
 起点课堂会员权益
起点课堂会员权益从「能看」到「懂我」:AI生图的五次需求革命
AI生图技术的进化史,从2014年的GAN到2026年的Seedream 5.0,不仅见证了技术的跃迁,更揭示了人类需求的觉醒——从简单的‘能生图就行’到‘我要好看的’再到‘我要它听我的’。每一次突破,都在重新定义创作的边界。

三个时代,同一个需求
2014 年,蒙特利尔大学的实验室里。研究员小李盯着屏幕上那张模糊的、像素化的人脸图像,激动得手都在抖:“它真的生成了!虽然看起来像马赛克,但这是机器自己‘想象’出来的!”
2022 年 8 月,某广告公司。设计师小王打开 Midjourney,输入“赛博朋克风格的咖啡馆”,30 秒后,一张精美绝伦的概念图出现在 Discord 频道里。她截图发给客户:“这个方向怎么样?”
2026 年 2 月,某电商公司运营部。运营小张对着电脑说:“帮我生成一张春节促销海报,要有舞龙元素,背景是故宫,文字写‘新春好礼 8 折起’,红金配色。”几秒钟后,Seedream 5.0 输出了一张完美契合需求的海报,连字体都工工整整。
同样是“给我画一张图”,十二年间,发生了什么?
这不是一个关于技术进步的故事。这是一个关于需求觉醒的故事——每一次 AI 生图的跃迁,本质上都是人类在重新发现:“原来,我真正想要的是这个。”
「能生图就行」—— 证明可能性的时代
GAN 横空出世:两个神经网络的“互相伤害”
2014 年 6 月 10 日,Ian Goodfellow 在蒙特利尔的一家酒吧里,和几个博士生朋友讨论生成模型。几杯啤酒下肚后,一个疯狂的想法冒了出来:让两个神经网络互相对抗,一个负责造假,一个负责打假,在这种“军备竞赛”中,造假者会越来越逼真。
当晚回家后,Goodfellow 连夜写代码,第二天早上就跑通了第一版 GAN(生成对抗网络)。这个模型的训练方式有点像两个人互相卷——生成器(Generator)拼命学习如何生成逼真的图像,判别器(Discriminator)则拼命学习如何识破假图。最终,当判别器再也分不清真假时,生成器就“毕业”了。
但那时候生成出来的图像是什么样的?用今天的眼光看,简直惨不忍睹:64×64 像素的低分辨率、人脸五官错位、背景一片模糊。但在 2014 年,这已经足够震撼学术圈——机器第一次展现出了“视觉想象力”。
这个产品是给谁用的?
关键问题来了:那时候的 GAN,根本不是一个“产品”。
- 它的用户是谁?研究员。
- 它的使用场景是什么?实验室里的论文实验。
- 它的核心需求是什么?证明“机器能生成图像”这件事在技术上可行。
普通人能用吗?不能。你需要懂 Python、懂深度学习框架、懂如何调参、懂如何搭建训练环境。更要命的是,训练一个 GAN 模型可能需要几天甚至几周,还经常遇到“模式崩溃”(mode collapse)——模型突然只会生成一种图像,怎么调都调不回来。
用一个不太恰当的比喻:2014 年的 GAN 就像莱特兄弟的第一架飞机。它能飞起来,这本身就是奇迹。至于飞得稳不稳、舒不舒服、能不能载客——那是后话。
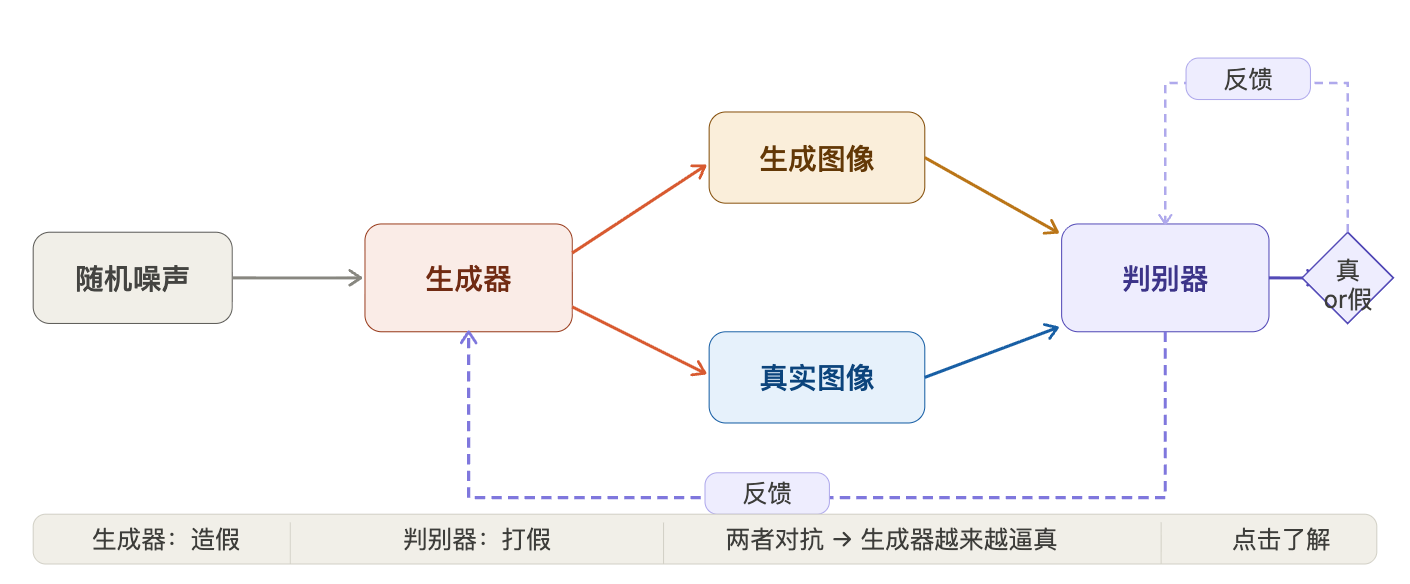
GAN 的对抗训练机制:生成器和判别器在博弈中共同进化
