
 起点课堂会员权益
起点课堂会员权益腾讯藏了三年的AI大招:生成三维空间,到底有多离谱?
腾讯IntelliScene系统正在颠覆游戏场景设计的传统模式。这款AI助手通过视觉引导生成与结构化语言解析,赋予了AI前所未有的空间智能——不仅能识别物体,更能理解三维空间中的功能关系、物理规则和叙事逻辑。从好莱坞级的美术设计流程中获得灵感,它让设计师从繁重的非核心场景搭建中解放,专注于最具创造性的部分。本文将深度拆解这套系统从1.0到2.0的演进历程,揭示多智能体协作如何攻克3D场景生成的世界级难题。

想象一下,你是一位电影的美术指导,正在筹备一部史诗级西部世界电影。你需要搭建一个完整的边境小镇。主角活动的酒馆、旅馆是“核心场景”,需要你倾注全部心血,精心设计每一个细节来塑造角色、推动剧情。但小镇里还有几十栋背景民居、马棚、铁匠铺,这些是“非核心场景”。它们数量巨大,对于营造世界的“沉浸感”至关重要,但如果每一栋都让你亲手去摆放每一张桌子、每一只杯子,那将是一个耗时数年、令人崩溃的“体力活”。
腾讯IntelliScene系统要解决的,正是这个“体力活”问题。 它的核心定位不是一个取代美术家的“全能AI艺术家”,而是一个极其强大和智能的“高级助手”。它的工作模式是:
- 需求理解与草稿生成:美术家给出一个模糊的指令(如“一个杂乱但温馨的猎人小屋”),AI助手快速生成多个可供选择的3D场景布局草稿。
- 人类审核与精细调整:美术家像主编审稿一样,在这些高质量的AI草稿基础上,进行微调、修改和最终验收。这极大地提升了初始方案的产出效率和质量底线。
关键边界:电影的主角戏份(游戏的核心关卡)必须由导演(人类专家)严格把控;而大量的群众演员站位、背景布置(游戏的边缘区域)则可以交给这位聪明的助手来高效完成,从而让导演能集中精力在最重要的创作上。
一、背景:为什么这件事如此之难?
1.1 核心痛点:场景设计是一座“冰山”
玩家在《荒野大镖客》中看到的美轮美奂的景色,只是冰山的尖顶。水面之下,是庞大、复杂且耗时的协作体系,涉及策划定调、美术制作、关卡摆放、程序实现等多个环节。
“一砖一瓦”的艰辛:每一个林中小屋里的家具、杂物、装饰品,都需要美术师从海量资产库中挑选,然后手动调整其位置、旋转角度、大小,并确保它们符合“有支撑(桌子上的杯子不会悬空)、无穿插(椅子腿不会陷进地里)、留通行(角色可以正常走过)”等基本物理和逻辑规则。
AI的切入点:让AI一下子接管整个冰山不现实,但可以先从冰山下水下部分那些可工程化、可验证的环节入手。比如:
大规模重复摆放:为上万平方米的森林自动分布树木、岩石和草丛。
- 基础约束检查:自动扫描整个场景,快速找出所有悬空的物体或互相穿模的家具。
- 局部细节填充:给定一个空房间的框架,自动填充上风格统一、布局合理的家具。
1.2 破局关键:赋予AI“空间智能”
过去的自动化场景生成工具,如程序化生成(PCG),更像是“撒豆成兵”,依据预设的规则随机放置,结果往往生硬、不合理。而早期的AI方法则像一个“黑盒”,你不知道它为何这样摆放,难以控制和调整。
真正的突破点在于让AI获得 “空间智能”——这不仅仅是“识别”物体,更是“理解”三维空间中的关系、物理法则和功能逻辑。
在这里举一个生动的例子:当AI布置一个卧室时,它不能仅仅是识别出“床”、“床头柜”、“台灯”这三个物体并把它们丢进房间。它必须理解:
- 功能关系:台灯是为阅读服务的,所以它应该放在床头柜上,并靠近床的一侧。
- 空间关系:床头柜必须紧贴床边,方便人伸手就能够到。
- 物理规则:台灯必须稳稳地“坐”在床头柜上(支撑关系),并且所有物体都不能浮空或相互嵌入。
- 叙事逻辑:如果这是一个匆忙离开的侦探的房间,那床上或许是凌乱的,台灯也许是开着的。这种布局背后是有“故事”的。
行业共识:李飞飞等AI领袖提出“空间智能是AI的下一个前沿”。腾讯的这项工作,正是要在游戏场景这个复杂的试验场中,攻克这一前沿难题。核心在于让AI学会回答“为什么这里应该放这个物件?”
二、演进:从“空想”到“实干”——IntelliScene 1.0到2.0
腾讯的探索并非一蹴而就,他们提出了一种反常的方法论:让AI“慢思考”。
这不仅仅是技术上的升级,更是设计哲学上的根本转变。我们可以通过一个生动的对比来理解:
传统AI/PCG(快思考):像是一个背熟了公式的学生,看到题目就立刻套用公式给出答案。速度很快,但可能完全不理解题目的实际意义,答案常常突兀、不合理,就像在厨房正中间生成一个马桶。
人类专家(慢思考):像是一位资深建筑师,接到“设计一个家”的任务后,会先与客户沟通需求、生活方式(目标规划),然后画出概念草图(视觉构思),再考虑功能分区、动线(逻辑推理),最后才选择具体的材料和家具(细化执行),过程中不断权衡美观、实用和预算。
腾讯IntelliScene的目标,就是让AI模拟后者这种严谨、深思熟虑的“慢思考”过程。
IntelliScene 1.0:用文字交流的“策划阶段”

