
 起点课堂会员权益
起点课堂会员权益一文讲透Token,为什么它正在成为“新工资”与“新KPI”?
“以后公司给工程师和产品经理发的,可能不只是工资,还有 Token。”
这句话听起来像个荒诞的玩笑,但回顾近期硅谷的动态,会发现它已经无限接近现实。
在AI全面重塑软件交互的今天,如果产品经理的视角还停留在 DAU、转化率和留存,而对 Token 缺乏概念,大概率会在未来的商业化设计中遭遇成本陷阱。

本文跳出深奥的算法,尝试用业务语言探讨两件事:第一,Token 是什么、在底层到底是怎么计费、怎么运转的?第二,为什么 Token 正在成为新时代的工作预算,甚至演变为核心 KPI?
Part 1:撕开大模型的黑盒,Token到底是什么?
1. 从一个根本的“常识违背”开始
当在 ChatGPT 或 DeepSeek 的输入框里敲下一段话时,体验和社交软件聊天一样自然。
但这里隐藏着一个违背直觉的常识:AI 大模型底层只能处理数字,它根本不认识人类的文字。
比如输入“今天天气真好”,模型看到的不是这六个字,而是一串冷冰冰的编号。
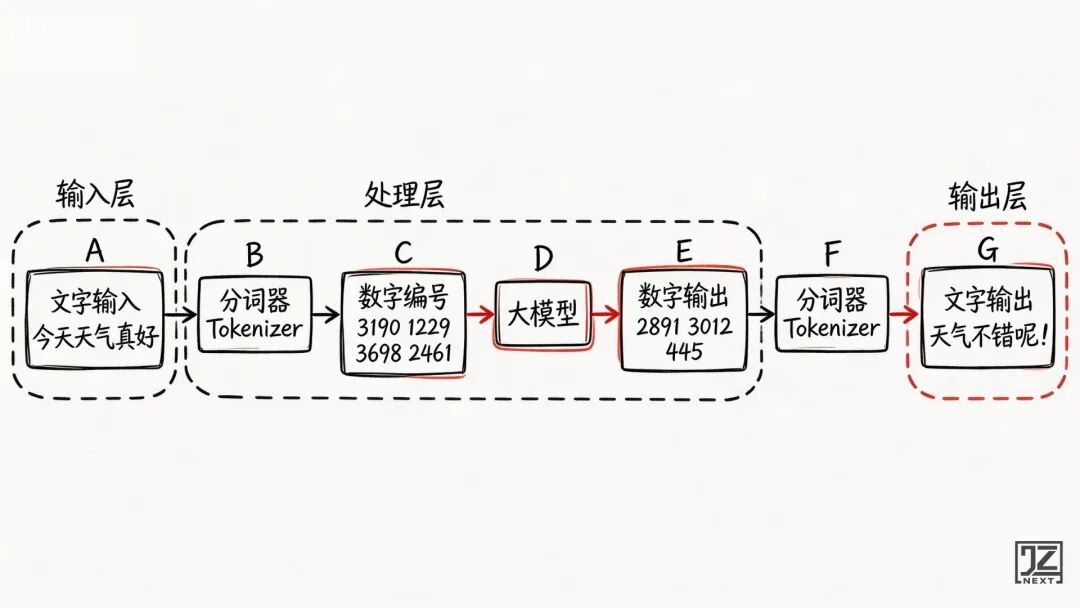
文字在进入模型之前,必须先被“翻译”成数字;
模型输出数字之后,也要再被翻译回文字。
而负责这个翻译工作的组件,就是分词器(Tokenizer)。
2. 分词器Tokenizer:没有感情的查字典机器
