
 起点课堂会员权益
起点课堂会员权益评测体系架构设计:从模型到智能体的全面评估框架
面对AI模型或智能体的评测难题,你是否感到无从下手?本文提供了一套完整的评测操作系统,从选型、验收到排查三大实战场景切入,教你如何精准提问、获取证据并做出决策。通过评测驱动开发(EDD)方法论,你将掌握从基座模型到智能体的全方位评估框架,实现从主观争论到客观归因的根本转变。

如果你正面对一个AI模型或智能体,想知道“它到底行不行?”,却苦于不知从何测起、测什么、测完又该如何决策——那么这份指南正是为你写的。
我们不会从复杂的理论开始。评测体系的本质,是 一套帮你“问对问题、拿到证据、做出判断”的操作系统。本文将直接带你进入三个最真实的战场:
- 选型战场: “几个模型,我该选哪个?”
- 验收战场: “新版本改好了,能上线了吗?”
- 排查战场: “线上出问题了,根因在哪?”
什么是评测
随着人工智能从单一的预测模型,演进为能够感知、规划、决策并执行复杂任务的智能体(Agent),传统的评测范式已面临严峻挑战。一个成功的AI系统,不仅要求其“基座模型”(如大语言模型、语音识别ASR、文本转语音TTS、多模态模型)具备卓越的基础能力,更要求在此基础上构建的“智能体”能够可靠、安全、高效地完成端到端任务。
评测驱动开发(Evaluation-Driven Development, EDD)
传统的软件开发是由测试驱动的,目的是为通过精确的测试用例,确保每个代码单元的行为符合确定性预期。
AI应用,是基于大模型开发的,其本质是属于概率性的生成,而模型生成对应的答案,它的决策逻辑是隐性的,可以理解成,模型也在猜你想要的答案。这代表着不会有一个明确的答案,或者说固定的答案,它的结果是基于概率的预测,也代表着它的结果并不那么固定,是一个“黑盒”;
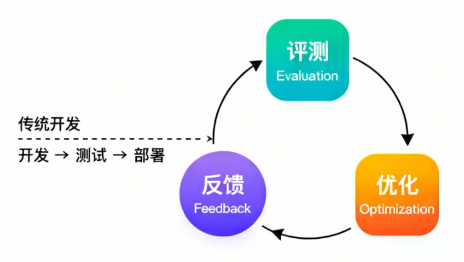
评测驱动开发(Evaluation-Driven Development, EDD)正是为应对这一转变而生的新范式。它是一种以持续评测为核心驱动力,通过系统性验证和优化AI&智能体能力与行为逻辑的方法论。
