
 起点课堂会员权益
起点课堂会员权益Gemma 4 爆火背后:开源 AI 的权力,正在换手
Gemma 4的发布不仅是一次技术升级,更是一场开源生态的格局重塑。Google DeepMind这次用端侧优化与Apache 2.0许可证的组合拳,彻底打开了手机AI与隐私敏感场景的潘多拉魔盒——5.5GB的E4B模型支持离线多模态处理,31B旗舰版以标准开源协议降低企业部署门槛。当阿里收紧API权限时,Google正用生态思维改写AI竞赛规则。

一、4月第一周,发生了什么
4月2日,Google DeepMind 正式发布了 Gemma 4。发布前两天,Hassabis 在 X 上发了四个钻石 emoji,其他什么都没说。Google 技术团队的 Logan Kilpatrick 发了一个字:”Gemma”。AI 圈的人看到这两条推文,就知道要有大动作了。
发布当天,Gemma 4 在48小时内登上了 Arena AI 开源模型榜第三位。Jeff Dean 在发布帖子里提到,Gemma 系列自第一代发布以来,开发者下载量已经超过4亿次,社区衍生出超过10万个变体版本。这个数字,放在任何一个开源项目里都是惊人的。
同一天,阿里巴巴发布了 Qwen3.6-Plus。两家在同一天出牌,不是巧合。这一周,是2026年开源 AI 最拥挤的一周。但大多数讨论,还是停在跑分上——这个榜第几,那个 benchmark 多少分。我觉得这些都是表面。这篇文章想说的,是跑分之外的两件事:第一,端侧 AI 这次是真的来了。第二,Google 这次是真的开放了。
这两件事加在一起,意味着一个产品机会窗口正在打开。
二、Gemma 4 是什么:四个尺寸,两个故事
Gemma 4 这次发布了四个版本:E2B、E4B、26B MoE、31B Dense。听起来像是四个产品,但我更愿意把它理解成两个故事。
第一个故事:手机里的 AI
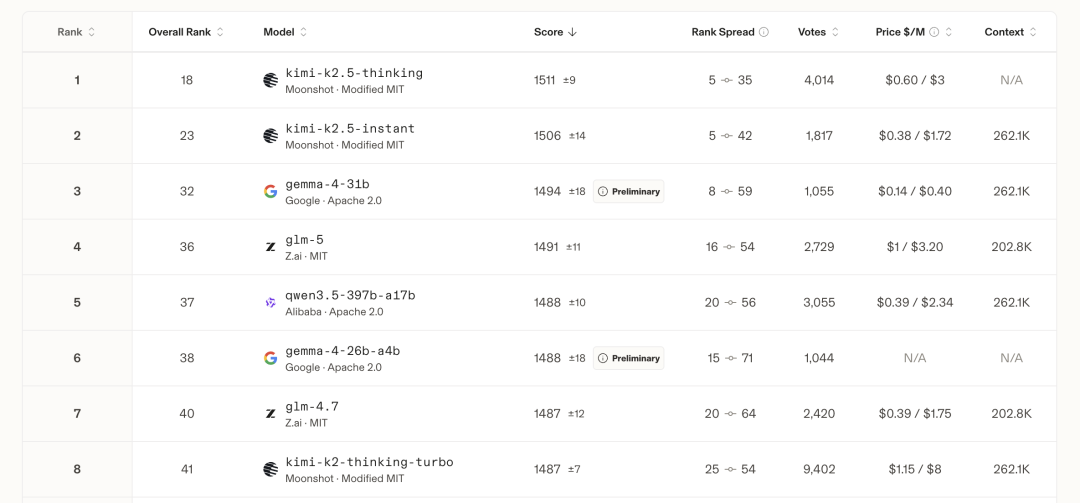
E2B 和 E4B,名字里的”E”代表”Effective”,有效参数。E4B 有效参数45亿,总参数约81亿。但推理时只用到45亿那部分——意味着它跑起来所需要的算力和内存,更接近一个4B的小模型,而不是8B的大模型。这个设计的意义是:它能塞进手机。
