起点课堂会员权益
起点课堂会员权益约束越多,AI 越自由:Harness Engineering
当AI编程工具在任务中途宣布「完成」时,多数人的第一反应是「模型不够强」。但真相恰恰相反——问题出在系统设计而非算法本身。本文通过真实案例揭示Harness Engineering如何通过约束、验证与反馈机制,让同一AI模型的效能提升25%,并深度拆解这套驾驭AI「野马」的现代缰绳体系。
先说一件让我有点尴尬的事
前段时间我在用一个 AI 编程工具做一个功能迭代,任务不算复杂,就是把几个模块串联起来,做一个数据处理的流程。我把需求描述得详细,觉得这次 AI 肯定能一把搞定
然后它就开始写了,写得相对流畅,代码一行一行往外蹦,我坐在旁边看着还挺爽的,感觉效率起飞了
大概二十分钟后,它停下来,跟我说:任务完成
我点开一看,好家伙,前半部分写得挺好,后半部分接口对不上,有个核心函数根本没实现,测试一个都没跑,然后它就这么宣布完成了
我当时第一反应是:这个模型不行,得换个更好的
这个想法,现在回头看,是完全错误的
其实这不是模型的问题
这个认知转变对我来说花了挺长时间,因为”换更好的模型”这个直觉实在太根深蒂固了
我用 AI 工具,形成了一个固定的思维模式:效果不好,就是模型不够强,等下一代模型出来就好了。逻辑在早期是有一定道理的,模型能力确实是最主要的变量
2026 年,这个情况就不一样了
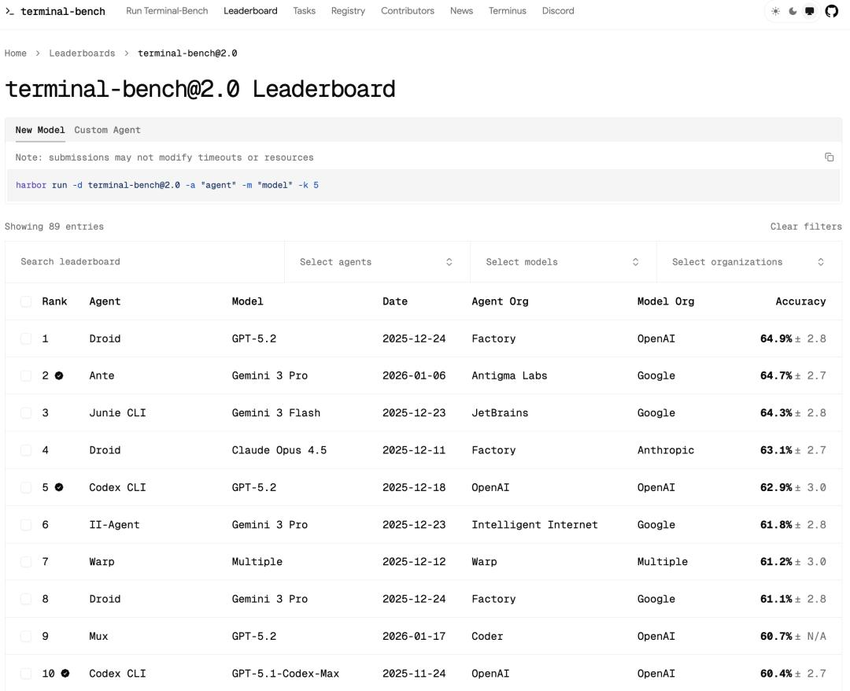
