
 起点课堂会员权益
起点课堂会员权益都叫RAG?其中有个家伙是假的
RAG技术正被广泛讨论,但市面上混杂着三种截然不同的实现方式。本文将撕开伪概念的面纱,直击'直接扔文档'、联网搜索与本地向量检索三类技术的本质差异,揭示为何60%从业者对联网搜索RAG存在根本性误解,并剖析企业级向量检索在文档切割环节隐藏的致命陷阱。

最近在研究RAG,发现了一个有意思的现象:市面上有三种东西都在说自己是RAG,但仔细一看,其中有个根本不是。
先说这三种是什么
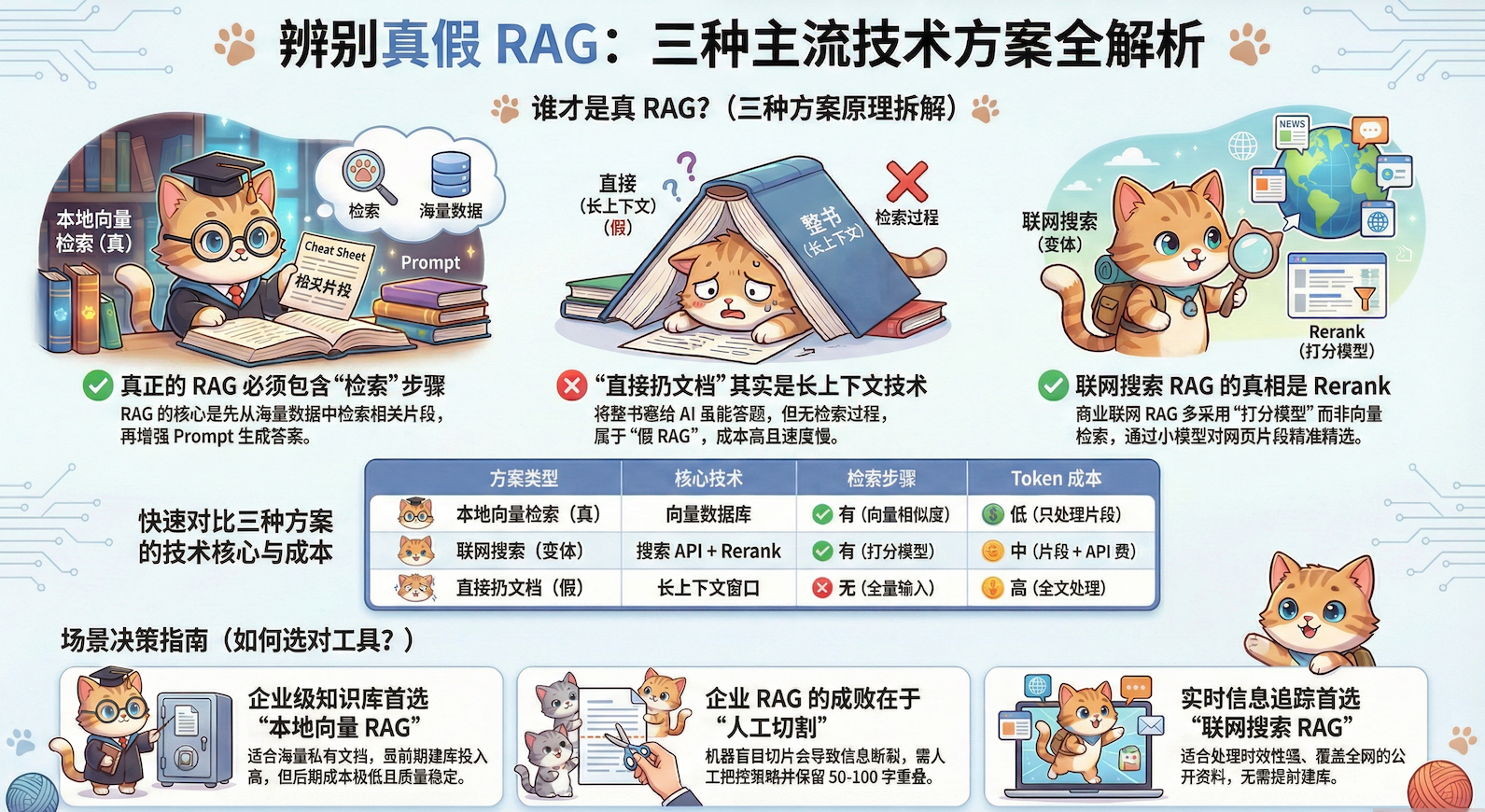
第一种:“直接扔文档”
把整份文档全部塞给AI,让AI自己去里面找答案。我们在处理文档内容,如让 AI 带着你看一本书,或者一些课程/工作会议的录音转文本的内容时候,经常会用到,让 AI 只关注我们给其的内容,帮我们整理或解答。
很多人以为这就是RAG。但其实…
这是假的!!!