技术的局限,就是需求的边界
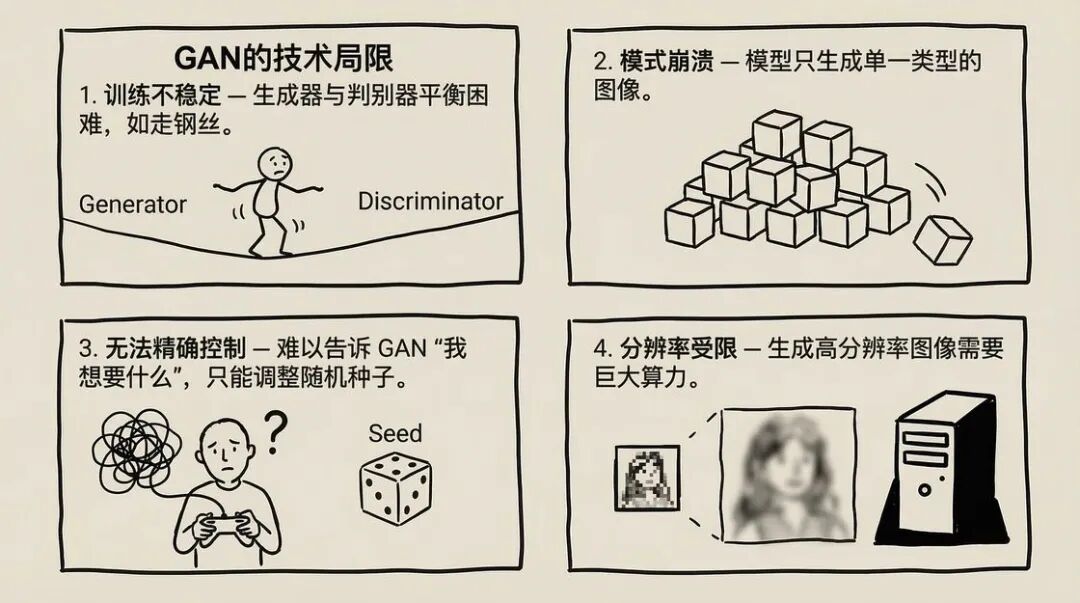
GAN 的问题不只是“难用”,更在于它的技术局限性:
- 训练不稳定—— 生成器和判别器的平衡很难把握,训练过程就像走钢丝
- 模式崩溃—— 模型可能突然“偏科”,只会生成某一类图像
- 无法精确控制—— 你很难告诉 GAN“我想要什么”,只能靠调整随机种子碰运气
- 分辨率受限—— 生成高分辨率图像需要海量算力,当时根本做不到
但这些“缺陷”,在 2014 年并不是问题。因为那时候的需求只有一个:证明 AI 能生成图像。
GAN 做到了。它打开了一扇门,让人们看到:机器不仅能识别图像,还能创造图像。
抛出一个问题:这个产品是给谁用的?
说实话这个问题问住我了。我们日常做产品,嘴上都说”以用户为中心”,但GAN那会儿压根没想过用户是谁。它就是一帮聪明人在自嗨,证明”我能做到”。我觉得这挺像我刚入行时做的第一个产品——功能堆了一堆,但从来没认真想过谁会用、为什么用。
「我要能用它」—— 打破门槛的时代
从实验室到大众:DALL·E 的破圈时刻
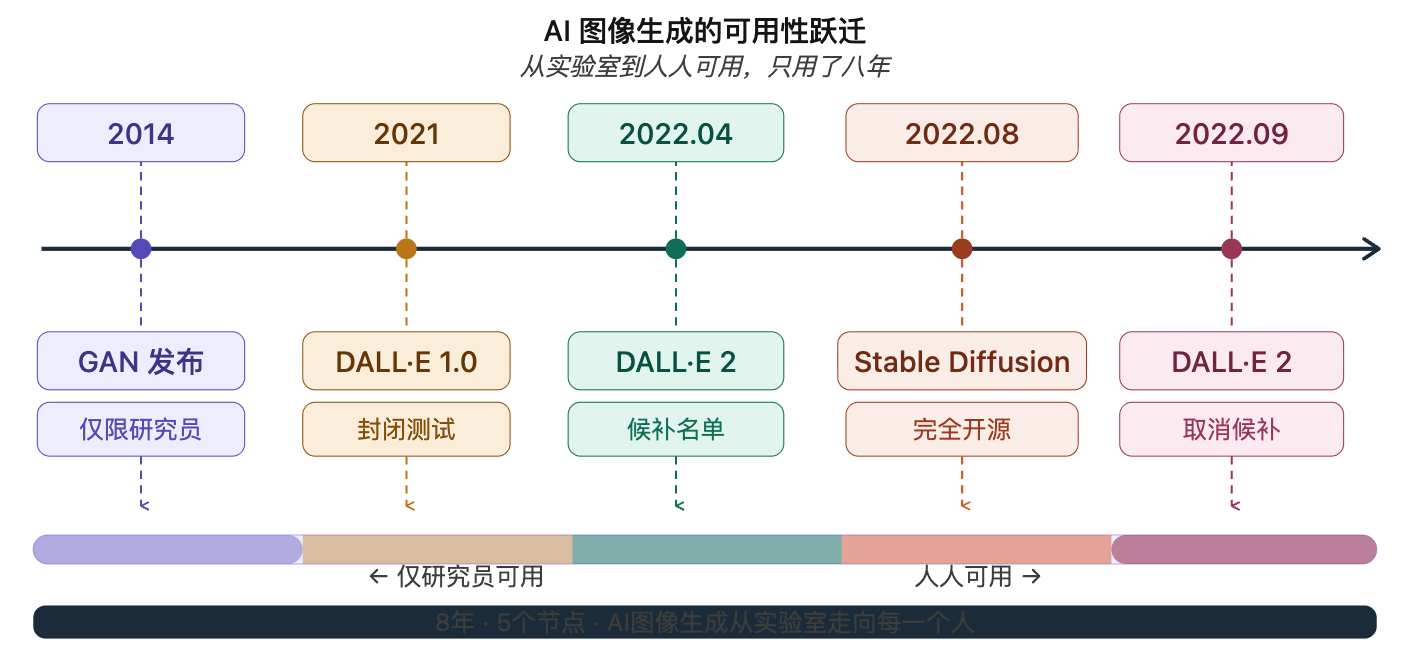
2021 年 1 月 5 日,OpenAI 发布了 DALL·E 1.0。这个名字是达利(Dalí)和瓦力(WALL-E)的组合,暗示着艺术与 AI 的结合。
DALL·E 做了一件在当时看来不可思议的事:你只需要输入一句话,比如“一只穿着芭蕾舞裙的牛油果”,它就能生成对应的图像。
这听起来很简单,但背后的技术跨越是巨大的。DALL·E 基于 GPT-3 的架构,将文本和图像统一编码到同一个“语义空间”里。简单说就是:它学会了把“文字描述”和“视觉画面”关联起来。你说“牛油果”,它知道那是绿色的、梨形的;你说“芭蕾舞裙”,它知道那是蓬松的、白色的。把这两个概念组合在一起,就生成了一个全新的、从未存在过的画面。
但 DALL·E 1.0 有个致命问题:它不对外开放。
OpenAI 只放出了几十个示例图像和一篇论文,普通人根本用不上。这就像在橱窗里展示一辆跑车,但不让你试驾。
Stable Diffusion:开源的“核弹”
真正的转折点发生在 2022 年 8 月。
Stability AI 联合慕尼黑大学和 Runway,发布了 Stable Diffusion——一个完全开源的文生图模型。更关键的是,它可以在消费级显卡(比如 RTX 3060)上运行,不需要昂贵的云服务器。

这意味着什么?任何人都可以在自己的电脑上,免费生成高质量图像。
Stable Diffusion 的发布,就像在 AI 图像生成领域投下了一颗“核弹”。短短几周内,GitHub 上出现了数百个基于它的开源项目:有人做了 Web 界面,有人做了 Photoshop 插件,有人做了 Discord 机器人。整个社区像打了鸡血一样疯狂创新。
到 2022 年 9 月,Stable Diffusion 的 Discord 服务器已经有超过 100 万用户。这个数字在一年后突破了 2000 万。
从封闭到开放:AI 生图的可用性时间线
什么在阻止用户靠近?
