
 起点课堂会员权益
起点课堂会员权益AI 产品经理今年最重要的能力,可能不是原型,而是“评测体系设计”
AI产品的评测体系正在成为产品经理的核心战场。微软Copilot的实践揭示了一个关键转向:从功能交付转向质量管控。文章深度剖析AI产品特有的评测挑战,提出4层评测框架,并指出未来产品经理的核心能力将从功能设计转向质量系统构建。掌握这套方法论,才能确保你的AI产品不只是能跑,还能在复杂场景中稳定可靠。

过去做产品,很多团队习惯先把功能做出来,再靠灰度、反馈和运营兜底。但到了 AI 产品,尤其是 Agent 产品,这套方法正在失效。模型会变、提示词会变、知识库会变、工具调用会变,权限边界还会跟着角色变化。真正决定产品能不能上线的,不再只是交互和原型,而是你有没有能力把“什么叫好、什么叫稳、什么叫可控”提前定义出来。
先看两个时间点。
2026 年 2 月 3 日,微软在官方 Copilot Blog 专门写了一篇文章讲怎么评测 AI agents。
2026 年 3 月 18 日,微软公布 Copilot Studio 2026 release wave 1 时,又把 support for evaluations 和治理能力一起放进了产品主叙事里,而这轮生产部署从 2026 年 4 月 1 日 已经开始。
这不是一个小信号。
它说明企业 AI 产品的竞争,正在从“谁先把 Agent 做出来”,转向“谁先把 Agent 管起来、测起来、迭代起来”。而这件事,恰恰落在 AI 产品经理身上。