分词器的工作逻辑非常简单粗暴,主要分两步:
第一步:切分。
把一段文字切成一小块一小块,这一小块,就叫一个Token。
第二步:编号。
分词器内部有一张极其庞大的词表,里面收录了几万个常见 Token,每个 Token 都有唯一编号。切完之后,直接替换成对应的数字。
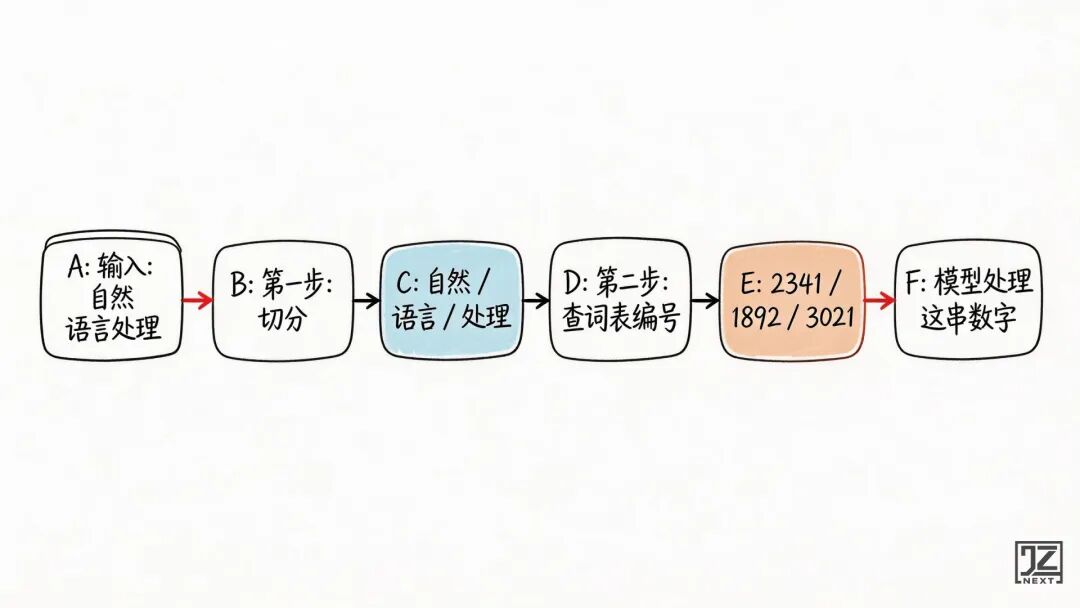
需要注意的是,分词器并没有在“理解”输入的文字,它只是在机械地查表。
3. 破除迷思:1个汉字 ≠ 1个Token
在做成本测算时,一个理所当然的误区是以为“1个汉字 = 1个Token”,这往往会导致极大的预算偏差。
Token 的切分逻辑是纯统计学规律:
在人类语料库里,谁经常挨在一起,谁就更可能被合并成一个 Token。
- “自然” / “语言” / “处理”——如果是普通语境,可能各是 1 个 Token。
- 但“语言模型”这四个字,在 AI 训练语料里大量捆绑出现,分词器大概率会直接把它打包成 1 个 Token。
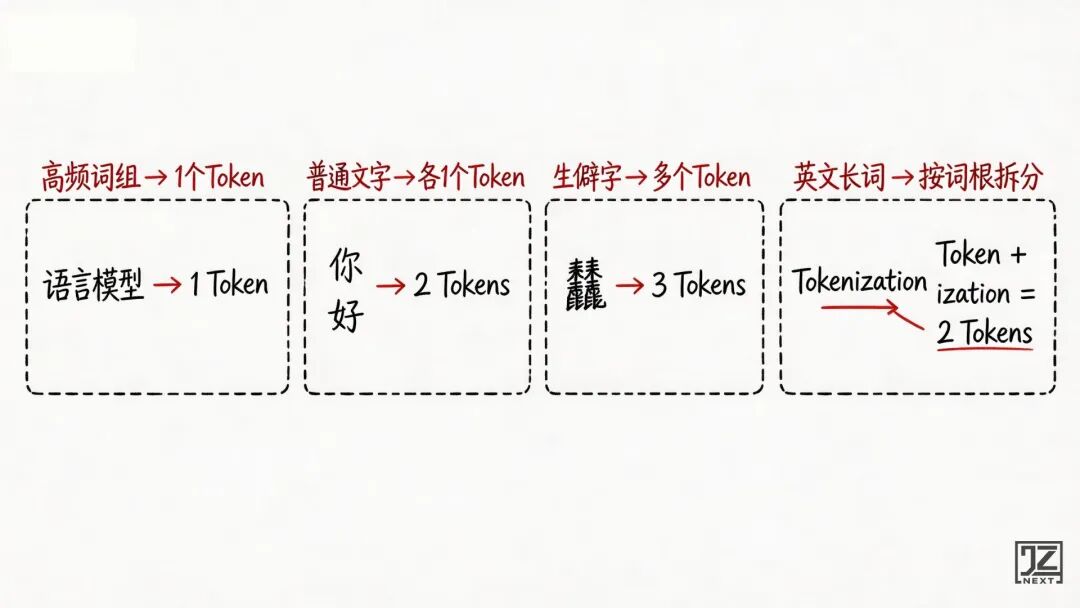
常见字、高频词组极其省 Token;生僻字、冷门词极其费 Token。
粗略的业务测算参考基准是:
1万个汉字 ≈ 1万~1.5万 Token;一本《三体》全三册 ≈ 100万 Token。
4. 商业模式的秘密:为什么“输出”比“输入”贵4倍?
