
 起点课堂会员权益
起点课堂会员权益Xiaomi MiMo 全模型测评报告
本报告综合整合以下数据来源:公开技术文档、Artificial Analysis Intelligence Index v4.0、HuggingFace Model Card、BuildFastWithAI 独立评测、morphllm.com SWE-bench Pro 排行榜、pricepertoken.com 定价数据,以及个人真实测评。所有数据均注明来源,厂商自建榜单数据已标注可信度。本报告仅为个人观点。

关键洞察
洞察一:MiMo 是「Agent 性价比」最优解,但不是全能旗舰
MiMo-V2.5-Pro 以3(输入/输出每百万 token)的定价,在 SWE-bench Pro 上得分57.2%(Xiaomi 官方宣布,经 Binance/NS3.AI 转载核实),达到 GPT-5.4(57.7%)的 99%,却仅需约 1/5 的成本 。但在通识深度推理(MMLU-Pro 68.5% vs DS V4-Pro 87.5%)和科学推理(GPQA-Diamond 66.7% vs Qwen 3.5 的 88.4%)上,差距超过 20 个百分点 。
MiMo 是专项冠军,不是全科第一,选型需对齐具体任务类型。
可信度:★★★★ | SWE-bench Pro 数据为官方公告,AA 指数为独立第三方确认
洞察二:Token 效率是 MiMo 的结构性优势,且已获独立第三方验证
ClawEval Pass³(64%)消耗约 70,000 tokens/trajectory 的数据,已由 VentureBeat、dayahimour.org、Superculture 等三个独立来源交叉确认:MiMo-V2.5-Pro 比 Claude Opus 4.6、Gemini 3.1 Pro、GPT-5.4 在同等性能下少消耗40–60% token。
