
 起点课堂会员权益
起点课堂会员权益大众点评的评分正在”通胀”——AI时代,消费决策的底层逻辑正在被重写
从一个4.8分和4.5分的餐厅之争说起,拆解一个延续20年的产品范式为何走向失灵,以及大模型将如何改变"看评价"这个动作本身。

一、一个所有人都在经历、却没人说破的产品悖论
周六晚上七点,你和朋友约了饭。打开大众点评,搜索”川菜”,跳出来的结果清一色4.5分以上。你点进第一家,4.8分,评价里写着”菜品精致””环境不错””服务态度好”。你再点进第二家,4.6分,评价里写着”味道很赞””装修有格调””下次还来”。你翻了三十条评价,关掉App,发现自己依然不知道哪家更适合今晚的局——是那种能大声聊天的朋友局,不是那种需要拍照发朋友圈的精致局。
这个场景,几乎每个都市人每周都在经历。
我们以为自己在”做决策”,其实只是在”翻信息”。翻了一圈之后,决策质量并没有提高,焦虑感反而增加了。这不是你的问题,也不是大众点评不够努力。这是一个产品逻辑层面的结构性困境——当所有商家的评分都挤在4.5到5.0这个狭窄区间里,当评价内容高度同质化,”评分”这个曾经无比高效的决策工具,正在丧失它最核心的功能:帮你区分好坏。
换一个更尖锐的说法:评分越来越高,评分越来越没用。
这篇文章想拆解的,正是这个悖论背后的产品逻辑:持续了二十年的”看评分→翻评价→做决策”这条用户路径,为什么正在系统性地失灵?而AI大模型的出现,是否意味着这条路径本身即将被重写?
二、回到原点:大众点评评分体系的”天才设计”
要理解评分为什么在失灵,得先理解它为什么曾经如此成功。
2003年大众点评上线时,它面对的是消费领域一个古老而根本的问题:信息不对称。你站在一条美食街上,面前有二十家餐厅,你对它们一无所知。传统的解决方案是什么?问朋友、看招牌、凭直觉——全是低效手段。
大众点评的评分体系,本质上是用产品化的方式,构建了一套”去中心化的消费信任体系”。它的设计有三层精妙之处。
第一层是数字评分。用一个1到5的数字,把复杂的消费体验压缩成一个可以瞬间理解的信号。你不需要读任何文字,看一眼4.8和3.9,就能做出初步判断。这极大地降低了认知门槛。
第二层是文字评价。数字只能告诉你”好不好”,文字能告诉你”好在哪里”。”他家的毛血旺是招牌””服务员响应很快但上菜慢”——这些信息让你的决策从粗筛进入精选。
第三层是图片评价。文字可以造假,但图片的造假成本高得多。一张实拍的菜品照片、一张店内环境照,提供了文字无法替代的体验感知。
这三层结构叠加在一起,让陌生人之间第一次可以通过一个产品建立消费信任。你不认识写评价的人,但你愿意相信一千个陌生人的集体判断。这种”社会证明”机制,是大众点评得以成长为国民级应用的根基,也是过去二十年消费决策领域最经典的产品范式之一。
但经典范式之所以是”经典”的,恰恰因为它属于一个特定的时代。
三、评分”通胀”:一个经典设计的系统性失灵
评分体系的失灵不是某一个环节出了问题,而是四重底层逻辑同时发生了结构性坍塌。
第一重:信息密度悖论。
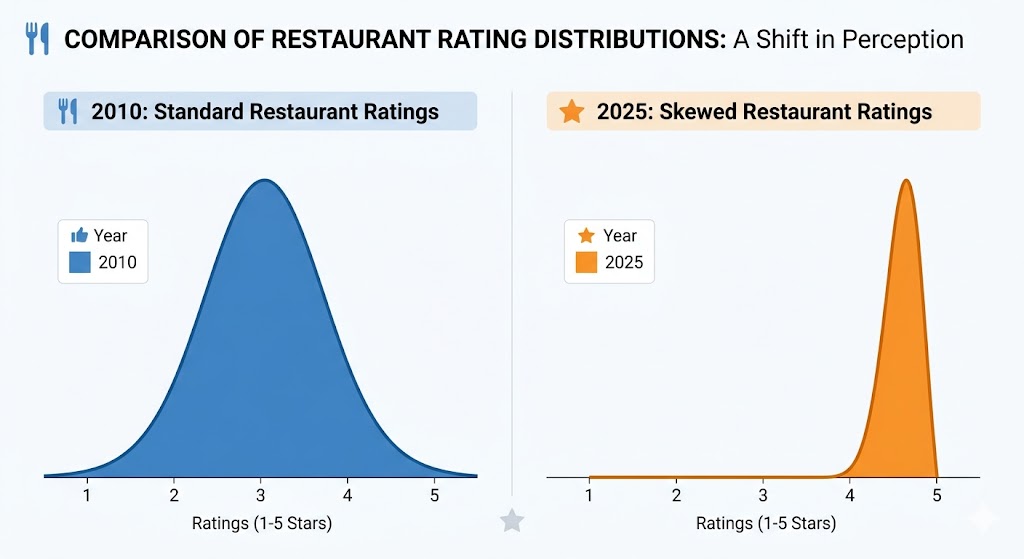
大众点评2025年数据显示,全年累计收到近4.5亿条用户评价,覆盖境内外近903万家商户。这个数字看起来是繁荣,但从产品逻辑看却暗藏危机。