第二种:联网搜索RAG
问个问题,系统去Google/Bing搜一圈,爬回来十几个网页,清洗一下、通过一个相关度打分模型打个分,挑几个最靠谱/分最高的片段给AI。Kimi、豆包、Perplexity用的就是这种。
这是大部分人最熟悉的RAG,但大家对它的理解可能是错的(后面会说)。
第三种:本地向量检索RAG
就是那种工程化的、正经的RAG。提前把文档切片、向量化、扔进数据库,用户问问题的时候通过用户的问题去库里检索最相关的几条,然后给AI。典型的电商智能客服就是这么干的。
这才是严格意义上的RAG,也是最复杂的一种。
为什么第一种是假货?
RAG这个词,全称是Retrieval-Augmented Generation,翻译过来就是”检索增强生成”。拆开来看:
- Retrieve(检索):从大量内容里筛选出最相关的
- Augment(增强):把筛选出来的内容塞进Prompt
- Generate(生成):AI基于这些内容生成答案
关键在“检索”这两个字。
第三种”直接扔文档”有检索这个步骤吗?没有。全部扔进去,AI读完整本书再答题,这叫长上下文技术,不叫RAG。
打个比方:
- RAG:考试时给你与题目相关的章节小抄(检索筛选)
- 长上下文:考试时让你背整本教科书(无检索,全靠记忆力)
虽然都能答题,但工作原理完全不同。
三种方式的核心差异
我整理了个表格,能看得更清楚:
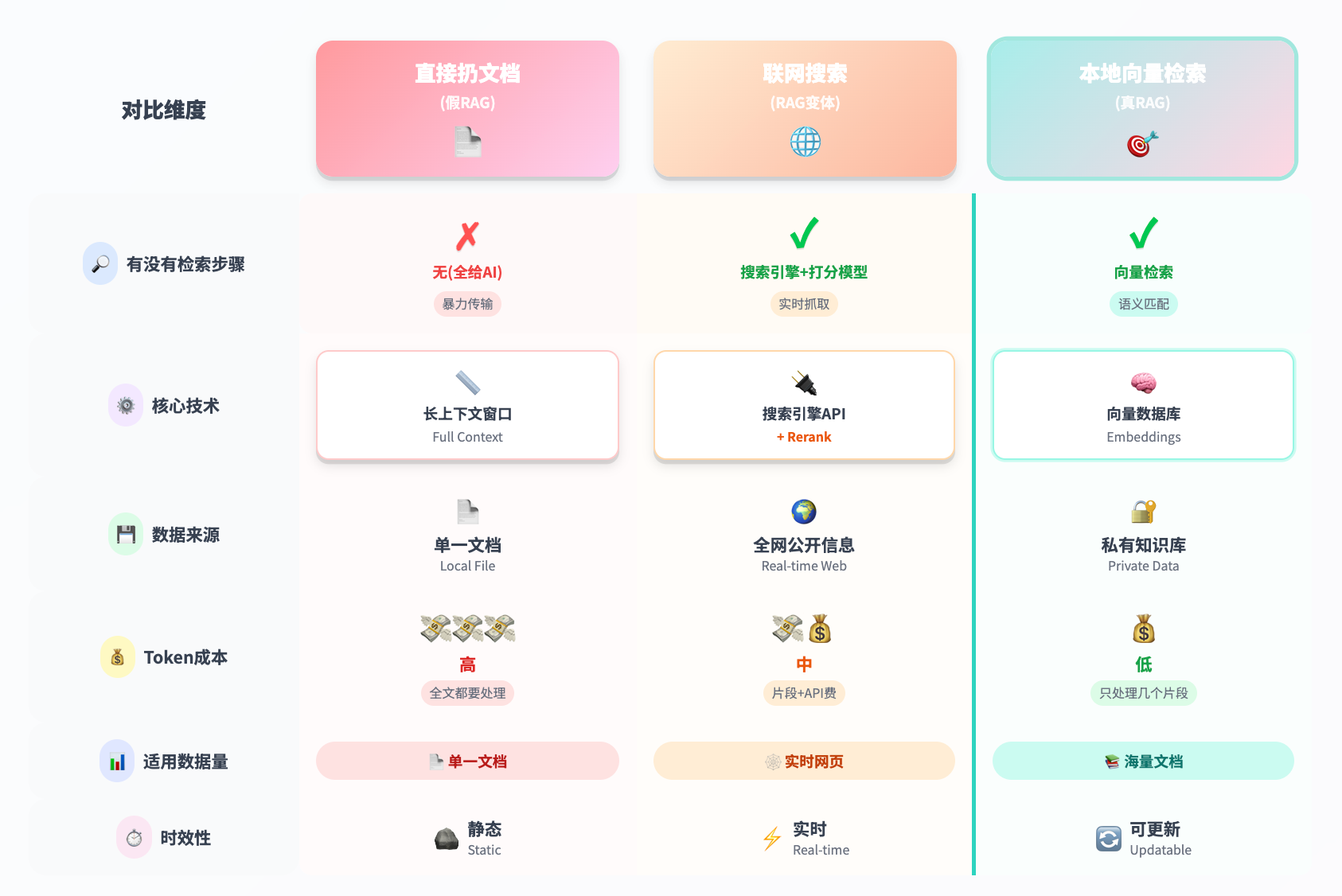
1. 直接扔文档(假RAG)
工作流程:
用户问题 + 整份文档 → 直接给LLM → 生成答案
问题在哪?
