
 起点课堂会员权益
起点课堂会员权益Codex开PDD店复盘:12单之后,我对AI自动化电商有了更真实的判断
当AI遇上电商创业,技术的光环下暴露出更残酷的现实瓶颈。一位实验者通过半个月的拼多多店铺运营,揭示了AI工具在选品逻辑、数据记忆、任务拆解等环节的核心缺陷——真正的挑战不在于模型能力,而在于如何将商业思维转化为可执行的系统设计。本文深度拆解从1688AI选品到gstack思维训练的全流程,带你看清AI电商创业中那些比技术更关键的认知升级。

用AI开了半个月拼多多店。12单,200块,1单退货。
不是来报喜的,这个成绩不值得报。但这半个月想清楚了一件事,比这12单值钱得多:
AI的真正瓶颈,不在技术,在脑子。
展开说。
这次实验的起点不是拼多多,是1688
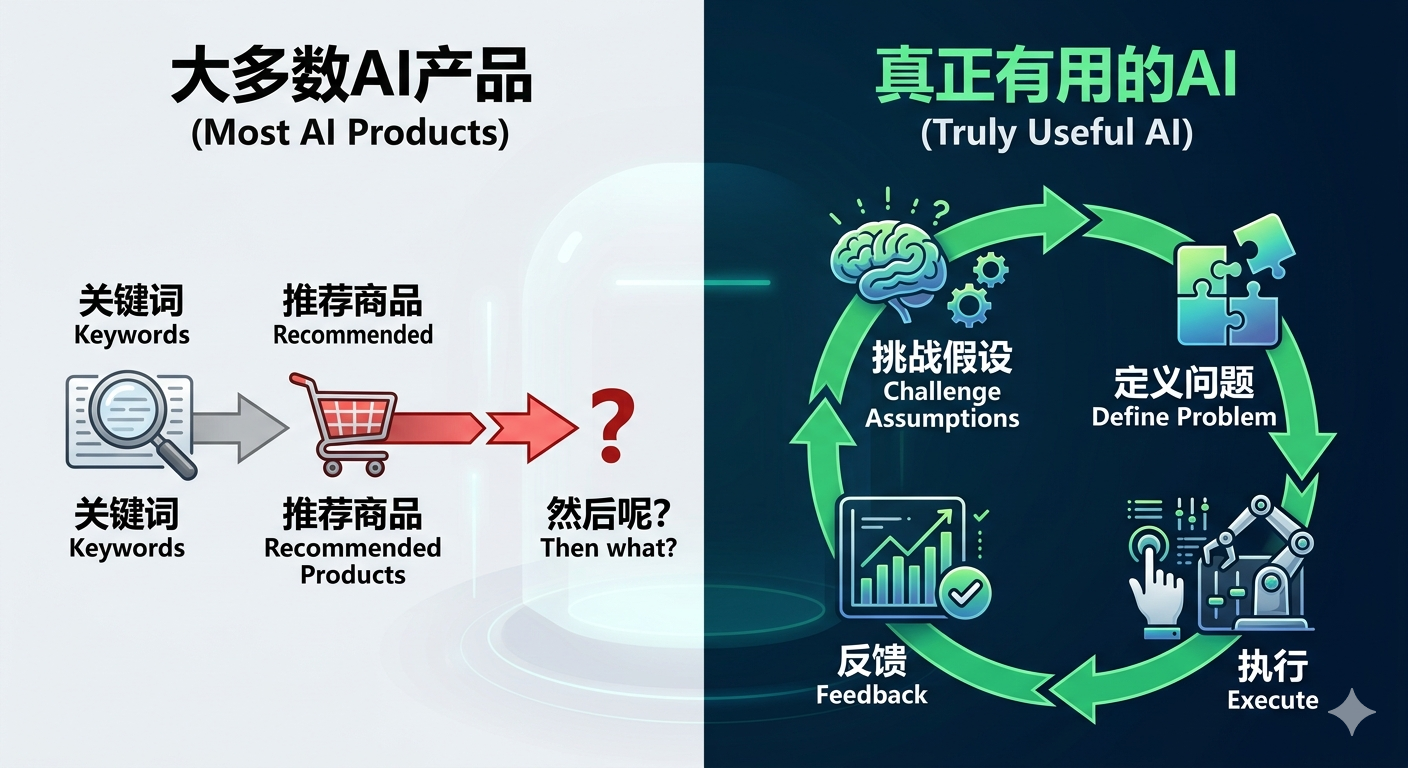
1688上线了AI版App,平台掌握供给侧数据,又天然靠近电商交易,按理说最适合做AI产品。体验了一圈,核心逻辑是:输入一个关键词或场景,推荐一批适合铺货的商品,再利用三方工具自动铺货。看起来是AI,本质上是搜索引擎加了一层壳。
关键问题在于——推荐完了,然后呢?