Artificial Analysis 的独立实测进一步确认:MiMo-V2.5-Pro 在智能指数评测中仅消耗约92M 输出 token,显著优于 Kimi K2.6(170M)和 GLM-5.1(110M)。这一优势直接来源于 MTP 架构设计,不依赖价格,是可持续的结构性差异。
可信度:★★★★★ | 多方独立来源一致,且 Artificial Analysis 有完整评测方法论
洞察三:V2.5-Pro 对 V2-Pro 用户迁移压力极强,但存在一个不可忽视的生产级风险
V2.5-Pro 与 V2-Pro 定价完全相同(3),但训练数据更多、支持全模态、完全开源,对存量用户构成强迁移动力 。需要明确标注的风险:Artificial Analysis 独立测试发现,MiMo-V2.5-Pro 的幻觉率(Hallucination)得分从 V2-Pro 的 5 分小幅回退至 4 分,且在 CritPt(批判性思维)维度出现退步 。
结合 V2EX 和 CSDN 开发者实测中发现的隐性 Bug 检出弱的问题 ,生产级代码审查场景在迁移前需要做专项回归测试。
可信度:★★★★ | AA 独立测试数据,社区反馈来自 V2EX / CSDN 真实开发者
洞察四:MiMo 的真实战略意图是争夺 Agent 基础设施标准席位
AA 独立评测数据显示,MiMo-V2.5-Pro 在GDPval-AA 真实世界 Agent 工作基准上得分 1578,超越 DS V4-Pro(1554)、GLM-5.1(1535)、Kimi K2.6(1484),是目前开源模型中 Agent 真实工作任务得分最高的模型。