通过将系统性评测深度嵌入开发全流程,形成“评测-反馈-优化”的闭环,为驾驭复杂的AI系统提供了质量保障、系统稳定和建立用户信任的导航塔。
通过设计不同的评测集,进而验证模型能力,通过持续的评测反馈,来了解AI的能力边界&可能会出现的风险;
评测的5W1H——在行动前先对齐认知
- 动机(WHY):为何评测?明确评测的核心目标,是为模型选型、能力诊断,还是驱动迭代优化。
- 对象(WHAT):评测什么?界定评测的具体目标,是基础模型、行业模型,还是智能体应用。
- 时机(WHEN):何时评测?将评测融入研发全生命周期,而非仅作为事后验收。
- 维度(WHERE):从何处评测?设计一套全面、科学的能力维度与高质量的评测集。
- 方法(HOW):如何评测?定义客观的推理方式、评估指标和评分标准。
评测框架
我提出了一个包含目标、指标、方法、实施、治理五个层次的完整评测体系;
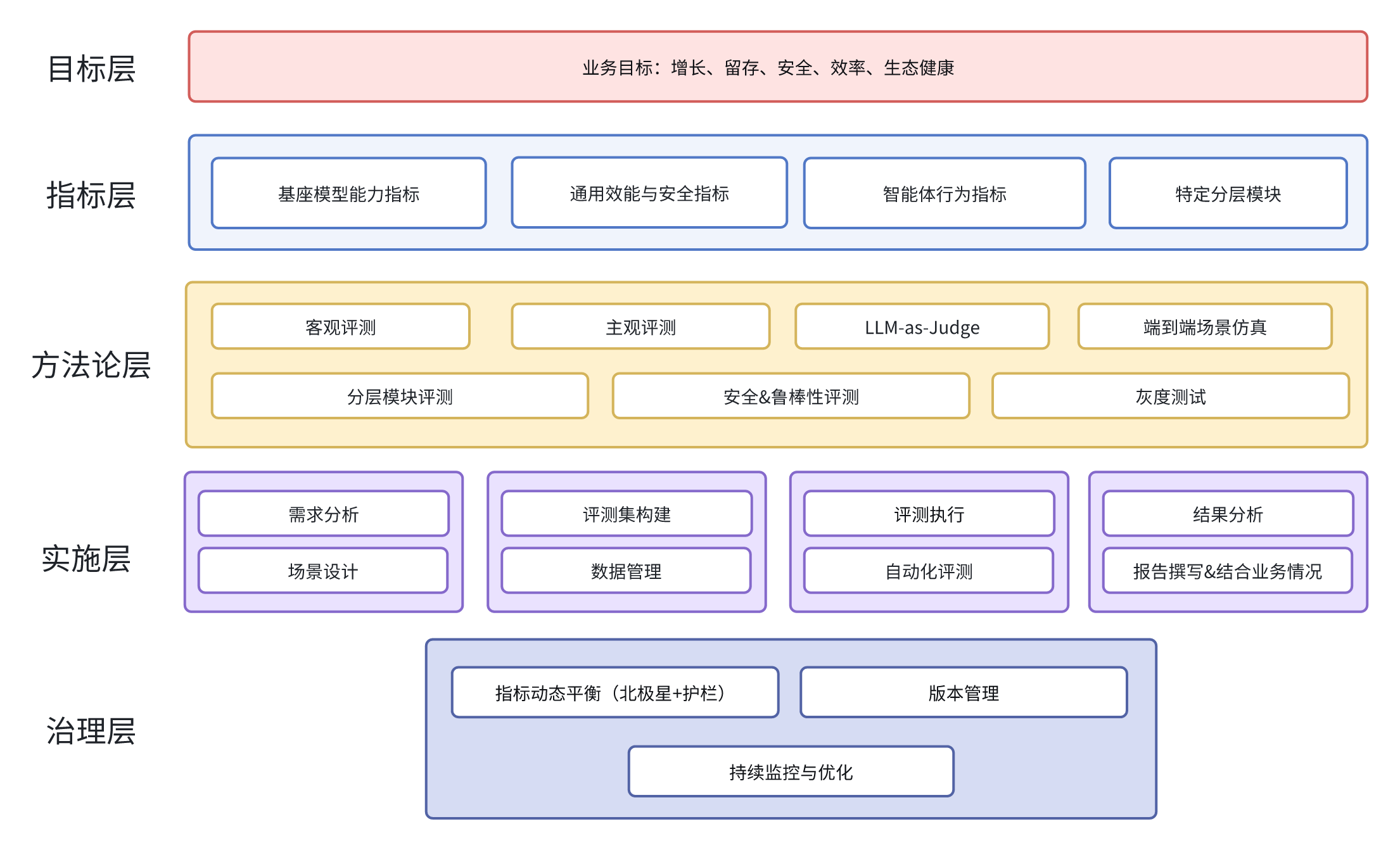
- 目标层:定义评测的终极目的,确保与业务战略对齐;
- 指标层:将评估目标分解为可衡量的维度,融合了“用户体验指标”与大模型的“能力/安全/对齐”维度;
- 方法论层:提供评估工具箱,根据评估目标选择合适方法;
- 实施层:将方法论落地为具体操作流程“评测流程”;
- 治理层:确保体系持续健康运行,引入“动态平衡”理念;
评测指标矩阵:基座模型与智能体的分与合
指标是评估体系的灵魂。我们将其划分为四类:
- 基座模型能力指标
- 智能体行为指标
- 通用效能与安全指标
- 特定分层模块
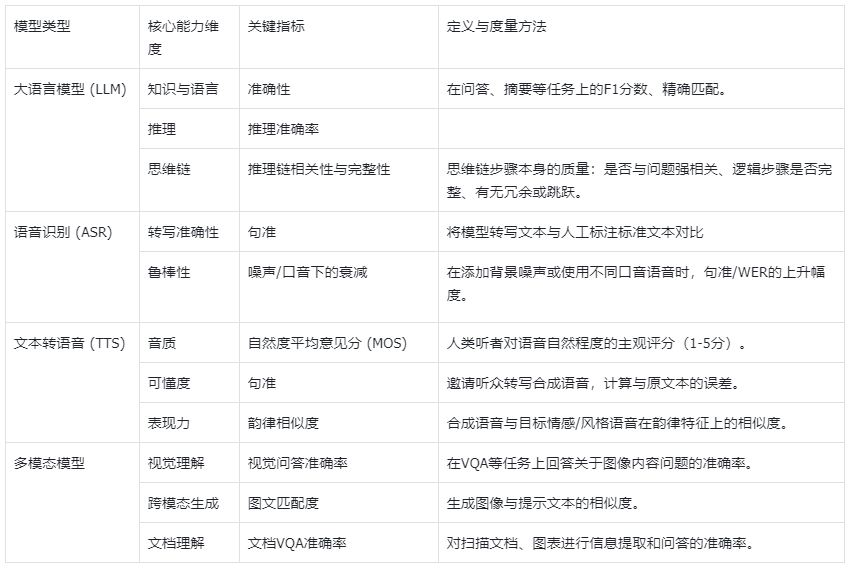
基座模型能力指标
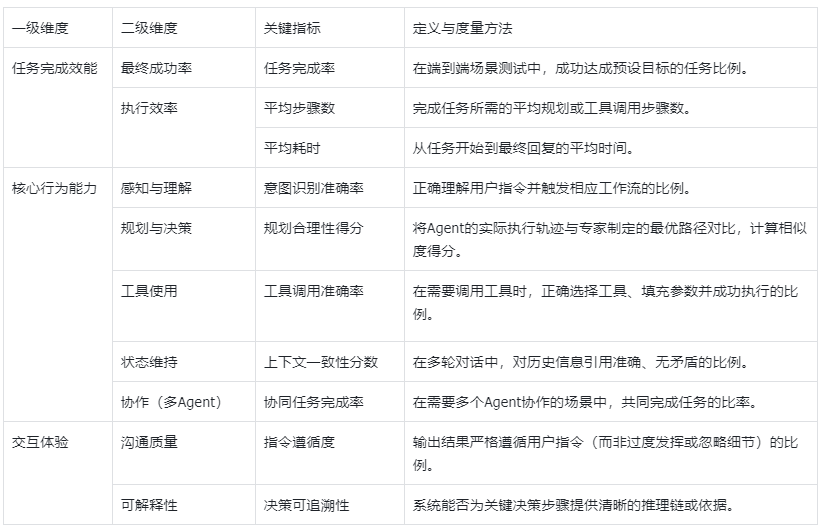
智能体行为指标
通用效能与安全指标
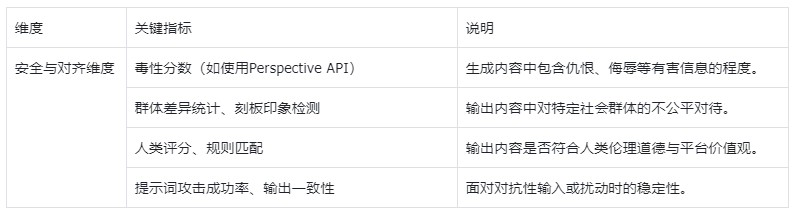
特定分层模块
- bad case回归:使用线上问题中的用户的负面反馈,或者在测试、质检等环节形成的案例,经过标注形成Bad Case作为评测集。目的是为了验证优化工作对bad case的优化效果。
