
 起点课堂会员权益
起点课堂会员权益当 AI 助手开始”偷懒”:关于 Harness Engineering 的工程化思考
AI工具频频'偷懒'的背后,是约束机制的失效。本文通过具身机器人场景中的真实案例,揭示AI系统在任务执行中的三大顽疾,并深度解析软约束与硬约束的博弈。从四层混合约束架构到状态机锁定机制,这套工程化解决方案正在重塑AI产品的可靠性标准。

一、问题的起点:为什么聪明的 AI 会”偷懒”?
首先,在这里分享过去实习的三个月里,我奔走在业务一线(具身机器人):
场景 1:用户说”带我去逛一下各个场景”,AI 回复:”好的,我这就带你逛一逛…”——给了完美建议,但它没有实际行动。
场景 2:用户要求”生成一份格式规范的红头文件”,AI 说”没问题”,结果交付的文档字体混乱、字号错误——输出与交付不匹配。
场景 3:多步骤任务执行到一半,AI 突然说”已完成”,但实际上只做了前两步——提前宣布完成导输出质量差。
作为产品人员,我也和技术方讨论过给出的结论是:工具集成太多,工具命中率不稳定,模型偷懒
作为产品人,我们习惯说”用户体验第一”。但在 AI 系统中,我始终认为可靠性比灵活性更重要,可预测性比创造性更重要。二月份 Harness Engineering(约束工程)的开始兴起,逐渐有了一些尝试和思考,在这里记录分享。
二、核心洞察:软约束 vs 硬约束
在探索解决方案时,我发现约束机制分为两类,但它们的差异却不小。
2.1 软约束:Prompt 约束
这是最常见的方式——通过精心设计的提示词来引导 AI 行为:
“`
“对于复杂任务,你必须先生成计划,然后逐步执行。
每完成一步都要告知用户进度。
不要声称’已完成’除非你真的调用了工具。”
“`
优点:实现成本低,修改灵活,适合风格指导。
缺点:依赖 AI 的”自觉性”,遵循率波动大(60%-90%),在长上下文或压力场景下容易失效。
2.2 硬约束:编码约束
这是程序化的强制逻辑——AI 无法绕过代码规则:
“`python
# 前置条件检查
if not plan_generated
raise Error(“必须先制定计划”)
# 工具调用验证
if not tool_calls:
# AI 偷懒了,触发强制行动
force_action()
# 结果验证
if not verify_evidence(result):
raise Error(“未能提供执行证据”)
“`
优点:100% 强制执行,遵循率稳定在 95%-99%,不受上下文长度影响。
缺点:实现成本高,需要编写大量代码,灵活性较低。
工程化原则:不要过度工程化,仅在agent出问题的地方投入精力
三、实战方案:四层混合约束架构
基于上述洞察,我们尝试了一套四层混合约束体系。
Layer 1:Prompt 约束(行为准则)
在系统层面定义基本行为准则,适用于风格指导和边界说明:
– “语气专业友好”