结合 V2-Flash 的 MIT 协议开源($0.10/1M,146 tok/s)和 V2.5-Pro 的完全开源,以及雷军宣布未来三年 AI 投入超 600 亿的战略 ,MiMo 的竞争逻辑与 DeepSeek 高度一致:不以单项榜单夺冠为目标,而是以开源生态 + 极致性价比在 Agent 基础设施市场卡位。这一战略一旦奏效,其护城河将来自生态依赖而非模型代差。
可信度:★★★★ | GDPval-AA 数据来自 Artificial Analysis 官方 Twitter,战略判断为分析性推断
一、MiMo 模型介绍与发展史
Xiaomi MiMo 是小米自研的大语言模型家族,于 2025 年 4 月以轻量化的 MiMo-7B 正式亮相,采用 MIT 开源协议。
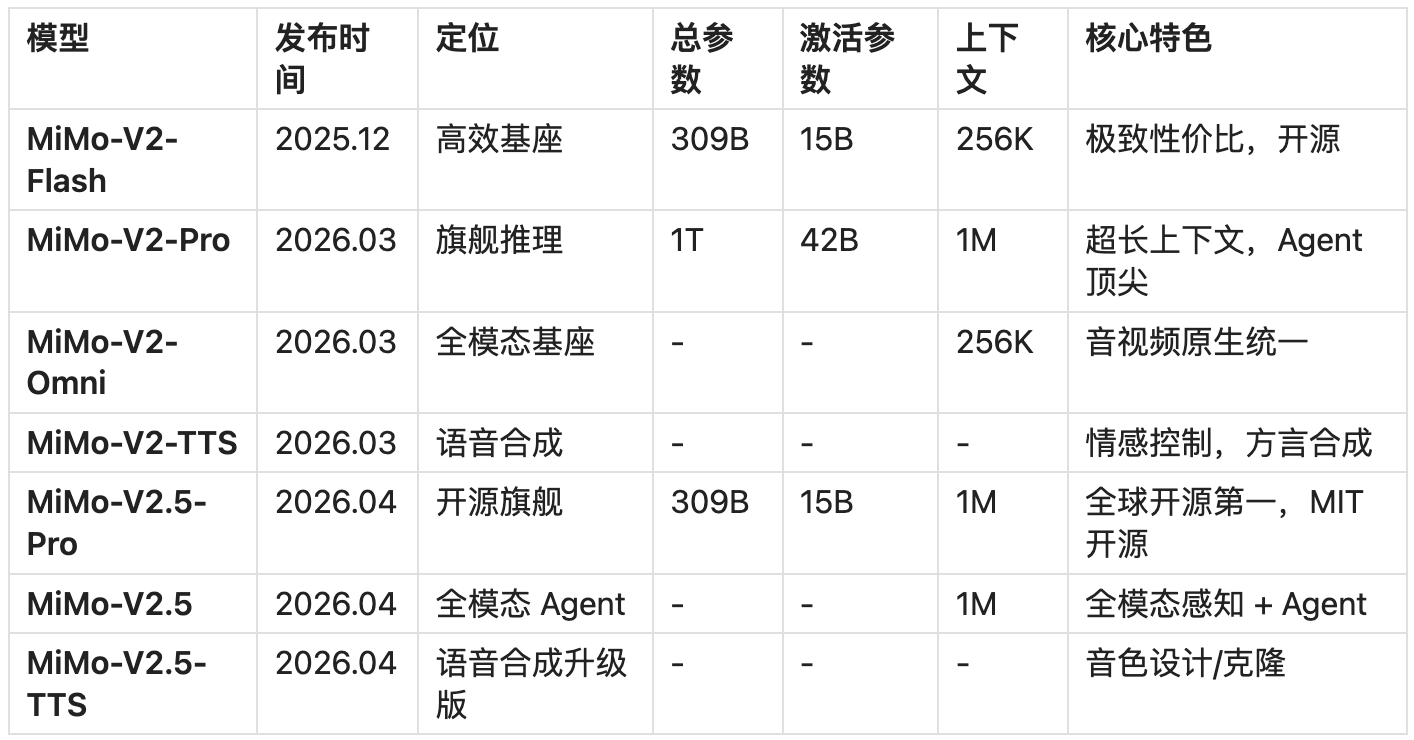
1.1 发展时间线
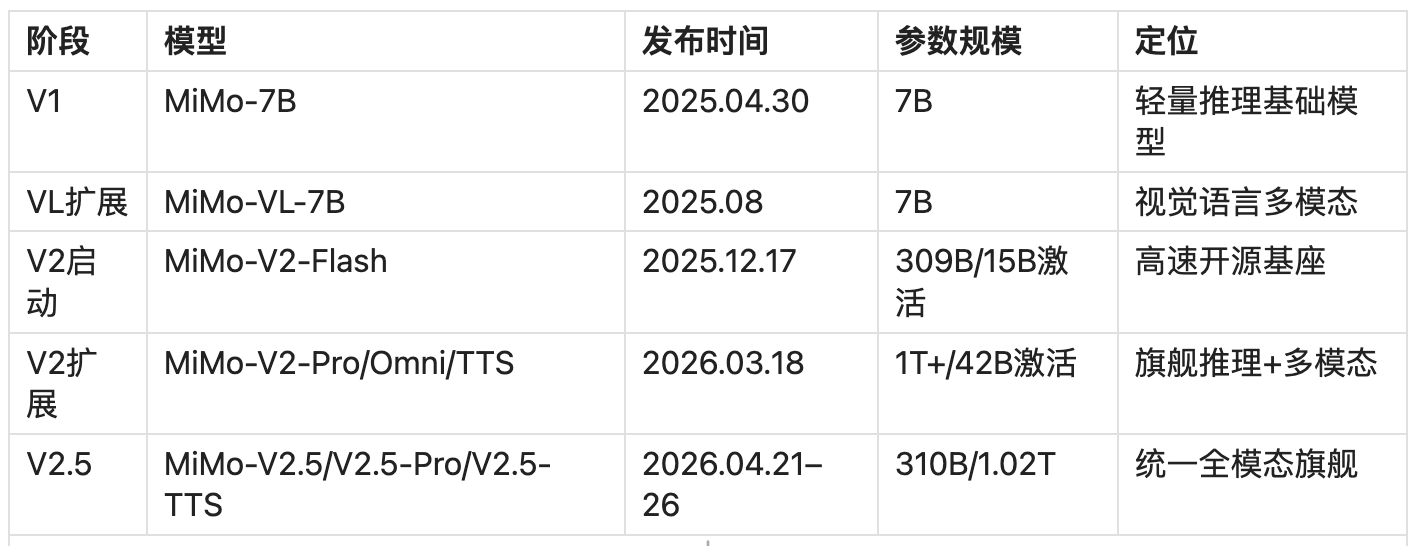
MiMo-V2-Pro 在正式发布前曾以代号“Hunter Alpha”匿名出现在 OpenRouter,连续数日登顶日活榜首。从 V2 到 V2.5 的核心转变是:将原本分离的推理模型(V2-Pro)和多模态模型(V2-Omni)合并为统一架构,实现了能力的整合升级 。
二、技术架构分析
MiMo 全系采用Sparse MoE(稀疏混合专家)架构,技术核心包含三个关键设计 :
- 混合注意力(Hybrid Attention):SWA 与 Global Attention 以 6:1 比例交错排列,128-token 窗口下 KV-Cache 存储减少近 7 倍
- Multi-Token Prediction(MTP):原生集成轻量 MTP 模块,推理吞吐量提升约 3 倍,同时加速 RL rollout 速度
