cn”,
“description”: “按照 XX 品牌规范撰写中文营销文案,保持语气、结构和禁用词一致。”,
“good_for”: [
“公众号推文”,
“电商详情页”,
“活动落地页”
]
}
当你说:帮我写一篇双十一活动主推文案,品牌是 XX。
Claude 在内部大致会做两件事:
- 看当前任务内容 → 觉得“品牌写作”相关;
- 在所有 Skills 的 meta 里找到 brand_style_cn → 决定:加载这个 Skill 的完整说明;
之后,Skill 里的各种“套路”就会生效,比如:
- 标题要包含的要素;
- 开头 100 字要解决什么问题;
- 哪些词属于品牌禁用词;
- 有哪些可复用的模块化段落结构;
- …
最后依旧回归老板BI案例:
老板BI案例
前面 MCP 那一大段,我们解决的是一件事:让 AI 能“摸到”BI 系统、数据库、报表 API,这属于能力打通的问题。
但你很快会发现,只把BI系统接进来,虽然缓解了一些问题,但还远远不够。因为巨婴老板非常挑剔,对于答案不太好他就又要骂人!
所以,想要让模型/Agent表现得更好,就可以上Skills了,他是中间缺少的一层:业务套路 / 分析 SOP / 汇报规范。
在之前的MCP案例里面,AI最终输出的是一堆文字,这个显然体验不好,也许可以将他变成表格或者图表,这里新增一个boss_bi_briefing_cn的Skill:
boss_bi_briefing_cn/
meta.json # 这是谁的技能,用来干啥,什么场景触发
instructions.md # 真正的SOP:分析步骤、优先级、禁忌
templates.md # 输出结构模板:标题、要点、行动建议
examples/ # 好的汇报示例 & 坏的汇报示例
checklists.md # 风险排查清单(例如:毛利、库存、客诉…)
首先,meta告诉模型什么时候会被用到:
{
“name”: “boss_bi_briefing_cn”,
“description”: “当用户是业务老板,提问涉及销售、区域、产品、客户等经营指标时,使用此Skill,以「高层经营汇报」方式组织 BI 分析结果。”,
“good_for”: [
“按区域/产品/渠道看Top N”,
“询问上月/上季度经营情况”,
“问「哪里出了问题」「有什么机会」”
]
}
比如,当老板问:上月华东区销售 Top 3 产品,顺便说说有没有什么异常?
Claude 内部会做两步:
- 看用户这句里出现了:上月 / 华东 / 销售 / Top3 / 异常 / 机会→ 判定这属于“经营分析”意图;
- 在所有 Skills 的 meta 里检索,发现 boss_bi_briefing_cn 非常相关→ 加载这整个 Skill;
其次,instructions:需要把“BI分析套路”写清楚(这个有点Workflow的意思):
# 使用场景
当用户是公司老板或高层,询问某时间段、某区域、某产品、某渠道的经营情况时,请启用此Skill。
# 总体原则
– 回答结构固定为:【一句话结论】→【关键数据点】→【原因与拆解】→【风险与机会】→【建议行动】。
– 避免仅堆数据,必须明确「好/坏」判断。
– 优先使用「经营视角」而不是「纯数据视角」。
# 分析步骤(示意)
1. 明确用户意图
– 是「看排名」?「找问题」?「要决策」?如果未说清,在不打断的前提下做合理假设。
2. 必查指标
– 销售额、销售数量
– 毛利额、毛利率
– 同比、环比
– 重点区域/重点客户的贡献度
3. MCP 工具调用建议
– 使用 sales_analysis.regional_ranking 获取 Top N 产品
– 同时调用 sales_analysis.yoy_growth、sales_analysis.trend 获取同比/趋势
– 如有库存波动,调用 inventory.check_warning 检查是否存在缺货/压货
4. 输出格式
– 先用一句话说清楚「整体情况如何」和「是否有异常」
– 接着用 3~5 个要点列关键数据(含同比/毛利)
– 对 Top1/异常项做原因猜测(明确标注是「推测」)
– 最后给出 2~3 条可执行建议
5. 风险与禁忌
– 禁止用绝对词:如「一定」「必然」。
– 避免只讲好消息不讲风险。
– 有数据不充分时必须说明「信息有限」。
接着就比较简单了,调用MCP并返回数据:
{
“tool”: “sales_analysis.regional_ranking”,
“parameters”: {
“region”: “east_china”,
“time_period”: “2024-05”,
“top_n”: 3
}
}
# 数据返回
{
“data”: [
{“product”: “iPhone 15”, “sales”: 12500000, “growth”: 0.15},
{“product”: “MacBook Pro”, “sales”: 9800000, “growth”: 0.08},
{“product”: “AirPods Pro”, “sales”: 5600000, “growth”: -0.05}
],
“period”: “2024-05”,
“region”: “east_china”
}
然后就是Skill的切入,解决了AI随缘输出问题:
【一句话结论】
上月华东整体销售表现良好,Top3 产品中有两款增长稳健,一款出现下滑,需要关注库存与渠道策略。
【关键数据点】
iPhone 15:销售额 1250 万,同比 +15%,毛利率 32%,主要增长来自线下经销渠道。
MacBook Pro:销售额 980 万,同比 +8%,毛利率 28%,客单价提升明显。
AirPods Pro:销售额 560 万,同比 -5%,毛利率 25%,在华东部分城市出现库存高企信号。
【风险与异常】
AirPods Pro 在苏州、无锡门店 3–4 周库存周转偏慢,促销策略未能有效带动销量。
华东整体毛利略低于全国平均,主要因为 iPhone 促销活动频繁。
【建议行动】
对 AirPods Pro 在库存高的城市做针对性促销或捆绑销售,并控制后续补货节奏。
评估 iPhone 促销对毛利的长期影响,尝试在部分城市增加高毛利配件搭售。
后续每月对华东 Top10 产品增加“库存 + 毛利”联合监控,提前预警。
在 BI 场景里,Skill 可以专门围绕老板的喜好设计一些规则:
- 在instructions里写死,所有回答必须先一句话结论;
- 如果出现异常自动识别,比如利显著低于全公司平均时,必须加注意风险标签;
- 尤其是模糊问答,当老板问题很模糊,那就要约定默认行为;
- …
以上,就是Skills的一些描述,应该是说清楚了…
三、结语
好了,经过前面的长篇大论,大家应该是看明白了,这里做个简单总结。
Anthropic这两年挺喜欢造名词的,我有时候也被搞得很蛋疼,最终官方不得发长文来解释自己发明了啥…
但如果你把今天这几个东西都当成传统软件世界里的老朋友,其实没那么复杂:MCP更像远程服务封装、Skills更像本地能力包。
在真实场景中,MCP与Skills的界限可能还没那么分明,一个Skill里会指导AI去调用哪些MCP工具;一个MCP服务的描述本身也自带使用逻辑。
记住MCP管接入,Skills管用好这个核心分工就行。而且这东西真正实践好用的范式可能还没出来。
然后,MCP现在几乎成为了事实上的标准,Skills这个东西各个基模会不会跟进,还不太好说,因为这东西对基模能力要求还挺高的,一个意图识别不准,很容易弄巧成拙。
本文由人人都是产品经理作者【叶小钗】,微信公众号:【叶小钗】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。






- 目前还没评论,等你发挥!


