
 起点课堂会员权益
起点课堂会员权益AGI bar火爆背后:模型蒸馏技术如何重塑未来?
AI酒吧的爆红背后,隐藏着一项正在重塑行业的技术革命——模型蒸馏。这项技术如同名师传授智慧,让小型模型获得媲美GPT-4等巨头的核心能力,同时实现惊人的效率提升与成本压缩。本文将深度解析模型蒸馏的原理、价值与未来走向,揭示AI民主化进程中的技术突破与商业博弈。

近期,名为“AGI bar”的酒吧在AI圈迅速走红,中文名知识蒸馏,契合AI模型训练中的“知识蒸馏”技术,同时AI领域也让一项重要技术——“模型蒸馏”(Model Distillation)——重新回到了聚光灯下。(PS:恰好前几日有空去了,附赠图片)
那么究竟什么是模型蒸馏?简单来说,这个过程好比一位博学的教授,将毕生所学教授给一个聪明的学生,使其虽未“读万卷书”,却能掌握核心智慧,举一反三。
这一概念最早可追溯至2015年,由深度学习巨擘Geoffrey Hinton等人开创性地提出。当时其价值并未完全显现,时至今日,随着GPT-4等万亿参数模型的诞生,让整个行业陷入了一场“成本危机”。模型蒸馏,作为应对这场危机的关键解方,迎来了它的第二春。
01.模型蒸馏科普——不是压缩,是“传授”
要理解模型蒸馏的精髓,首先要摆脱一个常见的误解:它不等于简单的模型压缩。如果说压缩是在为模型“减肥”,那么蒸馏则是在进行一场深度的“知识传授”。
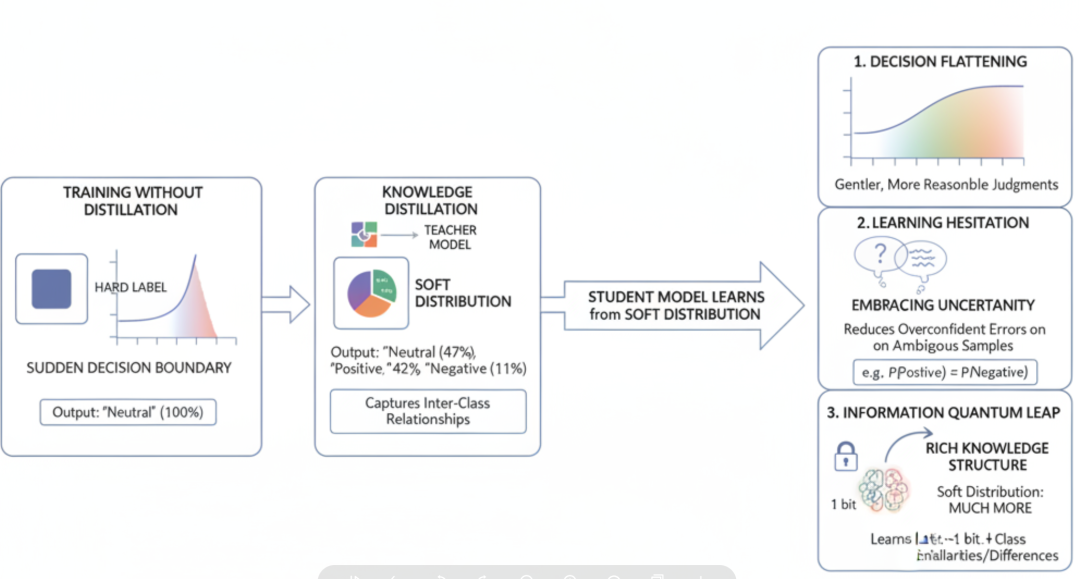
它不是在教小模型“标准答案是什么”,而是通过让大模型输出决策时的完整概率分布(例如,在情感分析中,输出的不是简单的“中性”,而是“42%正面、47%中性、11%负面”),教会小模型“答案在决策空间中的精确位置与边界关系”。
通过这种方式,学生模型学到的是连续的逻辑缓坡、合理的犹豫判断以及类别间的深层结构信息,而不仅仅是一个个离散、僵硬的标签。
传统AI的困境:巨人住不进小房子
近年来,以GPT-4为代表的巨型语言模型(LLM)在能力上取得了惊人的突破,同时带来挑战。
首先是 算力现实 。运行一次万亿参数级别的模型,不仅成本高昂,而且速度缓慢。例如,一次GPT-4的推理延迟可能超过0.5秒,内存占用高达100GB。
其次是需求矛盾 。在绝大多数现实应用场景中,我们并不需要一位无所不知的“爱因斯坦”来解决所有问题。
比如,一个用于实时监控系统日志并进行分类的AI,其核心任务可能仅仅是达到90%的准确率。
在这种场景下,动用一个万亿参数的大模型无异于“杀鸡用牛刀”,性价比极低。我们真正需要的,是一个反应迅速、成本低廉、足够聪明的“实习生”。
蒸馏的核心比喻:名师出高徒
模型蒸馏正是为了解决这一矛盾而生。它构建了一个“名师出高徒”的教学框架:
- 教师模型:通常是像GPT-4、DeepSeek-R1(671亿参数)这样经验丰富但行动笨重的“教授”。它们经过海量数据的充分训练,拥有强大的泛化能力和深刻的知识理解力。
- 学生模型:则是像小型BERT(1.1亿参数)或Qwen-7B(70亿参数)这样轻快好用的“学生”。它们结构简单、参数量小,专为高效运行而设计。