根据 Unsloth 的实测数据,E4B 在4比特量化下只需要约5.5GB内存,在 MacBook M4 Pro 24GB 上跑出了57 tokens每秒的速度。E2B 更小,只需约3.6GB,速度可以到95 tokens每秒。速度是什么概念?人类阅读速度大约是每分钟300到500个字,57 tokens每秒换算下来大概是每分钟三千多个中文字——比你读的速度快六到十倍。对话场景下,这已经是真正流畅的体验。
更关键的是:完全离线。Google 在发布时明确说明,E2B 和 E4B 与 Qualcomm、MediaTek 和 Google Pixel 团队深度联合优化,专门为手机、树莓派、NVIDIA Jetson Orin Nano 这类边缘设备设计。数据不上云,推理在本地完成,网络好不好,对它没有影响。
它还支持图像输入、音频输入,以及超过140种语言。一个5.5GB的模型,能看图、能听说话、支持140种语言、完全离线跑——这件事,在一年前是不可能的。
第二个故事:工作站上的主力模型
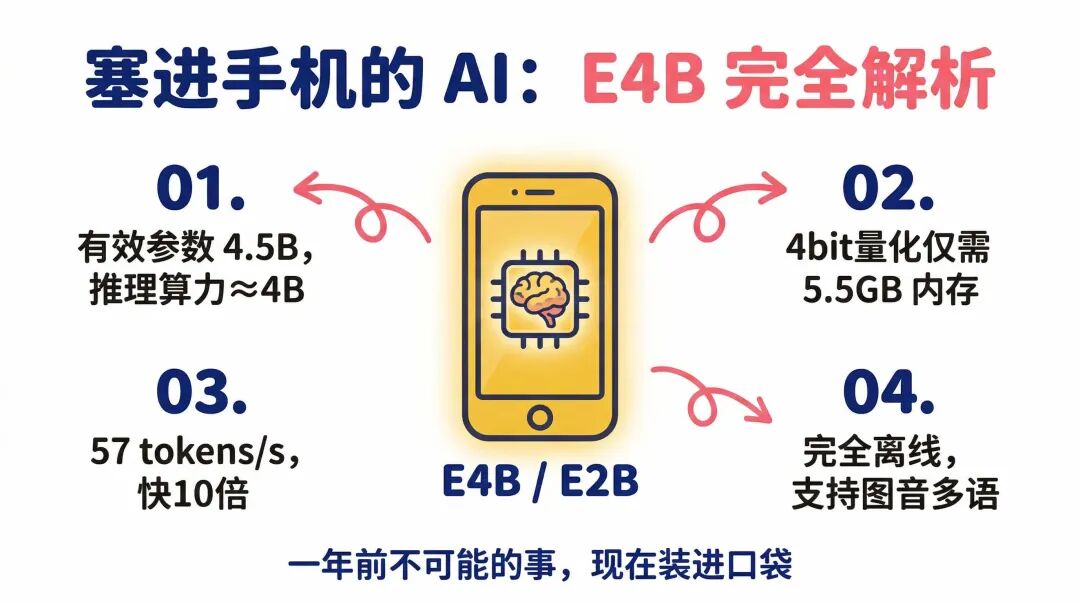
26B MoE 和 31B Dense,是给开发者和企业用的。31B Dense 是旗舰,在 Arena AI 开源模型榜排名第三,胜过了许多参数量是它20倍的对手。26B MoE 是效率版。MoE 是 Mixture of Experts 的缩写——混合专家架构。它的总参数是26B,但每次推理时只激活其中约3.8B的参数。
你可以这样理解:它拥有26B的知识储备,但每次回答只调用其中一小部分。就像一个博士,不会把所有知识都塞进每一句回答里,而是按需调取。结果是推理速度更快,显存占用更少,跑分和31B相差不大。
两个大模型都支持最长256K token的上下文窗口。256K token大约是40万到50万个中文字,相当于一部中等长度的小说。整个代码库、整份合同、整本报告,一次性扔进去,不需要分段。在硬件要求上,未量化的版本需要一张80GB的 H100——这是专业级配置。但量化后,消费级显卡也能跑起来:26B MoE 在4比特量化下约需18GB,31B Dense 约需20GB。一台配了高端显卡的工作站,够了。
