
 起点课堂会员权益
起点课堂会员权益AI 编程的“减肥”革命:CodeACT 带来的高效进化故事
在代码大模型训练陷入‘数据海战术’困境的2024年,南京航空航天大学的研究团队带来了突破性解决方案CodeACT。这套结合‘学霸式精准刷题’CDAS算法与‘俄罗斯方块式打包’Dynamic Pack的技术框架,仅用40%数据就让模型性能提升8.6%,训练速度提升4倍,重新定义了AI训练的效率革命。本文深度解析这场关于‘少即是多’的技术哲学实践如何改变大模型进化范式。

2024 年的夏天,人工智能领域正处在一场无声的火并中。在大模型的竞技场上,代码生成(Code Generation)成了衡量一个模型“智商”的最高标准。不管是 DeepSeek、CodeLlama 还是闭源界的王者 GPT-4,大家都在疯狂地投喂数据。
但是,这种“题海战术”正在遇到一个尴尬的瓶颈:显卡太贵,数据太杂。
对于很多开源团队来说,训练一个强大的代码大模型就像是在烧钱。你不仅需要数以万计的 H100 显卡,还需要在浩如烟海的互联网数据中寻找那些真正能让模型“开窍”的精华信息。
南京航空航天大学的研究者们坐不住了。他们想到:能不能让模型别再“傻练”,而是学会像学霸一样“精准刷题”和“高效吸收”?
他们把这个想法变成了一个全新的框架,叫CodeACT。
这个算法的出现,就像是给正在疯狂吃垃圾食品的 AI 模型制定了一套“有机饮食”+“高效燃脂”方案。它仅用 40% 的数据,就让模型的性能提升了 8.6%,同时训练速度快了近 4 倍。
这不仅是一个技术突破,更是一场关于“少即是多”的哲学实践。
“题海战术”的困境
在聊 CodeACT 之前,我们得先说说现在的 AI 是怎么变聪明的。
训练一个代码大模型,本质上是让它在大规模的代码库里玩“填空游戏”。你给它一段注释或者一段残缺的代码,它要猜出后面该写什么。
为了让它猜得准,开发者们发明了各种“合成数据”生成法。比如让 GPT-4 批量生成几十万道题,然后再喂给自家的开源模型。
合成数据(Synthetic Data):由人工智能模型(如 GPT-4)生成的训练数据,而非直接从互联网或现实世界中抓取的原始数据。在代码领域,通常表现为“指令-代码”对。
这种方法曾被视为“大力出奇迹”的典范。但很快,人们发现这像是在给模型吃“注水猪肉”:
- 质量参差不齐:生成的数十万道题里,有大量的重复、低级题,甚至有逻辑错。
- 训练效率低下:模型花了大把时间在做“1+1=2”的口算,真正能提升逻辑能力的“高考大题”却被淹没在题海中。
这种状况导致了一个致命问题:计算资源的极度浪费。
就像你请了一个名师教学生,结果名师整天让学生抄写生字表,而不是讲解解题思路。学生学得很累,显卡费用还高得吓人。
这就是代码大模型面临的“效率红利期”结束的标志。
之前的人怎么尝试解决的?
