
 起点课堂会员权益
起点课堂会员权益Claude Code Auto Mode:一次关于”信任边界”的产品设计实验
Claude Code 的 Auto Mode 打破了 AI 编程工具的尴尬困局——模型能力越强,用户越被频繁的确认弹窗所困扰。这次更新不仅是一次功能升级,更是对 AI 与人类信任边界的重新定义。从心理学的心流状态到企业级安全需求,Anthropic 用三层决策机制和智能回退设计,为开发者打造了既高效又安全的自主编程体验。

有一种工具,越好用,越让人抓狂。
这不是在说某款设计糟糕的软件,而是在描述 Claude Code 在 Auto Mode 上线之前的真实处境。它的代码理解能力、重构能力、调试能力,在开发者社区里口碑极好。但它有一个让人崩溃的习惯:每走一步,都要停下来问你”可以吗?”
改个文件名,问一下。执行一条 Bash 命令,问一下。写完一段代码,再问一下。开发者的注意力被这些弹窗切割得支离破碎,根本无法进入连续工作的状态。有人在社区里抱怨:”我雇了个能力极强的助手,但它每隔三秒就拍我肩膀。”
这就是 AI 编程工具在 2026 年初面临的核心悖论:模型能力越强,自主执行的范围越广,用户对失控的恐惧就越深,产品设计者就越倾向于设置更多确认节点,而这又反过来破坏了 AI 的价值。
2026 年 3 月 25 日凌晨,Anthropic 用 Claude Code Auto Mode 给出了自己的答案。这不只是一次功能更新,它是一次关于 AI 与人类之间”信任边界”应该如何设计的产品实验。
一、需求侧——开发者到底在忍受什么?
“每步确认”制造的体验断层
要理解 Auto Mode 的价值,首先要理解旧模式的代价有多高。
Claude Code 默认的权限模型,本质上是一种”零信任”架构:AI 不被默认信任能做任何有副作用的操作。这在逻辑上无懈可击——毕竟一个 AI 在你的文件系统里自由行动,确实存在风险。但这套逻辑在实际使用中带来了严重的摩擦。
心理学中有一个概念叫”心流”(Flow),指人在高度专注时进入的一种忘我状态,这是创造性工作效率最高的时刻。频繁的确认弹窗是心流的天敌——每一次中断都意味着认知资源的重新加载,开发者需要从”我在解决什么问题”切换到”这一步操作是否安全”,再切换回来。当这种切换每隔几分钟发生一次,整个工作体验就会从”高效协作”退化为”疲惫监工”。
更深层的问题在于,这种设计从根本上限制了 Agent 模式的可能性。把一个完整任务交给 AI 去执行,是 Agent 化编程工具的核心价值主张。但如果 AI 每走一步都需要人工审批,那它本质上还是一个”高级自动补全”,而不是真正意义上的 Agent。