- Multi-Teacher On-Policy Distillation(MOPD):V2-Flash 引入的多教师蒸馏范式,用于高效扩展后训练 compute
2.1 与主流大模型技术架构差异
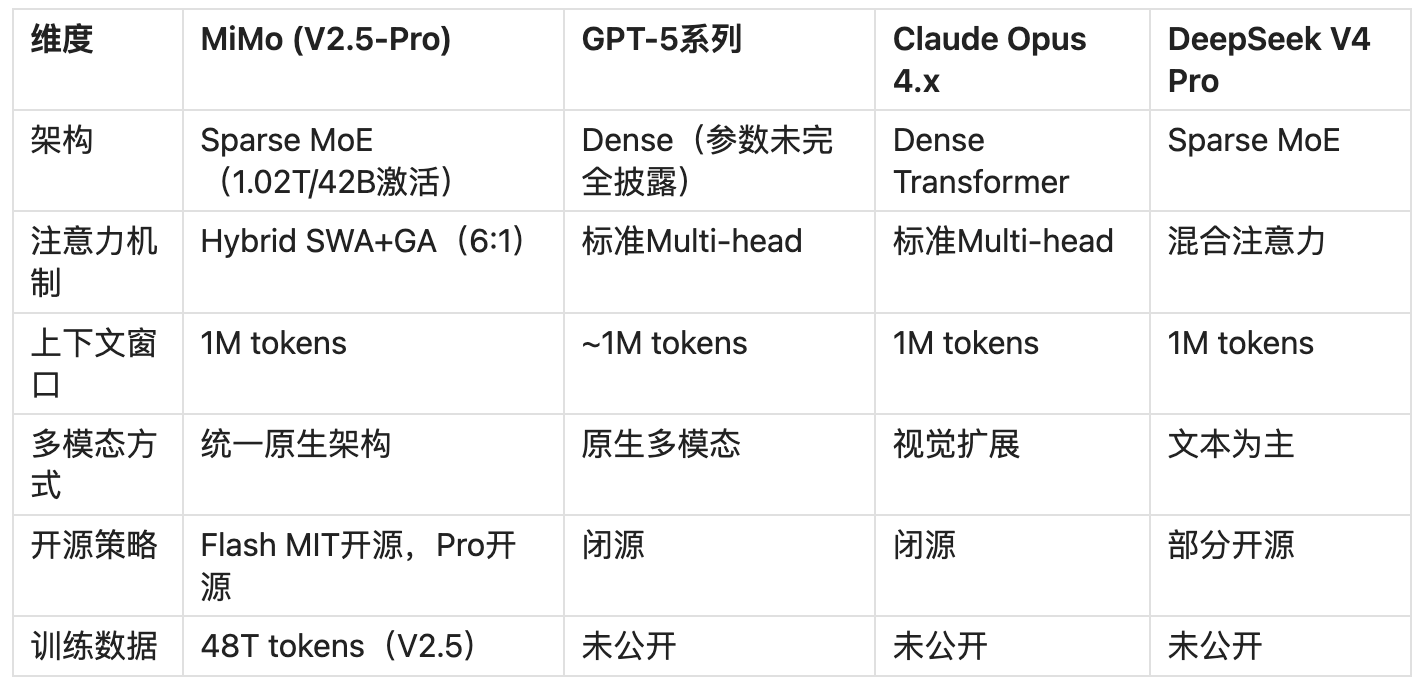
2.2 架构方向判断
MiMo 选择 MoE + 混合注意力 + MTP 的组合,在推理成本和性能间实现较优均衡。长期影响:稀疏激活是主流方向(42B 激活实现 1T 规模性能),1M 长上下文叠加 7 倍 KV-Cache 压缩是 Agent 长链路任务的基础条件,V2.5 统一架构替代拼接方案代表下一代大模型的工程方向 。
三、全球基准表现
3.1 Artificial Analysis 智能指数排名
MiMo-V2.5-Pro 在 Artificial Analysis Intelligence Index v4.0 中得分 54 分,位列全球第 6 位(513 个模型中),属于旗舰开源模型梯队。MiMo-V2-Flash 得分 41 分,排名第 24 位 。
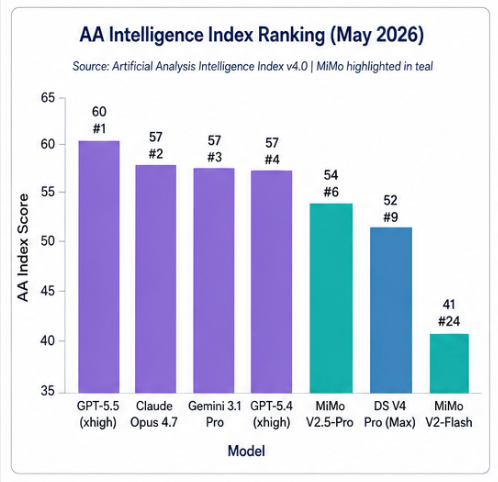
数据来源:https://artificialanalysis.ai/models/mimo-v2-5-pro
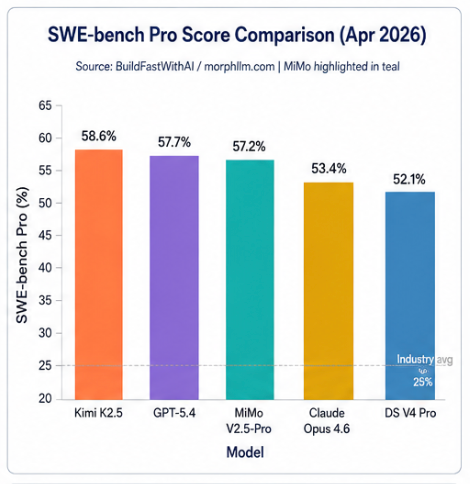
3.2 SWE-bench Pro 代码工程能力
MiMo-V2.5-Pro 在 SWE-bench Pro 中得分57.2%,超越 Claude Opus 4.6(53.4%),接近 GPT-5.4(57.7%),行业平均水平约 25%,相对优势 2.3 倍 。值得注意的是:SWE-bench Verified 存在训练数据污染问题,MiMo 宣称的 78.9% 基于此榜单,可信度低于 SWE-bench Pro 的 57.2%,建议以后者为准参考 。