有个团队拿同一个模型以Terminal Bench 2.0 的基准测试上跑了两次,唯一的区别是第二次改了模型外面那套系统——约束、验证流程、反馈机制这些。结果,分数从 52.8% 跳到了 66.5%,全球排名从三十名开外直接进了前五,这个实验数据让我印象巨深。模型一个参数都没变
这件事让我重新思考了一个问题:花了这么多时间盯着模型本身,是不是搞错了方向
我踩过的典型错误
在讲 Harness Engineering 具体怎么做之前,先说说我自己踩过的坑,因为这几个错误真的很典型,相信不少人都有过
第一个错误:把所有指令塞进一个大文件
我之前的习惯是维护一个长篇的 AI 指令文档,把所有规范、注意事项、约定全部写进去,觉得这样 AI 就能”记住”所有东西了
结果是,这个文档越来越长,越来越难维护,AI 开始不知道哪条是真正重要的,而且这个大文件会占掉大量上下文窗口,把真正有用的任务信息挤出去, 当所有事情都被标注为“重要”的时候,就等于什么都不重要
实际上就是把那个大文件改成一张地图,只有一百行左右,每行都是指向更深层文档的指针。AI 从地图出发,按需深入,而不是被一本百科全书淹没
第二个错误:觉得约束会限制 AI 的创造力
我们担心给 AI 套太多规则,会让它变成一个只会按图索骥的执行机器,失去灵活性
但实际情况是反过来的。当 AI 面对一个完全开放的解空间(Solution Space),它会浪费大量计算资源在死胡同里徘徊,每个方向、可能性都试一试,最后给你一个看起来很全面但“范”的结果
当你给它明确的边界,它反而能更快收敛到正确的解决方案。边界不是笼子,边界是跑道