核心用户场景
从社区反馈来看,对旧模式最不满的开发者,往往集中在三类场景中。
第一类是长任务执行者。这类开发者的典型需求是:给 AI 一个明确目标,比如”把这个项目从 JavaScript 迁移到 TypeScript”,然后去做别的事,回来看结果。旧模式下这完全不可能——任务会在第一个需要确认的操作处卡住,等你回来时屏幕上只有一个孤零零的确认框。
第二类是无人值守需求者。部分开发者希望在下班后或专注其他工作时,让 Claude Code 在后台跑自动化任务。这类需求在旧模式下同样无解,因为任何一步操作都可能触发等待人工响应的暂停。
第三类是企业级团队用户。对于工程团队来说,频繁的手动确认不仅是个人效率问题,更是团队协作流程的成本问题。当 AI 编程工具需要全程人工陪跑时,它的规模化价值就大打折扣。
“跳过权限”的危险诱惑
面对旧模式的摩擦,不少开发者选择了一条捷径:使用 –dangerously-skip-permissions 指令直接绕过所有权限检查。这个指令在开发者社区里已经有了一个戏称——”YOLO 模式”。
YOLO 模式确实解决了效率问题,但代价是安全边界完全消失。AI 可以自由执行任何操作,包括删除文件、修改系统配置、向外部发送数据。在完全隔离的测试环境里,这或许勉强可以接受;但在真实的开发环境中,这相当于把系统钥匙交给一个你无法完全预测行为的实体。
恰好在 Auto Mode 上线的同一天,前 OpenAI 核心创始成员 Karpathy 披露了一起 litellm PyPI 供应链攻击事件——一个看似无害的 pip install 命令,可以窃取 SSH 密钥、AWS 凭据、git 凭据、加密钱包等一切敏感信息。这个案例完美诠释了”完全放开权限”的潜在灾难:当 AI 在无人监管的状态下自主安装依赖包时,一次供应链污染就可能造成不可逆的损失。
旧模式(步步确认)与 YOLO 模式(完全放开)之间,存在一片巨大的空白地带。Auto Mode 要填补的,正是这片空白。
二、产品侧——Auto Mode 的设计哲学
从”工具”到”代理”的角色转变
Auto Mode 的本质,是对 AI 编程工具角色定位的一次根本性重新定义。
在旧模式下,Claude Code 是一个”高能力、低自主”的工具:它能做很多事,但每件事都需要人来拍板。这种模式的隐含假设是:AI 的判断不可信,人类必须全程监督。
Auto Mode 改变了这个假设。它的隐含逻辑是:AI 的判断在大多数情况下是可信的,人类只需要在关键节点介入。 这是一个看似微小、实则深刻的认知转变——它意味着 AI 开始承担真正意义上的”决策职责”,而不只是”执行职责”。