回头看,2021-2022 年的核心问题不是“技术不够好”,而是“普通人用不上”。
三道门槛挡住了大众:
- 技术门槛—— 需要懂代码、懂命令行、懂模型部署
- 算力门槛—— 需要高端 GPU,训练或生成一次可能要几小时
- 获取门槛—— 模型不开源,或者需要排队申请内测资格
DALL·E 和 Stable Diffusion 用两种不同的方式解决了这些问题:

DALL·E 的路径:把复杂性藏在云端,用户只需要在网页上输入文字,点击生成,等 30 秒就行。代价是需要付费,每张图 0.02 美元起。
Stable Diffusion 的路径:把模型完全开源,让社区去做各种易用性改造。代价是你需要自己配置环境,或者使用第三方服务。
两条路径,同一个目标:让不懂技术的人也能用上 AI 生图。
到 2022 年底,一个初中生都可以在手机上用 Discord 机器人生成图像了。门槛,被彻底打破。
抛出一个问题:什么在阻止用户靠近?
这个问题我反而觉得,不是在问”你的产品差在哪”,而是在问”用户想靠近,但是什么挡住了他”——这个视角一转,整个思路就不一样了。用户不是不想用,是你没把门开开。
「我要好看的」—— 审美即产品力的时代
Midjourney:一个 11 人团队的奇迹
2022 年 2 月,一个叫 David Holz 的创业者,在 Discord 上悄悄上线了 Midjourney 的公测版本。

那时候,Stable Diffusion 还没发布,DALL·E 2 还在内测。Midjourney 既不是最早的,也不是技术最强的。但它做对了一件事:它生成的图像,真的很美。
不是“技术上很厉害”的那种美,而是“设计师看了会心动”的那种美。光影、构图、色彩、氛围感——Midjourney 的输出就像是一个有审美品味的艺术家在创作,而不是一个冷冰冰的算法在计算。
更神奇的是,Midjourney 的团队只有 11 个全职员工。没有融资,没有大厂背景,没有顶级论文。但到 2023 年,它的年收入突破了 3 亿美元,Discord 服务器有 2100 万用户,成为 Discord 上最大的服务器。
这是怎么做到的?
社区即产品:Discord 上的“蜂巢思维”
Midjourney 的成功,很大程度上归功于它选择了 Discord 作为主战场。
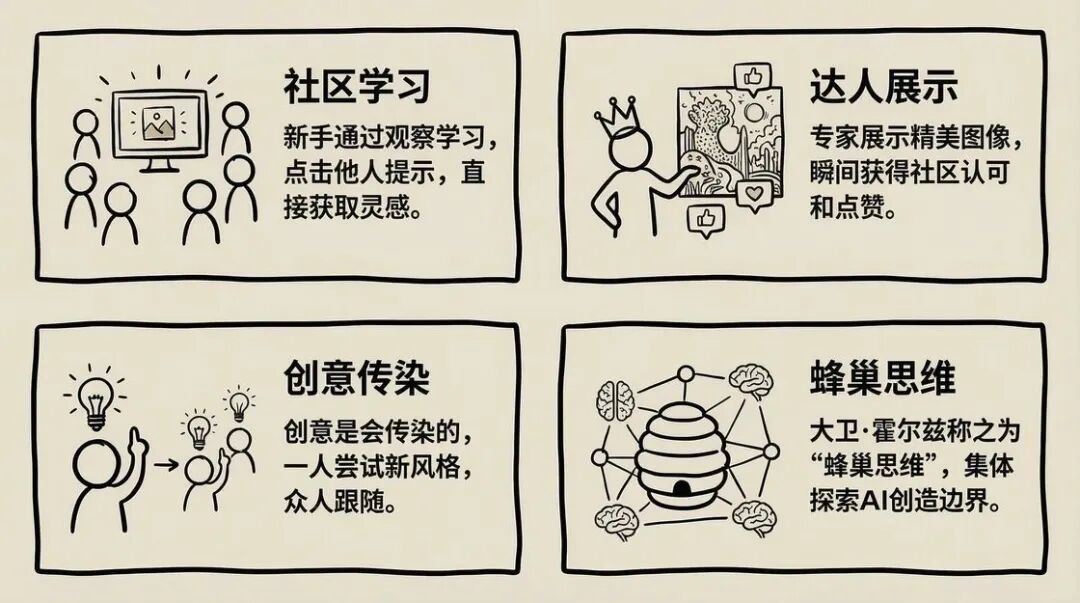
在 Discord 上,所有用户的生成过程都是公开的。你输入一个提示词,30 秒后,图像就出现在频道里,所有人都能看到。这创造了一种独特的“社区学习”氛围:
- 新手可以偷师—— 看到一张好图,点开就能看到别人用的提示词,直接学习
- 高手可以炫技—— 生成一张惊艳的图,立刻获得社区的认可和点赞
- 创意会传染—— 一个人尝试了“蒸汽波风格”,很快就有十个人跟着尝试
David Holz 把这种现象称为“蜂巢思维”(hive mind)——2100 万用户不是在各自为战,而是在集体探索 AI 的创作边界。
Midjourney 还做了一个聪明的设计:它不提供 API,不做网页版(早期),只做 Discord 机器人。
这看起来很“反直觉”——为什么不做一个漂亮的官网,让用户在网页上生成呢?
