
 起点课堂会员权益
起点课堂会员权益从特斯拉ICCV分享看未来:端到端自动驾驶的下半场将如何演绎?
Tesla AI副总裁Ashok在ICCV 2025的分享揭示了FSD V14背后的端到端架构如何突破自动驾驶领域的三大终极挑战:维度灾难、可解释性与评测壁垒。从20亿输入Token到2个输出Token的因果映射,到3D高斯重建与语言解释系统的结合,这场分享不仅展示了Tesla的技术深度,更预示了世界模型终局下自动驾驶的未来竞争格局。
Tesla AI副总裁Ashok在ICCV 2025的分享,不仅是FSD V14的技术预告,更是端到端(E2E)架构进入深水区后的实战复盘。对于行业而言,这次分享的价值在于它揭示了Tesla如何系统性地解决E2E面临的三大终极拷问:维度灾难、可解释性与评测壁垒。
视频:https://www.youtube.com/watch?v=45wwLSWvgJg
01 回归第一性:Tesla的端到端哲学
从V12起,Tesla彻底转向“Photon In, Control Out”架构,这不仅是技术栈的重构,而是对传统级联(Modular)架构弊端的彻底清算。该架构的核心价值在于利用Scaling Law,通过移除规则代码减少了中间规则处理环节,使得模型训练的梯度能够从输出端无缝反向传播至感知端,从而实现模型各部分的整体协同优化。
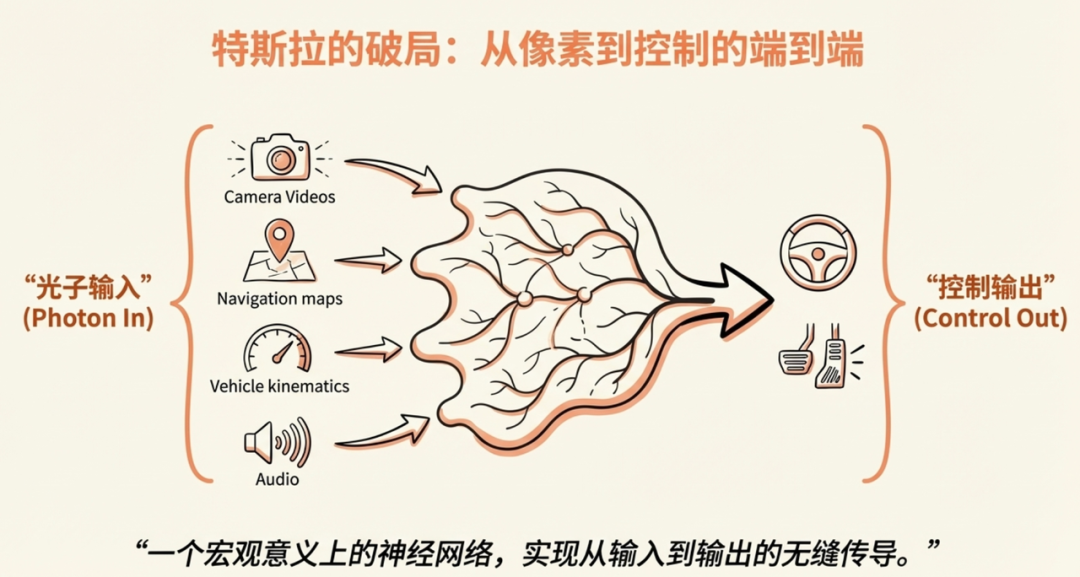
此次分享中详细介绍了Tesla AI采用E2E方案解决自动驾驶问题的关键原因。
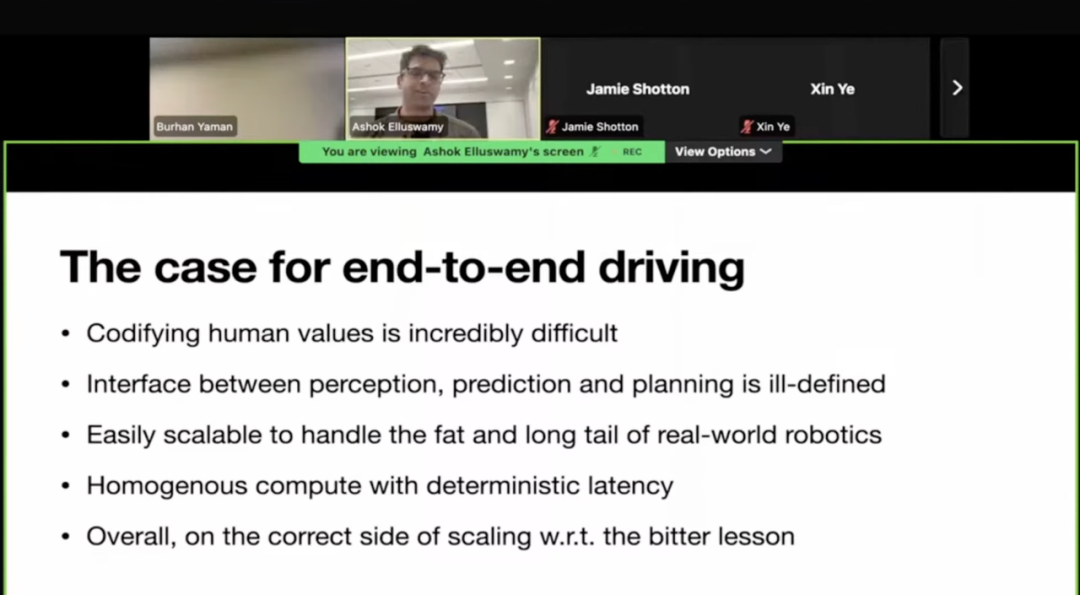
1.1规则无法穷尽的“价值博弈”
驾驶本质上是无数个微观“电车难题”的集合。Ashok举例:面对积水车道,是“压线绕行”还是“车道内涉水”?这种涉及安全与效率权衡的微妙价值判断,传统Rule-based代码根本无法完美定义。端到端的核心优势在于,它能从海量人类老司机的驾驶数据中,隐式学习到这种复杂的价值权衡(Value Judgement),而非依赖工程师写死在if-else里 。

