
 起点课堂会员权益
起点课堂会员权益具身智能的GPT-3时刻悄悄来了
具身智能正迎来关键拐点!Generalist AI的GEN-1机器人以99%的任务成功率震撼业界,其1小时快速学习能力与1800次连续稳定操作,标志着物理世界数据的Scaling Law首次被商业验证。这场从2%到99%的质变背后,揭示了一个更残酷的竞争逻辑:未来属于那些最先建立垂直场景数据护城河的企业。

具身智能到底值不值得关注,还是又一个PPT行业。
我之前的态度是:方向对,但时间表存疑。
但上周看完Generalist AI发布GEN-1的演示视频之后,我把这个判断改了。
不是因为视频拍得多好看,而是因为里面有三个数字,让我坐直了身子:1小时、1800次、99%。
先说说那个让我坐直的画面
画面里,一台机器人在流水线上打包积木。
不是那种工厂里固定轨道、固定动作的老式机械臂——是那种你给它一个新任务,它自己琢磨,然后开始干的机器人。
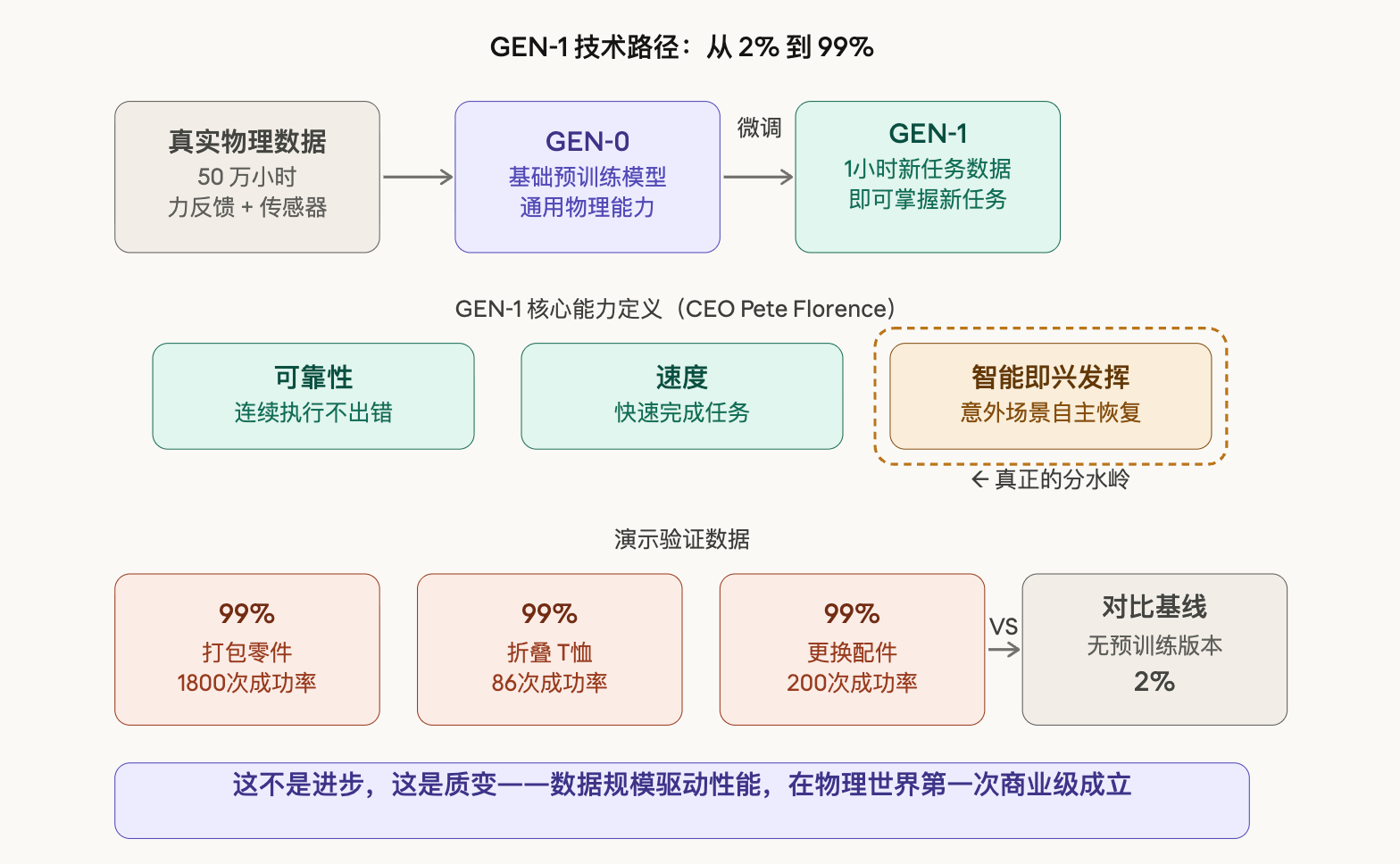
它连续打包了1800次以上,成功率99%。
这个数字乍一看好像还行,但你要知道,它之前是什么水平:同样的任务,没有预训练的版本,成功率是2%。
2%到99%,这不是进步,这是质变。
哎,这事儿就很有意思了。
GEN-1到底做了什么,为什么这次不一样