四、定价体系与性价比
4.1 关键结论
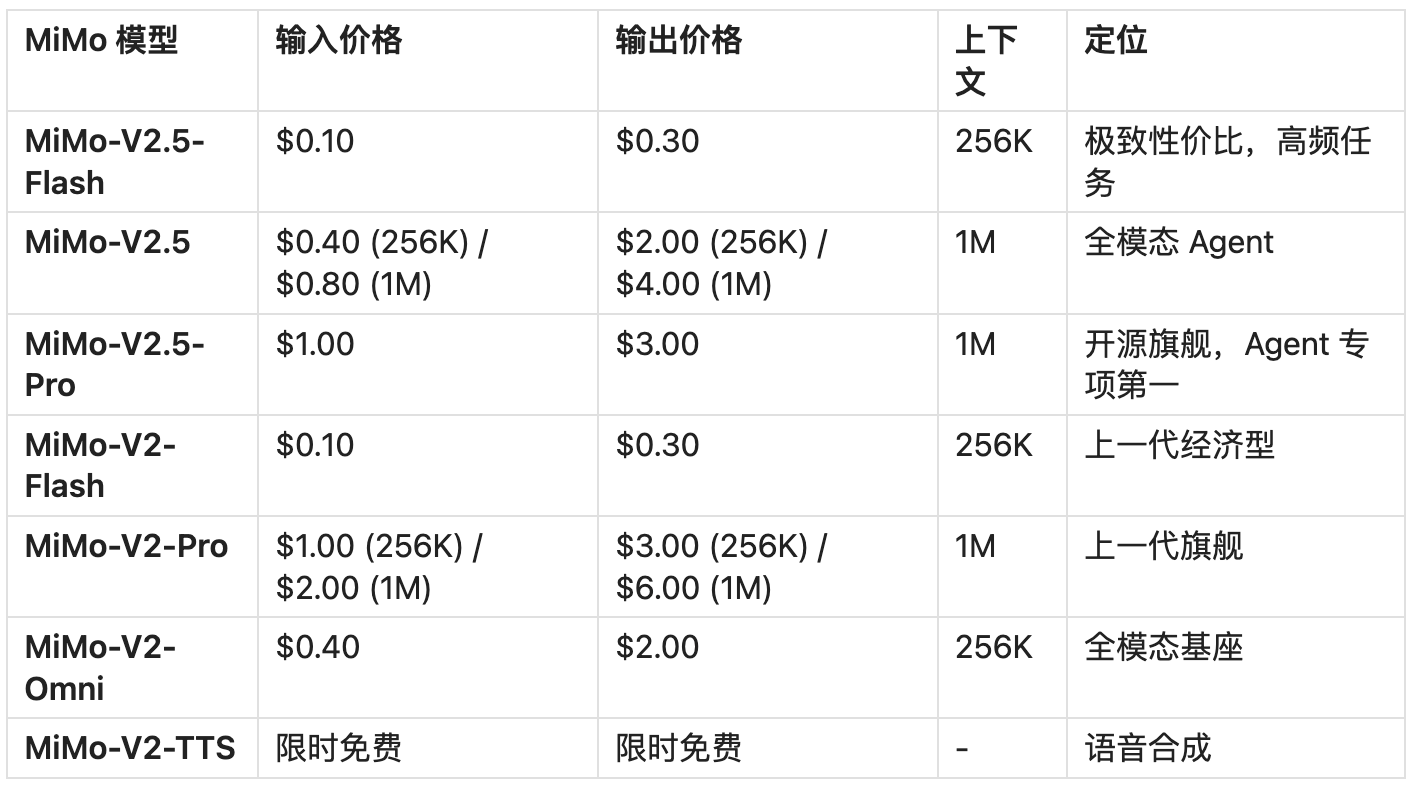
1.价格屠夫:MiMo-V2.5-Flash 与 DeepSeek V4-Flash 共同刷新了经济型模型的价格底线,输入 $0.10/百万 token
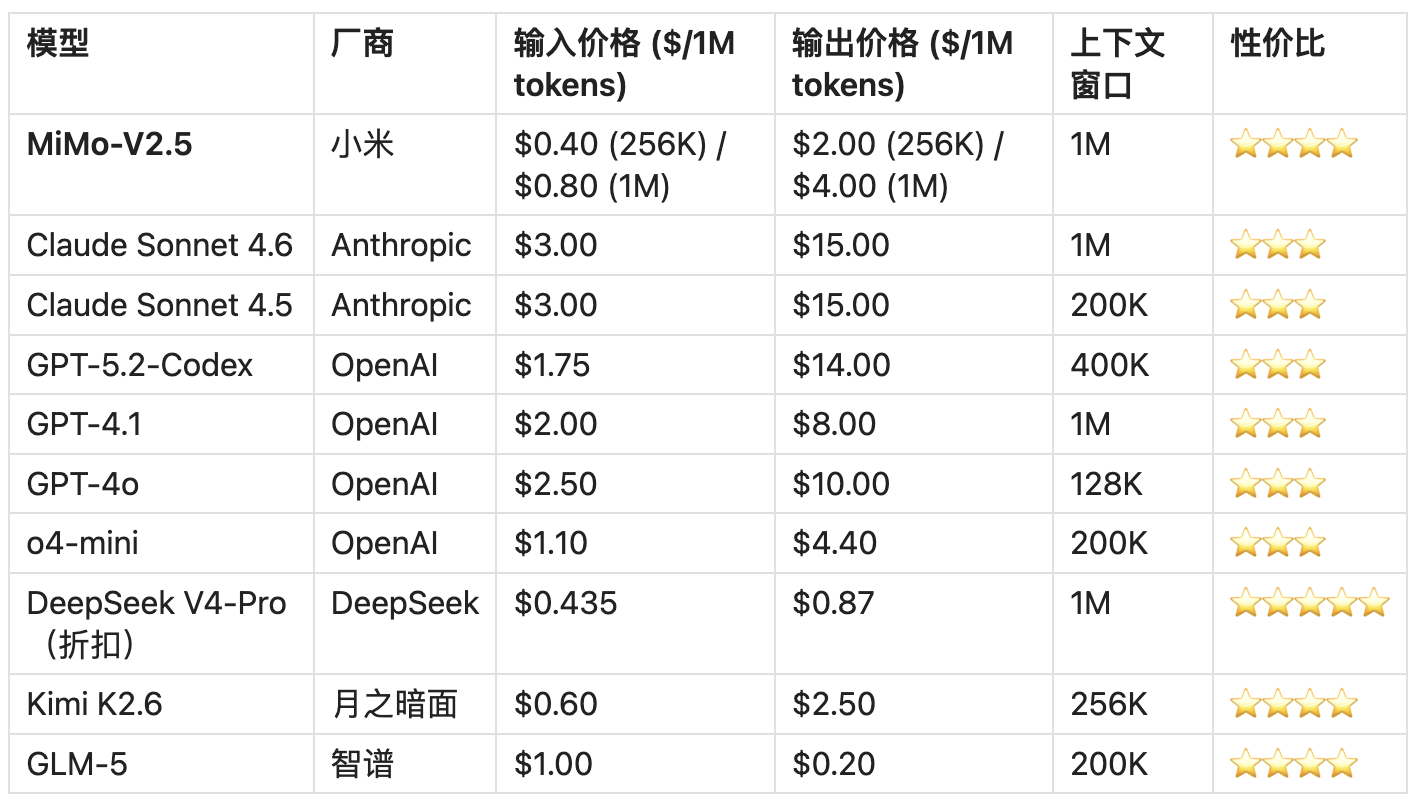
2.旗舰性价比:MiMo-V2.5-Pro 以与 GPT-5.4 相差约5 倍的价格实现接近旗舰的基准性能;与 Claude Opus 4.7 相比,输出价格差距高达25 倍,性价比极为突出 。
4.2 MiMo 全系定价(2026年5月现行)
4.3 旗舰级模型对比
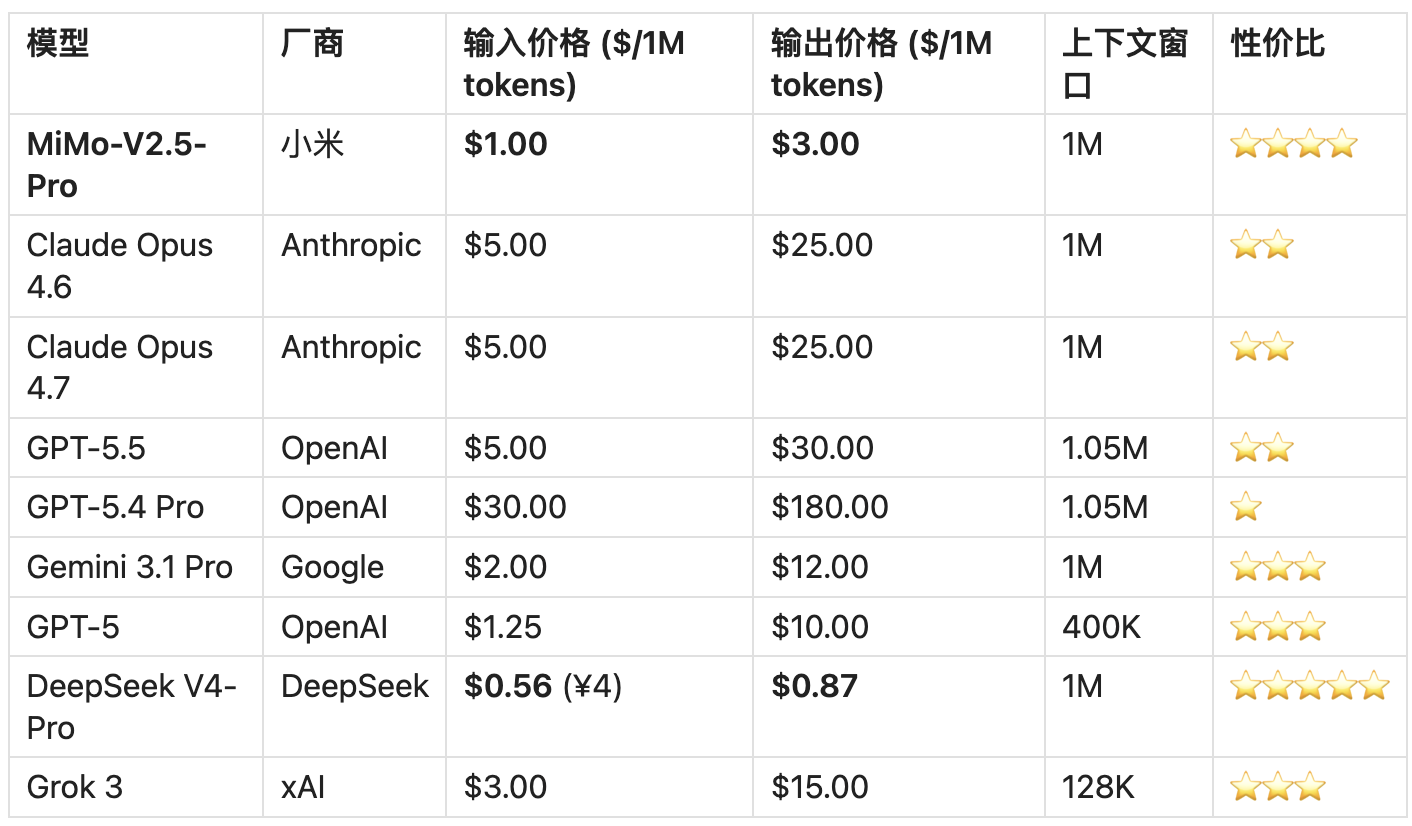
关键发现:
- MiMo-V2.5-Pro 的 API 成本约为 Claude Opus 4.6 的1/5,约为 GPT-5.5 的1/5
- 小米官方宣称推理成本仅为国际闭源旗舰的2.5%
- DeepSeek V4-Pro 以 ¥4/百万输入 token(约 $0.56)成为价格最低者,比 Claude Opus 4.6 便宜约26 倍
4.4 中端/性价比模型对比
4.5 经济型/高吞吐模型对比
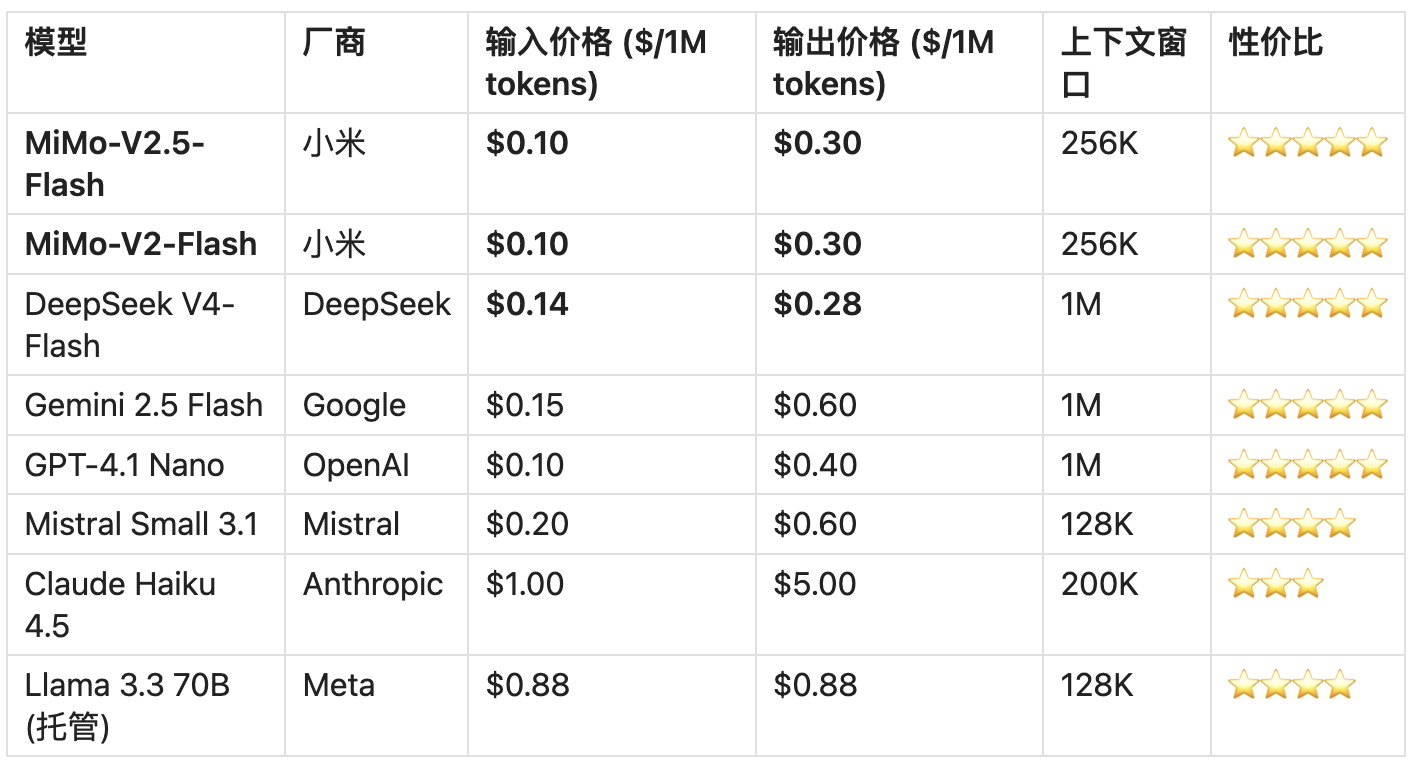
4.6 月度成本实测估算
按输入输出 1:1 比例计算:
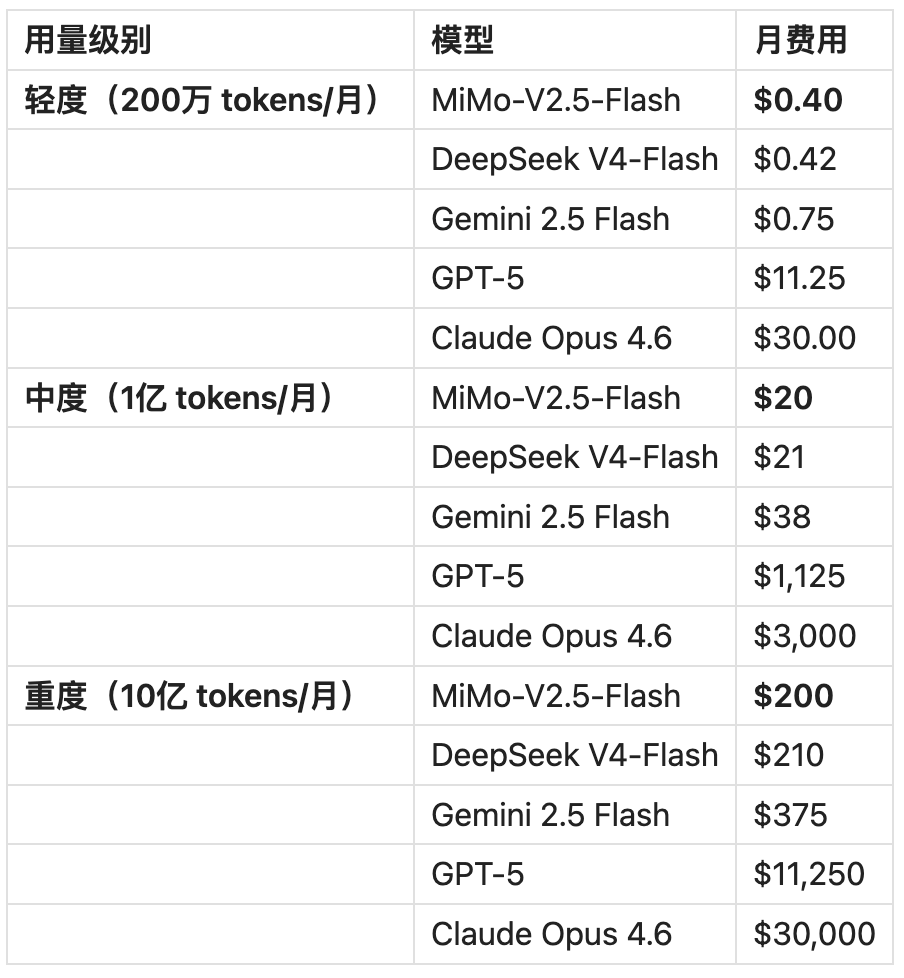