设想:用多个AI智能体(可以理解为多个各司其职的AI专家)通过对话协作,模拟人类设计流程。一个AI负责规划格局,一个AI负责挑选家具,另一个AI负责检查合理性。
验证的成功点:证明了基于大模型的推理式摆放是可行的,并且人类专家的设计流程可以被抽象成标准操作程序(SOP)教给AI。
发现的瓶颈:纯文本交流信息损失太大。就像你只通过电话用语言向同事描述一个房间的布局,很难精确传达每个物体的精确位置、角度和彼此间的空间关系。导致结果经常出现位置错误、旋转不准、比例失调等问题。
IntelliScene 2.0:引入视觉蓝图的“施工阶段”

核心升级:从“文本驱动”变为“视觉引导”。这是一个根本性的转变。AI的工作流程不再是空对空的文本推理,而是先产生一张具体的、包含丰富细节的“效果图”,然后所有后续工作都围绕这张精确的蓝图展开。这就像是建筑行业,从依赖口述要求,升级到先由建筑师画出详细的工程图纸,施工队再严格按照图纸施工,精度和可靠性得到质的飞跃。
三、解决方案:IntelliScene 2.0 技术流程深度拆解
整个系统如同一个高度现代化的智能工厂,流水线如下:
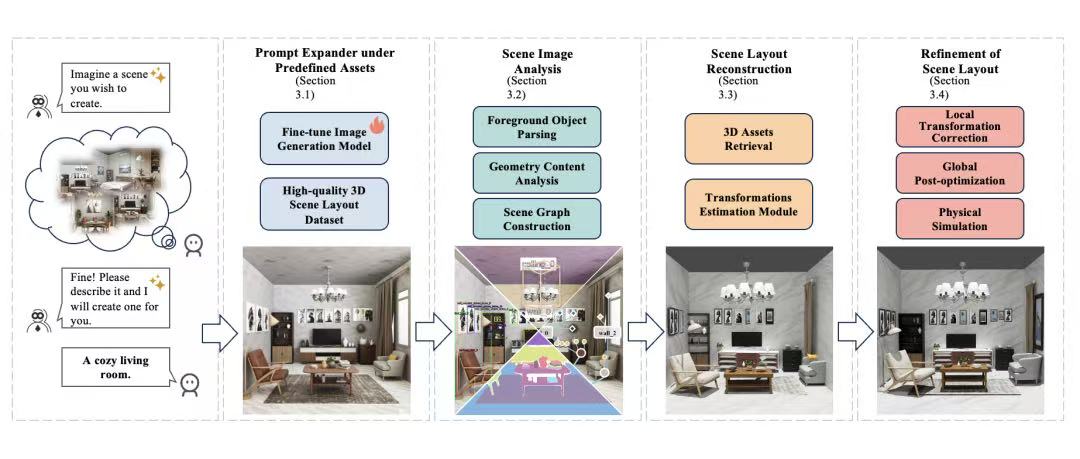
准备工作:建设“原料仓库”与“样板间”(高质量数据集)
这是所有AI能力的基石。腾讯做了两件至关重要的事:
3D资产库(原料仓库):自建了一个包含500个类别、2042个高质量3D模型的庞大仓库。这些模型风格写实,覆盖室内外常见物品,每个模型都带有详细的尺寸、描述等标签。
专家场景布局数据集(样板间):这是真正的核心竞争力。他们邀请了经验丰富的专业美术师,搭建了147个高质量的3D场景。每个场景平均有43.6个物体,远超普通数据集。
关键价值:这些不仅仅是模型的简单堆积,每个场景都附带了“设计思维链”,即专家对于“为何这样布局”的解释。例如,为什么要把这个箱子放在这个角落?是为了营造一种怎样的叙事氛围?这相当于把美术专家的“审美”和“逻辑”数字化、结构化了,供AI学习。
第一步:生成“施工蓝图”——视觉引导生成