先说背景。做GEN-1的公司叫Generalist AI,听名字就知道他们想做什么——通用的AI,不是只会一件事的那种。
他们的路径是这样的:先做GEN-0,用50万小时的真实物理交互数据进行预训练。注意,是真实的物理交互,不是仿真,不是视频,是机器人真实动过、感受过力反馈、采集过传感器数据的那种。
然后在GEN-0的基础上,做GEN-1。
GEN-1的核心能力是:给它1小时的新任务数据,它就能掌握这个任务。
掌握是什么意思?公司CEO Pete Florence给了一个定义,我觉得说得很准:可靠性 + 速度 + 智能即兴发挥。
前两个好理解,第三个才是重点——遇到意外场景,能自主恢复。
比如打包到一半,零件位置偏了,它不会卡死,不会报错,它会自己调整,然后继续干。
这个能力,才是真正的分水岭。
演示里还有几个场景:折叠T恤86次、为扫地机器人更换配件200次、自动打包零件连续工作超过1小时。全部成功率99%。
我之前遇到过一些机器人公司的朋友,他们跟我说,工厂里最怕的不是机器人慢,是机器人卡。卡一次,整条产线停,损失是按分钟算的。99%的成功率意味着什么,他们比我更清楚。
为什么以前机器人这么笨——问题根本不在硬件
这里有一个很多人没想清楚的点。
过去十几年,大家一直觉得机器人做不好是因为硬件不行——关节精度不够、传感器不灵敏、算力不足。