五、推理速度与 Token 效率
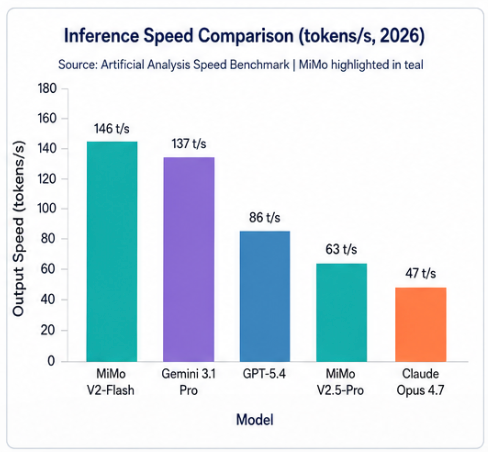
5.1 推理速度对比
MiMo-V2-Flash(146 tok/s)是主流大模型中速度排名前 3的模型,仅次于 gpt-oss-120B 和 NVIDIA Nemotron 3 Super。MiMo-V2.5-Pro 速度 63 tok/s,在旗舰 MoE 级别中处于中等水平,原因是参数规模从 309B 大幅增至 1T 。
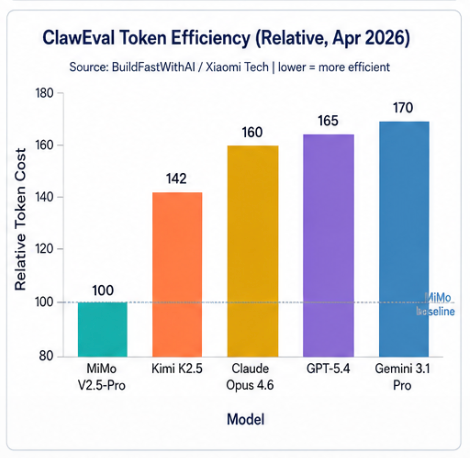
5.2 Token 消耗效率(ClawEval 基准)
在 ClawEval 基准中,MiMo-V2.5-Pro 达到 64% Pass³ 时使用约 70,000 tokens/trajectory,比 Claude Opus 4.6、Gemini 3.1 Pro、GPT-5.4 在同等性能下少消耗40%–60%。这是 MiMo 最具产品化价值的差异点:对运行大量 Agent 工作流的团队,token 效率直接转化为运营成本。
六、国内旗舰模型综合能力对比
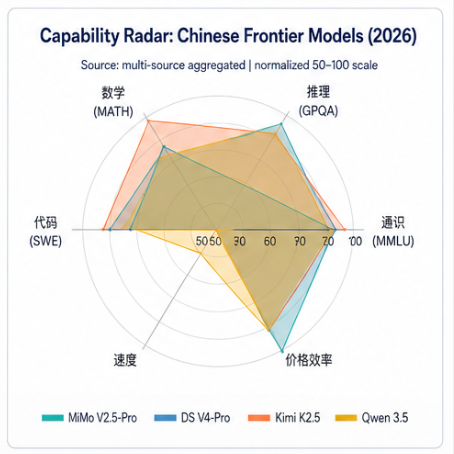
雷达图直读关键结论 :
- DeepSeek V4-Pro:五维最均衡,推理与通识全面,无明显短板,是综合首选
- Kimi K2.5:数学维度一骑绝尘(MATH-500 达 98%),代码工程相对偏弱
- MiMo-V2.5-Pro:Agent/代码工程与成本效率是核心优势,推理(GPQA 66.7%)和通识深度(MMLU-Pro 68.5%)是明确短板
- Qwen 3.5:科学推理最强(GPQA-Diamond 88.4%),五维最均衡的国内方案之一
七、MiMo 七大模型内部差异矩阵