因为 Discord 本身就是一个社交平台。用户在这里不只是“用工具”,更是“参与社区”。他们会在频道里讨论技巧、分享作品、互相点评。这种社交属性,让 Midjourney 从一个“工具”变成了一个“创作者社区”。
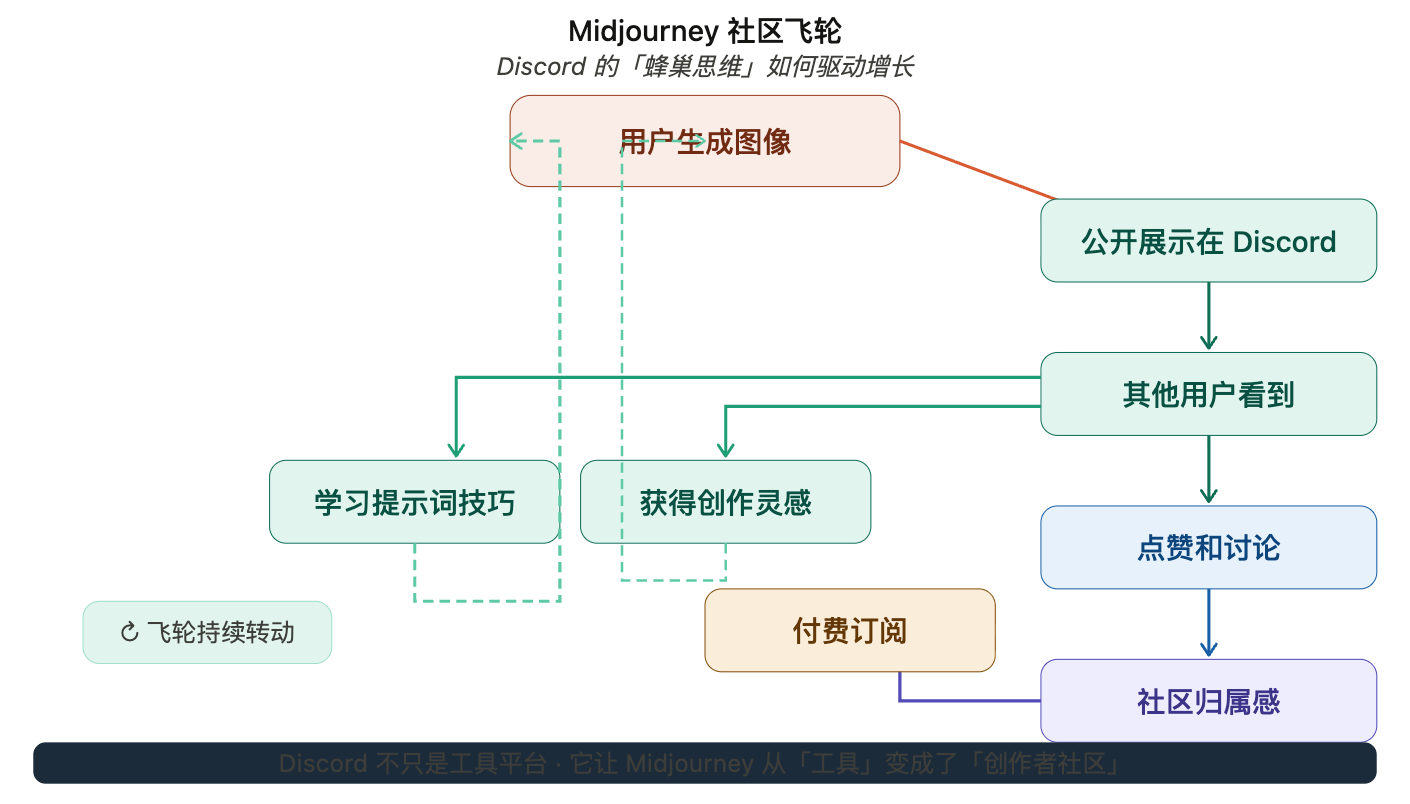
Midjourney 的社区飞轮:从工具到社区的转变
审美,才是真正的护城河
到 2023 年,市面上已经有十几个 AI 生图工具了。技术上,它们的差距并不大——都是基于扩散模型,都能生成高分辨率图像,都支持文生图和图生图。
但 Midjourney 依然是设计师和创作者的首选。为什么?
因为它的输出,有“审美”。
这听起来很玄学,但确实存在。同样的提示词,Midjourney 生成的图像往往更有“电影感”、更有“艺术性”。这不是偶然,而是团队有意为之的结果:
- 训练数据的筛选—— Midjourney 在训练时,更注重高质量的艺术作品和摄影作品
- 默认风格的调优—— 模型的默认输出偏向“视觉冲击力强”的风格
- 持续的迭代—— 从 V1 到 V7,每次更新都在优化光影、构图、细节
2023 年,一位设计师在 Twitter 上说:“我用 Stable Diffusion 做草图,用 Midjourney 做最终交付。因为客户看 Midjourney 的图会说‘哇’,看 Stable Diffusion 的图会说‘哦’。”
这就是审美的价值。在技术同质化的时代,审美成为了最难复制的竞争力。
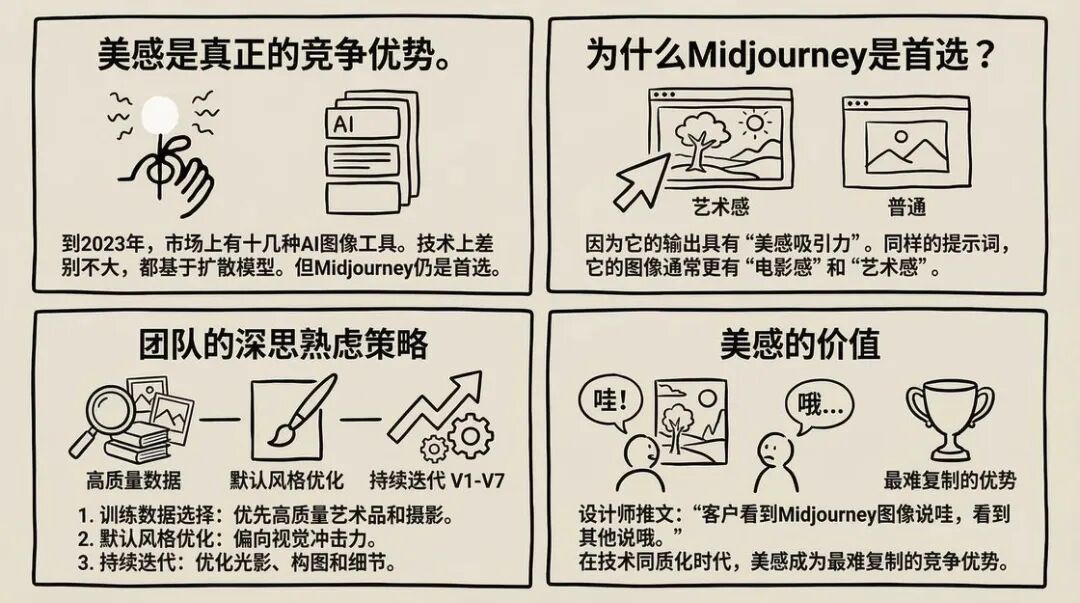
用户为什么愿意付费留下来?
Midjourney 的订阅制定价很有意思:
- 基础版8美元/月,每月 200 张图
- 标准版24 美元/月,无限生成(Relax 模式)
- 专业版48美元/月,更快的生成速度
这个定价不算便宜。Stable Diffusion 是免费的,DALL·E 按张计费也更灵活。但 Midjourney 的付费用户依然超过了 100 万。
他们为什么愿意付费?