1.2接口定义的“信息熵减”
传统架构最大的痛点是感知与规控间的“接口瓶颈”。Ashok展示的“鸡与鹅”典型案例:感知模块输出的Bounding Box丢失了关键语义——“鸡在过马路(需等待)”与“鹅在路边发呆(可绕行)”的区别。传统接口导致的信息丢失是不可逆的,而端到端通过高维特征流(Latent Features)传递,保留了环境的完整语义,让决策模块能获取无损的“上帝视角”。
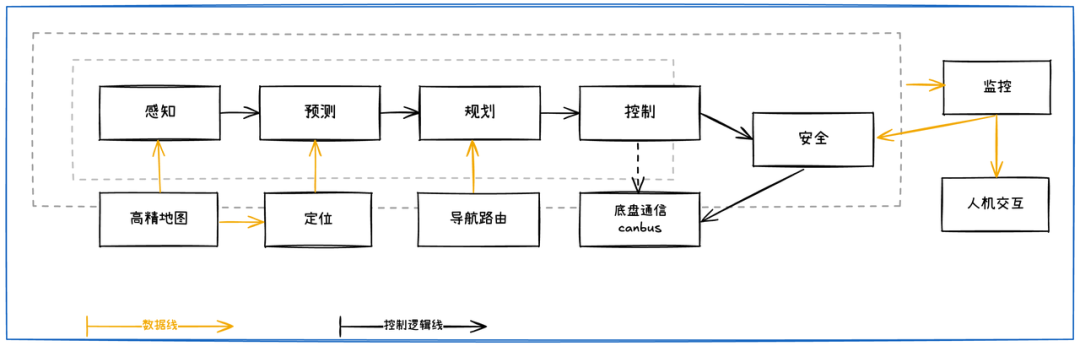
分段式自动驾驶功能模块间通过预设接口进行通信