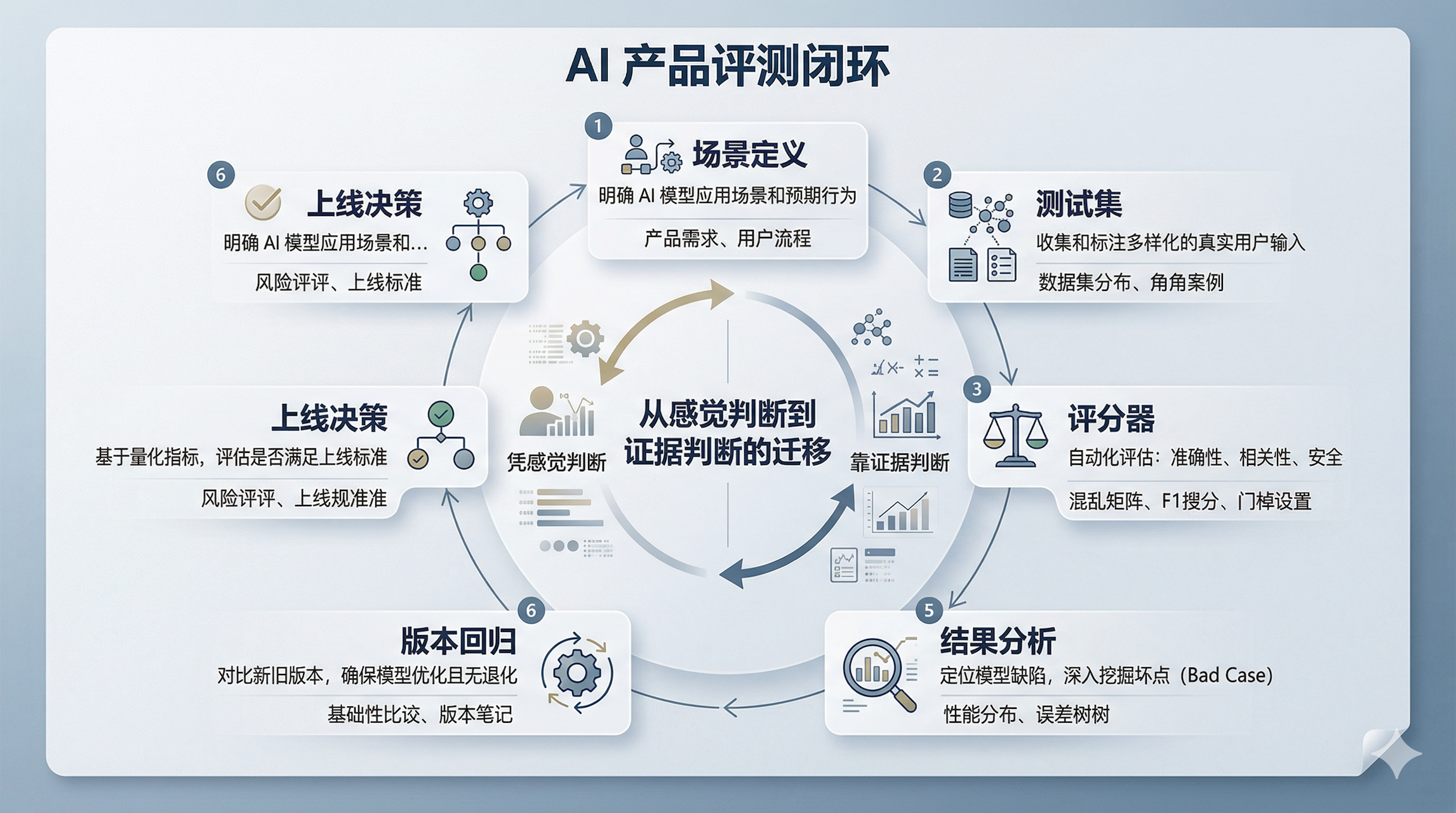
01 为什么说,评测正在变成 AI 产品经理的主战场?
很多团队现在还把评测理解成测试同学或算法同学的事,这个判断已经过时了。
因为 AI 产品的问题,越来越不像传统软件问题。
以前一个按钮错了、一个接口挂了、一个字段映射错了,问题是确定的。
现在你做一个 AI 助手、一个客服 Agent、一个企业知识问答系统,问题常常不是“能不能运行”,而是“在不同上下文下,它会不会做错事”。
- 同样一个问题,用户换个说法,结果可能就不一样。
- 同一个流程,知识库更新一次,回答质量可能就变了。
- 同一个工具调用,管理员和普通员工看到的结果还不一样。
所以 AI 产品真正难的,不是做出一个 Demo,而是回答这三个问题:
- 这东西在真实场景里到底好不好用?
- 它在哪些场景会失控?
- 每次更新之后,它是变好了,还是悄悄退步了?
这三个问题,单靠原型能力解决不了,必须靠评测体系解决。
02 传统产品指标,为什么不够用了?
很多 AI 产品刚上线时,最容易犯一个错,就是还在拿传统互联网指标做第一判断。
比如看点击率、留存、会话时长、满意度。
这些指标当然有价值,但它们更像结果层指标,不足以帮你判断 AI 为什么好,或者为什么坏。
AI 产品最麻烦的地方在于,它的失败经常是“局部失败”。
整体 DAU 看起来没问题,但关键场景错了一次,用户信任就会掉。
满意度平均分不低,但某一类高价值任务老是失败,业务价值就起不来。