不是因为功能,而是因为体验:
- 审美保证—— 生成的图像质量稳定,不需要反复调试
- 社区归属—— 在 Discord 上找到了一群志同道合的创作者
- 持续进化—— 每隔几个月就有大版本更新,能明显感受到进步
一个产品经理朋友跟我说:“Midjourney 的成功,证明了一个道理——在 AI 时代,工具的‘好用’不只是功能强大,更是‘用起来爽’。”
抛出一个问题:用户为什么愿意付费留下来?
Midjourney这个案例真的让我有点羞愧。一个11人团队,没有融资,靠的就是”用起来爽”。反观很多大厂产品,人多钱多,但用户留不住。我现在越来越觉得,功能是门槛,体验才是粘性。
「我要它听我的」—— 精准控制的时代
DALL·E 3:终于能写字了
2023 年 10 月,OpenAI 发布了 DALL·E 3。

发布会上,演示了一个让所有设计师尖叫的功能:它终于能在图像里准确渲染文字了。
这听起来不算什么大事,但在此之前,几乎所有 AI 生图工具都有一个共同的“智障”表现——你让它生成一张写着“OPEN”的门牌,它可能给你生成“OEPN”、“0PEN”或者一堆乱码。
为什么 AI 生图这么难处理文字?因为传统的扩散模型是在“像素空间”里学习的,它把文字当成一种“纹理”来生成,而不是理解文字的语义。就像一个不识字的人临摹书法,能模仿笔画的形状,但很容易写错。
DALL·E 3 的突破在于:它用了一个全新的“图像描述系统”。
在训练时,OpenAI 没有直接用网上爬来的图像标注(那些标注往往很粗糙,比如“一只猫”),而是用 GPT-4 给每张图像生成了详细的、长达几百字的描述。这些描述不仅包括画面内容,还包括构图、光影、情绪、甚至文字内容。
结果就是:DALL·E 3 不仅“看得懂”你的提示词,还能“理解”你想要什么样的画面。
GPT-4o:图像生成的“原生化”
2024 年 5 月,OpenAI 发布了 GPT-4o(o 代表 omni,全能)。这是一个真正的多模态模型——它可以同时处理文本、图像、音频,并且这些能力是“原生”的,不是后来拼接上去的。
到 2025 年 3 月,GPT-4o 的图像生成能力正式上线。这次的升级不是“更快”或“更清晰”,而是更听话。
举个例子:
以前(DALL·E 3):
你:“生成一张海报,左上角是 logo,右下角是二维码,中间是产品图,背景是渐变蓝。”
AI:给你生成了一张图,logo 在右上角,二维码不见了,背景是纯蓝色。
现在(GPT-4o):
你:“生成一张海报,左上角是 logo,右下角是二维码,中间是产品图,背景是渐变蓝。”
AI:完全按照你的要求生成,连渐变的方向都是对的。
更神奇的是,GPT-4o 可以“对话式生成”。你生成一张图后,可以说:“把 logo 放大一点”,“把背景改成暖色调”,“加一行文字‘限时优惠’”——它会在原图的基础上精确修改,而不是重新生成一张完全不同的图。
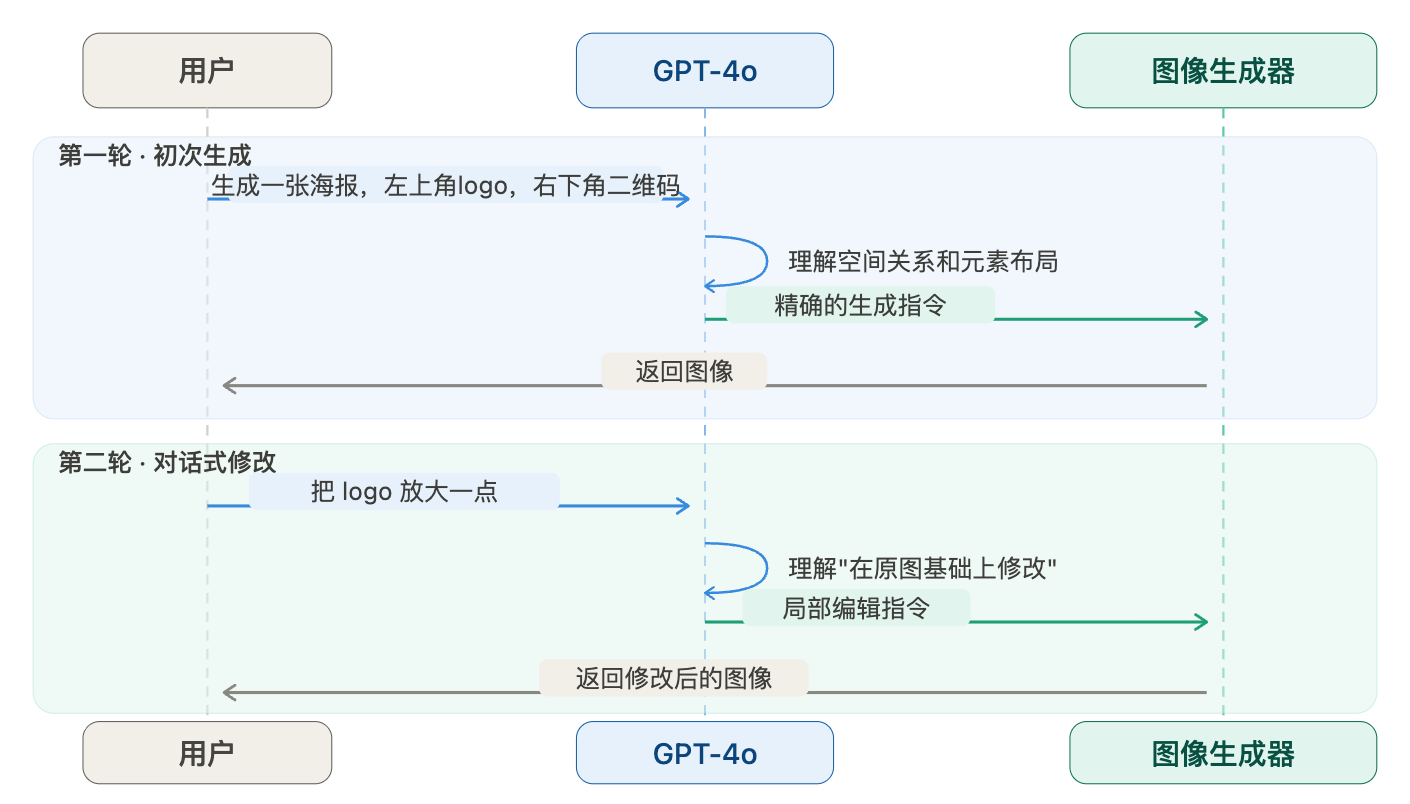
GPT-4o 的对话式图像生成:从“一次性交付”到“迭代式创作”
提示词工程:从“碰运气”到“精准控制”
2022 年,AI 生图圈子里流行一个词:提示词工程(Prompt Engineering)。
那时候,想生成一张好图,你需要掌握各种“咒语”:
- 想要高质量?加上“masterpiece, best quality, highly detailed”
- 想要特定风格?加上“by Greg Rutkowski, trending on ArtStation”
- 想要特定构图?加上“rule of thirds, golden ratio, cinematic lighting”
这些“咒语”是社区通过大量实验总结出来的经验。就像玩 RPG 游戏,你需要研究攻略、背诵技能组合,才能打出高伤害。
但到了 2024 年,这套玩法开始失效了。
DALL·E 3 和 GPT-4o 的出现,让“提示词工程”从“碰运气的艺术”变成了“说人话就行”。你不需要背咒语,不需要堆砌关键词,只需要用自然语言描述你想要什么,AI 就能理解。
这背后的技术原理是:AI 不再只是“匹配关键词”,而是“理解语义”。
举个对比:
2022 年的提示词:
“A cat, sitting on a chair, in a room, with a window, sunlight, warm lighting, cozy atmosphere, highly detailed, 4k, trending on ArtStation”
2024 年的提示词:
“一只猫坐在椅子上晒太阳,房间很温馨”
后者更短,但生成效果更好。因为 GPT-4o 能理解“晒太阳”意味着有阳光、有窗户,“温馨”意味着暖色调、柔和的光线。
用户真正想说的那句话是什么?