左图:⼀群鸡正在过马路, 自驾汽车能理解,等待最后⼀只鸡过马路之后再走
右图:⼀群鹅站在路边,自驾汽车理解完之后,决定绕行
1.3确定性与规模效应
除了解决Corner Case,端到端架构带来了两大工程红利:
- 确定性延迟:固定参数量的模型结构保证了单帧推理耗时的恒定,消除了传统规划求解器因场景复杂度波动带来的延迟抖动。
- 顺应Bitter Lesson:端到端自动驾驶是彻底的数据驱动范式,摒弃了人为设计的规则和评价指标(如Sutton在“Bitter Lesson”中提及“人为添加的归纳偏误更可能形成结构性限制”),使得系统性能上限仅受限于算力与数据规模,完美契合AI时代的摩尔定律。
02 直面端到端落地的三大挑战
Ashok将E2E的工程落地拆解为三个核心难题:维度灾难(怎么训)、可解释性(怎么信)、以及评测(怎么测)。

2.1 维度灾难:20亿到2的因果映射
Ashok指出,理想的E2E模型面临着极端的输入输出不对称:
1)输入token:
- 过去30s的时间窗口, 36hz采集的7路500万像素摄像头视频 等, 信息维度相当于20亿token
- 7台摄像头 × 36帧/秒 × 500万像素 × 30秒历史数据 / (5×5像素patch)
- 导航地图及未来数英里路线
- 100Hz运动学数据(如速度、惯性测量单元、里程计等)
- 48kHz音频数据 (可能是FSD14新增)
2)输出token:
- 预测转向与加速指令、方向盘等,约等于2token
3)学习20亿token→2token的正确因果映射关系
因此端到端方案要解决的是一个从高维到低维的映射问题,且还要反馈正确的逻辑,训练难度可想而知。

Tesla搭建强大的数据引擎(Data Engine)收集大量高质量数据,而非盲目堆砌里程,通过复杂的触发器(如“影子模式”预测偏差、用户接管数据、甚至专用模型采集特殊数据)定向挖掘长尾与高价值样本。而高效的数据筛选与回传机制,使得Tesla能收集海量的极端场景和主动避险数据,确保FSD模型具备极强的泛化能力。

2.2 可解释性:从黑盒走向“灰盒”
简单的端到端系统作为“黑箱”,在问题分析、行为解释和安全验证方面存在隐患。针对“黑盒”质疑,Ashok展示了Tesla目前的解法:VLA(Vision-Language-Action)+ 3D Gaussian。Tesla的E2E系统并非完全黑盒,而是一个具备中间监督信号的复杂网络。
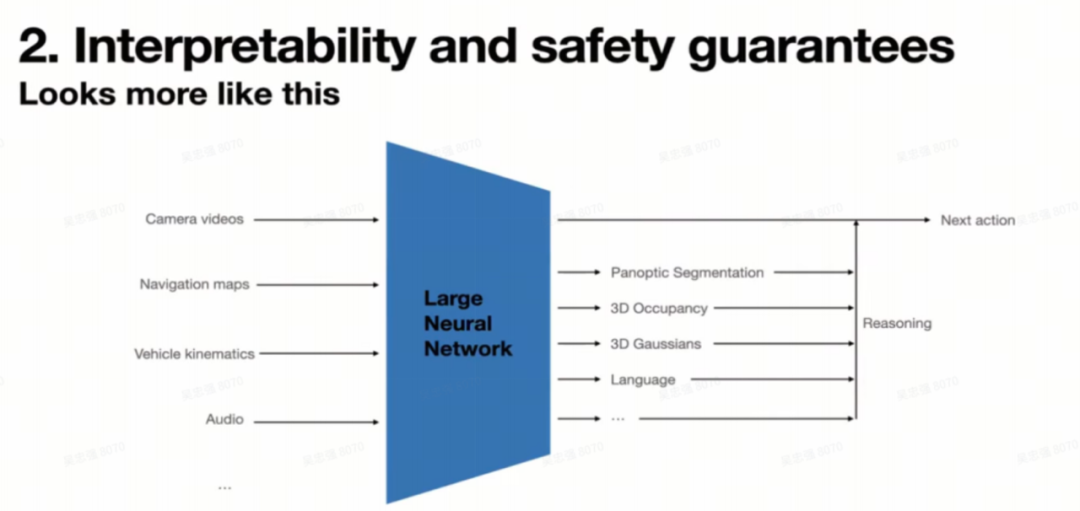
可以看到这样的端到端系统不仅输出了下一个驾驶控制指令,还在决策规划信号前输出了很多中间结果,包括了带速度信号的3D占据网格,3D高斯特征,车辆,行人,骑行人等动态障碍物,交通信号灯,信号牌,道路边沿、车道线等静态物体,还有限速,道路属性,以及语言模式表达的决策信息。