第三个错误:AI 说完成了就以为真的完成了
这个我已经吃过亏了。AI 有一个很根深蒂固的倾向,就是在任务看起来差不多完成的时候就停下来,然后报告完成
AI不会主动去跑测试、验证功能、检查边界情况。因为没有人告诉它必须这样做
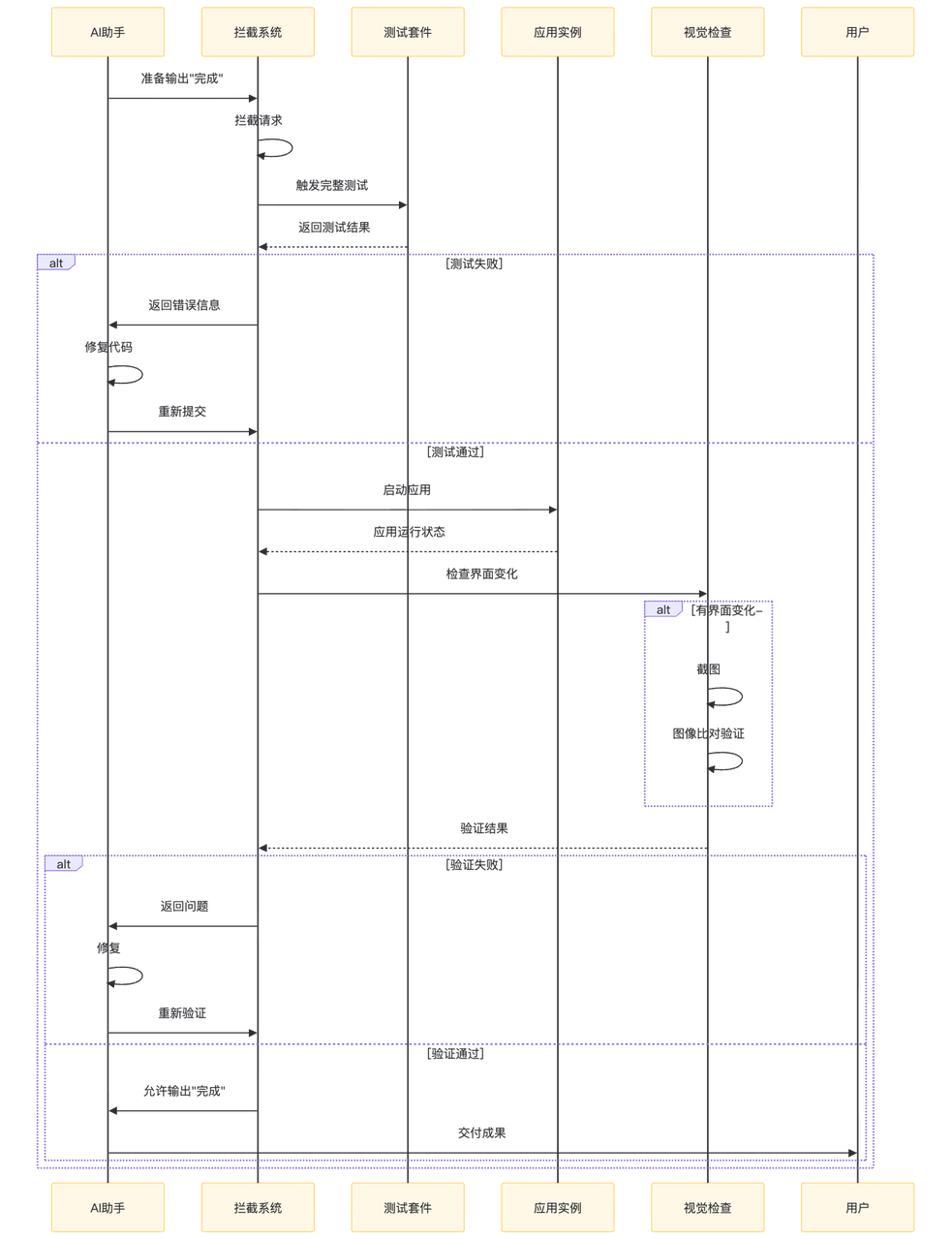
我在做 OpenClaw 的时候,就是围绕这个问题专门设计了一套执行逻辑:先框定边界,再进行执行。也就是说,在 AI 开始干活之前,先把”什么叫完成”定义清楚,把验证条件写进去,靠系统强制
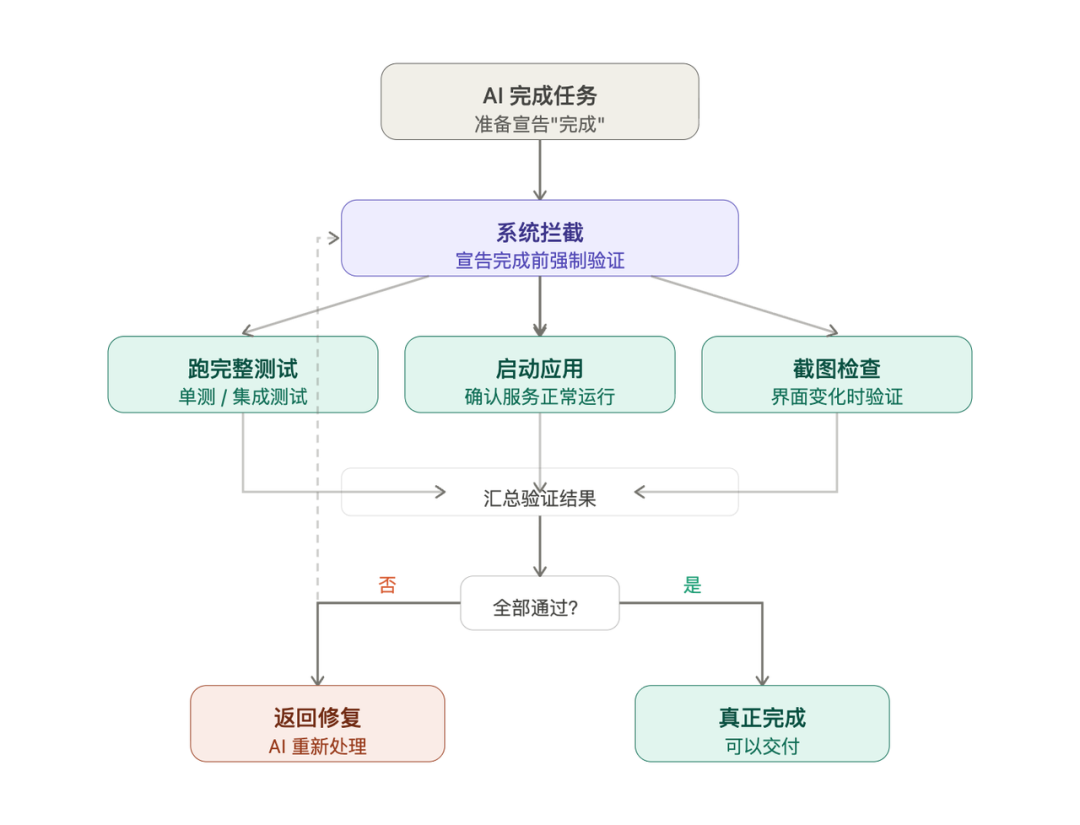
后来我的做法是:需要在系统里强制规定,在 AI 宣告任务完成之前,必须跑完整的验证流程。不验证,不允许退出
什么是 Harness Engineering
我第一次听说 Harness Engineering 的时候,大概是今年二月,朋友发给我一篇文章 Harness engineering: leveraging Codex in an agent-first world ,说有个团队用 AI 写了一百万行代码,全程零人工

吹牛吧这是(我的第一反应)
然后我把文章仔细看了一遍,发现不是吹牛,是真的。三个工程师,五个月,一百万行代码,交付了一个真实产品,有真实用户在用,能正常发布、部署、出 bug、被修复,全部由 AI 在那套系统里完成,效率大概是传统人工的十倍
但我注意到一个细节,文章里说,工程师不写代码之后,80% 的时间花在了什么上?