当一家餐厅只有10条评价时,每条评价都携带大量信息增量——你可以从中快速拼出这家店的全貌。但当评价增长到5000条时,第5001条评价对你的决策贡献趋近于零。你不可能读完5000条评价,而排在前面的”精选评价”又高度同质化。用户面对的不再是”信息不足”,而是”信息过载”。产品解决的问题变了,但产品形态没变。
第二重:均值回归陷阱。
这是一个博弈论的问题。当评分成为大众点评流量分配的核心权重,每个商家的理性策略就是”至少把评分刷到和竞争对手一样高”。你4.5,我也必须4.5;你4.7,我就得想办法到4.8。结果是,整个评分分布从早期的正态分布,逐渐被压缩到4.5-5.0这个极窄的区间里。区分度坍缩了。4.8分和4.5分之间,到底差多少?答案是:在统计学意义上可能有差异,但在用户体验层面,这个差异已经无法感知。评分变成了”入场券”而非”区分器”。
第三重:人类评价的心理学偏差。
行为经济学中有一个被反复验证的现象:人在做评价时,天然倾向于极端化表达。非常满意的消费者会主动写长评,非常不满的消费者会写差评泄愤,而大量”还行””一般””凑合能吃”的中间体验——恰恰是最真实、最有参考价值的部分——被系统性地忽略了,因为这些消费者没有足够的动力去写评价。评价样本本身就是偏斜的,基于偏斜样本计算出的评分,当然不准。
第四重:激励扭曲的死循环。
大众点评2025年评价透明度报告披露了一组触目惊心的数字:全年处置违规评价2557万条,警告违规商户超71万家,处罚超8.7万家;全年治理AIGC评价(AI生成的评价)1161万条。仅仅一年,就有近四千万条”有毒”评价流入系统。
这不是道德问题,这是机制设计问题。当评分直接决定流量和收入,而造假的成本远低于造假的收益,虚假评价就不是个别商家的”违规”,而是整个系统的”最优策略”。你可以惩罚个体,但你无法通过惩罚消灭一个由激励结构本身催生的行为。
四重逻辑叠加在一起,构成了一个悲观的结论:评分体系的失灵不是”管理不善”,而是”范式过期”。
四、为什么所有”打补丁”的方案都注定撞墙
必须公允地说,大众点评在对抗评分失灵这件事上投入了巨大资源,而且做出了不少有效动作。
2025年,大众点评将评价审核从四道防线升级至五道,引入AI智能体辅助人工审核,以千万级商家信息作为”信息底座”交叉验证评价真实性。同年升级星级评分规则,从”处罚造假”转向”正向牵引”——专注品质的商家更容易获得星级提升,依赖促评的商家则受到限制。数据显示,新规实施半年后,高强度促评商户数下降42%,用户对评价真实性的负面反馈下降27%。
这些努力值得尊重。但我想说一句可能不太舒服的话:这些方案的上限,在它们被设计出来的那一刻就已经被锁死了。
原因很简单。所有这些方案——无论是AI辅助审核、加权评分、黑名单机制,还是”优质评价”标签——都建立在一个隐含假设之上:用户会阅读评价,并自主完成信息萃取和判断。
但这个假设正在失效。
用户的注意力是有限的、是昂贵的。当信息噪声超过认知处理阈值,再精细的筛选和过滤都无法挽救一个”需要用户自己做苦力”的产品架构。这就像你可以不断优化一本电话黄页的排版、索引、分类方式,但你无法改变一个事实:用户已经不想翻电话黄页了。
问题不在黄页的质量,在于”翻黄页”这个交互范式本身过时了。
五、AI带来的不是”升级”,是范式跃迁
现在,让我来说这篇文章最核心的判断。