但其实核心就一件事:没有足够的物理世界数据。
大模型为什么这么厉害?因为互联网上有海量的文本数据,几乎人类写过的所有东西都在里面。你喂给模型,它就能学会语言的规律、知识的结构、推理的逻辑。
但机器人的数据从哪来?
物理世界的数据不能爬。每一个动作,都需要真实的物理交互——机器人要真的伸出手,真的抓住东西,真的感受到力的反馈,传感器真的记录下来。一个动作几秒钟,50万小时的数据,你算算要花多少时间、多少台机器、多少人力去采集。
这就是具身智能最大的瓶颈,不是算法,是数据。
GEN-1做的事情,本质上是第一次在商业级别证明:物理世界的数据,同样能驱动机器人能力的可预测提升。
这句话听起来平淡,但在机器人领域,这是一个悬而未决了很多年的问题。
Scaling Law,一个改变了AI格局的规律
稍微解释一下Scaling Law这个概念,因为它是理解这件事的关键。
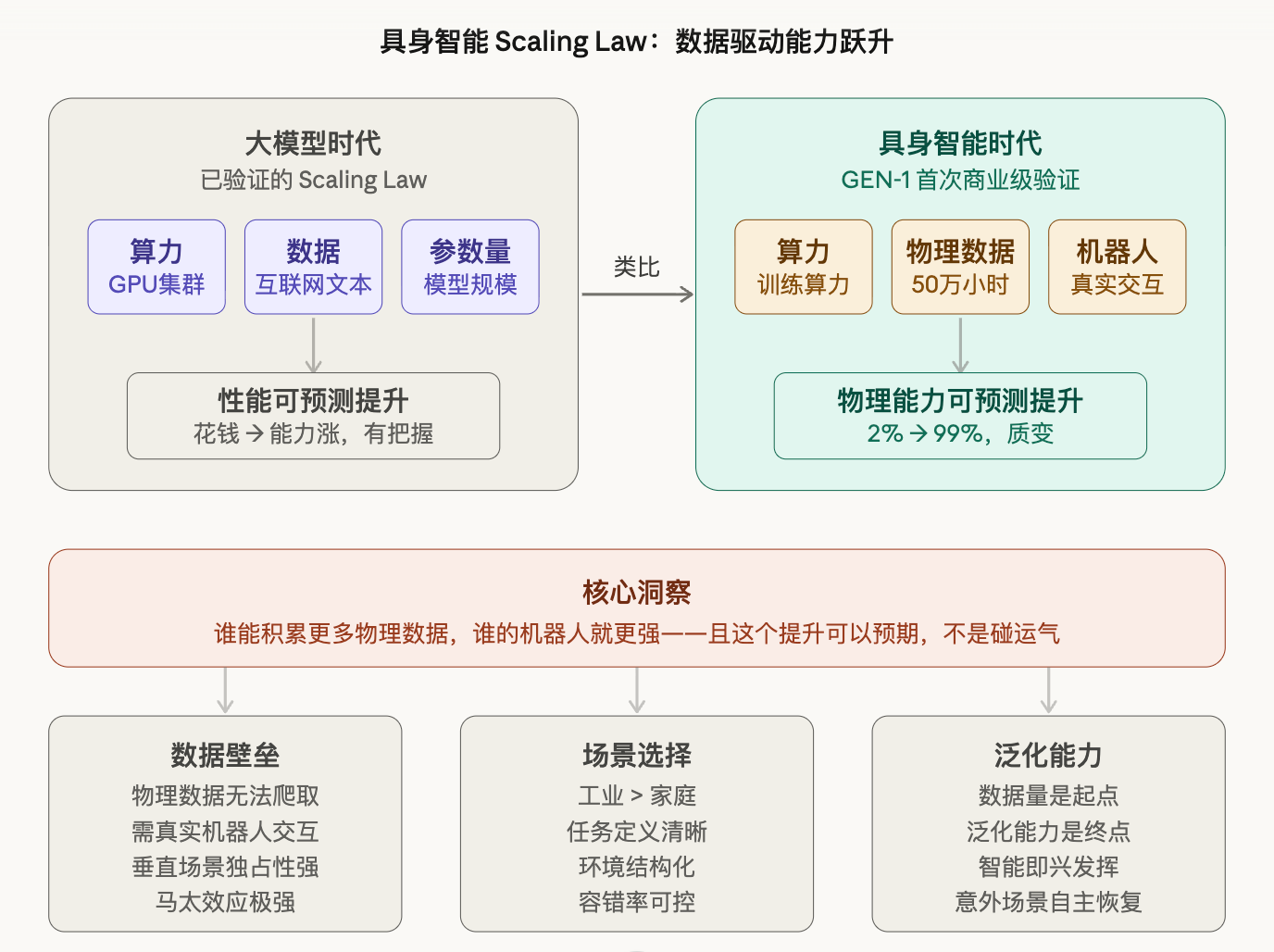
大模型领域有一个被反复验证的规律:算力、数据、参数量,三者同步扩大,模型性能会可预测地提升。 不是随机的,不是玄学,是可以用公式描述的。
正是因为这个规律,OpenAI、Anthropic这些公司才敢砸几十亿美元去训练模型——他们知道钱花下去,性能会涨,这是有把握的事。
但具身智能有没有自己的Scaling Law?