为了解决“数据低效”和“计算昂贵”的问题,研究界其实已经做过两轮重要的尝试。
第一次尝试:AlpaGasus 和 InsTag(靠外力的“精选模式”)
2023 年,一些研究者提出:既然数据太杂,那我们就请个“超级判官”来筛选。
比如AlpaGasus,它请 ChatGPT 给每条数据打分,低于 4 分的扔掉。InsTag则让大模型贴标签,看哪些领域的数据稀缺,就练哪些。
数据筛选(Data Selection):从大规模原始数据集中,利用某种算法或规则选出最高质量或最具有代表性的子集。
这种方法有效,但硬伤在于:贵。你要筛选 100 万条数据,就得给 OpenAI 交 100 万次 API 费。而且这种筛选是“静态”的,判官觉得好的题,学生未必觉得难。
第二次尝试:动态填充(Dynamic Padding)
在计算方面,研究者发现了显卡的“懒政”:填充(Padding)。
因为神经网络训练需要每一批数据长度一样,但代码有长有短。传统做法是往短代码后面塞一堆无效的“泡沫塑料”(Padding Tokens)。有时训练包里 80% 都是泡沫。
填充(Padding):在序列模型中,为了对齐序列长度而在末尾添加的占位符(通常是 0)。
有人提出了“动态填充”,每一批按该批最长的来补。虽有缓解,但依然没根治浪费。
CodeACT 的核心思想:自适应的“减肥”革命
CodeACT 的研究者们想做一件更酷的事:不要外面的判官,让学生自己当判官;不仅要动态填充,还要把包裹塞满。
这就是 CodeACT 的两个核心黑科技:CDAS和Dynamic Pack。
1. CDAS:挑选“高营养”题目
CDAS 的全称是Complexity and Diversity Aware Sampling(复杂性与多样性感知采样)。