翻看各大模型厂商的 API 定价页,往往会发现一个现象:
输出 Token 的价格远高于输入 Token。
以 DeepSeek 为例,输入 1M Token 是 2 元,输出则是 8 元,整整贵了 4 倍。
这直接决定了 AI 产品的交互设计逻辑。
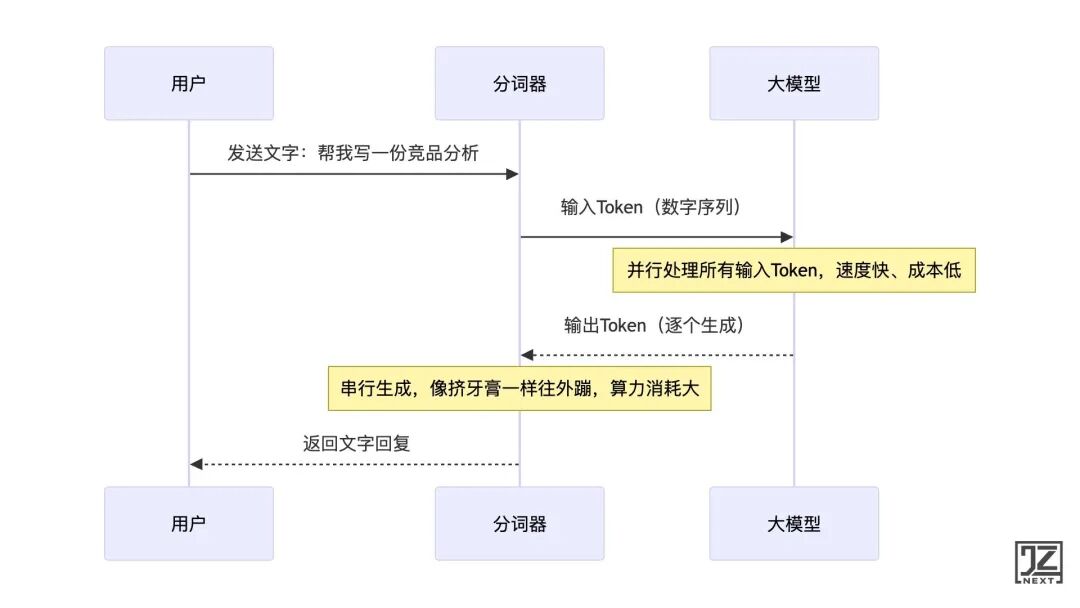
原因在于底层算力的处理方式不同:
- 输入 Token:模型是并行处理的,一口气全部读完,效率极高。
- 输出 Token:模型必须串行生成,前一个词没生成,后一个词就无法计算。就像工厂流水线,原材料(输入)可以批量卸货,但成品(输出)只能一件一件下线。
算一笔产品账:
假设某款 AI 客服系统,每天处理 10 万条咨询。如果每条回复平均 200 个 Token:
10万 × 200 Token = 2000万 Token/天 = 20M Token/天按 8元/M Token 计算 = 每天 160 元,每月近 5000 元。
若能通过 Prompt 优化,引导模型“说短话”,把回复压缩到 100 Token,产品毛利将直接翻倍。
在 AI 时代,字数就是真金白银。
5. 缓存命中:决定产品生死存亡的“省钱杠杆”
很多 AI 产品上线后,账单比预期高出几个数量级,复盘时往往发现是忽略了“缓存(Cache)”。
大部分 AI 应用在调用模型时,底层发送的结构是:
[固定的系统提示词 System Prompt] + [用户当次的输入]。
系统提示词通常是固定的(例如:“作为专业的法律顾问,请用严谨的语气回答……”),可能长达 500 个 Token。
大模型的缓存逻辑类似于计算器的“M+”记忆功能:
算过的前缀,存起来,下次直接复用。
- 没有命中缓存:10万次调用 × 500 Token × 2元/M = 每天 100 元。