这个问题,在 2024 年终于有了答案:用户想说的,就是他们用自然语言说出来的那句话。
AI 的进步,不是让用户学会“怎么跟 AI 说话”,而是让 AI 学会“听懂人话”。
抛出一个问题:用户真正想说的那句话是什么?
我们做需求访谈,用户说的和想要的,永远不是同一件事。用户说”我要更快的马”,想要的是”到达目的地”。AI花了十年学会听人话,我们做产品的,有时候连用户说的话都还没听懂。
「我要它懂我的世界」—— 本土化与实时性的时代
Seedream 5.0:联网的 AI,懂中文的 AI

2026 年 2 月,字节跳动发布了 Seedream 5.0 Preview。
这次更新,有三个关键词:联网、推理、本土化。
联网,意味着 AI 可以实时检索最新信息。你让它生成“2026 年春节联欢晚会的舞台设计”,它会先去搜索今年春晚的实际舞台照片,然后基于真实素材进行创作。这解决了一个长期困扰 AI 生图的问题——时效性。
以前,AI 的训练数据都是“过去式”的。它知道 2023 年的流行元素,但不知道 2026 年的。现在,通过联网检索,AI 可以跟上时代。
推理,意味着 AI 不再只是“照着提示词画”,而是能“理解你的意图”。
举个例子:
你:“生成一套电商产品的营销海报”
Seedream 5.0:理解到“一套”意味着需要多张图,自动生成主 KV、详情页 banner、朋友圈分享图,三种尺寸,风格统一。
这种“推理能力”,让 AI 从“执行工具”变成了“创意助手”。
本土化,是 Seedream 最大的优势。
作为一个中国团队开发的模型,Seedream 对中文语义、中国文化、中国审美的理解,远超国外模型。你说“国潮风”,它知道你要的是什么;你说“赛博朋克+中国风”,它能生成霓虹灯下的古建筑,而不是不伦不类的拼贴。
更关键的是,Seedream 在文字渲染上做了专门优化。中文字体、书法、印章、对联——这些在西方模型里经常出错的元素,Seedream 处理得游刃有余。
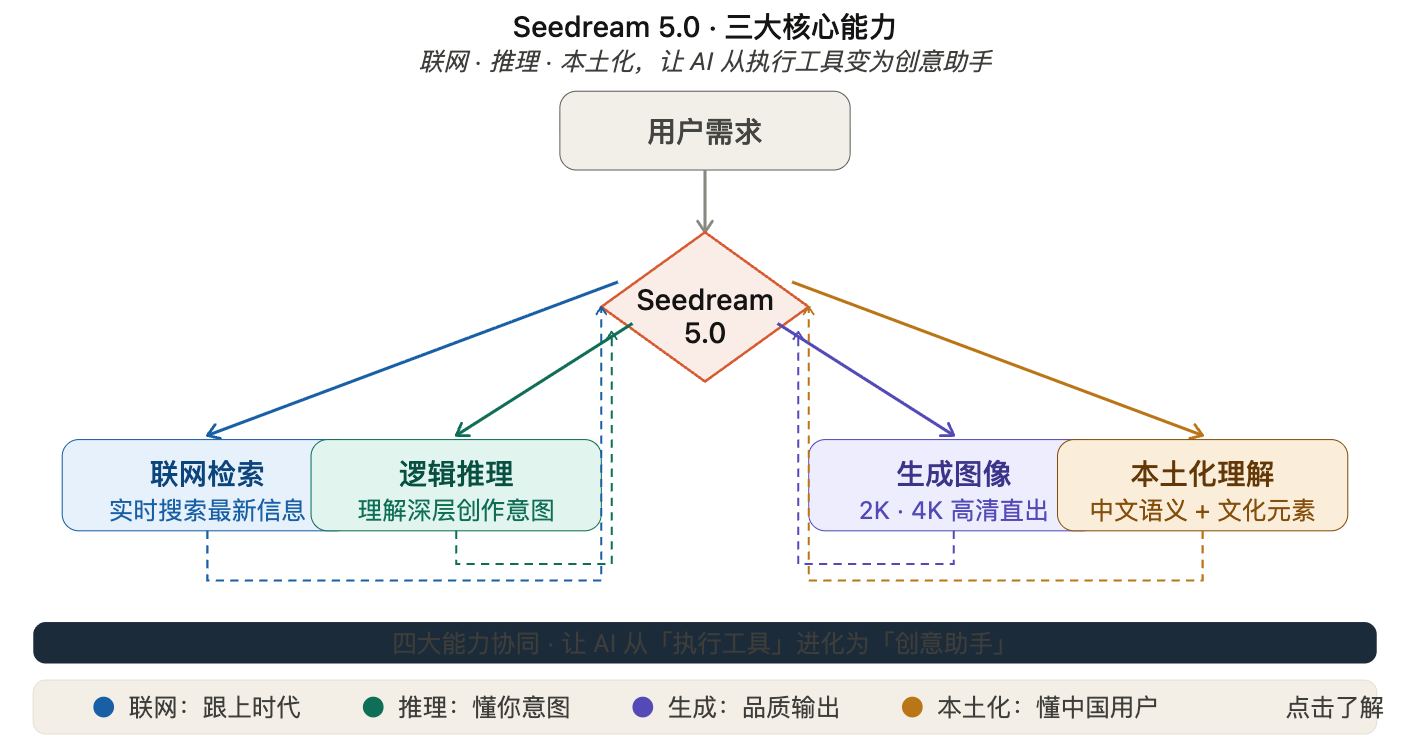
Seedream 5.0 的三大能力:联网、推理、本土化
国产 AI 图像模型的“春秋战国”
Seedream 不是孤例。2025-2026 年,国产 AI 图像模型进入了“春秋战国”时代:
- 腾讯混元图像 3.0—— 在 LMArena 全球盲测中登顶,偏好率 47%
- 阿里通义万相—— 主打电商场景,商品图生成质量行业领先
- 百度文心一格—— 与百度搜索深度整合,支持“搜索+生图”一体化
- 快手可图—— 专注短视频封面生成,理解“爆款”逻辑
这些国产模型有一个共同特点:垂直场景的深度优化。
不像国外模型追求“通用性”,国产模型更关注“在特定场景下做到最好”。电商运营用通义万相,短视频创作者用可图,设计师用混元,各取所需。
这背后反映的是需求的进一步细分:用户不再满足于“能生图”,而是要“在我的场景里好用”。
听话之后,下一个需求在哪里?