还是得自己验证商品有没有真实需求,自己算供货价加运费之后还剩多少利润,自己完成定价、审核。AI进入了选品这一个环节,但整条工作流的负担一点没减。
这是大多数AI产品的设计陷阱:优化了一个可见的步骤,但没有改变整条链路的负担。
带着这个失望,开始想一个不同的问题:有没有一种AI工具,不是在已有的思路上帮着跑得更快,而是能帮着判断这个思路本身对不对?
遇到了gstack
gstack是一个Skill,YC 现任 CEO 把 他自己的方法论写进了 Claude Code,里面有一个叫/office-hours的skill,模拟YC合伙人的问诊方式。它会像YC一样拷问你的想法,帮你想的更清楚。
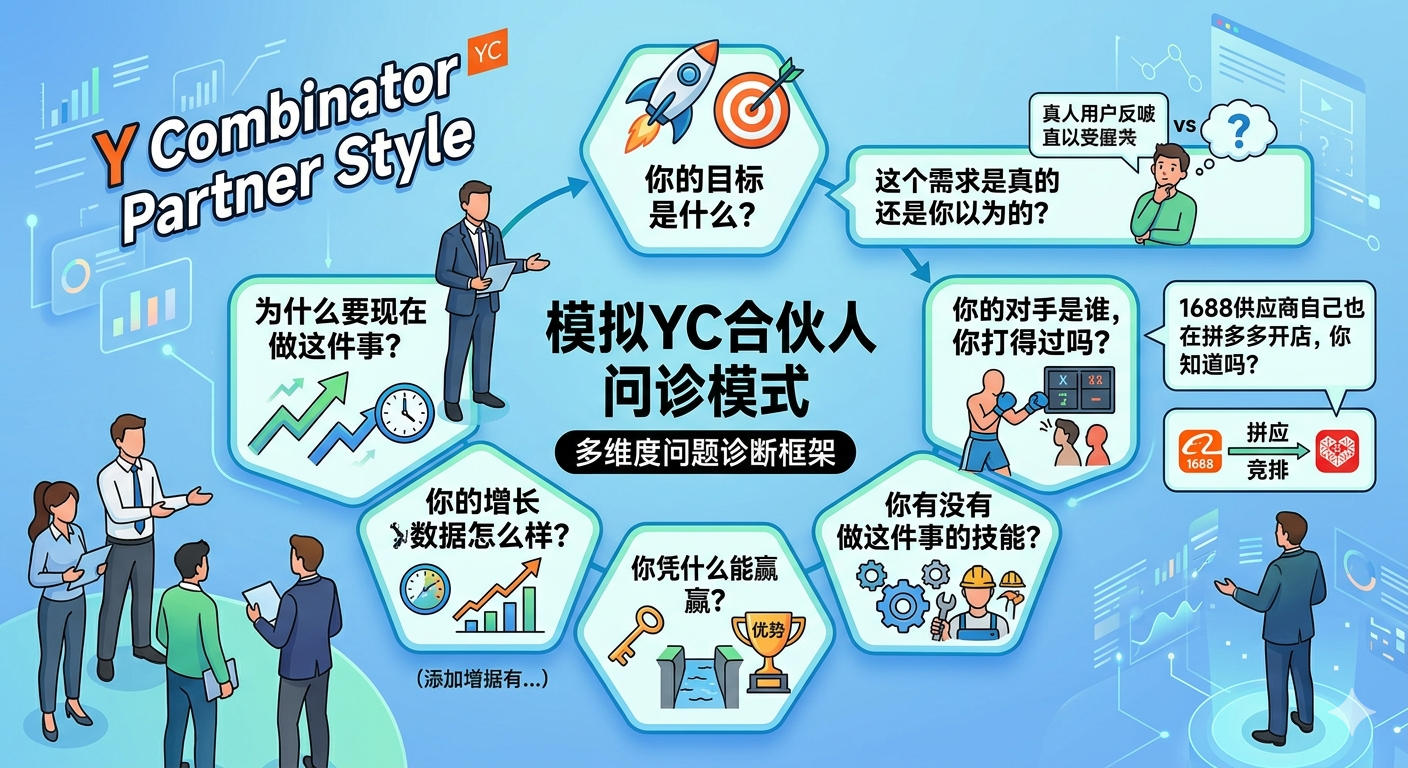
最早的选品逻辑完全是个人喜好驱动——选一个觉得有市场的品类,挑几款觉得好看的商品,直接铺。没做供需分析,没看竞争密度。/office-hours直接把这套逻辑打回来了:需求证据是什么?选这些商品的依据是什么?最小验证路径是什么?