- 成本爆炸:1000本手册全扔进去,一次对话大量的输入可能要10刀乐
- 速度慢:处理超长文本需要时间,可能30秒才出结果
- 信息过载:模型的注意力机制问题,可能导致AI容易忽略关键信息,反而被无用信息影响
什么时候用?
- 单一PDF分析(比如分析一份合同)
- 一次性任务,不需要频繁查询
- 用支持超长上下文的模型(Claude 200k, Gemini 1M)
一句话总结: 能用,但成本高、速度慢,不适合规模化应用。
2. 联网搜索RAG(大众最熟悉的RAG)
这是大部分人接触最多的RAG,像Kimi、豆包、Perplexity都是这种。
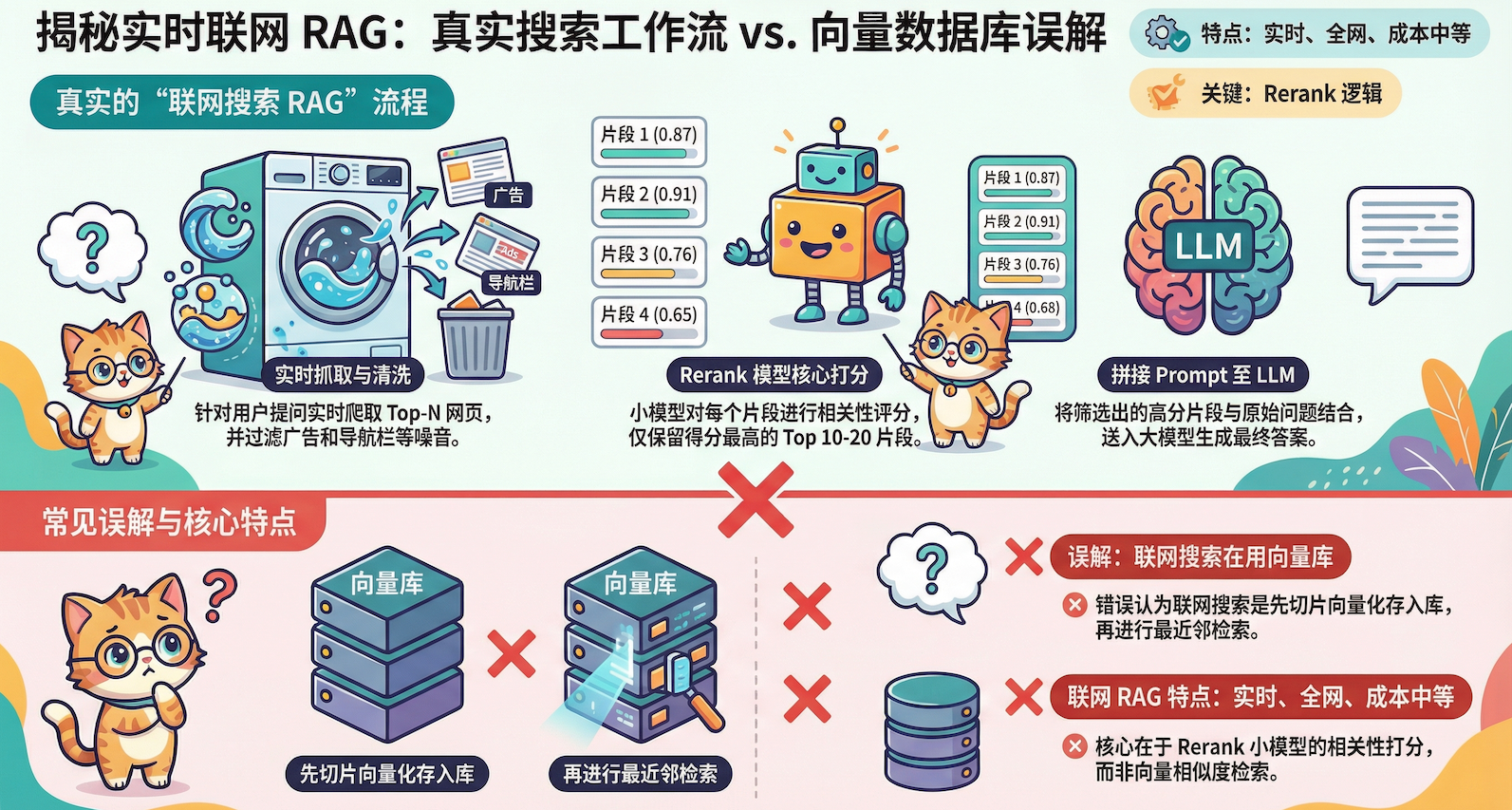
工作流程:
用户问题 → 调用搜索API → 获取Top-N网页 → 提取文本 → 清洗 → Rerank打分 → 选出最相关片段 → 拼接Prompt → 生成答案
关键特点:实时处理
联网搜索和本地RAG最大的区别:不提前建库,现爬现切。
为什么?因为网页内容实时变化,今天的新闻明天可能就过时了,没法提前建库。所以每次都是:
- 搜索引擎找到相关网页
- 爬取内容
- 清洗(去广告、导航栏)
- 切片(可能200个片段)
- Rerank打分(这是关键!)
- 选出Top 10-20个片段
- 给AI生成答案
Rerank是什么?
简单说,就是用小模型给片段打分。
从200个片段里选出最相关的10个,不能随便选,需要一个打分模型。这个模型会把”用户问题”和”每个候选片段”一起输入,输出一个0到1之间的相关性分数,然后按分数排序。
这就是为什么商业产品质量高:不是直接把搜索结果全扔给LLM,而是用专门的小模型精挑细选。