蒸馏过程的 关键突破 在于,学生模型并非简单地模仿老师给出的“标准答案”(即硬标签),而是学习老师在做出判断时的“思考过程与判断犹豫”。这个“思考过程”正是通过教师模型输出的完整概率分布(即软标签)来体现的。这使得知识的传递更加细腻和深刻。
原理层精讲:到底“教”了什么?
为了更深入地理解蒸馏的魔力,我们需要探究其原理层的三大核心变化。
从“硬标签”到“软分布”:以一个情感分析任务为例。对于一条评论,传统的训练方式是给它一个“中性”的硬标签。而蒸馏则不同,教师模型可能会输出一个软分布:“47%中性、42%正面、11%负面”。这个软分布告诉学生模型:这条评论虽然整体偏中性,但它与“正面”的相似度远高于“负面”。这其中蕴含的类别间关系信息,是硬标签完全无法提供的。
基于这种软分布的学习,带来了三大原理性变化:
- 决策拉平:在未蒸馏的模型中,决策边界往往是“一刀切”的。通过学习教师模型的软分布,学生模型学会了在决策空间中构建一个连续、平滑的概率坡道。这使得它的判断更加柔和、合理。
- 学会犹豫:教师模型的软分布中包含了其对判断的不确定性。例如,当正面和负面概率相近时,就体现了模型的“犹豫”。模型会“不自信”,从而在面对模糊或困难的样本时,能够减少过去小模型常犯的“过度自信”的武断错误。
- 信息跃迁:一个硬标签(如“中性”)所包含的信息量大约只有1 bit。而一个包含多个类别概率的软分布,其信息量远超于此。这实现了一次“信息跃迁”,让学生模型不仅学到了答案,更学到了类别之间的相似性、差异性以及整体的知识结构。
02.蒸馏的四大亮点——为何它是技术民主化的关键
模型蒸馏之所以被视为推动AI技术民主化的关键力量,是因为它在效率、成本、性能和灵活性方面带来了革命性的改变。
亮点1:极致瘦身,效率革命
蒸馏技术最直观的优势在于其惊人的“瘦身”效果。以具体数据为例,一个像DeepSeek R1这样的670亿参数模型通过蒸馏,我们可以得到一个仅有数亿参数的小型模型,其内存占用可降至200MB,推理延迟更能缩短至0.05秒。
这种数量级的优化,意味着AI模型终于可以摆脱对昂贵云端服务器的依赖,真正跑进手机、智能家居、车载系统等资源受限的设备中,实现无处不在的智能。
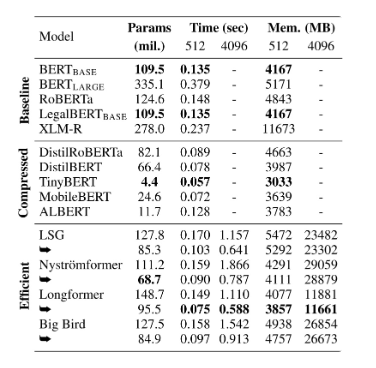
该表格清晰展示了模型蒸馏与压缩的效果。相较于BERT等基线模型,经过压缩的DistilBERT和TinyBERT在参数量、推理时间及内存占用上均实现了显著降低,证明了小型化技术在提升效率方面的巨大潜力。
亮点2:训练加速,迭代敏捷
训练一个千亿级别的大模型,往往需要动用上千块顶级GPU,耗时数月之久,成本高达数千万甚至上亿美元。这对于大多数企业和开发者而言是遥不可及的。
相比之下,蒸馏一个小型模型的过程则要敏捷得多。例如,训练DeepSeek R1可能需要1000个A100 GPU小时,而蒸馏训练一个小型BERT模型可能仅需5个GPU小时。
这种训练成本和时间的急剧下降,极大地降低了AI研发的门槛,使得中小型团队也能快速针对特定场景进行模型定制和迭代优化,从而加速了整个行业的创新步伐。
亮点3:更聪明,而非更笨
许多人会担心,模型变小了,能力是否也会大幅缩水?