不是写 Prompt,不是审代码,是构建那套围绕 AI 的约束系统
这个细节让我停下来想了一段时间,这套系统,就叫 Harness
它不是一个工具,不是一个框架,更不是一个 Prompt 模板。它是一套围绕 AI Agent 运行的系统,包括约束、反馈、验证和持续清理这几个部分。2026 年初,这套做法有了一个正式的名字:Harness Engineering。
“Harness”这个词来自马具——缰绳、马鞍、嚼子,那一整套用来驾驭马的装备。AI 模型就像一匹蛮力十足但方向感不太行的马,跑得快,但容易跑偏。Harness 的作用,就是把它的力气引到正确方向上。
Harness Engineering 的核心部分
这套系统大概有四个核心部分。
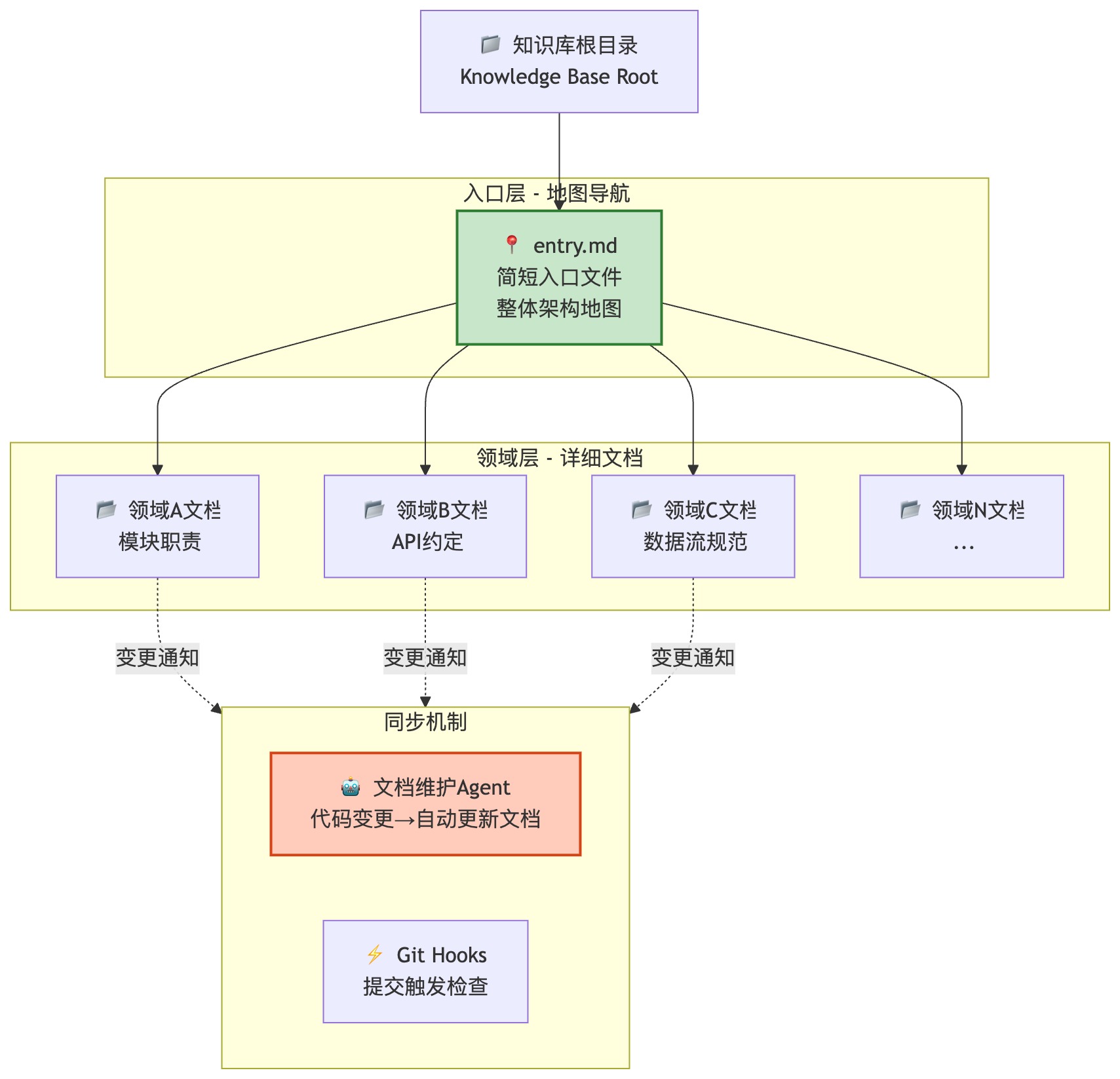
第一是知识系统