换句话说,AI 产品经理不能只看“用户有没有来”,还要看“它到底有没有正确完成任务”。
这也是为什么微软在官方评测文章里反复强调,评测不是一次性的 debug,也不是几条 prompt 试好了就算,而是一个持续的、可重复的质量机制。
真正值得关注的是,AI 产品的质量,不能只靠主观感觉。
它必须被拆成可以观察、可以比较、可以解释的信号。
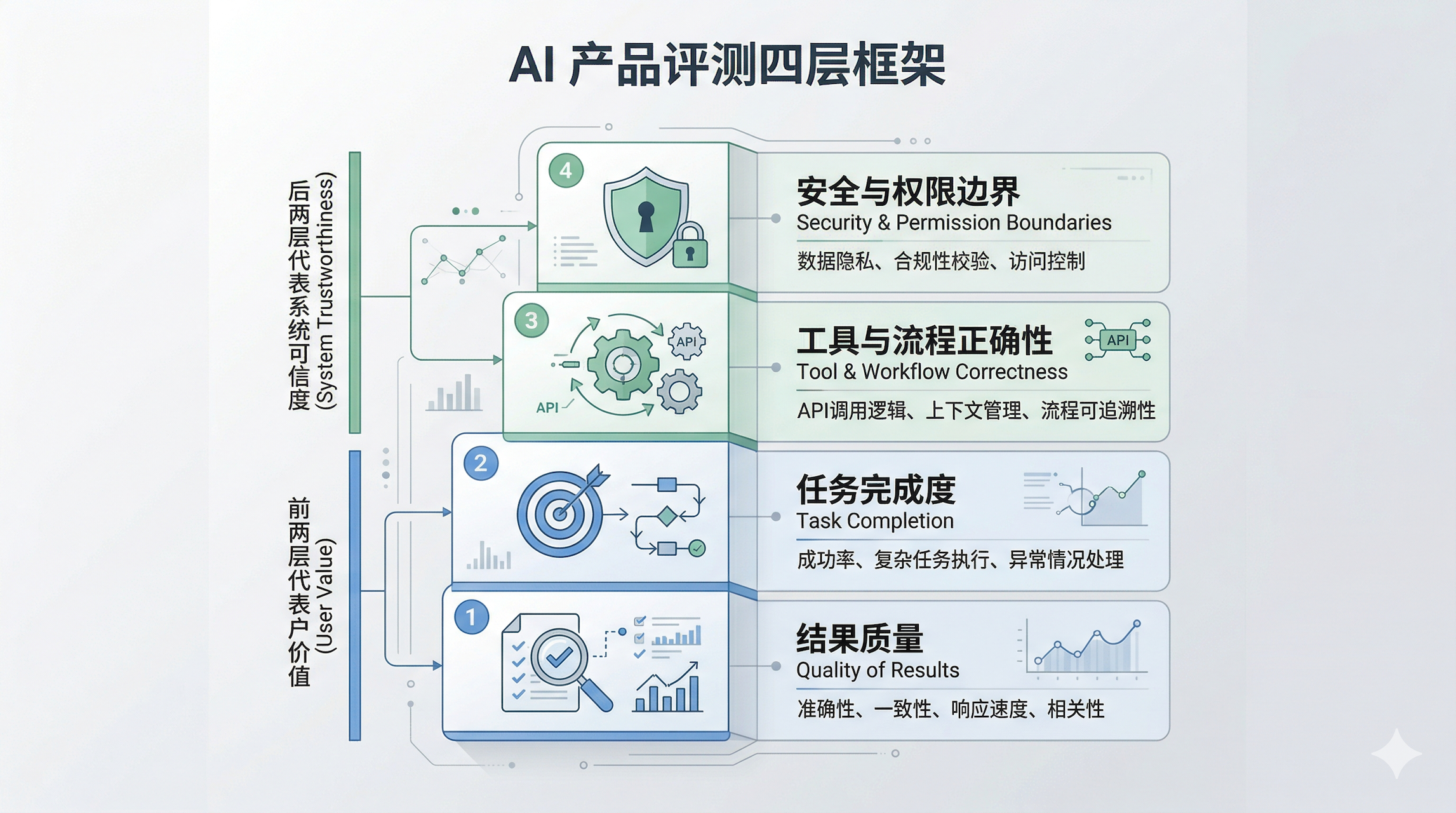
03 AI 产品经理,至少要搭好这 4 层评测框架
如果让我把这件事收敛成一个最实用的方法,我会建议 AI 产品经理至少搭这 4 层。
第一层,结果质量。
回答有没有解决问题,是否完整、准确、清楚,这是最基础的一层。
第二层,任务完成度。
不是只看它“答得像不像”,而是看它有没有把任务真正做完。比如有没有正确生成摘要、有没有把表单填完、有没有把用户带到下一步动作。
第三层,工具与流程正确性。
Agent 产品最关键的常常不是语言,而是调用。它是否调用了正确工具,调用顺序对不对,该升级人工时有没有升级,该停下时有没有停下。
第四层,安全与权限边界。
这是企业 AI 最容易被低估的一层。不同身份拿到的知识、可触发的动作、可见的数据本来就不一样。如果评测时不带身份上下文,很多“高分”其实都是假高分。
这 4 层里,前两层更像用户价值,后两层更像系统可信度。
AI 产品经理真正要做的,就是把这两部分同时拉住。
04 一套好的评测,不是从指标开始,而是从场景开始
很多人一上来就问:我要看哪些分数?