结果是,蒸馏出的学生模型往往比同样规模、但通过传统方式训练的模型表现更佳。这得益于它吸收了教师模型强大的泛化能力。
因为学生模型学习的是教师模型对数据深层结构的理解(通过软标签和中间特征),而不仅仅是拟合训练数据本身,所以它在面对从未见过的新数据时,能做出更准确的判断。
业界已经涌现出许多惊艳的案例。例如,DeepSeek团队曾利用一个拥有370亿激活参数的MoE(混合专家)模型,蒸馏出一个仅有70亿参数的小模型。令人惊讶的是,这个7B模型的性能在多个基准测试中,足以媲美其他厂商发布的700亿参数级别的模型。这充分证明了“名师”的指导价值。
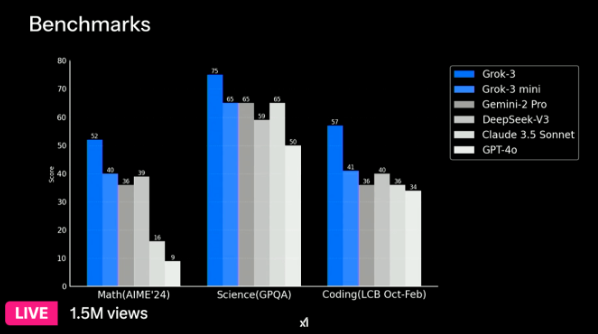
基准测试对比显示,即使是像Grok-3 mini这样相对较小的模型,在数学、科学和编程等多个领域也能取得与更大模型(如Gemini-2 Pro)相媲美甚至超越的成绩,这体现了高效模型设计的巨大潜力。
亮点4:场景灵活,万物皆可AI
蒸馏技术赋予了AI极高的场景定制灵活性。企业可以根据自身需求,从一个通用的“全科教授”(如GPT-4)出发,蒸馏出各种专攻特定领域的“小专家”。例如,可以为智能客服定制一个对话能力突出、响应迅速的对话模型;为内容平台定制一个高效精准的审核模型。这种低成本、高效率的行业落地能力,为实时监控,智能分析等前沿应用提供了方案,真正推动“万物皆可AI”的愿景成为现实。
03.防蒸馏兴起——技术盛宴中的防护墙
就在模型蒸馏技术高歌猛进,被誉为AI民主化福音的同时,一股“反向”潮流也开始涌动。科技巨头们在享受技术红利的同时,也开始警惕其核心知识资产被轻易“窃取”。
标志事件:Grok 3的“防蒸馏”铠甲
2024年,埃隆·马斯克旗下的xAI公司在发布其强大的Grok-3模型时,一个细节引起了业界的广泛关注:官方特别强调,该模型将具备“防蒸馏”(anti-distillation)技术,以保护其来之不易的知识产权techcrunch.comtechcrunch.c…。马斯克表示,在应用中会隐藏推理模型的“思考”过程,防止竞争对手通过模仿其输出来训练自己的模型。
关于其具体技术实现,业界有诸多猜想。一种可能是,API在返回最终结果时,会刻意隐藏或混淆内部的概率分布(logits),使得“学生”无法窥探“老师”的完整思路。其他可能的技术路径还包括对模型架构进行加密,或在输出中加入难以模仿的“水印”,从而增加知识提取的难度。

正如丹麦技术大学研究员Emil Njor所指出的,虽然小型化模型优势显著,但蒸馏过程本身可能非常耗费资源,且增加了技术复杂性。更值得警惕的是,大模型所有者可能会从法律或技术上限制对其模型的访问,从而阻碍蒸馏技术的创新。
为何要“防”?——AI知识产权的攻防战
巨头们筑起防护墙的动机非常明确:保护其核心商业资产。训练一个像Grok-3这样的大模型,背后是天文数字的投入。据报道,Grok-3的训练动用了约20万个顶级GPU,其算力投入是前代的10倍。这些投入不仅包括硬件成本,还涵盖了海量高质量数据的清洗与标注、顶尖研发人才的薪酬以及漫长的研发周期。可以说,训练好的大模型本身,就是这些公司最宝贵的知识产权。