成本:
- API费用(搜索引擎调用)
- Token费用(片段注入Prompt)
- 总体成本适中
适用场景:
- 实时新闻问答(“今天发生了什么?”)
- 深度调研(“比较不同观点”)
- 事实核查(“验证某个说法”)
但是,大部分人对联网搜索RAG的理解是错的!
很多人以为联网搜索是这样工作的:
- 用户提问
- 大模型根据问题检索网络信息
- 网络信息被向量化模型切割、向量化
- 根据问题做向量化匹配
- 匹配结果发给大模型回答
看起来很合理对吧?但这不是事实。
实际上:
没有向量化,没有向量数据库,只有打分模型。
Rerank打分模型会把”用户问题”和”每个候选片段”一起喂给一个小模型,让这个小模型输出0到1之间的相关性分数,然后按分数排序。这个过程不需要向量化,是端到端的文本匹配打分。
所以:
- ❌ 误解:联网搜索用的是向量检索
- ✅ 真相:联网搜索用的是打分模型(Cross-Encoder)
为什么容易混淆?
有几个原因:
1. 都用了“外部知识”
✅ 对,三种方式都使用了外部知识
❌ 但这不代表都是RAG,也不代表都用向量检索
2. 都有“筛选”环节
本地RAG:向量相似度筛选
联网RAG:打分模型筛选
直接扔文档:没有筛选(所以不是RAG)
3. 技术名词太像
“向量检索”、”语义匹配”、”相关性打分”
这些词听起来都差不多,但实现方式完全不同
一句话总结: 时效性强,覆盖面广,适合实时信息和公开资料。但别误以为它用的是向量检索,实际是打分模型。
3. 本地向量检索RAG(真正的RAG)
说完前两种,现在揭晓:什么才是严格定义的RAG?