但更准确的问题应该是:我到底在测什么场景?
微软在官方评测流程里,第一步不是先选模型,也不是先看报表,而是先定义 scenario 和 scope。这个顺序很重要。
因为 AI 产品的评测,最怕“测得很全,但和真实使用没关系”。
真正有效的做法是:
先找高价值场景。
比如“员工问报销政策”“销售查客户信息”“运营生成活动初稿”“客服判断是否该转人工”。
再补真实表达。
不要只写标准问法,要把模糊表达、混合意图、半截问题都放进去。
然后给每类场景定义成功标准。
什么叫答对?什么叫做到位?什么叫必须升级?什么叫宁可拒答也不能乱答?
做到这一步,评测才不是“拿 AI 试试”,而是在验证一个具体业务能力。
所以从产品经理视角看,测试集不是技术附件,而是需求定义的一部分。
你怎么设计测试集,基本就决定了你最后会把产品做成什么样。
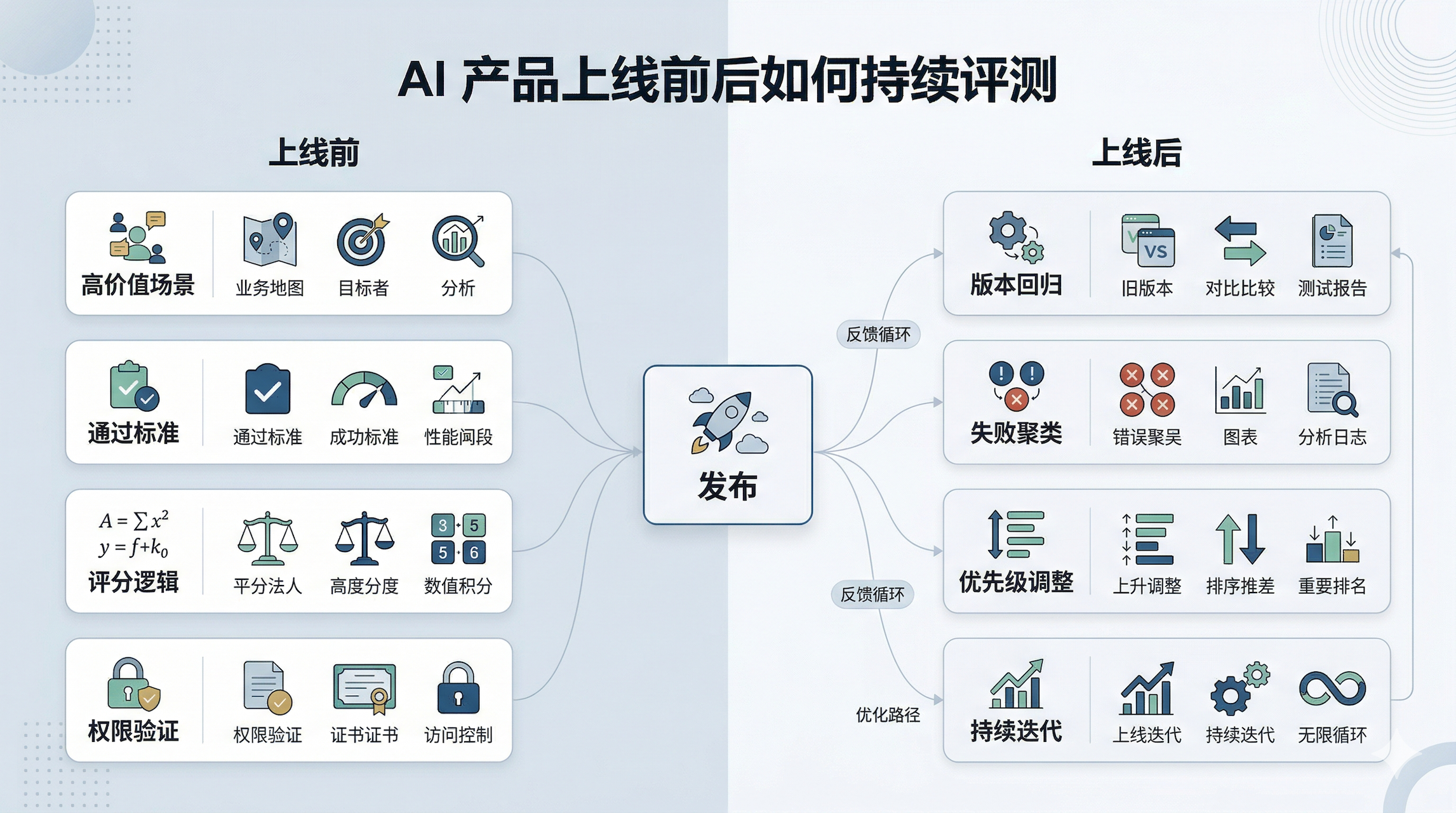
05 AI 产品经理上线前后,分别该做什么?
很多团队把评测放到上线前临时补,这会很被动。
更稳妥的方式,是把评测拆成上线前和上线后两段动作。
上线前,你至少要做 4 件事:
- 选出 20 到 50 个高价值真实场景,先做最小测试集。
- 为每个场景定义通过标准,而不是只看“像不像正确答案”。
- 至少配置 3 类评分逻辑:质量、能力、工具/流程。
- 用不同身份去跑一次,验证权限和知识边界。
上线后,还要继续做 3 件事:
- 每次改提示词、模型、知识库或工具后,都跑回归。
- 不只看平均分,更要看失败是否集中在某一类高风险场景。