- 命中缓存:按大厂普遍的缓存折扣价(如 0.1元/M),同样的调用只需每天 5 元,成本暴降 95%。
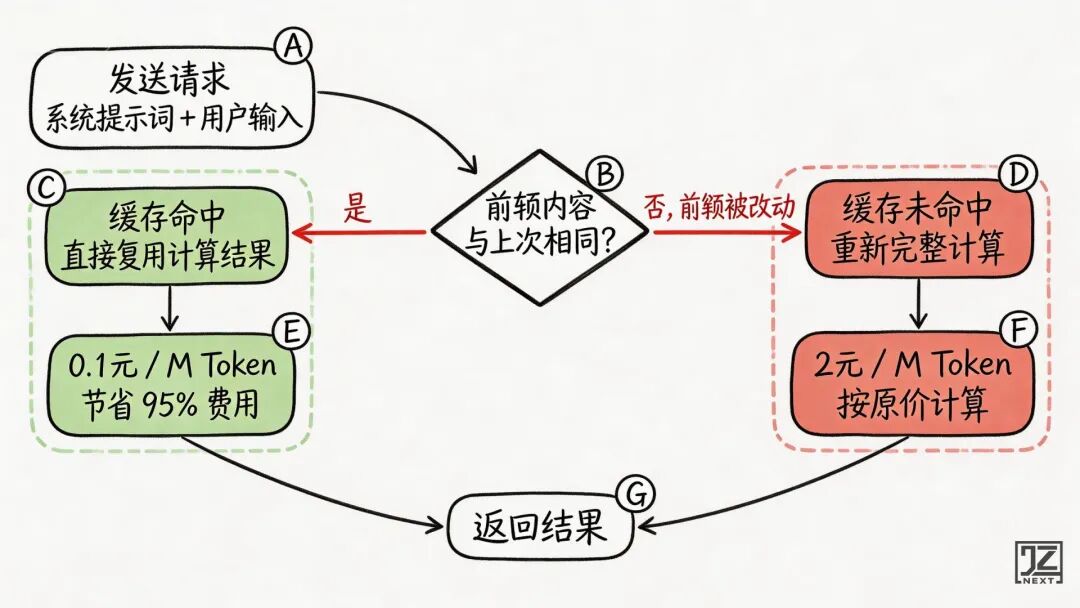
缓存优化的关键在于:
在设计 Prompt 拼接逻辑时,应将绝对不变的内容放在最前面,把动态变化的(如用户输入、时间戳)放在最后面。
哪怕前缀里多加了一个空格导致缓存穿透,省下的成本也会瞬间清零。
Part 2:Token 正在成为工资,这不是比喻
讲完了底层逻辑,再来看行业正在发生的变化。
1. 硅谷正在重估“员工价值”
2026 年 GTC 期间,英伟达 CEO 黄仁勋在一次公开访谈中抛出了一个很有冲击力的判断:如果一个年薪 50 万美元的工程师,一年连 25 万美元的 Token 都没有消耗掉,他会非常警觉。更进一步,他还谈到,未来给工程师配置 Token 预算,规模可能会达到其年薪的一半。
换句话说,在他眼里,Token 已经不是可有可无的调用费用,而是优秀工程师应该被配置的生产力预算。
原话是这样的:
“If that $500,000 engineer did not consume at least $250,000 worth of tokens, I’m going to be deeply alarmed.”“I’m going to give them probably half of that on top of it as tokens…”
这不是一句猎奇口号。
它背后真正变化的是:
企业正在重新定义,一个人到底靠什么创造价值。
过去,公司给工程师配的是电脑、软件许可证和云资源;现在,越来越多公司开始认真思考另一件事:
如果一个工程师能持续调用模型、Agent 和推理能力,他的产出究竟会被放大多少倍?