如果任何人都可以轻易地通过模型蒸馏,以极低的成本“复制”出一个性能相近的模型,那么巨头们的商业护城河将不复存在。因此,“防蒸馏”的出现,标志着AI行业可能正在从早期的“开源共享”极客文化,逐渐转向更加注重商业利益的“闭源防护”模式
开放与保护的再平衡
“防蒸馏”的兴起,引发了一场关于开放与保护的深刻辩论。
从商业角度看,保护知识产权是企业维持竞争力和持续投入研发的必然选择。但从整个生态发展的角度看,过度防护又可能减缓技术的传播速度,抑制中小企业和学术界的创新活力。
未来,我们可能会看到一个更加复杂的局面:开源社区与闭源商业模式将长期并存,各自服务于不同的市场和用户群体。
同时,也可能出现一些折中方案,例如“有限度蒸馏”的许可模式,即大模型厂商授权合作伙伴在特定条件下使用其模型进行蒸馏,从而在保护自身利益和促进行业应用之间找到平衡点。
04.未来展望——蒸馏将带我们走向何方?
尽管面临商业博弈的挑战,但模型蒸馏作为一项底层技术,其推动AI走向实用化和普及化的大趋势已不可逆转。它将从多个层面深刻地重塑我们的未来。
硬件进化:更轻、更巧、更无处不在
模型蒸馏是让AI从云端数据中心走向日常生活每个角落的关键催化剂。
未来,无论是能够实时翻译的智能耳机、能主动感知并响应主人情绪的智能家居中控,还是具备高级辅助驾驶能力的汽车,背后都离不开高效运行的蒸馏模型。硬件的形态将不再受限于计算单元的体积和功耗,AI将以更自然、更无感的方式融入我们的生活。
开发者新范式:从“拼规模”到“拼精巧”
在过去几年里,AI领域的竞赛焦点一直是“更大、更强”,参数规模的比拼近乎疯狂。然而,随着2025年的临近,行业的风向正悄然转变。推理成本和部署效率正成为新的核心议题。开发者的范式将从“大力出奇迹”的规模竞赛,转向“精巧实用”的工程优化。
如何设计更高效的蒸馏算法、如何结合量化与剪枝等多种压缩技术、如何在有限的硬件资源上榨干每一分性能,将成为衡量AI工程师核心竞争力的关键标准。
对普通人的意义:AI民主化的加速器
归根结底,模型蒸馏对普通人最大的意义在于,它是AI民主化的终极加速器。
它让最尖端的AI智慧摆脱了云端的束缚,使其能够以低廉的成本、高效的方式赋能我们身边的每一个设备和应用场景。
尽管Grok-3等事件揭示了商业世界中存在的“防护墙”,但这并不会改变技术降低门槛、普惠大众的宏大叙事。因为市场的力量和用户的需求,终将推动技术向着更开放、更易得、更实用的方向演进。
05.结语
我们正步入一个“大智慧,小体积”的AI实用主义时代。从爆火的AGI bar到我们手机里日益聪明的语音助手,它们不仅仅是酷炫的硬件或软件,更是模型蒸馏技术成功落地的生动象征。
理解这背后“蒸馏”的魔法,以及围绕它所产生的技术创新与商业博弈,能帮助我们更清晰地洞察AI发展的脉络。这不仅是技术人员的必修课,也是每一个希望拥抱未来的人,理解这个正在被AI加速重构的世界的钥匙。未来已来,它比我们想象的更小,也更强大。
本文由 @kiddo 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议









这比喻太绝了,把技术讲得像武侠传功,又酷又接地气。