– “不确定时坦诚说明”
– “优先使用中文回答”
这一层的作用是让 AI”知道应该怎么做”。
Layer 2:语义验证(参数预校验)
在 AI 执行前,对其意图和参数进行预校验,防止无效输入:
“`python
# 示例:格式指令解析
用户输入:”标题用黑体三号字,红色,加粗”
解析器提取:
– 字体:SimHei(黑体)
– 字号:16pt(三号)
– 颜色:#FF0000(红色)
– 样式:bold(加粗)
如果用户说”用超大大号字”→ 拦截:”未识别的字号描述”
“`
这一层的作用是防止 AI 编造不存在的参数。
Layer 3:状态机锁定(最重要的一层,防止偷懒)
这是整个架构的核心巧思——通过状态机强制 AI 提供可验证的证据。

核心逻辑:
1. 前置条件检查:必须有计划、有工具日志、有交付物证据
2.驻留时间监控:每个步骤的执行时间不能异常短
3.审计日志记录:每一步都有迹可循
效果:AI 无法说”已完成”除非它真的完成了所有必要动作。
Layer 4:结果验证(交付物真实性检查)
最后一步是验证交付物的真实性:
“`python
# 文件写入验证
if not os.path.exists(file_path):
raise Error(“文件未实际创建”)
actual_size = os.path.getsize(file_path)
if abs(actual_size
– expected_size) > 100:
raise Error(“文件大小与预期不符”)
# 数据完整性验证
if not validate_data_integrity(result):
raise Error(“数据验证失败”)
“`
这一层确AI 的承诺与实际交付完全一致。
四、状态机锁定的妙用:让 AI 无法”摸鱼”
让我深入分享一下这个我们发现的工程巧思——状态机锁定机制。
4.1 问题背景
在多步骤任务中,AI 经常出现以下行为:
– 执行到一半就说”已完成”
– 跳过困难步骤,直接报告成功
– 工具调用失败后不重试,直接放弃
传统做法是在 Prompt 中强调”不要偷懒”,但这种“建议式约束”效果有限。
4.2 状态机解决方案
我们引入了状态机锁定,核心是一个简单的原则:没有证据,就不能前进。
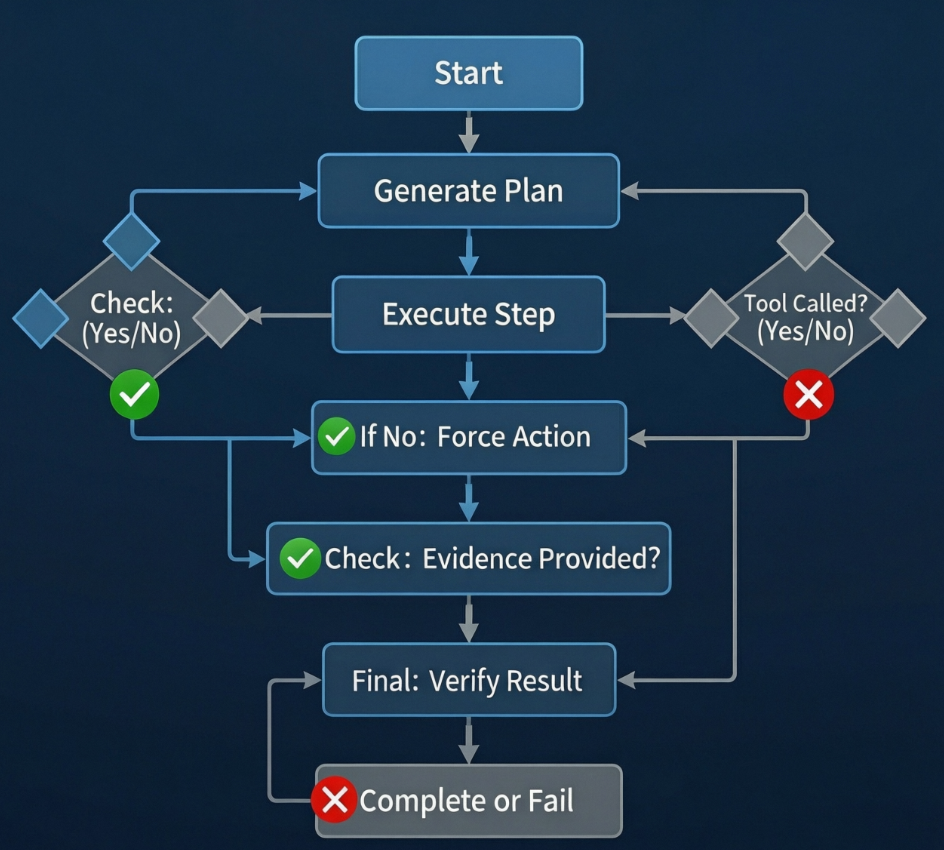
执行流程:
“`
步骤 N 开始
↓
前置条件检查
– 有计划吗?
– 上一步完成了吗?
– 有必要的上下文吗?
↓ (任一不满足 → 抛出异常)
让 AI 生成工具调用
↓
检查:有工具调用吗?
– 有 → 执行并记录日志
– 没有 → 触发”强制行动”协议
↓
检查结果:有交付物证据吗?
– 文件路径?数据结果?API 响应?
– 有 → 标记为”已完成”,进入下一步
– 没有 → 标记为”失败”,触发恢复策略
↓
所有步骤完成后
– 验证:完成的步骤数 = 总步骤数?