这个问题在2026年之前,没有人能给出确定的答案。有人觉得有,有人觉得物理世界太复杂、变量太多,Scaling Law不成立。
GEN-1的出现,给出了第一个商业级别的正面回答。
这意味着什么?意味着接下来,谁能积累更多的物理数据,谁的机器人能力就会更强——而且这个提升是可以预期的,不是碰运气。
这个逻辑一旦成立,整个行业的竞争逻辑就变了。
2026年的具身智能,像极了2020年的GPT-3
GPT-3出来的时候,大多数人的反应是:挺厉害的,但好像也没什么用。
当时能做的事情,写个段子、接龙、简单问答,看起来像个高级玩具。
然后两年后,ChatGPT出来了。
我觉得GEN-1可能是同一个时刻。
不是说GEN-1已经是终态,而是说它完成了一件关键的事:证明了这条路是通的。 数据规模驱动性能,在物理世界成立了。
同期的行业信号也在佐证这一点。
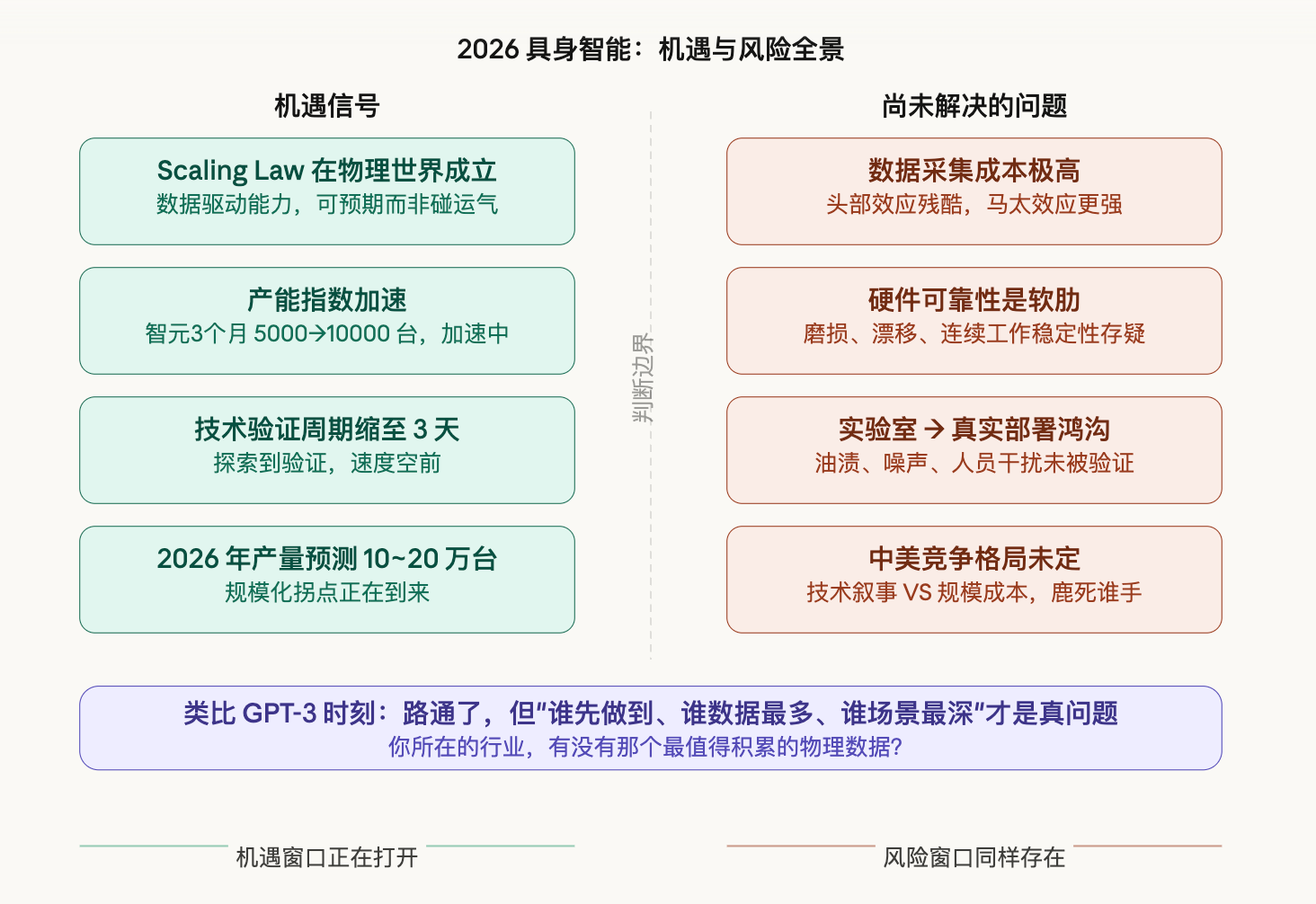
今年3月30日,智元机器人(Agibot)生产了第10000台人形机器人。从5000台到10000台,只用了三个月。产能在加速,不是线性加速,是指数加速。
同样是3月,全球首届具身智能开发者大会在深圳召开。有一个细节让我印象深刻:有人提到,现在一个新的技术方向,从探索到验证,周期已经缩短到3天。3天。
国内的预测是,2026年人形机器人产量将达到10万到20万台量级。
这些数字叠在一起,你能感受到那种加速的气息。
数据是新的护城河——这是我认为最值得认真对待的判断
说到这儿,可能有人会问:那我能从这件事里拿到什么?