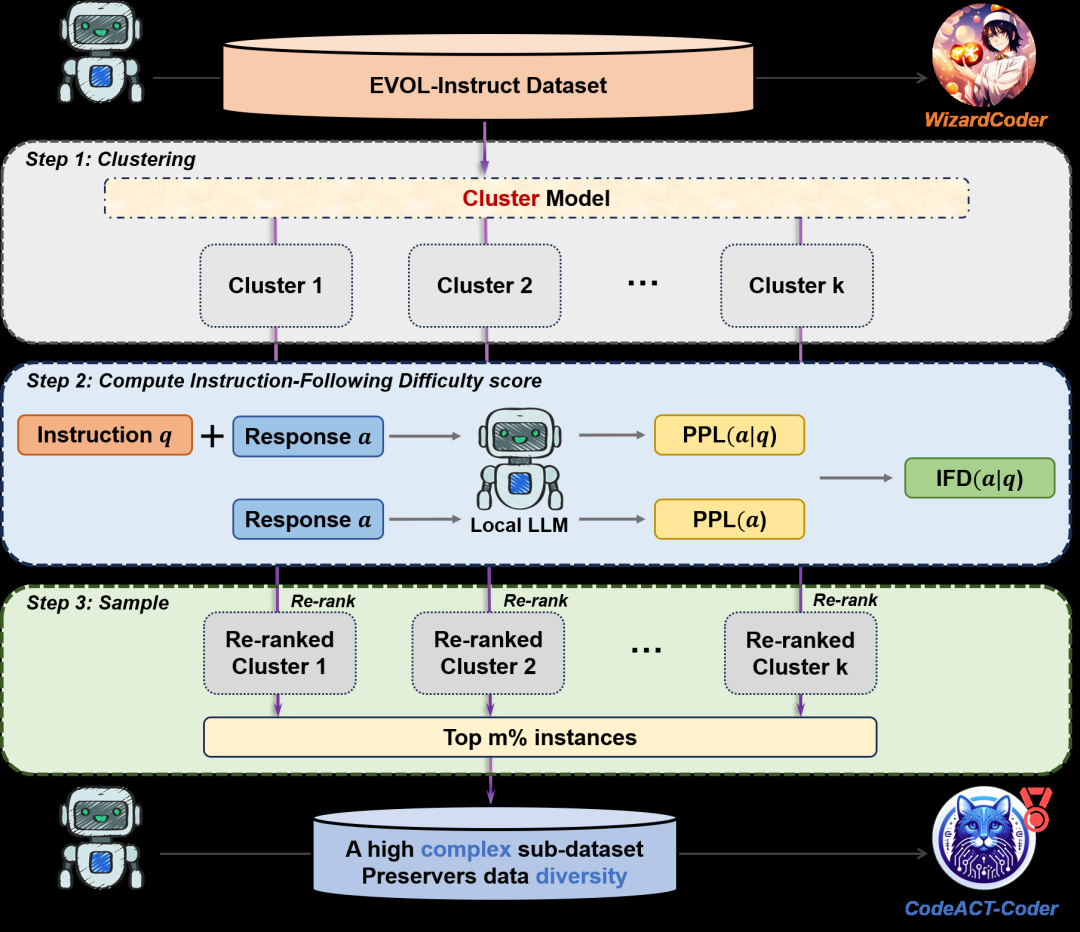
图 1 展示了 CDAS 的完整工作流:首先通过聚类(Clustering)保证多样性,然后利用本地模型计算 IFD 分数来识别难度(Complexity),最后对每个簇进行重新排名并采样。这种“模型自我打分”的方式彻底告别了对 GPT-4 的昂贵依赖。
它如何判断“难不难”?(难度分)
CDAS 引入了一个非常巧妙的指标:IFD 评分(Instruction-Following Difficulty)。
IFD 评分:通过比较模型在“有提示”和“无提示”下生成答案的困惑度之比,来衡量数据的认知价值。
我们可以把它想象成一个公式:
IFD = 模型在有题目时的“懵逼”程度 / 模型在没题目时的“懵逼”程度
翻译成人话:如果模型不看题就能猜出答案,说明这题太简单;如果看了题还是很懵,但比不看题明白了很多,说明这题有极大的“点拨”作用,是一道好题。
2. Dynamic Pack:告别“填不满的包裹”
如果说 CDAS 解决了“吃什么”,那Dynamic Pack就解决了“怎么吃得更快”。
研究者提出了俄罗斯方块式打包。在一批数据(Batch)里,不再补充填充符,而是把多份短代码首尾相连,拼成一个正好塞满显存限制的长序列。
打包(Packing):将多个短序列合并为一个长序列的操作,通过注意力掩码(Mask)确保不同序列互不影响。
比喻时间:
- 普通训练:一辆卡车只拉一个杯子,剩下全是泡沫。
- Dynamic Pack:快递公司把几百个小快递塞满一辆卡车,不留空位,一趟运走。
显卡的每一分算力都用在了代码上,而不是在算“泡沫”。