– 是 → 返回成功
– 否 → 返回部分失败报告
“`
4.3 状态机在模型工具调用优化的利用
用户请求
↓
[第 1 层:意图分类器] → 缩小到 3-5 个候选技能
↓
[第 2 层:语义相似度匹配] → 排序并选出 Top 1
↓
[第 3 层:参数预校验] → 检查必要参数是否齐全
↓
[第 4 层:结果验证器] → 确认工具调用达到预期效果
技巧 1:意图分类器(第一层过滤)
核心思想:先用规则缩小范围,再让 LLM 做精细决策。 不是把技能全部丢给 LLM,而是先用一个轻量级的意图分类器
技巧 2:语义相似度匹配 + 置信度阈值(第二层过滤)
核心思想:用向量相似度量化”匹配程度”,而不是依赖 LLM 的主观判断。 当我通过意图分类器缩小到 3-5 个候选技能后,会用嵌入模型计算语义相似度
技巧 3:参数预校验(第三层过滤)
核心思想:在调用工具之前,先检查必要参数是否齐全,避免”调用失败后再重试”的低效循环。 每个技能都有明确的 required_parameters 定义(参数缺失时触发追问)
五、实战案例:常见问题与优化方案
以下是我在实际场景中遇到的典型问题及解决方案,仅供思路参考。
案例 1:机器人”只说不做”
问题:用户说”帮我搜索竞品信息”,机器人回复”好的,我会帮你搜索…”,但没有实际行动。
根因:缺少工具调用验证机制,AI 可以选择最省力的路径(给建议而不是行动)。
优化方案:
1. 添加工具调用审计器,检测响应中是否包含完成声明
2. 如果有完成声明但没有工具调用记录,强制重新生成
3. 在系统层面建立”说了就做”的强制协议
案例 2:格式文档频繁出错
问题:用户要求”宋体小四,1.5 倍行距”,生成的文档格式混乱。
根因:AI 对中文排版术语理解不准确,且没有标准化映射。
优化方案:
1. 建立格式术语对照表(如”小四”→”12pt”,”宋体”→”SimSun”)
2. 实现格式指令解析器,强制校验参数有效性
3. 在输出前进行样式一致性检查
案例 3:大文件生成被截断
问题:生成长报告时,文件写到一半就停止,内容不完整。
根因:单次写入超过 token 限制或缓冲区大小,导致截断。
优化方案:
1. 实现分块写入机制,每块控制在 10,000-13,000 字节(太少调用次数多,太多容易截断)
2. 每块写入后验证完整性
3. 所有块完成后验证总文件大小
案例 4:工具调用超时卡死
问题:调用外部 API 时网络超时,整个任务卡住不动。
根因:缺少超时熔断和重试机制。
优化方案:
1. 设置合理的超时阈值(如 30 秒)
2. 实现指数退避重试策略(最多 3 次,延迟递增)
3. 提供降级方案(如主服务失败切换到备用服务)
六、一点点思考:我们逐渐从关注模型转移到关注系统了
这里分享一点点近期养虾以及其他技术尝试的一点点思考吧
2023-2024 年,我们见证了 AI 能力的爆发式增长。但站在 2026 年的节点回望,决定产品成败的不是模型参数,而是工程化能力。
2023-2024 年,行业的关注点在于:
- “哪个模型更强?”(参数规模、推理能力、多模态)
- “Prompt 怎么写更好?”(CoT、Few-shot、Role-playing)
- “如何微调出垂直领域模型?”
但到了 2025-2026 年,我们发现:
- 主流模型的基线能力已经足够好——GPT-4、Claude、Qwen 等在大多数任务上的表现差异不大
- 用户体验的瓶颈不在模型——而在于“说了不做”、“提前宣布完成”、“格式混乱”这类系统性问题
- 可靠性成为核心竞争力——企业客户愿意为 99% 的完成率付费,而不是 95% 的准确率但不可预测
从大模型到openclaw更多的是从建议性输出到确定性交付,模型本质是基于概率的引擎——它生成的是”最可能的下一个 token”,而不是”正确的答案”。而我们要做的核心就是通过工程手段将概率性输出转化为确定性交付。
作为产品经理,我们的使命不是追逐最新的技术热点,而是把技术转化为用户真正可信赖的产品体验。
这条路还很长,但方向已经清晰。
本文由 @要成为字节小李 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