2026 年的 AI 生图,已经可以做到:
- 听懂自然语言
- 精确渲染文字
- 理解空间关系
- 实时联网检索
- 适配本土文化
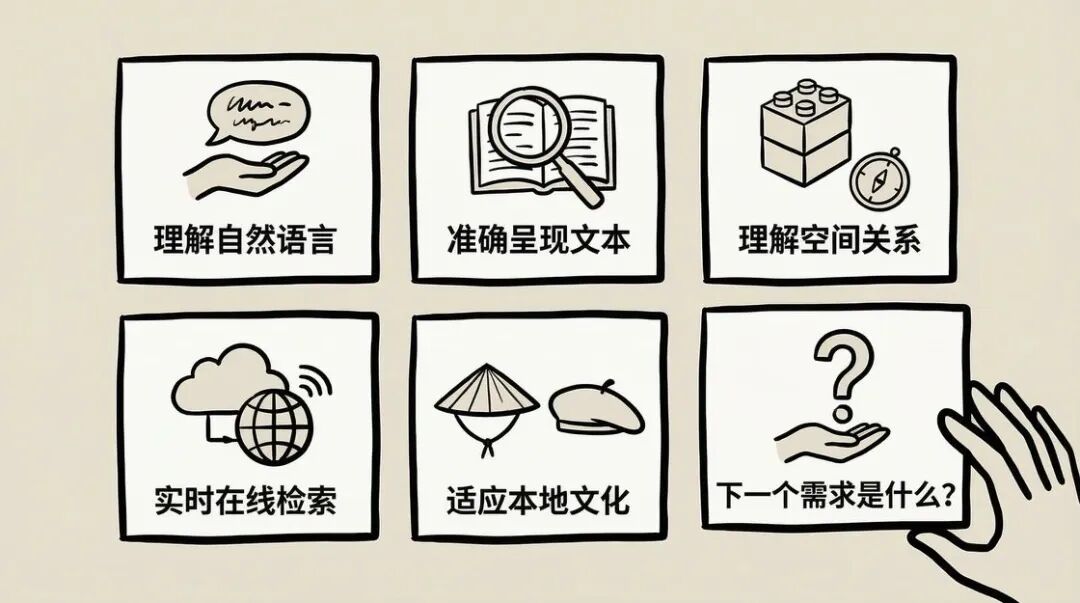
那么,下一个需求是什么?
从 Seedream 5.0 的用户反馈来看,答案开始浮现:
- 个性化—— “我希望 AI 记住我的审美偏好,不用每次都重新描述”
- 协同性—— “我希望 AI 能和我‘一起’创作,而不是‘帮我’创作”
- 情感化—— “我希望 AI 理解我的情绪,生成的图像能传达我的感受”
这些需求,已经不再是“工具”层面的,而是“关系”层面的。
抛出一个问题:听话之后,下一个需求在哪里?
我脑子里第一个念头是——其实用户自己也不知道。下一个需求往往不是被”说”出来的,是被”触发”出来的。就像没人说”我需要Instagram”,但iPhone相机一出来,那个需求就被点燃了。所以与其去问用户,不如去观察他们在什么时候感到”差一点点”。
终章:第六次革命在哪里?
站在 2026 年,回望 AI 生图的十二年,我们见证了五次需求革命:
- 能生图就行—— 证明可能性
- 我要能用它—— 打破门槛
- 我要好看的—— 审美即产品力
- 我要它听我的—— 精准控制
- 我要它懂我的世界—— 本土化与实时性
那么,第六次革命会是什么?
我不知道答案。但我有三个猜想,分享给你。
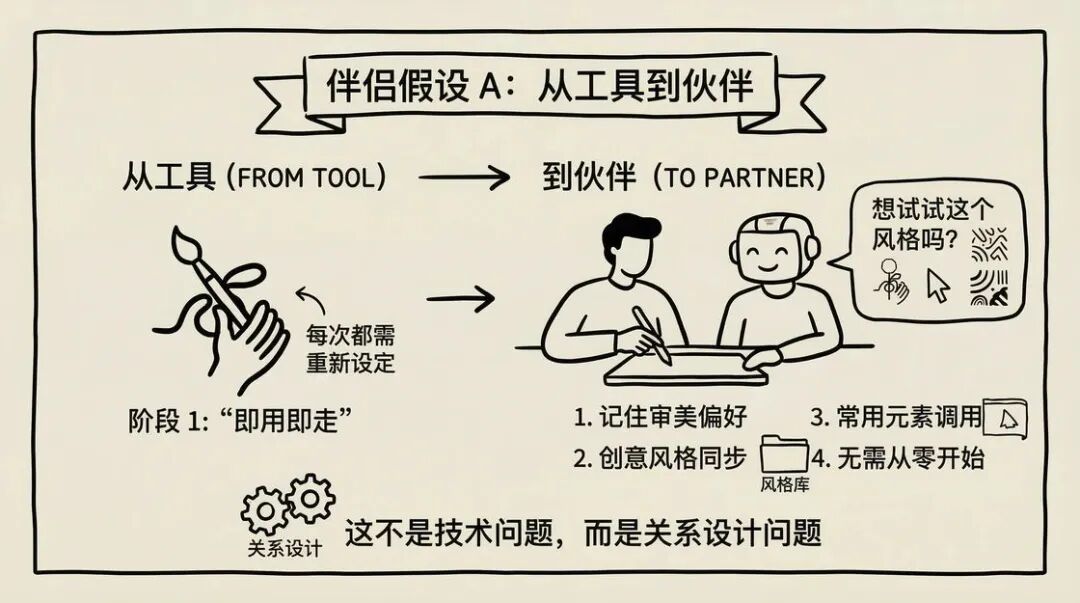
猜想 A:陪伴感 —— 从工具到伙伴
也许未来的 AI 生图工具,不再是一个“用完就走”的工具,而是一个“长期陪伴”的创作伙伴。
它会记住你的审美偏好、你的创作风格、你的常用元素。你不需要每次都从零开始描述,它会主动说:“要不要试试这个风格?我觉得挺适合你的。”
就像一个老搭档,你们之间有默契,有共同语言。
这不是技术问题,而是关系设计的问题。
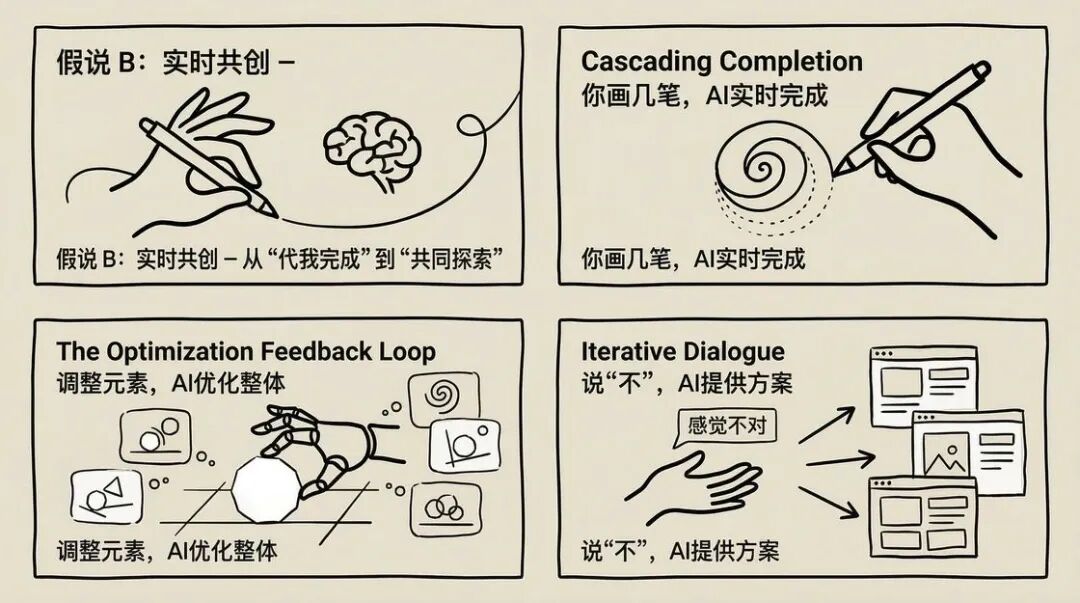
猜想 B:实时共创 —— 从「帮我做」到「一起做」