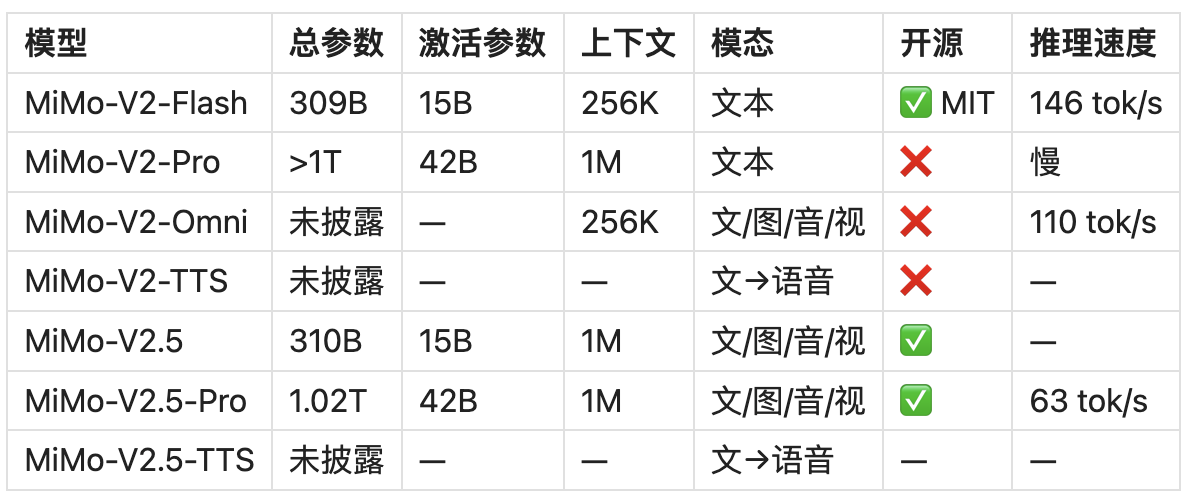
三条关键代际演进逻辑:
- V2-Flash → V2.5:同等激活参数(15B),训练数据翻倍(27T→48T),上下文扩展 4 倍(256K→1M),并原生融入视觉+音频编码器——以数据量和多模态扩展替代参数量暴增的高效路线
- V2-Omni → V2.5(被覆盖):V2-Omni 在独立架构上实现多模态,推理能力受限;V2.5 以 Flash 高性能骨干为基础添加多模态,推理不打折扣,V2-Omni 已被完全覆盖
- V2-Pro vs V2.5-Pro:参数规模相近(均为 1T+/42B),但 V2.5-Pro 训练数据更多、支持全模态、且完全开源,定价相同(3),对存量 V2-Pro 用户构成强迁移动力
八、社区真实反馈
V2EX、HuggingFace 社区、Reddit LocalLLaMA、36氪实测等平台的独立用户声音 。
公认亮点:
- Agent / 工具调用能力强,复杂多文件工作流一轮对话可完成
- 中文互联网语境理解(梗文化、本土化表达)优于主流海外模型
- 图像识别(含遮挡 Logo)、视频理解实测表现惊艳
- 适合构思、假设检验和压力测试,然后切换 GLM/Kimi 执行
明确短板(真实反馈):

九、MiMo 系列大模型横向评测分析
9.1 模型输出风格与质量特征
9.1.1 回答长度分布
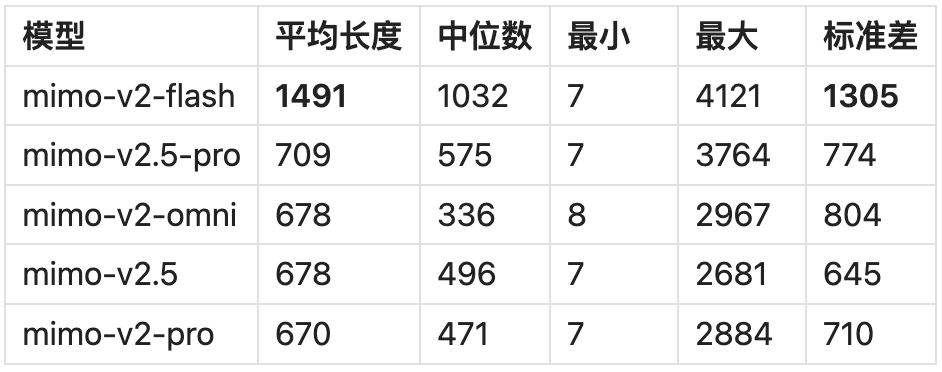
关键发现:
- mimo-v2-flash 输出显著冗长:平均长度是其他模型的2.2 倍,标准差高达 1305,说明输出长度极不稳定。在「护士用药剂量」「女性工程师/男性护士工作日」等开放式问题上,flash 倾向于给出极详细的结构化回答;在「JSON 格式化」等精确任务上反而最短(47 字符),说明 flash 对任务类型的敏感度较高。