三、为什么偏偏是现在:端侧 AI 真正落地的两个条件
端侧 AI 这个词,已经被说了好几年了。每次有人说”AI 要跑在手机上”,紧跟着就是一堆限制条件:能力不够、太慢、太大、耗电太快、只能做简单任务。这些限制,不是没有道理。它们是真实存在的工程问题。但 Gemma 4 E4B 的出现,让我觉得这个局面开始松动了。不是说所有问题都解决了,而是说:卡住端侧 AI 的三个核心卡点,这次同时被突破了。
卡点一:算力
之前的端侧模型,要么太慢,要么太耗电,要么两者兼有。E4B 之所以能在手机上跑得快,是因为它从架构层面就是为端侧设计的——不是把大模型压缩后硬塞进去,而是一开始就面向边缘设备的算力约束来设计和训练。结合 Qualcomm 和 MediaTek 的芯片优化,E4B 在主流安卓旗舰上能实现接近实时的响应速度。
卡点二:体积
之前能在手机上跑的模型,能力太弱;能力够强的模型,体积又太大。E4B 量化后约5.5GB——一部高清电影的大小。对于现在动辄256GB存储的旗舰手机来说,这不是问题。更重要的是,5.5GB的体积里,装进了图像理解、音频处理、140种语言、指令跟随、函数调用的能力。这个密度,是之前的端侧模型做不到的。
卡点三:能力
这是最核心的。之前端侧模型能做的事,本质上是”比较聪明的自动补全”。Gemma 4 E4B 在多项基准测试上,超过了 Gemma 3 的27B版本——一个比它参数量大六倍的模型。这意味着:现在跑在你手机上的 AI,实际能力已经超过了一年前只有服务器才能跑的中型模型。
端侧落地之后,打开的是什么?
我觉得端侧 AI 是接下来两年最值得产品人关注的方向之一。不是因为它现在有多成熟——它有很多问题还没解决。而是因为它第一次让”本地跑”从工程师的玩具变成了真实的产品选项。
具体来说,有三类场景,之前完全做不了,现在开始可以认真想:
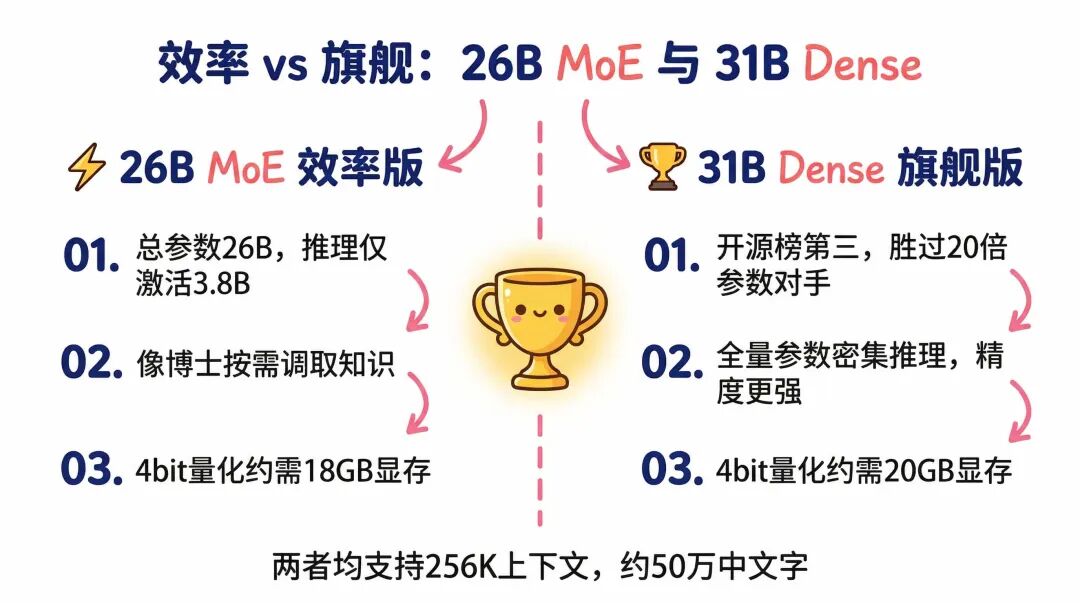
场景一:隐私敏感类产品
医疗问诊 App、企业内部知识库助手、法律文件分析工具。这类产品一直有一个死结:用云端 AI,数据要上传,合规风险很高;不用 AI,产品没有竞争力。