也许未来的 AI 生图,不再是“你下指令,它执行”,而是“你们一起探索”。
你在画布上随手画几笔,AI 实时补全;你调整一个元素,AI 自动优化整体构图;你说“这里感觉不对”, AI 给出三个改进方案让你选。
这种“实时共创”的体验,会让创作过程本身变得更有趣。
这不是生成速度的问题,而是交互范式的问题。
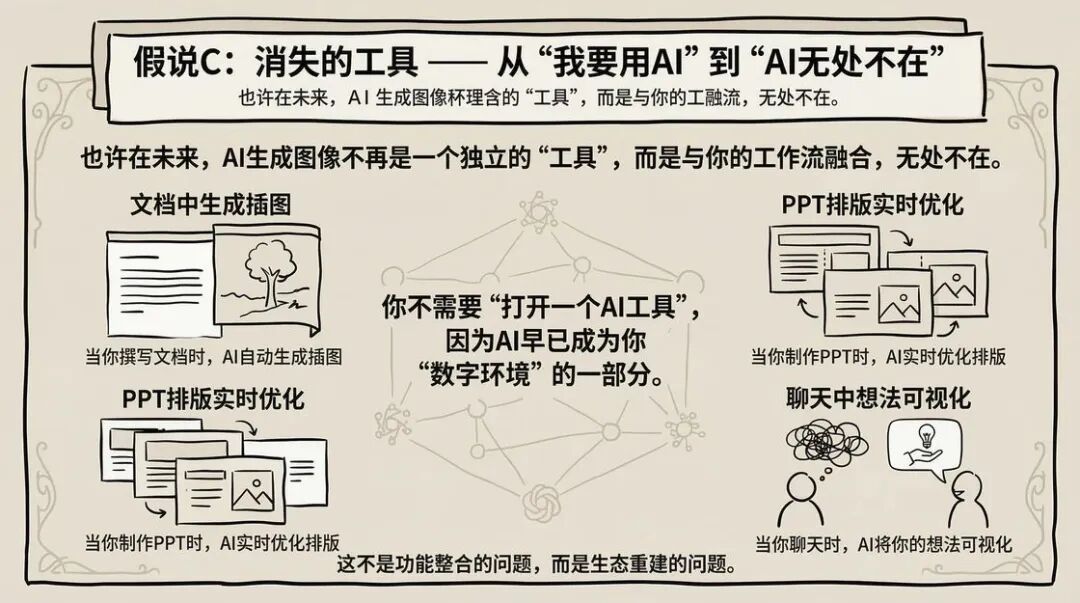
猜想 C:消失的工具 —— 从「我去用 AI」到「AI 一直在」
也许未来的 AI 生图,不再是一个独立的“工具”,而是融入你的工作流,无处不在。
你在写文档,AI 自动生成配图;你在做 PPT, AI 实时优化版式;你在聊天,AI 把你的想法可视化。
你不需要“打开 AI 工具”,因为 AI 已经成为你的“数字环境”的一部分。
这不是功能集成的问题,而是生态重构的问题。
结尾:我们在 AI 中看见的,是自己
每一次 AI 生图的需求升级,本质上都是人类在问自己:「我到底想要什么?」
- 2014 年,我们想要的是“证明机器能创造”;
- 2022 年,我们想要的是“让普通人也能用”;
- 2023 年,我们想要的是“生成的图像要美”;
- 2024 年,我们想要的是“AI 要听懂我的话”;
- 2026 年,我们想要的是“AI 要懂我的世界”。
但这些需求,真的是 AI 给我们的吗?
不是。
是 AI 像一面镜子,让我们看清了自己真正的需求。
我们以为自己想要的是“更强的工具”,但其实想要的是“更好的体验”;
我们以为自己想要的是“更多的功能”,但其实想要的是“更懂我的伙伴”;
我们以为自己想要的是“更快的生成”,但其实想要的是“更有意义的创作过程”。
不是 AI 越来越懂我们,而是我们借助 AI,越来越清楚地看见自己。
这才是 AI 生图这十二年,最大的价值。
本文由 @AGI审判官 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Pixabay,基于CC0协议






- 目前还没评论,等你发挥!