自然语言的System 2思考
Ashok给出了System 2慢思考应对施工长尾场景的例子:引入了大语言模型(LLM)的思维链(CoT)能力。在遇到“道路封闭”等长尾场景时,模型不仅输出动作,还能生成自然语言解释(“识别到封路标识 -> 推理出无法直行 -> 决定左转绕行”)。这种逻辑推理能力的显性化,是建立人机信任的关键。

3D Gaussian的空间理解
3D Gaussian重建,比点云或多边形的表达更高效可微;比NeRF等隐式表达的几何信息更明确,因此3D Gaussian成为了目前自动驾驶领域最主流的场景重建表征。
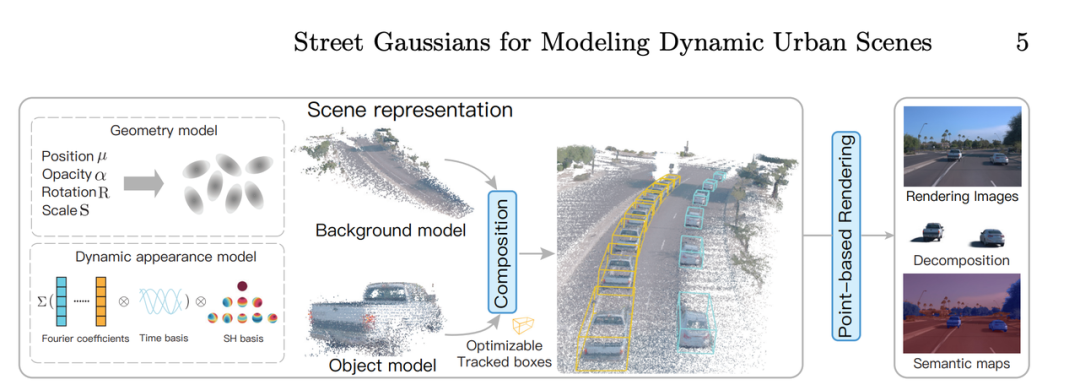
3D Gaussian自动驾驶场景重建,来自Street Gaussians https://arxiv.org/pdf/2401.01339
Tesla采用生成式3D Gaussian Splatting(3DGS)进行场景重建。其优势在于生成效率极高(220ms)、无需预设关键点且支持动态物体。

从效果上看,不仅重建过程生成了语义分割信息,还能够支持非常大的新角度渲染,一方面解决了Tesla端到端模型训练时候单纯监督驾驶动作监督信号过于稀疏单一的问题,也确保了Tesla对周围环境的良好空间理解。

Tesla是强视觉方案,同时包括了语言形式的决策和动作控制信号输出,而这一技术架构被认为是当前行业公认的最优解,但并非Tesla独享,国内Moment、地平线、理想、卓驭等厂商也在积极推进。