任务:用户输入“一个充满阳光的现代图书馆”的文本描述,系统需要先生成一张符合要求的、高质量的彩色图片。
巨大挑战:生成的图片里的书架、桌椅等,必须和“原料仓库”(3D资产库)里的模型外观尽量相似,否则下一步“按图索骥”会非常困难。
解决方案——模型微调:
他们以强大的FLUX图像生成模型为基础,使用自建的147个“样板间”渲染图对其进行微调。
微调的核心目标是让模型学会两件事:① 专家级的布局审美(空间与美学先验);② 生成物体的外观要与资产库中的模型保持风格一致(资产一致性)。
结果:微调后的模型,能根据用户指令,生成既美观、布局合理,又与自己仓库里的“现货”长得像的效果图,为后续步骤奠定了完美基础。

第二步:“蓝图会审”——视觉解析与几何解码
现在,AI需要像工程师一样,仔细“审阅”这张效果图,提取所有可用的信息。
物体识别与分割(列出物料清单):
使用一系列视觉模型(如Grounding DINO, SAM),像用PS的魔术棒一样,把图片中的每一个物体(书桌、椅子、书本)都精确地识别出来,并用轮廓框(Mask)标出。
高级技巧——查漏补缺:AI会计算图中还没被标记的区域,怀疑可能有漏网的物体(比如背景里一个模糊的相框)。它会针对这些区域进行第二轮识别,确保“物料清单”完整无缺。
几何分析(理解空间结构):
深度估计:使用Depth Anything V2等模型,估算图片中每个像素的深度距离,将2D图片转换成有远近关系的“伪3D”点云图。
物体包围盒(OBB)拟合:对每个识别出的物体,根据其对应的点云,计算出一个3D的、带方向的最小包围盒子。这个盒子给出了物体在空间中的大致位置、尺寸和朝向。
结构平面提取:通过算法(如RANSAC)找出图中的地板、墙面等主要平面,并计算它们的法线方向。这是判断“靠墙”等关系的基础。
逻辑关系分析:
结合几何规则和视觉语言模型(VLM),判断物体间的关系,主要是:
支撑关系:A物体是否垂直支撑着B物体?(如地板支撑桌子,桌子支撑杯子)。
靠墙关系:物体是否与墙壁等边界对齐?