传统评分体系的本质,是一种有损压缩。它把千差万别的消费体验——口味、环境、服务、等位时间、适合的人群、适合的场景——压缩成一个数字:4.5分。这个压缩过程必然丢失大量信息。而且,压缩出来的结果是”去场景化”的——它不关心你是一个人吃工作餐还是带父母吃生日宴。
大模型的能力,恰好是反过来的。它不做压缩,它做展开——理解非结构化的海量文本,识别其中的模式、情感、细节,然后基于你的具体需求,生成个性化的决策建议。
这让AI能做到三件评分体系根本做不到的事。
第一,语义级的评价萃取。
AI不是在”算平均分”,它是在”读懂一千个人的真实体验”。它可以从海量评价中识别哪些是水评、哪些是利益交换评价、哪些是真实的消费反馈。更重要的是,它可以提取出人类快速浏览时无法捕捉的细粒度信息——”多位评价者提到周末晚市等位超过40分钟””近三个月有关服务态度的负面反馈显著增加””素菜选择较少,不太适合素食者”。
有意思的是,大众点评自己的用户调研显示,七成用户认为AI生成的评价”华而不实””信息不准确”。但这恰恰说明了一件事:AI的能力应该用在**”读评价”这一侧**,而不是”写评价”那一侧。让人类写真实的体验,让AI去读懂和提炼——这才是正确的分工。
第二,场景化的需求匹配。
同一家餐厅,对不同的人、不同的场景,价值完全不同。一个带着三岁孩子的妈妈关心的是”有没有儿童座椅””会不会太辣””服务员对小孩有没有耐心”;一对约会的情侣关心的是”灯光是不是太亮””桌间距够不够私密””适不适合拍照”。
评分是一刀切的——4.8分对妈妈和情侣是同一个4.8分。但AI可以基于你当下的具体需求做语境化推荐。你说”今晚想找个能大声聊天、人均别超过150的地方”,AI可以从评价文本中提取”环境嘈杂度””消费水平””适合聚会”等维度,给出一个真正匹配你当下需求的推荐——而不是一个冷冰冰的排序列表。
第三,跨信息源的交叉验证。
大众点评的评分只能反映大众点评生态内的数据。但AI不受这个限制。它可以同时理解社交媒体上的讨论、外卖平台的复购率、地理位置和通勤距离、当天的天气、你过往的消费偏好——然后综合所有维度给出判断。
举个例子:一家评分4.5的露天烧烤店,在大众点评的评分体系里,它和其他4.5分的店没有区别。但如果AI知道今天北京下雨,它就不会推荐这家店给你。这种”常识级推理”是评分体系根本无法承载的。
所以我的核心结论是:AI带来的不是“评分体系的升级版”,而是一个完全不同的消费决策范式。 从”信息呈现+用户自行判断”,变成”需求理解+AI推理+可解释推荐”。从用户做苦力,变成AI做苦力。
六、产品重构猜想:如果大众点评”杀死”自己的评分页
如果上面的判断成立,那大众点评的产品形态应该往哪里走?我做三个层次的推演。
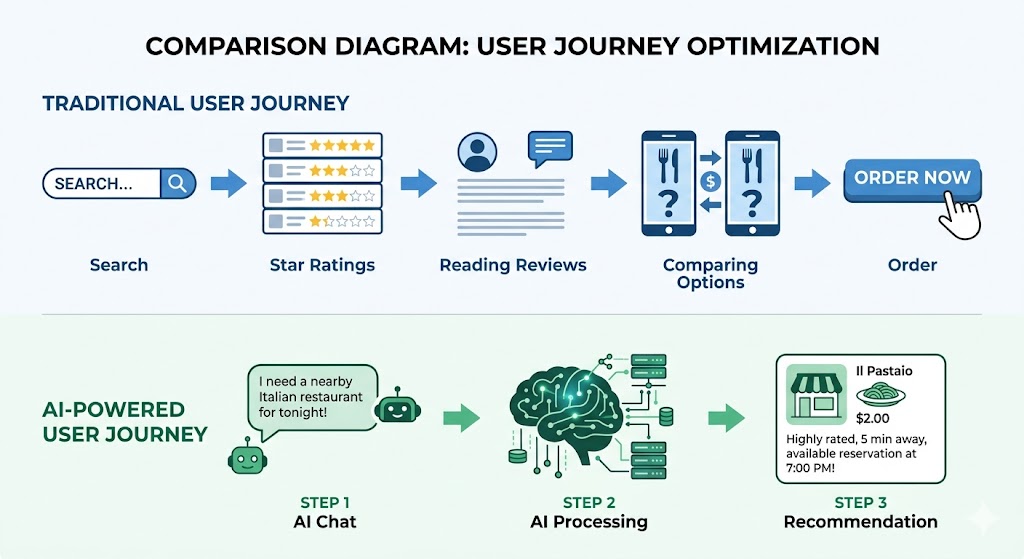
交互层重构:从“搜索+筛选”到“对话+追问”。
目前的交互模式是结构化的——你需要选择品类、设定距离、勾选评分范围、选择排序方式。这个过程本质上是在”将你的模糊需求翻译成机器能理解的参数”。但自然语言交互消除了这个翻译成本。你不需要把”今晚想和三个朋友吃顿好的,不要太远,最好有包间”拆解成五个筛选条件,你直接说出来就行。更重要的是,AI可以追问:”你们几位有忌口吗?””预算大概什么范围?””需要停车位吗?”——这种多轮对话比任何筛选器都高效。
信任层重构:从“社会证明”到“可解释推理”。