AI 要在一个复杂项目里干活,它得知道整体架构是什么、各模块的职责是什么、API 约定是什么。这些信息不是靠一个大文件给它,而是靠一套分层的文档结构。一个简短的入口文件作为地图,指向各个领域的详细文档,AI 按需取用。更关键的是,这套文档要跟代码保持同步,代码变了,文档跟着变,甚至可以专门跑一个”文档维护 Agent”来做这件事。
第二是架构约束
你要把架构规则写成机器可执行的检查,而不是靠人记、靠 Code Review 来维护。比如你规定模块之间的依赖方向是单向的,这条规则不是写在文档里的,是写成了自动检查规则,任何违反的代码都过不了流程,无论是人写的还是 AI 写的。更聪明的做法是,把错误信息写得很详细,不只说”你违反了规则 X”,而是解释”为什么这个规则存在、正确的做法是什么”。这样 AI 遇到错误的时候,能自己理解为什么错了,然后自己修正。
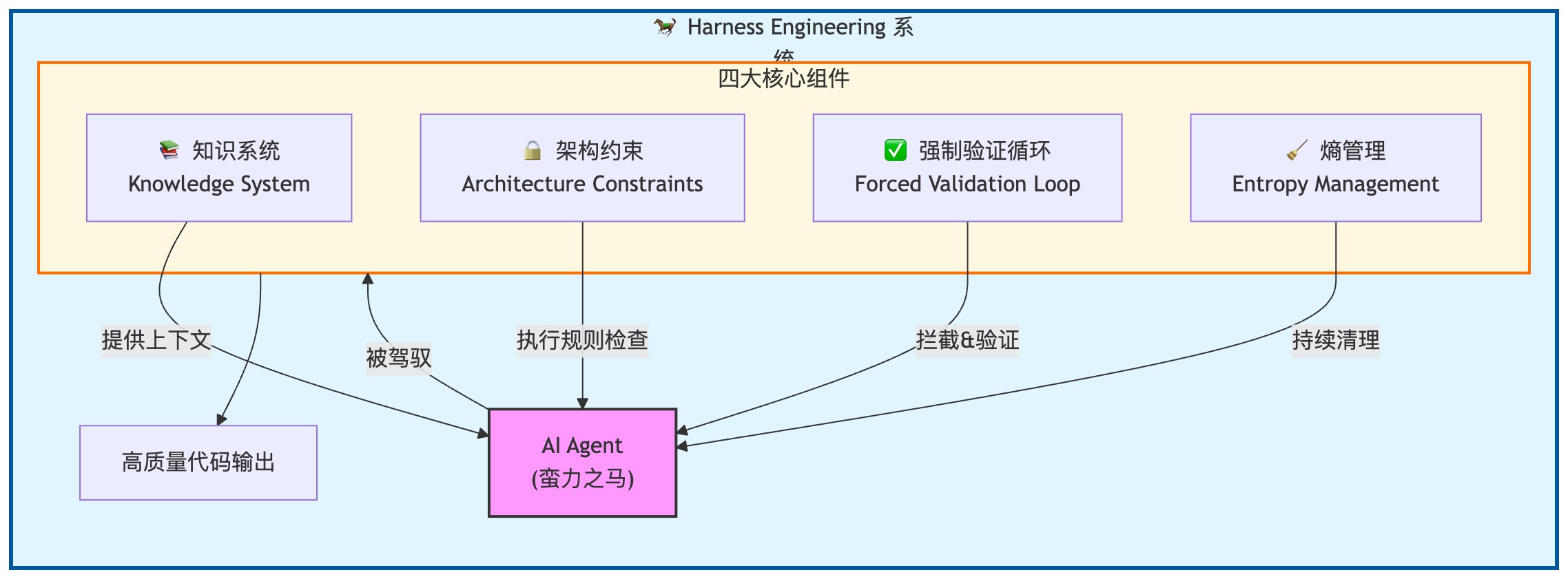
第三是强制验证循环