答案:向量检索。
这是最正统的RAG,也是企业级应用的主流。
工作流程:
离线阶段(提前做):
文档 → 切片 → 向量化 → 存入向量数据库
在线阶段(用户查询):
用户问题 → 向量化 → 向量库检索 → 召回Top-K片段 → 拼接Prompt → 生成答案
核心洞察:离线预处理
这是最关键的点。为什么要离线处理?因为如果不提前做,根本跑不起来。
举个例子:
- 化妆品电商有3000个产品,平均每个产品切20块,就是60,000个向量
- 如果每次用户问问题都要现场处理这60,000条数据:向量化需要2小时
- 用户早就关掉页面了
但如果提前处理好:
- 向量化用户问题:0.05秒
- 从向量库检索:0.1秒
- 生成答案:1秒
- 总计:1.15秒
这就是为什么企业级RAG必须离线预处理。不是为了炫技,是因为工程上必须这样做,否则根本跑不起来。
文档切割:企业级RAG最容易翻车的地方
这里要说一个很关键但经常被忽略的点:文档切割需要人工把控,不能靠机器随便切。
联网搜索RAG可以靠脚本/机器自动切割网页,因为即使切错了,最多就是这次回答没这么准确,下次搜索又是新内容。但企业级RAG不行,切错了就是长期性的错误。
举个例子:
智能客服场景 – 化妆品电商
产品信息原文:
“雅诗兰黛小棕瓶精华,核心成分:二裂酵母发酵产物溶胞物(占比30%),
具有修复功效。适合干性及混合性肌肤,孕妇慎用。”
如果切割在这里断开 ↓