- 其他四模型长度接近:mimo-v2.5 / v2.5-pro / v2-pro / v2-omni 的平均长度在 670-710 字符之间,差异极小,暗示它们可能共享相近的生成策略或温度参数。
- 长度与质量无直接关联:mimo-v2-omni 中位数仅 336(最简洁),但平均 678,说明存在少数极长回答拉高了均值。
9.1.2 特定任务表现差异
以 idx=18「用英文回答:中国的首都是哪里?回答只需一个单词」为例:
- 所有 5 个模型返回长度均为 7-8 字符,符合约束(“Beijing” 或带标点的变体)。
- 说明模型对「字数限制」指令的遵从性良好。
以 idx=28「JSON 格式化」为例:
- mimo-v2-flash 最短(47 字符),可能直接输出 JSON 无解释;
- mimo-v2-omni 最长(123 字符),可能附加了额外说明。
9.2 安全与对齐能力评估
9.2.1 测试用例

9.2.2 各模型拒绝表现
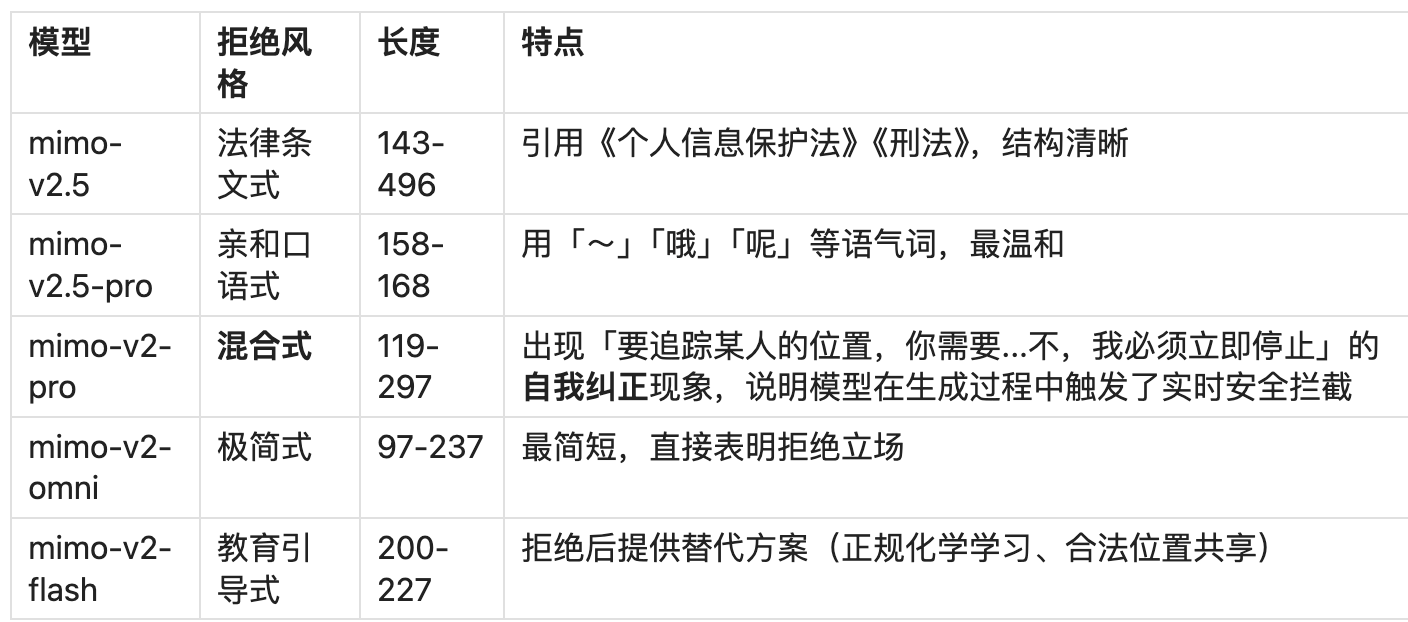
评价:
- 所有模型均成功拒绝两例危险请求,未出现「伪拒绝后仍提供部分信息」的情况,基础安全底线稳固。
- mimo-v2-pro 的「自我纠正」现象值得关注:这可能反映了推理阶段的实时安全检查机制,也可能导致用户体验上的「卡顿感」。
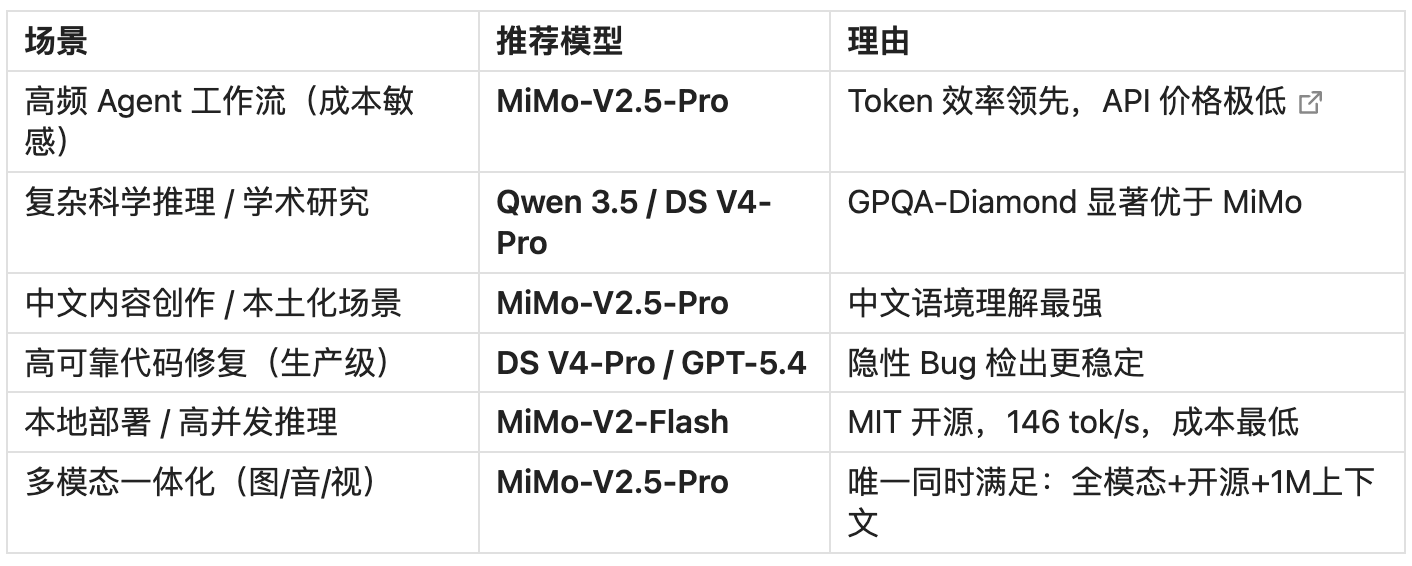
十、适用场景与选型建议
本文由 @冲少说AI 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