这种转变在产品设计上有一个直接体现:Auto Mode 把“确认”的触发条件,从“所有操作”收窄到了“高风险操作”。 绝大多数日常开发操作——本地文件读写、常规代码修改、向当前分支推送代码——都不再需要人工介入,AI 直接执行。只有当操作触及安全边界时,人类才重新进入决策链。
“安全自主”而非”完全放开”的精准卡位
Auto Mode 最值得称道的产品决策,是它对自身定位的精准把握。
它没有选择成为另一种形式的 YOLO 模式——那会让安全意识强的开发者望而却步。它也没有在旧模式上小修小补——那无法解决根本矛盾。它选择了一条更难走但更有价值的路:构建一套智能的风险判断机制,让 AI 在安全边界内自主决策,同时在边界处保留人类的最终控制权。
这种定位在商业上也极为聪明。它同时满足了两类看似矛盾的用户需求:追求效率的开发者得到了”不被打断的工作流”,注重安全的开发者和企业得到了”可信赖的自动化框架”。这不是妥协,而是真正找到了两者的交集。
三层决策机制:规则与智能的平衡
Auto Mode 的核心技术实现是一套分层决策机制,逻辑清晰,层次分明。
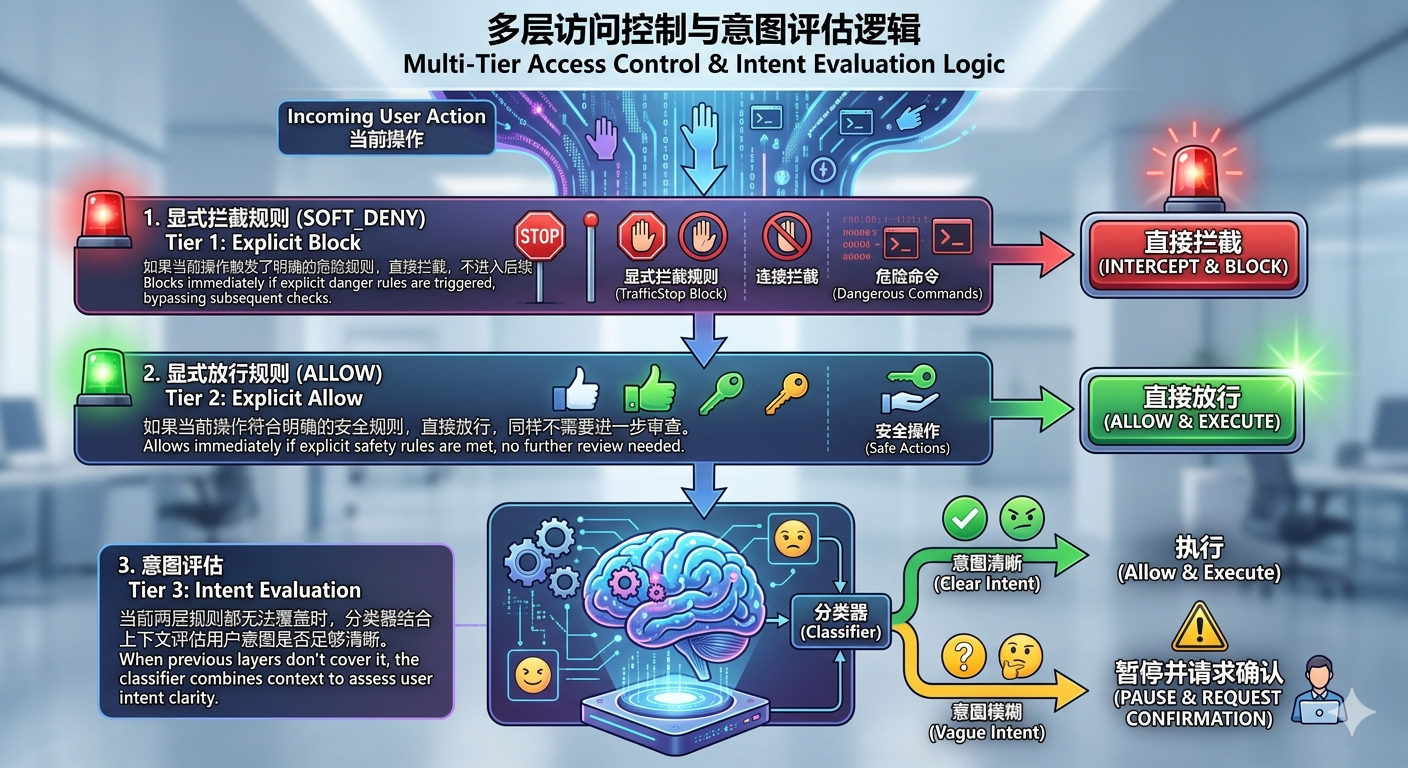
第一层是显式拦截规则(soft_deny):如果当前操作触发了明确的危险规则,直接拦截,不进入后续判断。第二层是显式放行规则(allow):如果当前操作符合明确的安全规则,直接放行,同样不需要进一步审查。第三层是意图评估:当前两层规则都无法覆盖时,分类器结合上下文评估用户意图是否足够清晰——意图清晰则执行,意图模糊则暂停并请求确认。
这套机制的设计智慧在于:它不是一个简单的黑白名单,而是一个有层次的决策树。规则层处理确定性强的情况,智能层处理模糊地带。两者结合,既保证了效率,又保留了灵活性。
回退机制:失控保护比功能本身更重要
Auto Mode 中最容易被忽视、却最能体现产品成熟度的设计,是它的回退机制。
当分类器在单次会话中连续拦截 3 次操作,或累计拦截达到 20 次时,Auto Mode 会自动暂停,系统恢复到逐步确认模式,并提醒用户介入。这个设计传递了一个明确的信号:AI 永远不会在用户不知情的情况下陷入危险的死循环。
从产品经理的角度看,这个机制的价值不在于它被触发的频率,而在于它存在这件事本身。它是一种”安全网”的心理锚点——用户知道系统有兜底机制,才会真正放心地把任务交出去。这是建立用户信任的关键一环,远比任何功能介绍都有说服力。
三、技术侧——分类器模型的能力与边界
为什么需要独立分类器,而不是让主模型自我判断?