2.3 评测体系:最枯燥但最深的护城河
Ashok直言评测是“最枯燥但最重要”的环节,也是拉开差距的分水岭。

三个挑战中棘手的问题:
- 无论数据集质量多高,训练Loss不能代表端到端模型性能(设定合理的评测指标是关键)
- 开环指标不能保证闭环性能(所以闭环的评测是必要的)
- 自动驾驶存在多种驾驶行为来避免驾驶失败,评测指标需要正确的反应这种驾驶行为的多模态性
- 一种方法是来评估对驾驶行为结果的预测
- 一个平衡且全面的评测集非常关键(核心关键还是高质量评测集)
- 评测是枯燥乏味的,但是告诉你个秘密,评测至关重要
闭环仿真系统
Tesla完善的评测体系中的核心就是基于神经网络的闭环仿真系统。这个仿真系统可以通过收集⼤量廉价的离线<状态-动作>数据对进行训练。
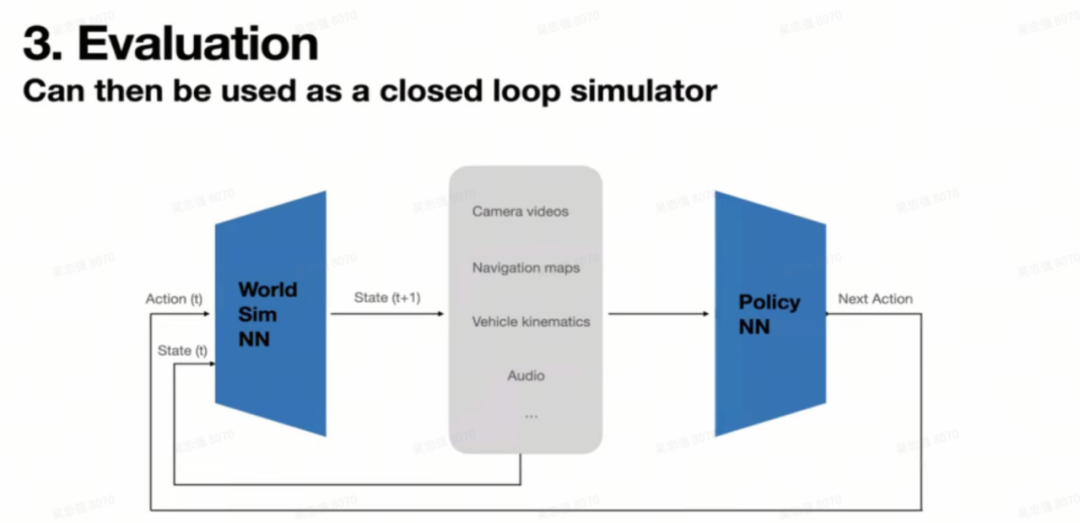
生成的数据: 8个摄像头的数据 由 同⼀个神经网络输出, 效果非常逼真