第三步:“按图索骥”——场景图构建与资产检索
构建场景图(生成装配说明书):
将前两步的所有信息整合成一张结构化的“场景图”。这不再是一张图片,而是一个包含所有物体节点、以及节点之间关系(支撑、靠墙等)的网状数据结构。它完整描述了场景的构成逻辑。
3D模型检索(去仓库里找对应的货):
拿着“效果图”和“装配说明书”,去“原料仓库”(3D资产库)里寻找最匹配的实物3D模型。
匹配标准是综合性的:
语义对齐:类别必须正确(图上是书桌,就不能拿个餐桌出来)。
视觉一致性:计算图片中物体与仓库模型渲染图的视觉特征相似度(使用DINOv2模型),确保外观像。
几何约束:模型的大小要与蓝图中估算的物体大小相近,不能差太多。

第四步:“精密装配与调整”——姿态估计与全局优化
这是技术含金量最高的步骤,目标是让3D模型在3D空间中精确还原蓝图中的布局。
旋转估计(确定物体的精确朝向):
粗筛选:为候选的3D模型从162个均匀分布的角度拍摄“标准照”,与效果图中的目标进行特征匹配,选出最像的Top-K个候选角度。
精细择优:使用一种基于“单应性矩阵”的方法,分析哪个候选角度最接近纯粹的旋转(而非扭曲变形),从而锁定最精确的朝向。此法能有效处理对称物体带来的歧义。
几何增强:同时,利用第二步中从点云拟合出的OBB的几何方向作为参考。如果视觉估计结果和几何参考方向差异太大,系统会智能地选择更可靠的那个,或者进行加权平均,大大提升了朝向估计的稳定性。

全局布局优化(解决冲突,确保合理):
问题:由于估算误差、遮挡等原因,直接放置的物体可能会穿模(椅子腿插进地里)或悬空。
解决方案:引入一个“全局优化求解器”。它将场景图中定义的“支撑”、“靠墙”等关系作为必须遵守的硬性约束,同时要求最终布局与蓝图效果的总体偏差最小。
过程:这个求解器(如采用模拟退火算法)会智能地、微调每个物体的位置和旋转,直到找到一个既能完全满足所有物理约束(无穿插、有支撑、靠墙),又最大限度地忠实于原效果图的全局最优布局。有时还会加入简单的重力模拟,让堆叠的物体更自然。
四、效果评估:专业人士的“盲测”
为了客观验证效果,腾讯设计了严格的评估:
美术专业学生评估(无纹理布局):
方法:邀请100名美术专业学生,对IntelliScene 2.0和其他几种前沿方法生成的无纹理场景布局进行两两比较。
维度:“合理性与现实性”和“美学吸引力”。
结果:在餐厅、客厅、卧室等多种场景下,IntelliScene 2.0的用户偏好率显著高于所有对比方法(如DiffuScene, Holodeck等),普遍达到75%-85%的偏好率。
资深行业专家评估(完整可交互场景):
方法:邀请公司外部的资深游戏美术,在3D软件中交互式浏览带纹理的完整AI生成场景。
标准:1-5分制(3分代表人类专业平均水平)。
结果:在整体构图、语义逻辑、美学吸引力上获得高分。最有力的证明是:在某些案例中,评估者无法区分这个场景是出自外包美术之手还是由AI生成的。 这标志着其产出质量已达到了实用水平。
五、总结与核心启示
IntelliScene 2.0的成功,超越了技术本身,带来了三点深刻的启示:
- 多智能体协作是解决复杂AI任务的必由之路:将一个宏大问题拆解,由专门化的智能体(视觉生成、解析、优化等)分工协作,是可行且高效的。
- 视觉与结构化语言是3D理解的“一体两面”:在3D领域,图像提供的丰富空间信息,与文本和关系图提供的抽象逻辑信息,二者相辅相成,缺一不可。
- 高质量、富含“思维链”的数据是AI能力的基石与壁垒:最终决定AI高度的,并非模型本身,而是用于训练它的数据质量。那些蕴含了人类专家设计意图和推理过程的“思维链”数据,是无价的宝藏。这不仅是技术壁垒,更体现了对人类智慧的尊重和利用。
展望未来,腾讯希望将游戏场景作为培养AI“空间智能”的绝佳平台,最终训练出具备更强空间认知能力的“摆放大模型”。而当前的IntelliScene系统,既能高效产出内容,又能在此过程中生成海量的、高质量的结构化场景数据,反哺下一代AI的成长,形成一个强大的飞轮效应。
本文由 @郑嘉智(AIPM) 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