为什么 CodeACT 这么好用?
1. 它是“量身定制”的
IFD 评分是基于基础模型(Base Model)生成的。针对 DeepSeek 选出来的题,最适合 DeepSeek 练。这是真正的“因材施教”。
2. 不同采样策略对比
研究者测试了不同的采样方法,结果显示 CDAS 在各个维度上都表现优异。
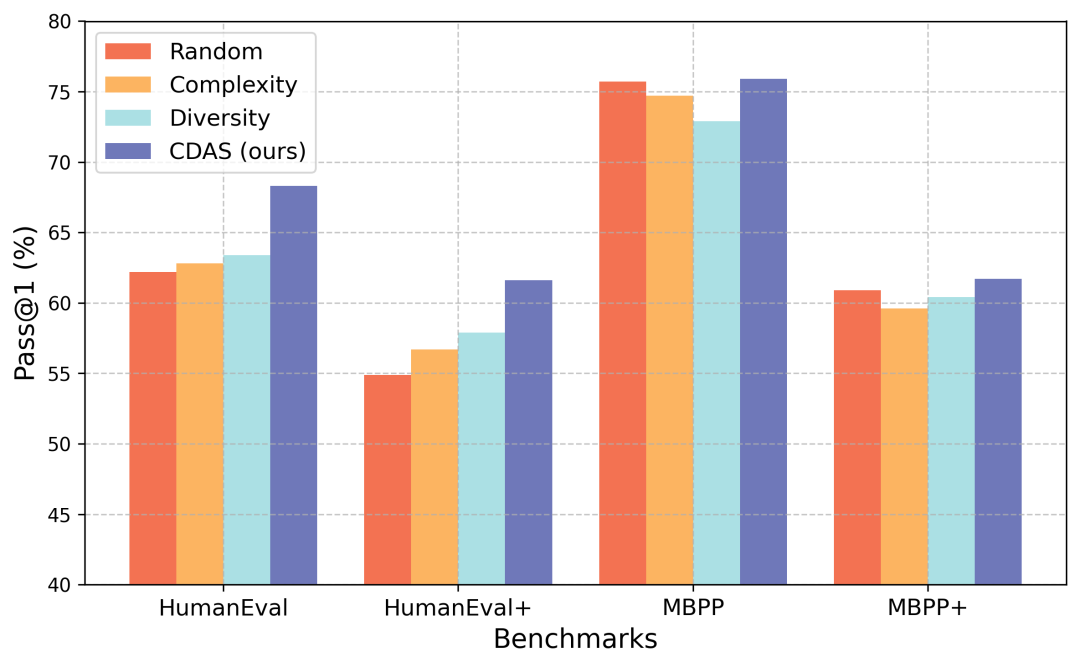
图 2 对比了随机采样(Random)、仅看难度(Complexity)、仅看多样性(Diversity)和 CDAS(Ours)。可以看到 CDAS 在 HumanEval、MBPP 等主流榜单上均稳居第一,证明了“难度+多样性”缺一不可。
实验结果:40% 的数据,翻倍的战力
实验数据非常震撼。在HumanEval这种硬核代码测试集上:
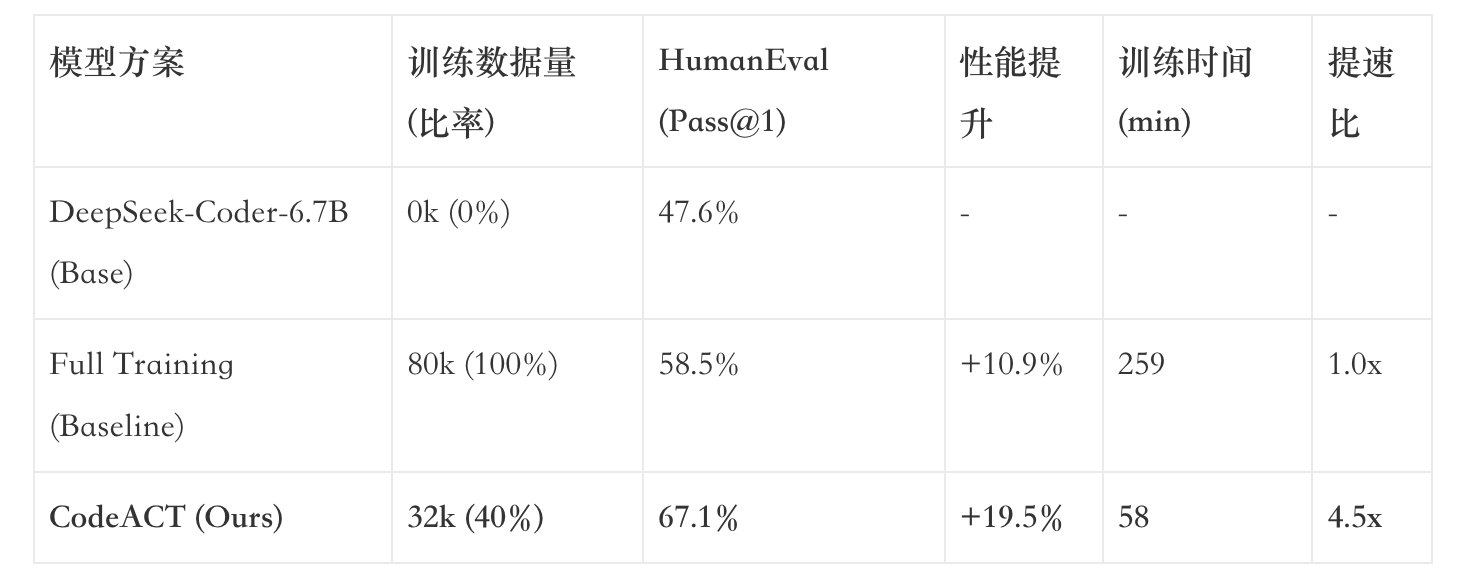
这意味着什么?数据量只用了原来的 40%,分数反而提高了 8.6 个百分点(相对于 Baseline)。更夸张的是,时间缩短了 4.5 倍。
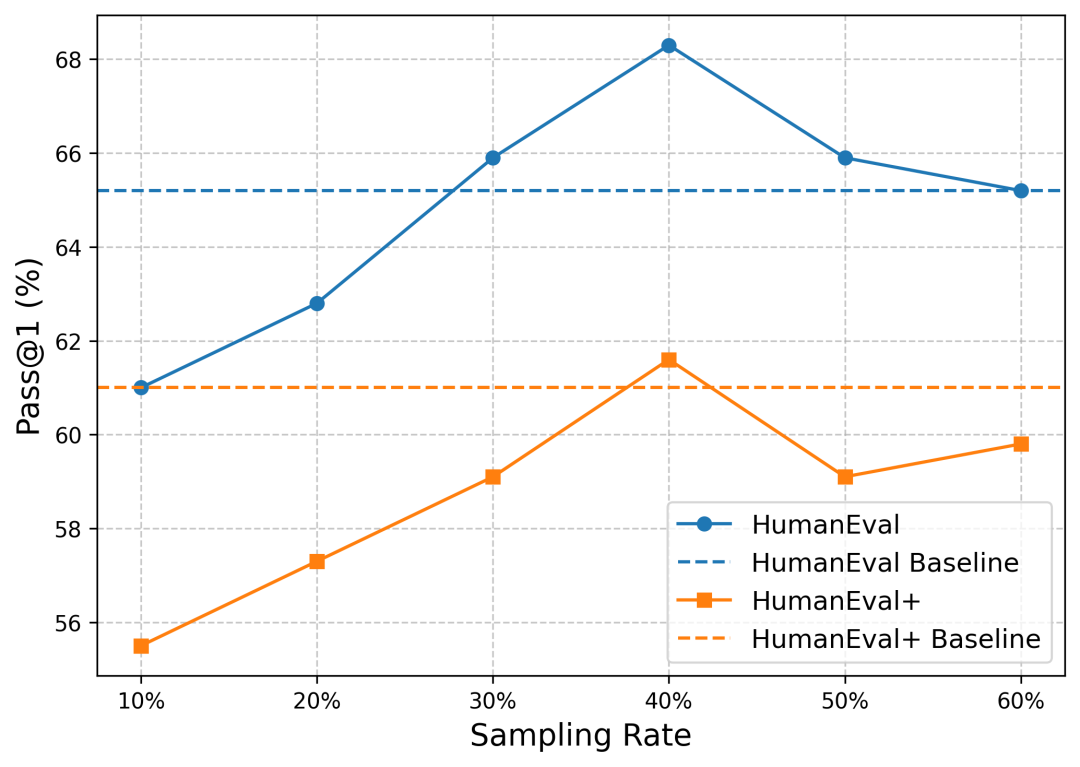
图 3 揭示了一个有趣的现象:随着采样率提高,性能并不是无限增长的。在 40% 左右达到了一个黄金平衡点。这暗示了数据集中存在大量的“噪声”或“垃圾信息”,过多的低质数据反而会干扰模型的学习。
深层的启示:关于进化的三个思考
启示一:高质量的“减法”是最高级的“加法”
在信息爆炸时代,冗余信息反而会变成负担。不管是训练 AI 还是提升自我,“克制”比“贪婪”更能创造奇迹。
启示二:自适应系统需要“自我觉察”