传统评分的信任逻辑是”别人都说好,所以好”——这是社会心理学中的从众效应。但这种信任机制的问题在于,你不知道”别人”是谁,不知道他们的偏好是否和你一致,不知道他们的评价是否真实。AI时代的信任逻辑应该变成”可解释推理”——AI告诉你”我推荐这家是因为:评价中67%提到了安静适合谈事情,人均消费在你的预算范围内,距你当前位置步行8分钟,而且最近一个月没有关于卫生问题的投诉”。你不需要相信一个数字,你需要相信一个推理过程。推理过程透明了,信任就建立了。
数据层重构:UGC从“展示内容”变成“训练数据”。
这个转变是最深刻的。过去,用户写评价是”给别的用户看的”;未来,用户写评价首先是”给AI学的”。评价内容的首要角色从”前台展示”变成”后台燃料”。这也解释了一个看似矛盾的现象——大众点评一边在大力推进AI能力,一边在严厉打击AIGC评价。因为AI生成的评价对人类读者来说”看起来挺像那么回事”,但对训练数据来说,它是有毒的噪声。真人写的20个字,哪怕有错别字、有情绪化表达,对AI来说也比一段完美流畅的AI生成文本更有价值。
美团目前正在研发一款覆盖餐饮、酒旅等全服务场景的AI助手。如果这个产品成型,大众点评的核心形态很可能从”评价平台”进化为”个人消费决策Agent”。评分页面不会消失,但它在产品架构中的角色,将从C位主角降为辅助配角。
七、给产品经理的三个启示
最后,从这个案例中提炼三个对产品经理有实际参考价值的思考。
第一,区分“功能层护城河”和“资产层护城河”。
大众点评的评分功能可以被AI更好地替代,但大众点评的护城河并没有因此消失。903万家商户的信息基建、20年沉淀的消费行为数据、用户”吃饭前先打开点评”的心智惯性——这些是资产层的护城河,不会因为评分页面的重要性下降而蒸发。功能层的东西AI可以重做甚至做得更好,但资产层的东西需要时间堆积,这才是真正的壁垒。产品经理必须清楚,自己守的到底是哪一层。
第二,警惕“旧框架内打补丁”的思维惯性。
面对产品失灵,大多数产品经理的第一反应是”优化现有方案”。加个筛选条件,改个排序算法,上个推荐模型——这些都是在旧框架内修修补补。真正需要问的问题是:如果我今天从零开始设计一个解决同样问题的产品,我还会选择”评分+评价”这个方案吗?如果答案是”不会”,那你要做的不是优化,而是重构。
第三,最危险的思维是“我的产品+AI”,最有价值的思维是“AI原生地解决这个问题”。
“在现有的评分页面上加一个AI总结”——这是”产品+AI”的思路,是把AI当工具、当锦上添花的装饰品。”让用户直接和AI对话,由AI完成从需求理解到推荐输出的全过程”——这是”AI原生”的思路,是重新思考产品形态本身。
两种思路的差距,就像在马车上装一个发动机,和直接造一辆汽车的差距。
评分不会死。就像马车没有完全消失一样,它会在某些场景下继续存在——作为一种快速粗筛的辅助手段,作为用户心智中根深蒂固的参考锚点。但作为消费决策的核心产品范式,它的黄金时代确实正在过去。
下一次你打开大众点评,面对满屏4.5分以上的餐厅再次陷入纠结时,不妨想想:也许问题不在于哪家餐厅更好,而在于”用评分选餐厅”这件事本身,已经该换个方式了。
本文由 @Token跳动 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