在 AI 准备说”完成”之前,系统拦截它,要求它跑完整的验证——测试要跑,应用要启动,如果有界面变化,要截图检查。就是这一个改动,让前面提到的那个团队基准测试分数从 52.8% 跳到了 66.5%。
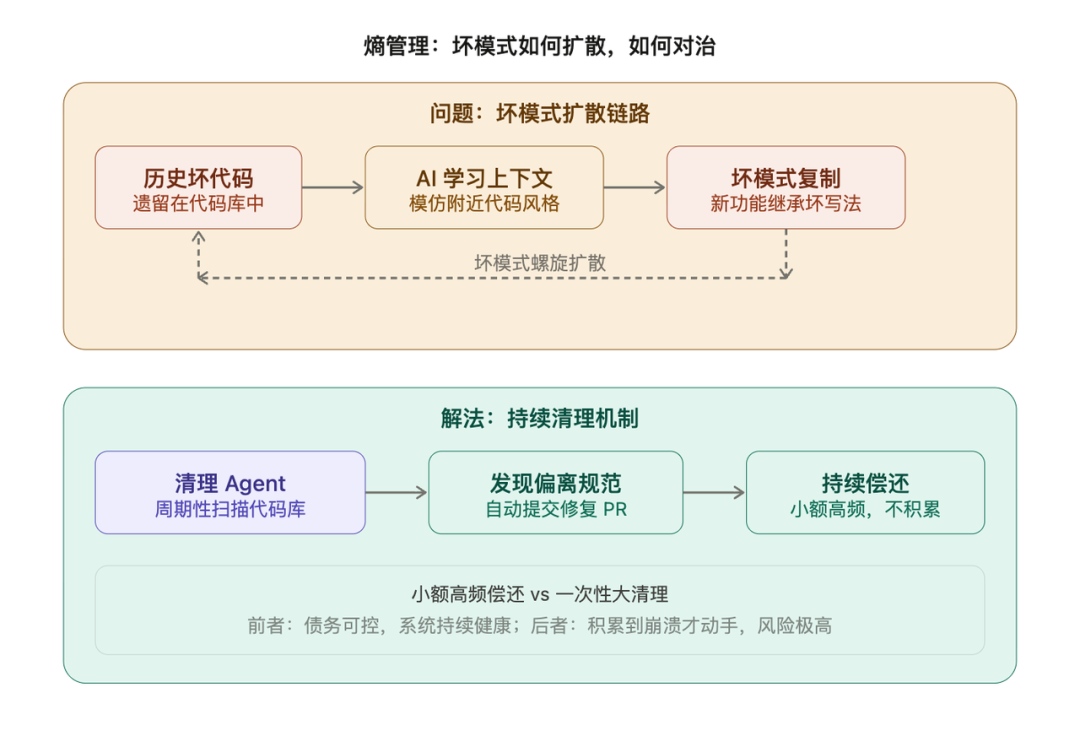
第四是熵管理
AI 生成代码的时候,有一个很坏的习惯,就是复现代码库里已有的模式,包括坏的模式。如果你的代码库里有一段写得很烂的代码,AI 在旁边写新功能的时候,可能会模仿那种写法,然后坏的模式就扩散了。解法是建立一套定期运行的清理机制,后台有专门的 Agent 周期性扫描代码库,找到偏离规范的地方,自动提交修复。技术债务不要等积累到崩溃才还,小额高频持续偿还,效果比一次性大清理好得多。
Harness Engineering 是不是终极解法
不是。
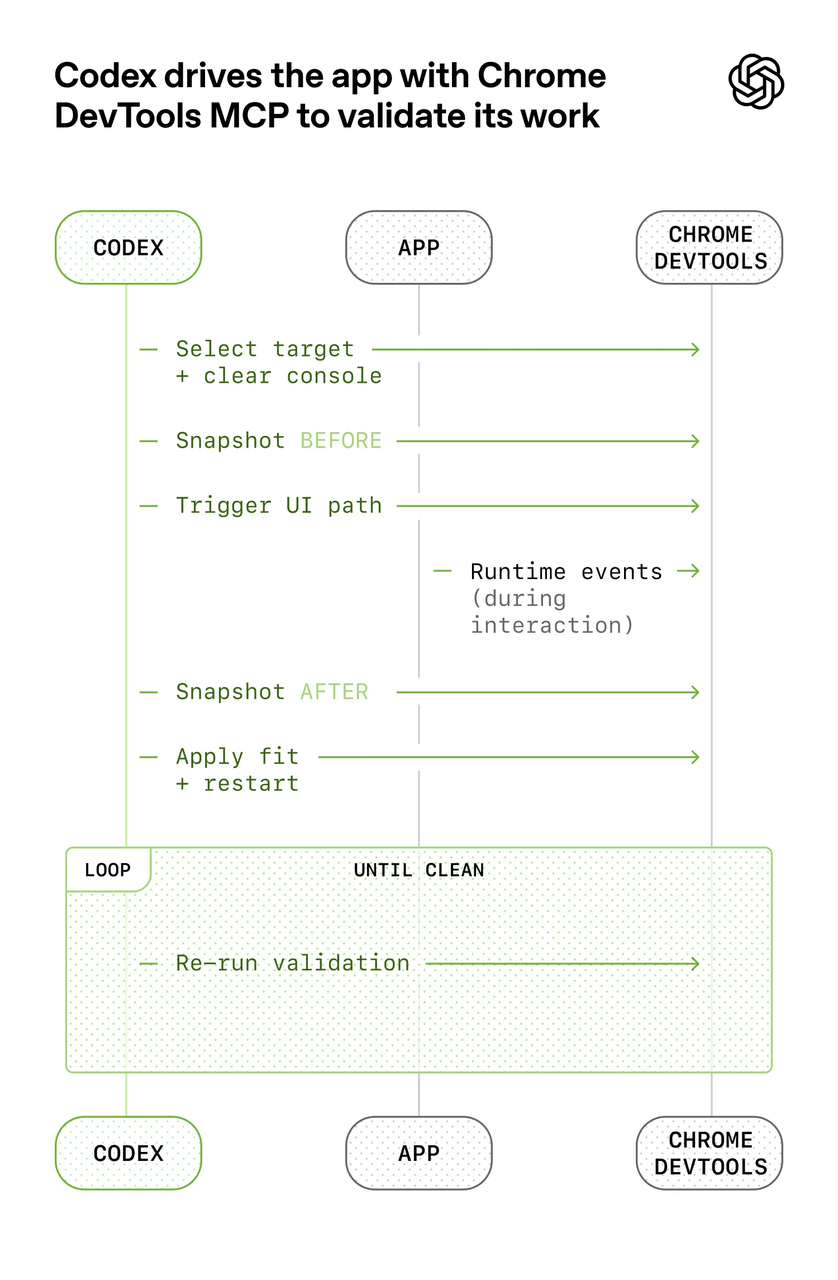
做了对比实验:没有 Harness 的情况下,AI 写得很快,但大概每隔几个功能就会出现一次架构偏移,模块之间的依赖开始乱,文档和代码开始脱节,测试覆盖率开始下降,工程师每周五要花 20% 的时间专门清理这些问题。有了 Harness 之后,AI 的单次任务速度稍微慢一点,因为要跑验证,但架构偏移几乎消失了,文档保持同步,测试覆盖率稳定,工程师不再需要专门的清理时间。
但 Harness 也有它的边界。它对”可验证的任务”效果最好——代码能跑、测试能过、结果能量化。对于那些需要主观判断的任务,比如内容质量、用户体验,Harness 能给你结构,但给不了你答案。
所以更准确的说法是:Harness Engineering 是一个让 AI 在复杂系统里长期可靠运行的前提条件,而不是让 AI 变得更聪明的方法。它解决的是”怎么让 AI 不乱跑”,不是”怎么让 AI 跑得更快”。
回到最开始的问题
回到最开始那件让我尴尬的事,如果当时我有一套 Harness,那件事会怎么发生?