几个问题下来就明白了,”觉得好看”根本不是一个商业判断。被逼着回到供需数据上:哪些品类在拼多多有真实需求,哪些货在1688有稳定供给,两边价差能不能容下利润空间。
1688的AI推荐了商品,但没有挑战选品逻辑。gstack什么都没帮着做,但在开始执行之前,把思路里最脆弱的地方暴露出来了。真正有价值的AI工具,不只是加速执行,而是在动手之前,先确认方向是对的。
想清楚了问题,开始执行。然后遇到了真正的现实。
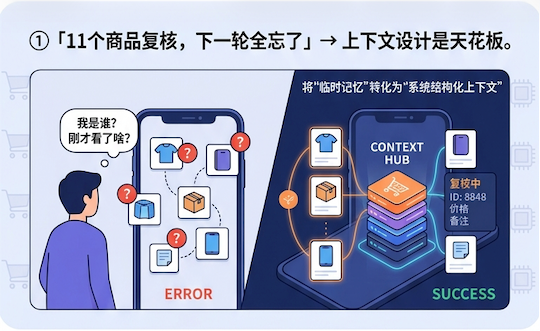
第一个撞上的墙:AI没有记忆。
让AI做价格巡检,把店里11个在售商品的供货价、运费、拼单价逐个核对。第一轮做得挺好,9个商品完成纠偏,2个确认不用改。但到第二轮,上一轮的所有结论全忘了——哪些商品已经复核过,哪些规格运费要加3.5,哪些SKU不能盲改,统统不记得。上一轮刚确认”这个商品中高风险,不要自动改价”,下一轮又去碰了。
大模型每次开新对话,默认就是失忆状态。单次任务没问题,但一旦项目跨天、跨轮次,没有记忆就意味着同一个坑反复踩。即使对调整单任务的提示词也无济于事。
解决方案是维护一份共享状态文档,结构化记录已验证的规则、商品状态、阻塞原因。每次AI开工前先读,结束后追加新结论,只追加不覆盖。但真正有效的不只是”记下来”,而是把隐性经验改写成显性规则。
比如发现AI自动调价时默认不会把运费加进拼单价。这个坑不能靠AI”下次注意”,下次照样忘。所以直接写死成公式:
落地成本 = 代发价 + 运费 + 0.5风险预留
利润款 = 落地成本 × 1.25 价格保留1位小数,向上取整
规则写进共享文档,AI每次读到就能执行。不靠记忆,靠系统。
这不是一个技术问题,是一个协作设计问题。做过团队管理的人都知道,新人入职最大的效率损耗不是能力不足,是上下文缺失。写给AI的共享状态文档,本质上和写给新同事的交接文档是同一件事——把”只存在于某个人脑子里的东西”变成”谁来了都能接着干的东西”。大多数人用AI的方式是”每次重新讲一遍需求”,这就像每天早上把昨天的交接文档撕了,重新口述一遍。
AI的可靠性,取决于上下文质量。模型能力是地板,上下文设计才是天花板。
数据获取新方案
因为之前有了获取数据的解决方案,通过让AI在浏览器里模拟人的动作——打开1688详情页,等页面加载完,逐个读价格和运费。问题马上暴露:慢,每个商品至少几十秒,而且很多数据例如多规格SKU的价格并不能直接在页面加载完成。而且连续访问几个详情页之后,1688直接弹验证码。有一次核查到第4个商品就开始频繁弹滑块,剩下7个全卡住,那一轮巡检直接变成”已完成4/11,剩余待补查7个”。
这件事逼着去想一个更根本的问题:AI获取数据,总共有哪些办法?什么时候应该用什么办法?