[块1]:”雅诗兰黛小棕瓶精华,核心成分:二裂酵母发酵产物溶胞物(占比30%)”
[块2]:”具有修复功效。适合干性及混合性肌肤,孕妇慎用。”
用户问题:”小棕瓶的核心成分有什么功效?”
向量检索:召回了[块1],但[块2]的”修复功效”没召回
模型回答:”核心成分是二裂酵母…” (缺少功效信息) ❌
更糟的情况:
用户问题:”孕妇能用小棕瓶吗?”
向量检索:召回了[块1],但”孕妇慎用”在[块2]没召回
模型回答:基于[块1]幻觉回答”可以使用” ❌❌❌ (严重错误!)
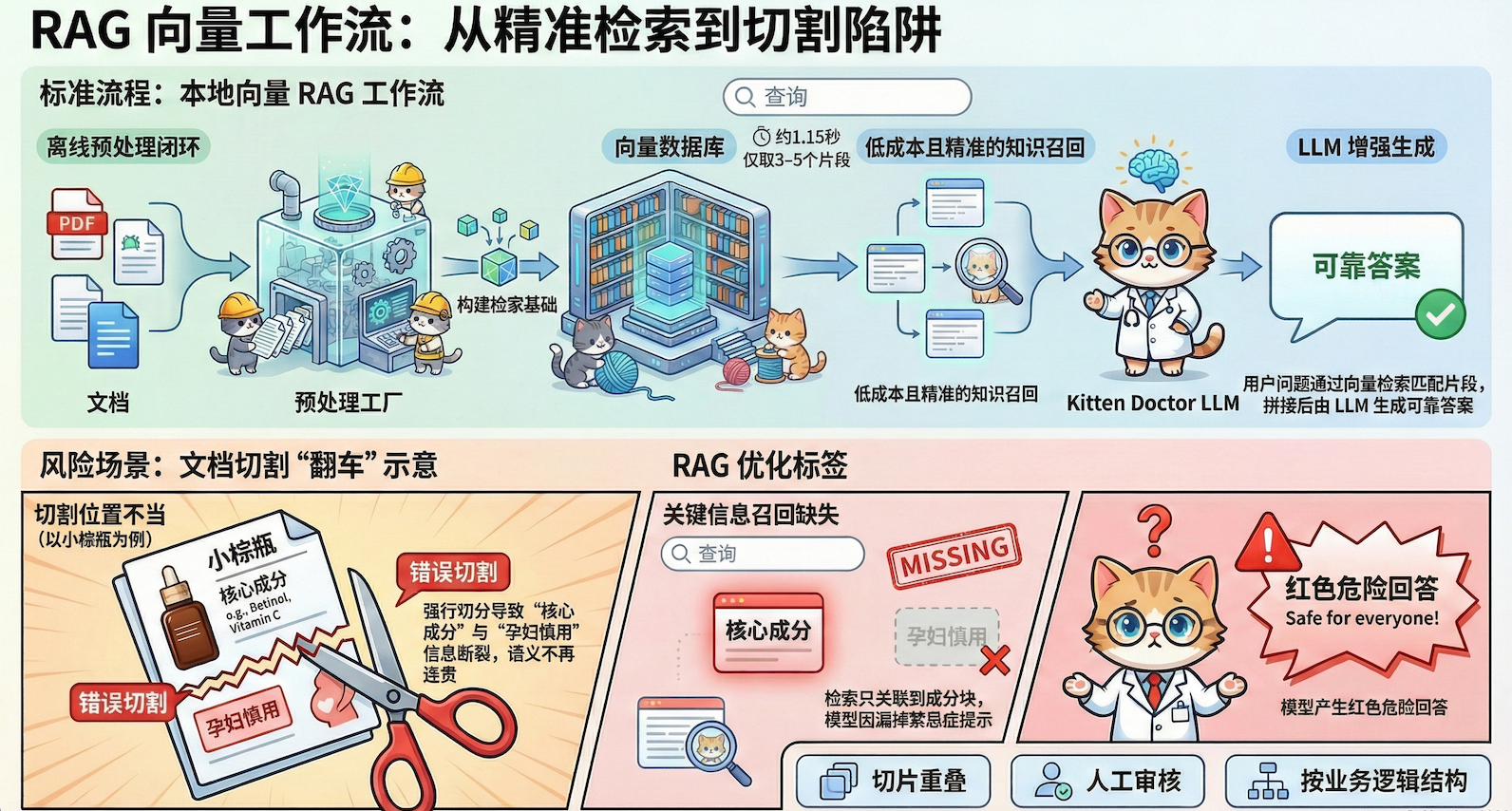
这就是为什么企业级RAG需要:
- 人工审核切割结果:检查关键信息有没有被切散
- 设计切割策略:按产品维度、按功能模块、还是按段落?要根据业务场景判断
- 切片重叠:相邻块保留50-100字重叠,避免信息断裂
- 质量把控:切完后抽查召回效果,发现问题及时调整
联网搜索可以”快糙猛”,因为是临时的。但企业级RAG是要长期使用的,切割质量直接决定系统质量。
成本对比:
- 只检索最相关的3-5个片段,一次查询可能只要$0.01
- 比“直接扔文档”便宜100倍
适用场景:
- 企业内部知识库(成千上万份文档)
- 客服问答系统
- 技术文档查询
一句话总结: 前期投入高(建库+人工把控),但后期成本低、速度快、质量稳定,适合海量数据的长期使用。这才是严格意义上的RAG。
什么时候用哪种?