- 功能模块/链路评测:是从“模型单点能力”切换到“系统协作能力”。很多线上翻车根本不是模型不行,而是链路不稳定、约束没做好、工具调用不可靠。比如评测模型应用中的意图识别模块的准确率、知识库部分的召回准确率等。通过评测识别各功能的效果方便后续进一步优化。
这种情况下可以针对评测对象的各种功能针对性设计评测集。
比如:
- RAG的检索是否找得到、找得准、引用是否正确、回答是否被证据约束。
- 文生图看是否能把图里信息结构化,并且在多轮里保持一致。
这一类评测做得越好,我越容易定位责任:到底是模型问题、检索问题、工具问题,还是提示词/约束问题。对产品来说,这意味着我能更快迭代,而不是在“模型不行/系统不行”的争论里来回拉扯。
评测方法论
根据评测不同指标和场景

根据评测方式
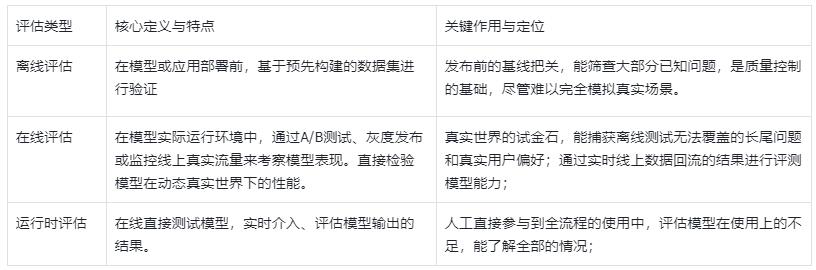
实施流程
评测集构建原则
高质量的评测集决定评测的置信度,是我们提出评测集构建的 “RADICAL”原则:
- 代表性 (Representative): 覆盖核心用户场景和请求分布。
- 真实性 (Authentic): 优先使用脱敏的真实数据或高保真合成数据,或用LLM生成+人工校验的高仿真数据。
- 多样性 (Diverse): 涵盖不同难度、风格、边缘案例。
- 防污染 (Isolated): 严格隔离测试集与训练集,防止数据泄露至训练集,导致分数虚高。
- 覆盖度(Coverage):覆盖关键功能点&覆盖关键部分内容;
- 可标注性 (Annotatable): 具备清晰、可操作的标注标准。
- 分层 (Layered): 建立“基础-进阶-挑战”三级体系。
对于智能体评测,需额外构建包含工具调用序列、环境状态变化、多轮对话上下文的轨迹级标注数据。
评测流程(在已有明确的规则下)
- 需求分析与设计:明确业务场景、评测对象和目标。
- 数据准备:根据RADICAL原则构建或准备评测集。
- 评测执行及优化:选择合适方法执行评测,分析结果并迭代优化模型或系统。