端侧模型直接解开这个死结。数据不出设备,不经过任何服务器,没有传输,没有存储,没有泄露风险。这不是技术参数的变化,是合规边界的变化。医疗和法律这两个行业,数据主权一直是云端 AI 进不去的门槛。端侧让这扇门开了一条缝。
场景二:离线场景
工厂车间、建筑工地、偏远地区、飞机上。这些场景有个共同点:网络不稳定,或者根本没有网络。之前所有依赖云端的 AI 工具,在这些场景里都是摆设。
端侧模型不需要网络。AI 变成了一个真正跟你走的工具,而不是一个需要连接才能用的服务。在工业检测、设备维护、野外作业这些场景里,这个差别是决定性的。
场景三:深度个性化
模型跑在本地,理论上可以真正记住你——你的习惯、你的偏好、你的上下文历史——而不是每次对话都从零开始。云端 AI 在这件事上有天然的劣势:数据在服务器上,个性化能力受限于隐私政策和数据孤岛。本地模型没有这个限制。未来真正能做到”了解你”的 AI 助手,很可能不是跑在云端的,而是跑在你设备上的。
AI 研究者 Nathan Lambert 在 Interconnects AI 上说过一句话,我觉得说到点子上了:开源模型的成败,从来不是发布日的跑分决定的,而是被用起来的生态决定的。端侧恰好是最难被云端替代的生态位。在这里站稳脚跟的开源模型,比在服务器上跑的开源模型,更难被替换。
这个判断我很认同。端侧不是一个细分市场,它是一种不同的权力结构:用户控制数据,用户控制模型,用户控制 AI 能做什么。这和云端模式的底层逻辑完全不同。
四、Apache 2.0:一件被严重低估的事
现在说第二件事。
2026年1月,一个做保险理赔工具的开发者,和团队开会讨论用哪个开源模型。他们测试了 Gemma 3,性能不错,对结构化输出任务很合适。然后有人问:许可证怎么样?十分钟后,他们放弃了 Gemma 3,转向了 Qwen。不是因为 Qwen 更好,是因为 Qwen 的许可证更简单。
这个故事来自独立开发者博客 mayhemcode.com 的作者,他在 Gemma 4 发布后写道:他认识的好几个开发者团队,都经历过类似的过程。Gemma 的性能够用,但那份自定义许可证让合规团队头疼,让法务审查拖延,最后很多团队直接绕开了 Gemma。4月2日,Gemma 4 发布,许可证换成了 Apache 2.0。
为什么许可证这件事,比听起来重要得多?