- 把评测结果接到迭代优先级,而不是做成一份没人看的周报。
这里有一个特别重要的判断:不是所有失败都同样重要,模式 比 个案 更重要。
如果一个低频场景偶发失误,未必是头号问题。
但如果所有“需要升级人工”的场景都没升级,那就是结构性问题,优先级必须拉满。
06 未来一年,AI 产品经理最稀缺的能力,会越来越像“质量负责人”
为什么我会说,AI 产品经理该补的不是更多原型技巧,而是评测体系设计?
因为原型解决的是“你想做什么”,评测解决的是“你做出来的东西,到底能不能承担真实业务”。
前者决定产品起点,后者决定产品生死。
尤其到了 Agent 时代,产品经理不再只是定义页面、流程和按钮,还要定义:
- 什么叫成功
- 什么叫失败
- 失败后该怎么收口
- 哪些风险可以接受
- 哪些风险必须阻断上线
这其实已经不是一个单纯的“功能设计”角色,而更像是一个“AI 质量设计者”。
一句话总结就是:AI 产品经理的竞争力,正在从做功能,转向做可信的能力系统。
如果你的团队现在已经在做 AI 助手、知识问答、自动化 Agent 或企业 Copilot,我会建议你先别急着再加功能。
先问一句更关键的话:你们有没有一套在每次更新后,都能证明自己“确实变好了”的评测体系?
如果没有,这很可能才是当前最该补的产品能力。
本文由 @AIGC土豆 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自作者提供






- 目前还没评论,等你发挥!