闭环仿真系统的几大作用:
1. 利用闭环仿真验证端到端Policy的正确性

2. 利用场景编辑生成能力生成对抗样本检验模型能力

3. 利用模拟器在闭环仿真系统中获取人驾真值
03 行业共识:世界模型是终局
结合Tesla的分享与国内头部玩家(如理想、小鹏等)的动作,自动驾驶技术栈的演进路径已相对清晰:
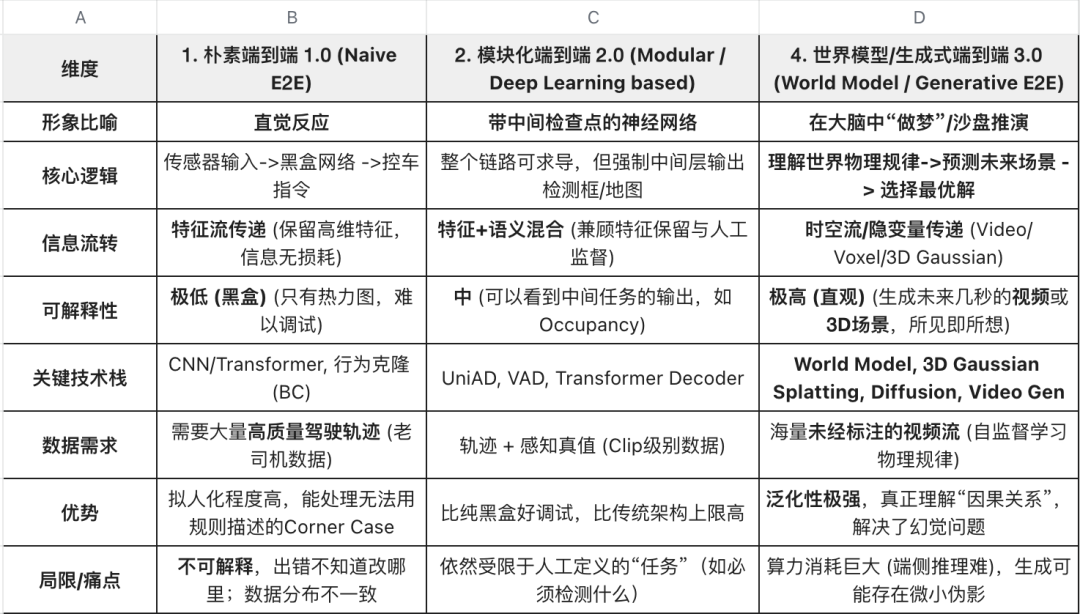
架构演进:
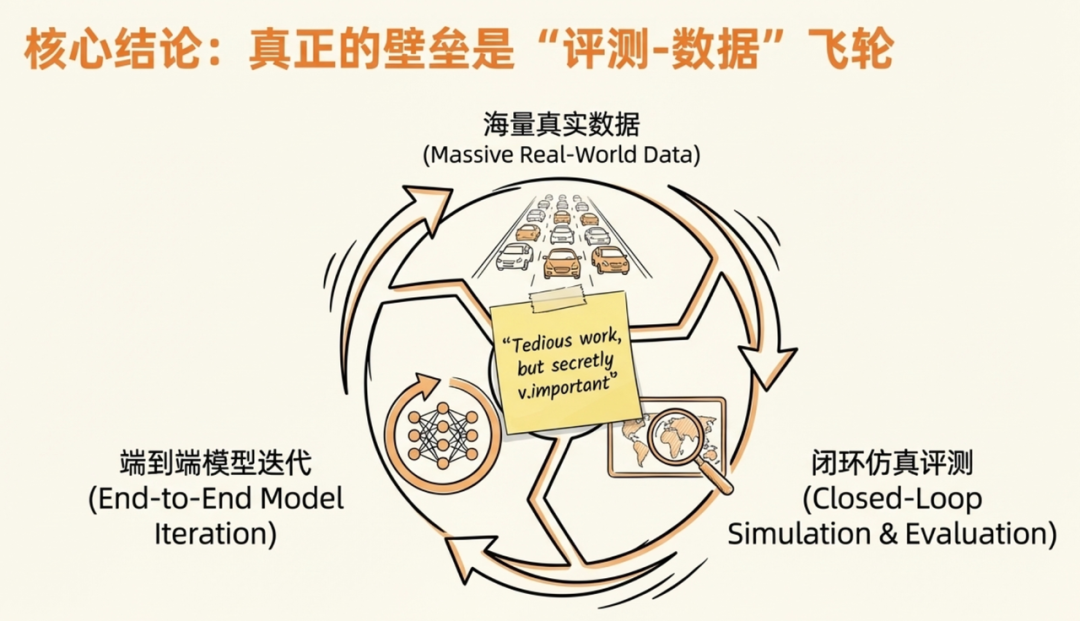
真正壁垒:不仅在于端到端模型架构本身的领先性,更在于“海量真实数据 -> 闭环仿真评测 -> E2E模型迭代”这一飞轮的运转效率。
结论:Teals正在用3D高斯与大语言模型告诉行业——别担心E2E是黑盒,当它能把脑海中想象的未来世界画给你看时,它就已经理解了这个世界。
参考文章:FSD V14的技术突破——ICCV Ashok技术分享解析
本文由 @杰克说AI 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