- 上线运营:基于评测结果做出上线决策,并转入持续监控。
我们将评测体系的应用浓缩为三个最高频、最核心的场景,并为每个场景配备“操作流”与“决策清单”。
场景A:模型/智能体能力排查与根因定位
- 触发条件: 线上监控告警(如错误率上升、用户负面反馈)、发现系统性缺陷。
- 核心目标: 快速定位问题是源于基座模型、任务规划、工具调用、还是其他系统模块。
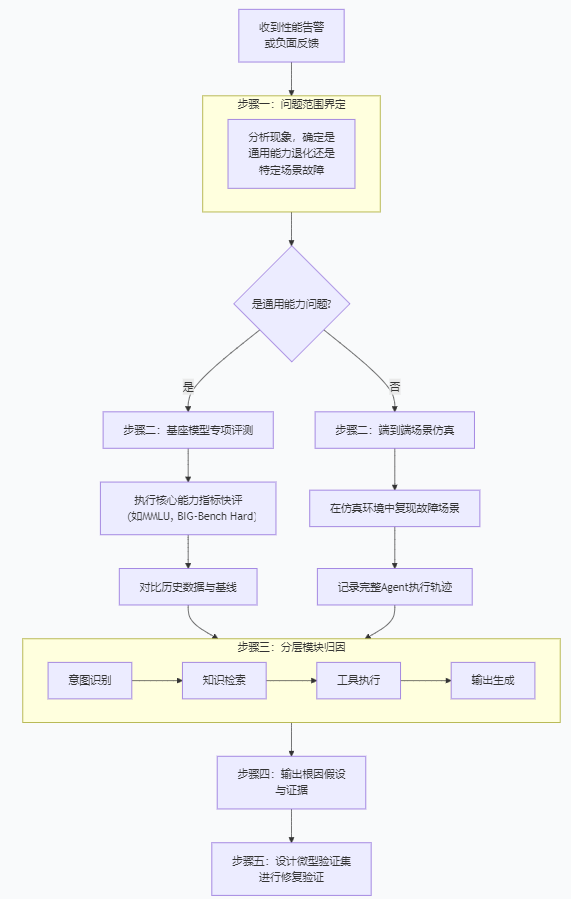
步骤二:评测
- 专项评测(离线评估)
- 端到端场景仿真评测(运行时评估)
决策清单(用于步骤三、四):
- 意图识别层: 用户query是否被正确解析?历史上下文是否被准确捕捉?(检查:意图识别准确率日志)
- 知识/检索层: 检索到的文档是否相关、完整、时效性足?(检查:检索召回率、精确率;引用来源相关性)
- 规划与工具层: Agent制定的步骤计划是否合理?工具选择是否正确?参数填充是否准确?(检查:规划合理性得分、工具调用成功率日志)
- 基座模型层: 在给定的正确上下文和工具结果下,模型的生成本身是否有问题?(检查:将前三层结果“固定”为理想状态,单独评测模型生成质量)
- 安全与约束层: 是否因过度严格的安全过滤导致合理答案被拦截?或约束不足导致幻觉?(检查:安全规则命中日志、输出与原始证据的一致性)
场景B:版本迭代与上线决策
触发条件: 新模型训练完成、智能体逻辑重大更新、主要工具链升级。
核心目标: 判断新版本是否达到上线标准,并识别潜在风险。
操作流:
- 建立评测基准线
- 执行对比评测: 在完全相同的评测环境和数据集上,测试新版本(V-new)。
场景C:能力对标与竞品分析
核心目标: 客观量化自身与竞品在各维度上的优劣。
操作流:
- 定义对标战场: 明确对比的范围(如:通用知识问答、金融报告分析、代码生成)。
- 构建/选用中立评测集
- 实施公平评测: 确保评测环境、提示词模板、上下文长度等变量一致。采用 “双盲”评测(LLM-as-Judge或人工)。
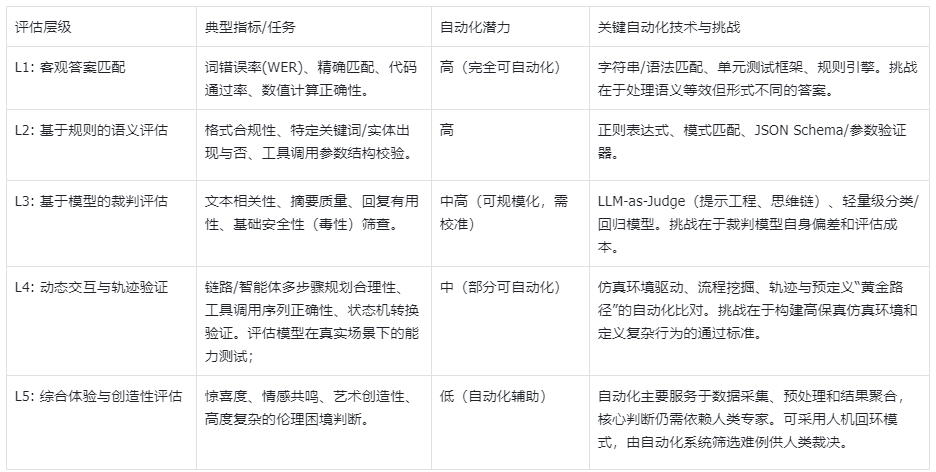
自动化评测