只有系统本身知道自己的盲区在哪里。一个优秀的进化过程,不应该是被外界强行灌输,而是建立一种“自反性”。
启示三:工程细节决定了成败的上限
真正的卓越,往往隐藏在那些看似不起眼的“打包”细节里。
影响与争议
影响
CodeACT 降低了开源社区复现顶级代码模型的门槛。它证明了,普通算力通过巧妙的策略也能挑战巅峰。
争议与局限
- 难题的正确性:CDAS 选出的“难题”本身代码逻辑是否正确?如果喂给模型“高难度的错题”,后果可能很严重。
- 泛化边界:仅用精选数据是否会导致模型没见过“市面”?这还需要在更广阔的编程场景中验证。
写在最后
CodeACT 的故事告诉我们,当我们开始在数据和效率上运用“智慧”时,技术进化的齿轮才会真正加速。AI 训练的“自动挡”时代,才刚刚开始。
关键术语表
- LLM(大模型):Large Language Model。
- CDAS:复杂度与多样性感知采样,兼顾难题与覆盖广度。
- IFD(指令跟随难度):衡量模型理解指令困难程度的指标。
- Dynamic Pack(动态打包):首尾相连填满算力的策略。
- HumanEval:OpenAI 发布的常用代码基准测试集。
原论文:CodeACT: Code Adaptive Compute-efficient Tuning Framework for Code LLMs作者:Weijie Lv, Xuan Xia, Sheng-Jun Huang (南京航空航天大学 & 深圳市人工智能与机器人研究院)
本文由 @yan 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务






- 目前还没评论,等你发挥!