如果你没在企业里推过开源模型,可能很难理解这件事有多大。开源模型进企业,卡住团队的往往不是技术能力,而是法务。自定义许可证意味着:你需要让法务团队专门审查这份协议,需要评估哪些条款有风险,需要确认商业使用的边界在哪里,需要等待。
这个等待,可能是几周,也可能让整个项目搁置。Apache 2.0 没有这个问题。它是软件行业用了几十年的标准许可证。可以修改、可以商用、可以重新分发,不需要解释,不需要审批。技术团队不用等法务,直接做决定。
用那个开发者的话说:Apache 2.0 是他们其他所有开源依赖已经在用的许可证。选 Gemma 4 的决定,因此从一个法律问题变成了一个技术问题。
开源格局里,许可证是什么分水岭
我简单对比一下现在主流开源模型的许可证情况:
Qwen 系列和 Mistral 系列,都是 Apache 2.0。之前的 Gemma 3 用的是 Google 自定义许可证,有商业使用限制,条款需要专门解读。Llama 4 是 Meta 自定义的社区许可证,有月活跃用户数量上限,超过一定规模需要额外申请。
Gemma 4 现在是 Apache 2.0,和 Qwen、Mistral 站在了同一条线上。这是 Gemma 系列第一次用 OSI 认可的标准开源许可证。
VentureBeat 在报道 Gemma 4 时做了一个观察,我觉得值得记一笔:就在 Google 往更开放的方向走的同时,阿里巴巴 Qwen 系列的部分旗舰型号开始走向 API-only——只提供 API 访问,不完整开放模型权重。Qwen3.6-Plus 目前就是这种形式:可以通过 API 调用,但完整权重还没开源。
中美两家在开源这件事上,路线正在悄悄对调。这背后的逻辑不难理解:开源会让竞争对手直接拿走你的模型。当能力足够强的时候,开源的代价就变大了。阿里选择在能力到达一定水位后收紧;Google 选择在这个节点往开放走,用开放换生态。
哪条路对?现在还不知道。但我自己的判断是:Google 这次是真开放了。Apache 2.0 不是技术升级,是 Google 第一次承认,开发者才是模型未来的主人。
研究者 Sebastian Raschka 在分析中特别提到:Apache 2.0 许可证这件事”不应该被低估”——对于整个开源生态来说,许可证的门槛往往比能力的差距更难跨越。Gemma 4 跨过去了。

五、开源格局:Gemma 4 在哪个位置
说完 Gemma 4 自身,我想帮你建一个简单的认知框架:现在的开源模型格局是什么样的,Gemma 4 处于哪个位置。
Qwen3.5 / Qwen3.6-Plus(阿里)
Qwen 系列目前在编程和 Agent 工作流方向走得最深。Qwen3.6-Plus 主打”Agentic Coding”——代理式编程。它能分解复杂的工程任务,自主写代码、测试、调试,循环执行,直到完成。在 SWE-bench 这个代码工程基准测试上,Qwen3.6-Plus 的得分已经能和 Claude Opus 4.5 相比。
它的上下文窗口是100万 token,可以一次性放入整个代码仓库。代价是:旗舰版目前只有 API 访问,模型权重不完整开放。适合重度代码工作流,但对企业自部署不太友好。
Llama 4(Meta)
Llama 4 的 Scout 版本上下文窗口达到1000万 token,是目前开源模型里最长的。整个大型代码库、几百万字的文档集合,一次性放进去没有问题。
但 Meta 的许可证对大规模商用有限制——月活跃用户超过一定数量需要单独申请授权。这对大多数公司不是问题,但对某些场景是限制。