Auto Mode 选择引入一个独立的分类器模型(基于 Claude Sonnet 4.6),而不是让执行任务的主模型顺带做安全判断,这个架构决策背后有深刻的工程逻辑。
主模型在执行任务时,其注意力集中在”如何完成目标”上。如果同时要求它评估自身行为的安全性,两个目标之间存在潜在的利益冲突——为了完成任务,模型可能在安全判断上产生偏差(即”目标导向的合理化”)。独立分类器的存在,相当于引入了一个没有任务压力的”第三方审计员”,其唯一职责就是评估风险,不受任务目标的干扰。
此外,独立分类器还有一个工程优势:它可以独立迭代和优化,不需要重新训练整个主模型。随着分类器积累更多真实使用数据,其判断准确率可以持续提升,而主模型的能力不受影响。
四类高危行为的识别逻辑
分类器重点扫描的四类高危行为,覆盖了开发场景中最主要的风险类型。
大规模文件删除针对的是最直接的数据损毁风险。删除一个临时文件是正常操作,但批量清空目录则可能是灾难性的误操作。分类器通过操作规模和目标路径的组合判断来区分两者。敏感数据外泄针对的是数据安全风险,重点检测向外部地址发送大量数据的行为,尤其是涉及密钥、凭证、个人信息的传输。恶意代码执行针对的是供应链和注入攻击,识别那些行为模式异常的命令序列。提示词注入攻击则是最具前瞻性的一类防护——当 AI 处理的内容(用户输入、网页数据、文档内容)中藏有恶意指令时,分类器能够识别出这种”二阶攻击”并拦截。
分类器的已知盲区
诚实地评估 Auto Mode,需要正视分类器的能力边界。
最典型的盲区是“逻辑性破坏”。分类器擅长识别系统层面的危险操作(rm -rf /、向外发送数据),但对业务逻辑层面的破坏性操作可能不够敏感。比如 truncate table users 这条 SQL 命令,从系统安全角度看并无异常,但对业务数据来说是致命的。分类器的判断框架是”系统安全”,而不是”业务安全”,这两者之间存在一个难以用通用规则覆盖的灰色地带。
另一个潜在盲区是环境上下文的局限。分类器默认信任本地工作目录和已配置的远程仓库,但对于特殊的安全需求(比如涉及高度敏感数据的项目),这种默认信任可能过于宽泛。
Token 成本也是一个不容忽视的技术代价。每次操作前的分类器审查都会消耗 Token,越复杂的命令,审查成本越高。这意味着 Auto Mode 在提升效率的同时,也在提升使用成本——对于高频使用者来说,这是一个需要认真管理的变量。
四、商业侧——Auto Mode 背后的增长逻辑
团队版优先开放的战略意图
Auto Mode 首先在团队版(Team Plan)以研究预览形式开放,企业版和 API 访问随后跟进。这个发布顺序不是偶然的,它反映了 Anthropic 的商业优先级。
团队版用户通常是工程团队,他们有更强的多步骤任务需求,对 Auto Mode 的价值感知最直接,也最有能力提供有质量的使用反馈。先在这个群体中验证功能,既能快速收集真实数据优化分类器,又能通过团队内部的口碑传播形成自然的用户增长。同时,企业级用户的安全合规需求更高,先在团队版跑通安全机制,再向企业版推广,也降低了大规模商业化的风险。
Token 消耗的双刃剑效应
Auto Mode 对 Anthropic 商业模式的影响是双向的,这一点值得深入分析。
从正面看,Auto Mode 显著提升了用户粘性和使用深度。当 AI 真正能够无打断地执行长任务时,用户愿意把更复杂、更大规模的任务交给它,单次会话的 Token 消耗随之大幅上升。这对订阅制产品来说是极好的消息——用户越依赖,流失率越低,续费率越高。
但从另一面看,Token 消耗的急剧增加也可能触发用户的”成本焦虑”。Reddit 上已经有用户反映,”改个错别字,Claude 自动运行了 10 步,一周的额度没了”。当用户开始感觉 Auto Mode 在”烧钱”而不是”帮忙”时,使用热情会迅速降温。如何在用户价值感知和成本控制之间找到平衡,是 Anthropic 需要持续优化的产品课题。
竞品压力与行业范式迁移
Auto Mode 的发布,对 GitHub Copilot、Cursor 等竞品构成了明确的产品压力。这些工具目前大多仍停留在”辅助建议”模式,最终决策权完全在开发者手中。这种模式安全,但在 Agent 化浪潮中正在显得越来越保守。