AI 还是会开始写代码。但在它准备说”任务完成”之前,系统会拦截它,要求它跑测试、检查接口、验证核心函数是否实现。它会发现后半部分的问题,然后自己去修。它不会在任务没完成的时候宣布完成,因为系统不允许。
这就是”约束越多,AI 越自由”的意思。不是说约束让 AI 变得更聪明,而是约束让 AI 的聪明用在了正确的地方,不会浪费在无效的徘徊和虚假的完成上。
如何开始实践
如果你现在想开始做点什么,不需要一上来就搭一套完整的 Harness,可以从两件小事开始:
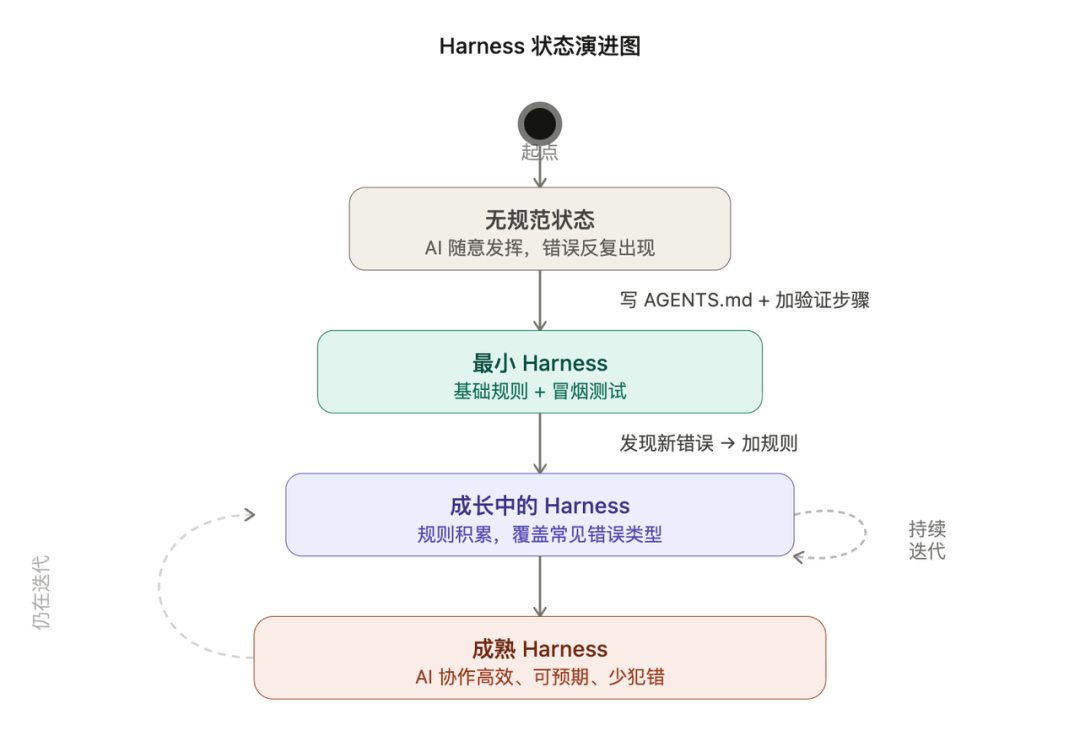
最小可行的起点就是两件事:
- 给你的项目写一个 AGENTS.md ,把你希望 AI 遵守的规则写进去,不用长,一百行以内,每一行对应一个你希望 AI 不要再犯的错误;
- 在你的工作流里加一个验证步骤,任何任务在宣告完成之前,必须跑验证,哪怕只是最基本的冒烟测试。
从这两件事开始,每次 AI 犯一个新类型的错误,就回头加一条规则。Harness 不是一次性设计好的,它是一点一点长出来的。不需要多复杂,但会让你用 AI 做事情的效果明显不一样
AI 已经是千里马了,这一点毋庸置疑。但千里马没有缰绳,跑得再快也到不了目的地
Harness Engineering 就是这个时代最重要的缰绳,不是用来束缚它,是用来让它的力量真正被用到正确的方向上
本文由 @炸毛疯兔 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自用户提供






- 目前还没评论,等你发挥!