Mistral
Mistral 的优势在轻量和工具链成熟。小模型跑得很好,社区支持稳定,微调路径清晰。多语言和多模态是相对弱项。
Gemma 4
Gemma 4 的差异化不在某一项单独能力,而在一个组合:端侧优化 + 140种语言 + Apache 2.0 + 与 Google 生态的深度集成。它不是每项都最强,但它是最容易被用起来的。
特别是在三个细分场景里:需要本地跑的、面向全球多语言市场的、需要干净许可证的企业部署。在这三个方向上,Gemma 4 目前没有对手能同时满足全部条件
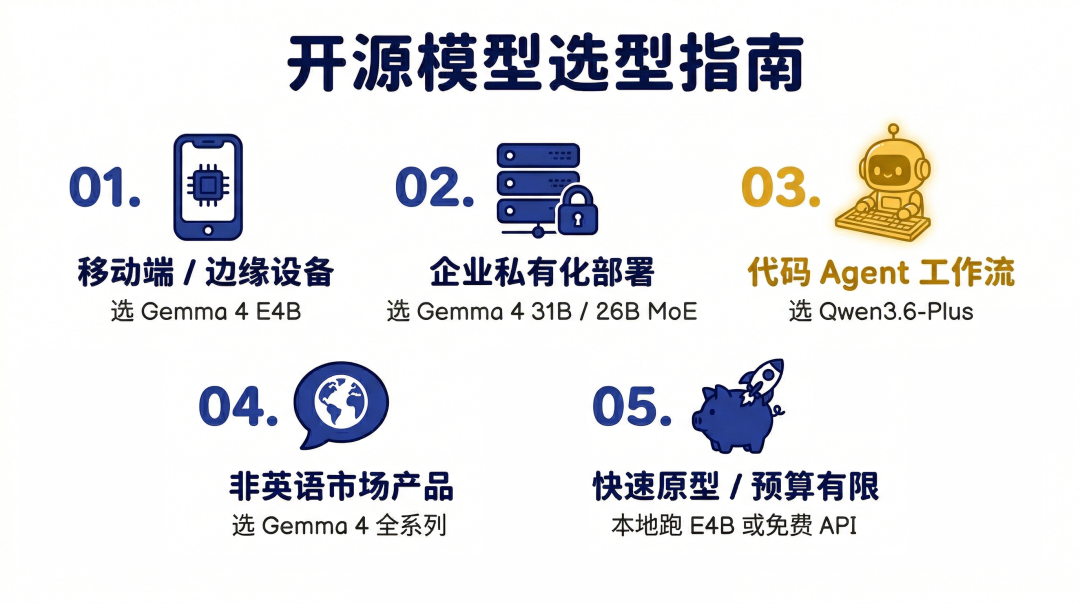
六、你的场景,该怎么选
说了这么多,落到实际,怎么选?
我把常见的场景拆开,一个一个说。
场景一:做移动端或边缘设备 App
选 Gemma 4 E4B。
理由:它是目前唯一一个同时满足”够小、够快、多模态、完全离线、Apache 2.0″这几个条件的模型。Google 和 Qualcomm、MediaTek 的深度合作,意味着在主流安卓芯片上有专门的性能优化,不是其他模型量化后硬跑能比的。模型约5.5GB,24GB内存的 Mac 或主流安卓旗舰都能跑。
场景二:企业内部私有化部署
选 Gemma 4 31B 或 26B MoE。
理由:Apache 2.0 许可证终结了法务审查的问题。31B 是最强版本,量化后约需20GB显存。26B MoE 性能接近,速度更快,量化后约需18GB,性价比更高。两个版本都支持256K上下文窗口,处理长文档、长合同、大型代码库没有问题。
场景三:代码 Agent、自动化工程工作流
选 Qwen3.6-Plus。
理由:这个场景 Gemma 4 暂时不是最优选。Qwen3.6-Plus 的100万上下文、原生 Agent 编程能力,更适合需要模型主动跑代码、执行工作流的场景。注意:这是预览版,数据会被用于模型改进,正式版定价还未公布。
场景四:产品面向非英语市场
选 Gemma 4 全系列。
Gemma 4 的140种语言是原生训练的,不是翻译模型加持的。社区测试显示,在德语、阿拉伯语、越南语、法语等非英语任务上,Gemma 4 的表现明显优于同等参数规模的其他开源模型。如果你的产品要服务东南亚、中东、非洲市场,这一点值得重视。
场景五:快速原型,预算有限
选 Gemma 4 E4B 本地跑,或者 Qwen3.6-Plus 的免费 API。Gemma 4 E4B 本地跑,一次下载,永久免费,没有请求限制,没有隐私问题。Qwen3.6-Plus 的 OpenRouter 免费版,适合需要更强能力但不想本地部署的情况。
两条路,各有取舍,看你的具体需求。
七、结尾
AI 从云端走到你手里,听起来像是一个技术参数的变化。但我觉得它不只是这个。
当一个 AI 模型能跑在你的手机上,完全离线,数据不经过任何服务器,你修改它、调整它、在商业产品里使用它,都不需要任何人的许可——改变的不只是部署方式,改变的是一种权力关系。
过去几年,AI 的控制权在云端服务商手里。你能用什么、能做什么、数据怎么处理,都是别人说了算的。Gemma 4 不是打破这个格局的全部,但它是一个节点。它让”本地跑”第一次变成了一个真实的、可以认真对待的产品选项。
端侧 AI 还有很多问题没解决。能力的天花板还在,硬件的门槛还在,工具链的成熟度还差一截。但方向对了。这件事开始了。
本文由 @AI进化论 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