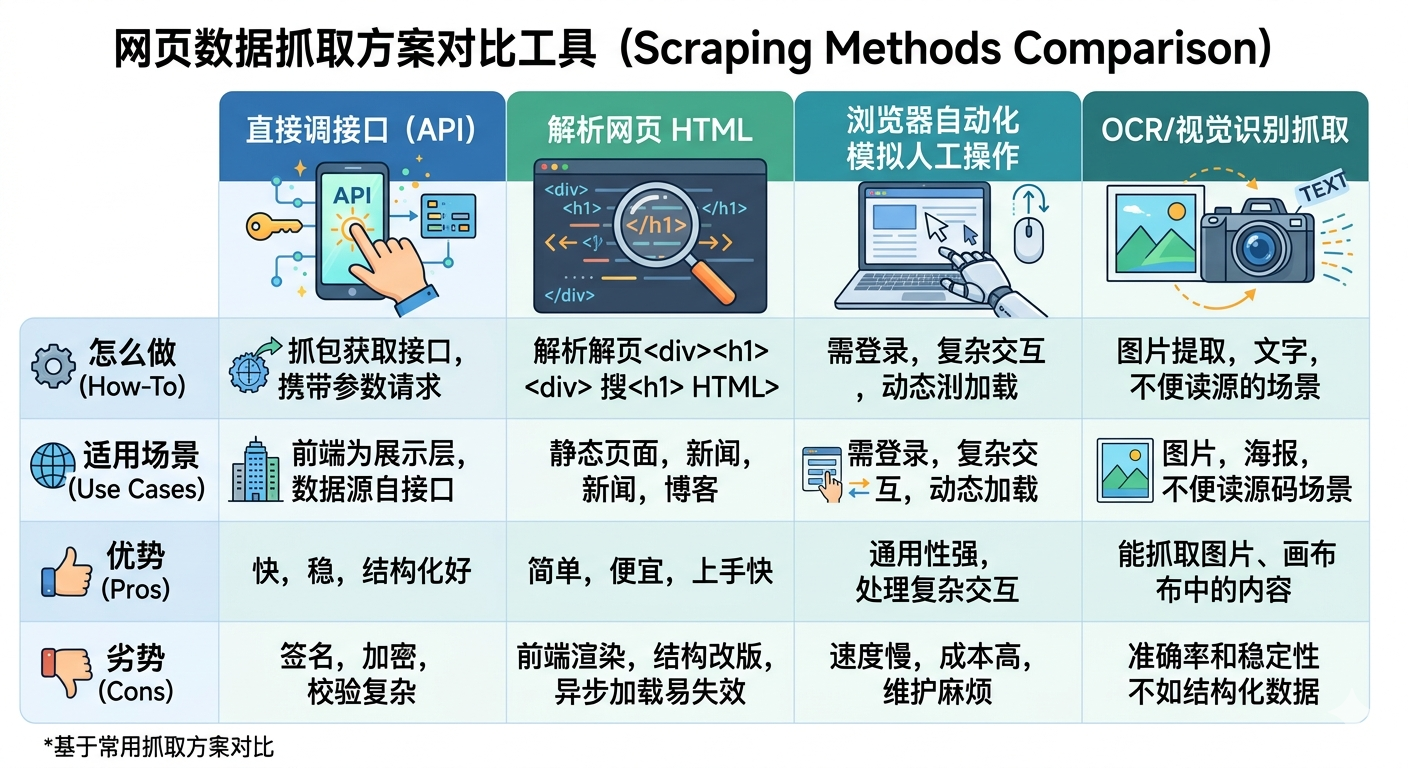
页面是给人看的,API是给机器用的。让AI模拟鼠标点击读页面文字,本质上是在用最慢的方式访问数据。后来改成直接从前端页面的网络请求里提取接口返回的原始数据,速度和准确度都上了一个台阶,风控触发也大幅降低。
同样的思路也改了任务设计。
一开始一个自动化任务做五件事——选品、验证、铺货、改价、回写飞书,一条龙。结果任何一步出错,整个重跑,还不知道卡在哪。后来拆到一个任务只做一件事:今天只做新选品且去重,产出100个原始1688商品链接,不做任何其他操作。听起来像退步,但先跑通一个最小的稳定流程,才谈得上扩展。
这和之前搭建数据Agent的经验直接相关。搭Agent的时候踩过完全一样的坑:让AI一次性完成登录→筛选→翻页→下载的全流程,结果任务过长导致幻觉频发、中途欠费、执行不可控。最后的解法也一样——把长流程拆成独立子任务。有了那个经验,在电商场景再遇到同样的问题,解法是自然的:不是”怎么让AI把五步一起做好”,而是”为什么要让AI一次做五步”。
大多数人遇到”自动化跑不通”的第一反应是”AI还不够强”。但真正的瓶颈往往不在AI的能力,在任务设计的粒度。
在AI和目标之间,找阻力最小的路径。路径越长,摩擦点越多,系统越脆弱。
真实业务到处都是意外,AI不知道什么时候该停