我觉得最有价值的判断是这个:在具身智能时代,数据是真正的护城河,不是算力,不是模型。
大模型时代,算力可以租,模型可以开源,最难复制的是数据。但文本数据相对好办,互联网上有的是。
具身智能的数据壁垒更高。你在某个工厂场景里积累的10万次操作数据,别人没有。你的机器人在某条产线上跑了半年,积累了各种异常情况的处理经验,这些数据是你独有的。
谁先在垂直场景里跑起来,谁就在建一道后来者很难翻越的墙。
那什么场景最值得先切入?
我的判断是:工业场景,不是家庭场景。
工业场景的优势在于边界清晰——任务是定义好的,环境是相对结构化的,重复性高,容错率相对可控。这正好符合当前具身智能的能力边界。
家庭场景是另一回事。你家里的情况,跟我家里的情况不一样,跟他家里的情况也不一样。变量太多,部署成本高,用户期望复杂——奶奶摔倒了机器人没反应,这个负面新闻比一百条好新闻杀伤力都大。
2026年,专注一个工厂、一条产线、一类零件,比做”通用家用机器人”靠谱得多。
还有一点值得说:任务泛化能力,将成为第二道壁垒。
光有数据还不够。GEN-1展示的”智能即兴发挥”——遇到意外场景能自主恢复——本质上是一种泛化能力。从一个任务迁移到相邻任务的能力。
未来创业公司的差异化,不只在于”我有多少数据”,还在于”我的数据训出来的模型,能泛化到多大的任务范围”。数据量是起点,泛化能力是终点。
但先别太乐观——有些问题真的还没解决
我不想把这篇文章写成纯粹的鼓吹。
有几个问题,我觉得必须说清楚。
数据采集成本依然极高。 50万小时的真实物理数据,不是每家公司都有能力积累的。Generalist AI能做到,是因为他们在这件事上投入了大量资源和时间。头部效应会非常明显——有数据的公司越来越强,没数据的公司越来越难追。这个马太效应,在具身智能领域会比大模型领域更残酷。
硬件可靠性是软肋。 软件能力再强,机械结构的磨损、传感器的漂移、关节的疲劳,仍然是商业化落地的硬约束。一台机器人在实验室里跑得很好,放到真实工厂里连续工作三个月,会发生什么,现在还没有足够的数据。
从实验室到真实部署,有一道很深的鸿沟。 GEN-1的演示环境相对结构化,光线、温度、零件摆放都是可控的。真实工厂的情况是:地面有油渍,零件有毛刺,工人会突然走过来,噪声会干扰传感器。这些变量,是另一个量级的挑战。
中美竞争格局还没有定。 Generalist AI在技术叙事上领跑,但中国公司——智元、宇树、傅利叶——在产量和成本上正在快速追近。技术先发优势能维持多久,规模化生产的成本优势又价值几何,这场竞争的结果,现在真的还看不清楚。
最后,我想问你一个问题
GPT-3出来的时候,大多数人觉得”挺厉害的”,没几个人意识到两年后会发生什么。
GEN-1可能是同一个时刻。
数据规模驱动性能,在物理世界成立了。接下来的问题不是”能不能做到”,而是”谁先做到”、”谁的数据最多”、”谁的场景最深”。
这场竞争,刚刚开始。
所以我想问你:你所在的行业,有没有那个最值得积累的物理数据?
如果有,现在可能是开始认真想这件事的时候了。
本文由 @酸奶AIGC 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