Auto Mode 代表了一个清晰的行业信号:AI 编程工具的竞争焦点,正在从“能否完成编程任务”转向“能否在安全边界内自主完成编程任务”。 前者是能力竞争,后者是信任竞争。信任竞争的壁垒更高,因为它需要的不只是模型能力,还需要工程积累、安全机制设计和大量真实使用数据的迭代。Anthropic 通过 Auto Mode 率先建立了这个维度的先发优势。
五、风险侧——产品经理不能忽视的隐患
误判的两种代价与产品责任边界
分类器的误判存在两个方向,且代价截然不同。
漏拦危险操作的代价是直接的、可见的:文件被删、数据外泄、系统被破坏。这类错误会立即引发用户愤怒和信任崩塌,是 Anthropic 必须竭力避免的。误拦正常操作的代价是间接的、累积的:用户被频繁打断,体验退化,逐渐放弃使用 Auto Mode,转而回到旧模式或竞品。这类错误不会引发危机,但会悄悄侵蚀产品价值。
Anthropic 官方的建议——”在 Docker 容器或隔离环境中使用”——实际上是在划定产品责任边界。这个建议传递的信息是:Auto Mode 是一个强大但仍在演进中的工具,Anthropic 对其安全性有信心,但不承诺在所有环境下的零风险。这是一种务实且诚实的产品态度,但也意味着用户需要自己承担一部分环境配置的责任。
用户认知风险:过度信任的陷阱
Auto Mode 面临的最隐性风险,是用户对它的过度信任。
当一个工具被定位为”安全自主”时,用户很容易从”谨慎使用”滑向”完全依赖”。他们可能开始在越来越敏感的环境中使用 Auto Mode,减少对 AI 行为的监控,甚至把它部署在生产环境中而不做任何隔离。这种认知漂移是渐进的,不易察觉,但一旦出现问题,后果往往比 YOLO 模式更严重——因为用户已经习惯了不盯着屏幕。
如何在产品层面持续提醒用户”你仍然是最终责任人”,同时又不破坏 Auto Mode 带来的流畅体验,是一道没有完美答案的产品设计难题。
六、行业视角——这次更新意味着什么?

从”副驾驶”到”主驾驶”的范式转移
Auto Mode 的发布,是 AI 编程工具从”副驾驶”(Copilot)向”主驾驶”(Autopilot)转变的一个标志性节点。
“副驾驶”模式的本质是:AI 提供建议,人类做决策,人类执行操作。”主驾驶”模式的本质是:AI 做决策,AI 执行操作,人类保留否决权。这两种模式对开发者工作流的影响是质变而非量变——前者是工具,后者是协作者。
Auto Mode 还不是完全意义上的”主驾驶”——它在高风险节点仍然需要人类介入。但它清晰地指出了方向:随着分类器能力的持续提升,AI 能够自主处理的操作范围会越来越广,人类需要介入的节点会越来越少。这个趋势不可逆转。
“安全边界内的自主决策”将成为行业标准
Auto Mode 确立的产品范式——智能分类器 + 分层决策机制 + 人类最终控制权——很可能在未来一两年内成为 AI 编程工具的标准配置。
这不是因为 Anthropic 拥有某种不可复制的技术优势,而是因为这个范式精准地解决了 AI 编程工具的核心矛盾,任何认真做这个领域的团队都会走到同一个答案。竞争的差异将体现在分类器的准确率、规则的可配置程度、回退机制的优雅程度,以及与不同开发环境的集成深度上。
结语:信任,是 AI 时代最难设计的产品功能
回到最开始的那个产品悖论:AI 越强大,用户越不敢放手。
Auto Mode 给出的解法,不是让用户”更勇敢”,也不是让 AI “更保守”,而是建立一套可验证的信任机制——让用户不需要勇气,因为系统本身已经足够可靠;让 AI 不需要保守,因为安全边界已经被清晰定义。
这个思路,其实超越了 AI 编程工具本身。在 AI Agent 大规模落地的浪潮中,几乎所有场景都会面临同一个问题:如何让人类在”放手”的同时,始终感到”掌控”?这不是一个技术问题,而是一个关于人机信任关系的设计问题。
Claude Code Auto Mode 是一次重要的实验。它的成败,不仅关乎 Anthropic 的产品竞争力,也将为整个行业如何设计”可信赖的 AI 自主性”提供宝贵的参考。
AI 终于开始“自己开车”了。但真正的挑战,是让坐在副驾驶的人,既能闭上眼睛休息,又能在需要时随时接管方向盘。
本文由 @酸奶AIGC 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