有一次发现Chrome的会话接不上,调试口存在但不可用。AI具备操作浏览器的能力,但最终连业务后台的门都进不去。
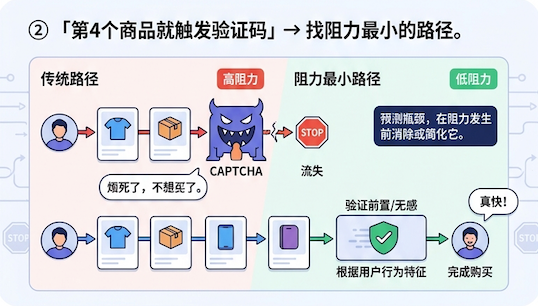
还有一次,一个商品在1688的批发价已经涨到41.81,但拼多多前台拼单价还是29.9。AI没发现这个问题——不是算不对,是看到的数据本身就是旧的。上一次读取之后供货价变了,AI不知道。如果这时候让AI自动改价,直接亏钱。
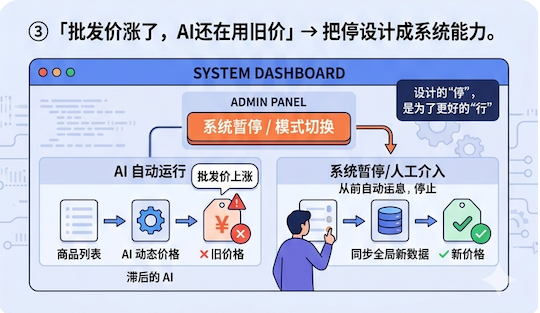
一开始把这些当”待解决的技术问题”,想办法绕过去。后来意识到,这些摩擦不是bug,是真实业务的常态。消除不了,只能设计进系统里。
制定了一套策略:拿不到真实数据就停止自动改价,而不是用旧数据凑合;
触发验证码就暂停并记录阻塞,而不是硬冲;
每一步的结果都回写共享状态,下一轮AI能看到上一轮卡在哪里、为什么停了。
然后让gstack对每轮数据做漏斗分析——从选品数量到验证通过率到最终上架率——把漏斗数据反馈给AI,根据真实转化调整下一步方案。这样AI就从一个盲目往前推的执行器,变成了一个”执行→观测→调整→再执行”的闭环系统。
做产品的人都知道一个概念:防御性设计。好的产品不是只设计”一切正常时的路径”,而是把异常、中断、回退都设计成系统能力的一部分。但大多数人用AI的时候,脑子里只有happy path——默认AI能顺利跑完,出了问题再补救。这就像写代码只写正常逻辑不写异常处理一样,在demo里能跑,在生产环境里必崩。