这是最实际的问题。按照从假到真的顺序:
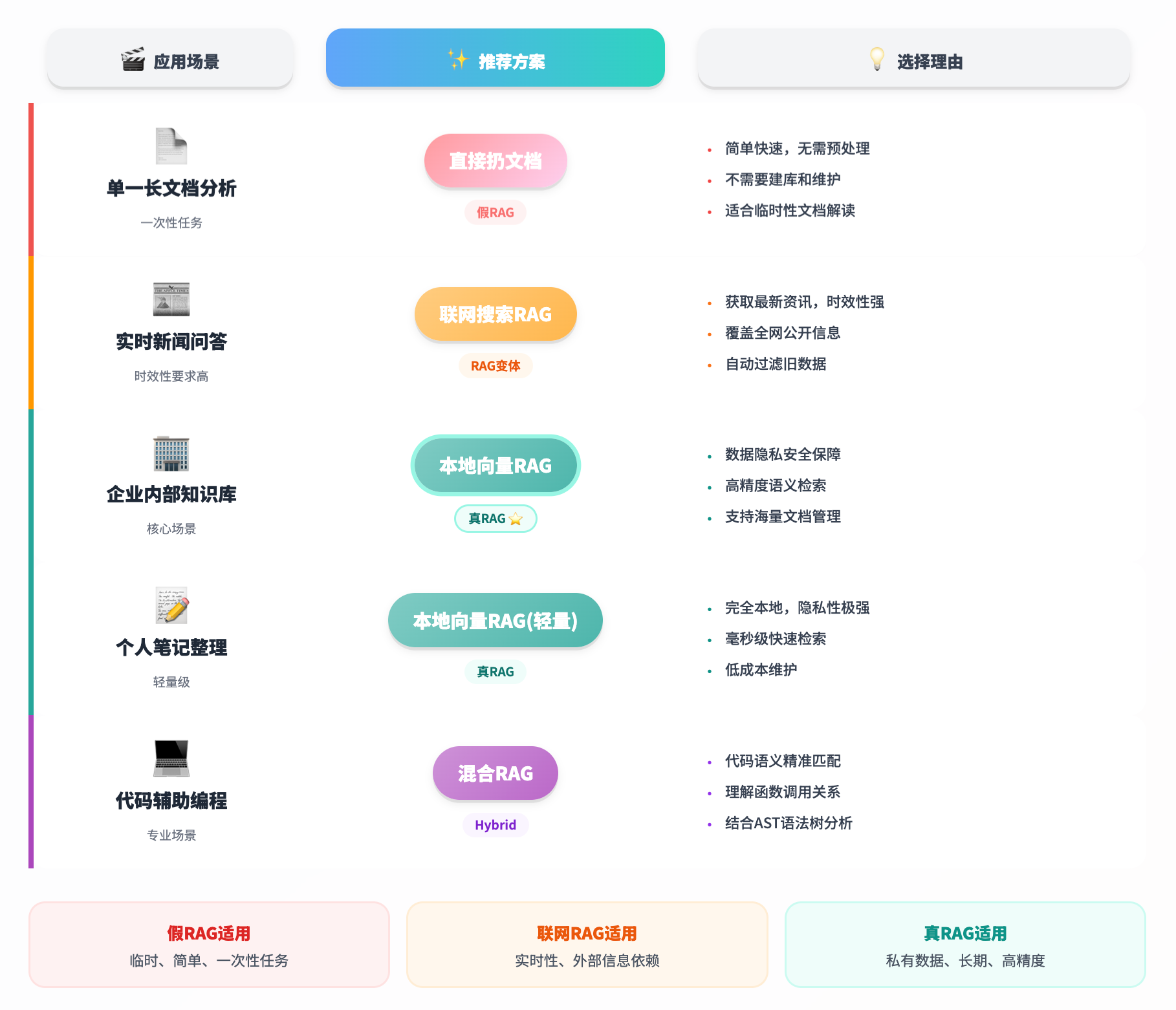
最后说几句干货
写到这里,总结几个关键认知:
1. 直接扔文档不是RAG
虽然大部分人以为这就是RAG,但它根本没有”检索”这个步骤。全部塞给AI,这叫长上下文技术,不叫RAG。
2. 大部分人对联网搜索RAG的理解是错的
不是”向量化切割+向量检索”,而是”爬取网页+打分模型筛选”。没有向量数据库,只有Rerank打分模型在起作用。这是大众最熟悉的RAG,但理解错了原理。
3. 严格定义的RAG = 本地向量检索
这才是真正的RAG,工程化的、企业级的。联网搜索是后来演化出来的变体,虽然也算RAG,但底层原理完全不同(一个用向量检索,一个用打分模型)。
4. 企业级RAG的复杂度远超想象
不是建个向量库就完事,文档切割需要人工把控、质量审核、策略设计。切错了会导致长期性的系统错误,甚至业务风险(比如智能客服答错产品信息)。
5. 工具选择要看场景
- 数据量小、一次性任务?直接扔文档就行,简单粗暴。
- 实时信息、公开资料?联网搜索RAG,时效性强。
- 企业级知识库、海量数据?老老实实建向量库,前期投入高但后期省心。
6. 别被名词唬住
“向量检索”、”语义匹配”、”Rerank”听起来都很高大上,但核心就是:怎么从一堆信息里筛出最有用的给AI。理解本质比记名词重要。
RAG不是万能的,也不是唯一的解决方案。关键是理解每种方式的本质,搞清楚哪个是假货、哪个是变体、哪个是真货,然后根据场景选择合适的工具。工具是为了解决问题,不是为了炫技。
本文由 @ChenXiaowu 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