黄仁勋甚至把“不充分使用 AI”类比成做芯片设计却还在用纸和笔。
2. 巨头们的“Token 军备竞赛”
这绝非英伟达一家之言,各大科技巨头已经将其落地为管理动作:
- Meta 的 60 万亿 Token 狂欢:Meta 内部搭建了 “Claudeonomics” 排行榜,追踪 8.5 万名员工的 AI Token 消耗量。30天内全公司消耗了 60 万亿个 Token。排名第一的员工,每天消耗 93 亿个 Token。CTO 明确表示,Token 消耗量已成为衡量员工 AI 使用深度的重要指标。
- OpenAI 的面试新筹码:顶级工程师在求职 OpenAI 时,已经开始主动询问入职后能分配的专属计算资源(Token额度)。
- Shopify 的绩效新规:CEO Tobi Lütke 明确要求将 AI 使用能力纳入绩效评估。工程团队获得无限量 Token 供应,但使用频率会被严格追踪。
3. 为什么 Token 会成为薪酬的“第四支柱”?
风险投资人 Tomasz Tunguz 曾预测,Token 额度将与“底薪、奖金、股权”并列,成为高级人才薪酬的第四支柱。背后的驱动力在于:
- Agent 时代的算力爆炸:过去用 AI 是一问一答;现在的 AI Agent 会自己拆解任务、反思、调用工具。完成一个复杂任务消耗的 Token 呈指数级上升,Token 变成了真实的、规模巨大的生产资料成本。
- 生产力上限的硬约束:在 AI 时代,一个员工能产出多少,极大程度取决于能调用多少算力。限制 Token 额度,实质上就是限制产出空间。
- 人才争夺的硬通货:超过 60% 的工程师在评估新工作时将 AI 工具权限列为“必备条件”。缺乏充足 Token 预算的公司,在顶尖人才争夺中容易处于劣势。
- 极致的精确可计量:相比于“弹性工作制”这种模糊福利,Token 是绝对精确的数字,发放 100 万 Token 就是 100 万,透明且易于量化。
Part 3:AI时代的商业与职场重塑
Token 机制正在深刻重塑产品侧的日常工作与商业设计逻辑,这并非仅仅是研发团队的课题。
1. 商业化重塑:Token 演变为 COGS(主营业务成本)
在传统移动互联网时代,多一个用户点击按钮,边际成本几乎为零。
但在 AI 时代,用户的每一次对话、每一次 Agent 触发,都在产生真实的算力消耗。
构建“Token 经济学”思维成为商业化设计的核心:
- 场景分级:并非所有功能都需要调用最昂贵的旗舰模型(如 GPT-4o 或 Claude 3.5 Sonnet)。高频但简单的分类、总结任务,完全可以路由给成本更低的小模型(如 GPT-4o-mini 或开源 8B 模型)。
- 交互限制:在产品 UI 上,通过设定字数限制、提供预设选项(代替开放式输入)、甚至限制每日免费对话次数,能够有效从产品端掐断 Token 的无谓损耗。
2. 交互与体验设计:在“冗长”与“精准”间找平衡
由于输出 Token 成本高昂,这就要求在设计系统提示词时,有效克制 AI 的“废话倾向”。
- 强制结构化输出:限制 AI 仅输出 JSON 格式,或者明确指令“不要任何解释,只给出最终结果”。
- 流式输出(Streaming)的体验填补:因为输出 Token 是逐字生成的,为了缓解用户的等待焦虑,打字机效果(流式输出)配合优秀的 Loading 状态和骨架屏设计,成为了填补首字响应时间(TTFT)的标配。
3. 职场价值重塑:生产资料的重新定义
在工业时代,企业的核心成本是电费和人工。在 AI 时代,Token 扮演了电力的角色。
日常工作中涉及大量的竞品分析、PRD 撰写、用户反馈聚类、数据清洗。消耗的 Token 越多,意味着把越多的重复性劳动交给了机器,个人工作杠杆率也就越高。
在未来的职场沟通或机会选择中,除了关注 DAU、转化率、薪资和期权,或许还可以增加一个评估维度:“公司会为该岗位的日常工作,提供多少 AI 工具的 Token 预算?”
理解 Token,不仅是掌握一个技术词汇,更是洞察 AI 时代生产资料分配的底层逻辑。
本文由 @JZNext 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自作者提供






- 目前还没评论,等你发挥!