“知道什么时候停”和”知道怎么往前走”是同等重要的能力。甚至在真实业务里,前者更重要——往前走错了可以回退,不知道该停的时候不停,造成的损失往往不可逆。
真正可靠的系统,不是永远冲过去的系统,而是知道什么时候该停、并且能把停的原因记下来的系统。
整个实验跑通的模式是:AI自动化 + Human in the loop
AI做有规则、可重复、跨系统的脏活:按成本模型算价格、批量复核SKU、把结果写回共享状态。这些事纯人工做极其烦,11个商品逐个在1688和拼多多后台之间来回对照,谁干谁崩溃。但判断节点必须留给人:这个方向继续还是放弃、价格是不是符合直觉、被风控之后要不要继续推。
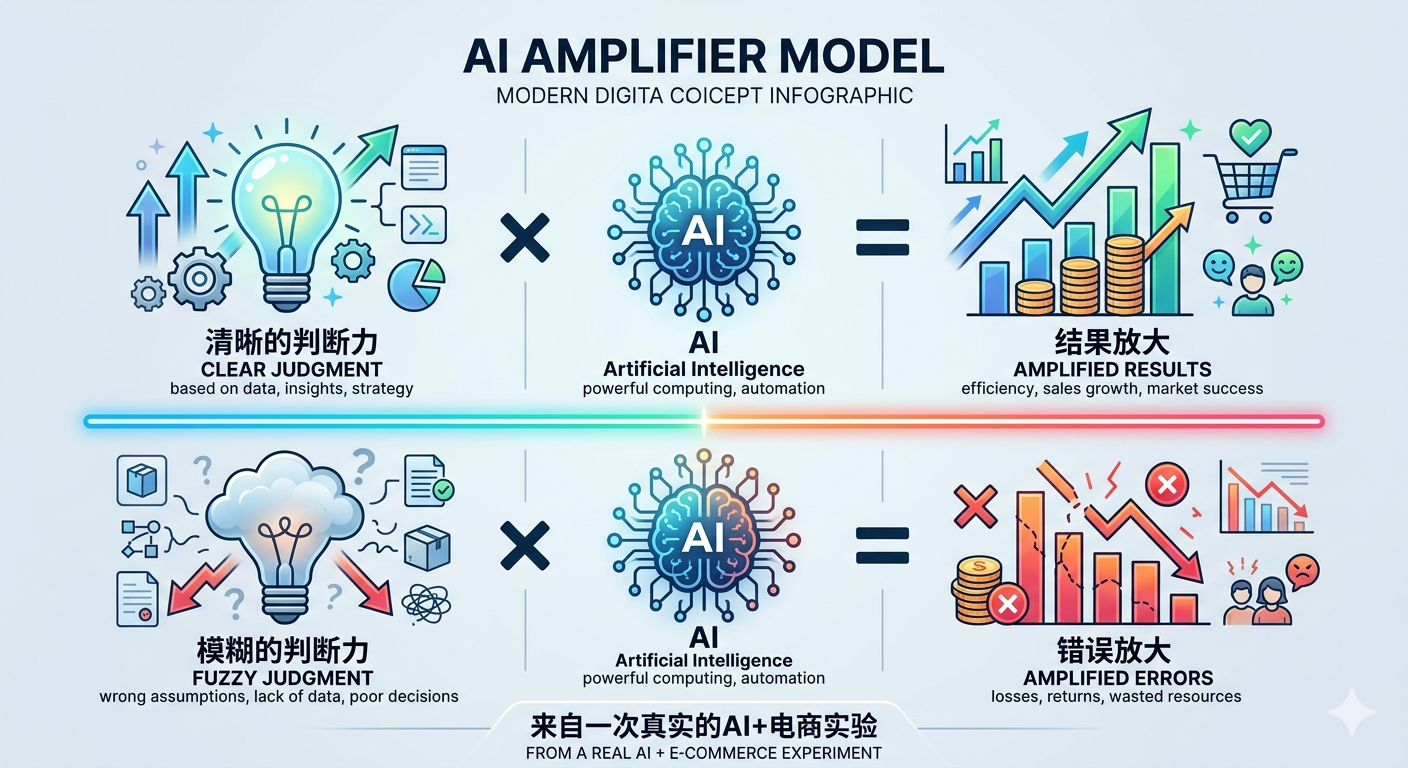
想清楚之后,AI帮着执行得很好。 没想清楚之前,AI只是帮着更有效率地犯错。
AI是放大器,不是替代品。放大的是已有的判断力。还没有的东西,放大不了。
技术的门槛在消失。思维的门槛留下了。
本文由 @诸葛铁铁 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Pexels,基于CC0协议






- 目前还没评论,等你发挥!