在面向基座模型与智能体的评测体系中,自动化评测不是一种可选项,而是支撑体系高效运转的核心引擎。它的价值体现在三个层面:
- 效率提升:将评测周期从“周/月”缩短至“小时/分钟”,实现快速迭代验证。
- 一致性保障:消除人工评估的主观偏差,确保评估结果的可重复性与可比性。
- 并非所有评估都适合全自动化,在任务足够客观时/规则足够明确时,才更加容易;
治理与持续运营:实现动态平衡
评测体系不是一成不变的,需要持续运营和调整,其核心是 “北极星+护栏”动态平衡模型。
- 锚定北极星指标 (North Star Metric): 选择1个最能代表模型核心价值的业务指标,作为全团队一致的努力方向。
- 设置护栏指标 (Guardrail Metrics): 定义一组防止系统跑偏的监控指标。基于不同的业务的需要,定义不同的系统性指标
- 模型版本管理:严格关联模型文件、评测报告和上线决策。
- 评测集版本管理:任何评测集更新需记录变更日志,并重新评估基线模型以校准分数波动。
总结
至此,我们已经共同构建了一套从模型到智能体的全面评估框架。
这套体系的意义,远不止于“打分”或“排名”。它是一套动态的导航系统,旨在帮助你和你的团队,在复杂且快速演进的AI浪潮中,实现三个根本性的转变:
- 从“主观争论”到“客观归因”:当线上效果不佳时,不再陷入“模型不行”还是“系统不行”的无休止争论。利用“分层模块评测”与“五步诊断法”,你可以像资深医生一样,迅速定位病灶是源于基座模型的“脑力”,还是RAG检索的“记忆力”,亦或是工具调用的“执行力”。
- 从“经验决策”到“证据决策”:在决定是否发布新版本、该选择哪个模型时,不再依赖模糊的感觉。基于测试后的结果&分析,你的每一次关键决策都有清晰的证据链支持。评测报告,就是你最可靠的技术罗盘。
- 从“静态快照”到“动态进化”:评测不是项目终点的验收,而是贯穿产品全生命周期的脉搏。通过北极星与护栏指标的动态平衡、评测集的持续演进,以及自动化评测的深度集成。
本文由 @一葉 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


