
 起点课堂会员权益
起点课堂会员权益别迷信大模型了,我在零食店扫了半年货架,悟出了这套“最小框”法
当大家都在聊 GPT-4V 怎么看图写代码时,我却被一个零食货架上的白色纸巾包装搞破防了。
在真实业务场景里,特别是“空台面”检测这种细碎活儿,一味堆参数往往不如一个巧妙的标注逻辑加上底层的工程微调管用。

复盘:为什么第一周就“翻车”了?
我负责的这个 AI 巡店项目,初衷很简单:给某全国连锁零食品牌的 万家门店做“陈列饱和度监控”。业务需求很明确:货架要是连续空缺超过10分钟,赶紧发告警叫店员补货。
但上线第一周,我们就发现现实远比实验室残酷:
- “伪装者”白色包装:有一款白色的“脆脆角”,整排摆满的时候,由于反光和颜色,算法直接把它当成了背景,报告“大面积空缺”。
- 标注的主观偏差:散装称重区最头疼。有的标注员框个大圈,有的框几个碎圈,导致模型训练时特征极其混乱,根本无法收敛。
- 货架的“户型差异”:大户型开阔卖场的货架能有2米长,小户型多拐角的小便利店可能就80厘米。同一套 YOLO 模型,换个店准确率就断崖式下跌。
说白了,缺货检测不难,难的是“空台面”识别:因为它没有参照物。
破局:“最小检测框”标注法
为了解决“没参照物”和“标准不一”的问题,我推翻了之前的逻辑,设计了一套两步走的方案。
3.1 找准“标尺”:用统计学干掉主观判断
既然商品是排队站的,那我们就给空位设个“标准座”。我们从几万张图中拉出了 X% 的样本,强迫标注员按单个商品列去框空位。跑完数后,我们对这些框的短边像素做了分布统计,发现 30px 是出现频次最高的一个数值。
以此为基准,当出现大面积空台面时,我们不再允许画大框,而是像拼积木一样,用 30px 宽的最小框平铺过去。这直接让模型学习到的特征从“随机噪声”变成了“固定纹理”。
3.2 深度对齐:模型层面的针对性优化
有了标准的标注逻辑,模型层面的配套调整才是真正发挥威力的关键:
1)Anchor Size重构:原生 YOLO 的 anchor 比例通常是针对常规物体的。针对我们这种长条状的“最小框”,我重新聚类并预设了更窄长、比例更集中的重构 Anchor boxes,确保模型在第一层特征提取时就能精准捕捉到这种纵向空隙。
空台面标注框尺寸分布与 anchor 选型
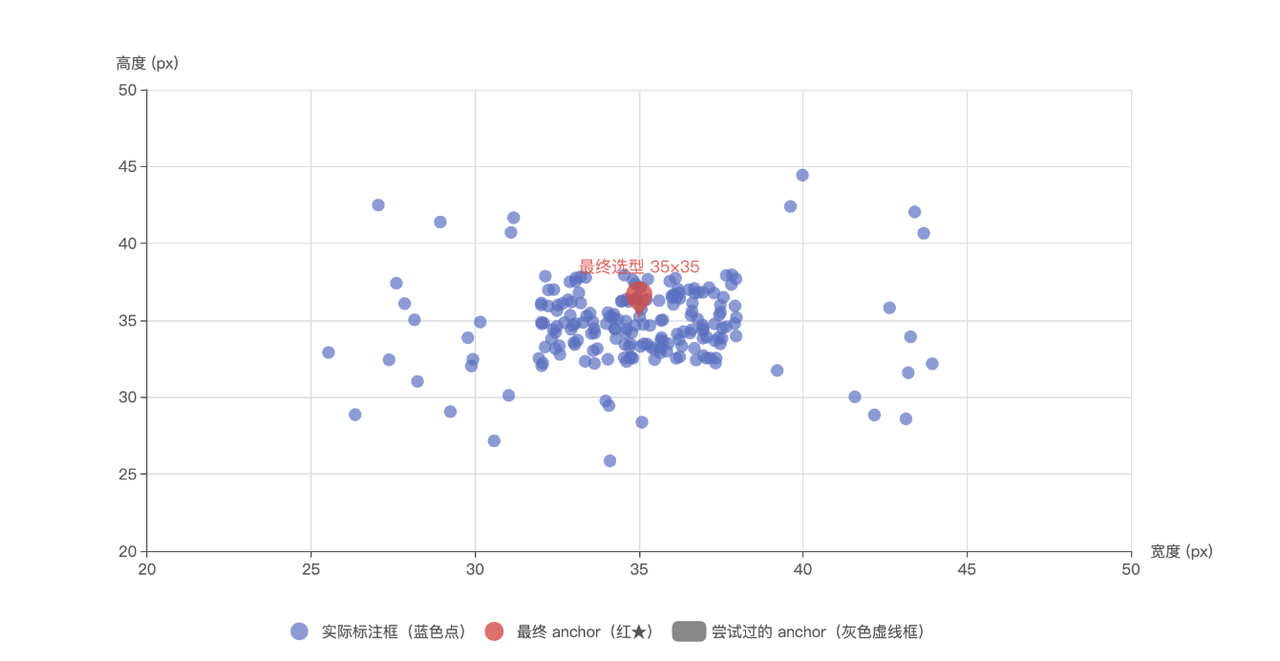
标注框数据高度集中在 35×35 区域,先尝试 30×35 anchor 效果不佳,最终选用 35×35 作为最优检测框尺寸。
2)Loss function 权重倾斜:在计算损失函数时,我们针对“空台面(Empty)”类别进行了权重平衡优化,适当降低其权重以减少误报,优先保证模型预测为缺货时的准确性。这种调整使得模型在确认缺货场景下的准确率提升了 30%以上,有效降低了无效质检成本和客诉。
成本与效益:这套方案值多少钱?
这种“土洋结合”的方法,不仅是技术上的胜利,更是商业上的逻辑自洽。
举个例子:
假设一个拥有 1000 家门店的连锁品牌:
- 人力成本:以前每店每天人工巡视货架需花费约 1 小时。引入这套 AI 预警后,人工巡视频次降低了 50%,折算下来,全系统预计每年可节省人力成本约 数百万元(区域人工成本差异)。
- 业绩增量:更及时的补货减少了 50%↑ 的“断货流失”,对于高频刚需的零食赛道,这部分带回的销售额增量同样可观。
AI巡店系统边缘-云协同架构
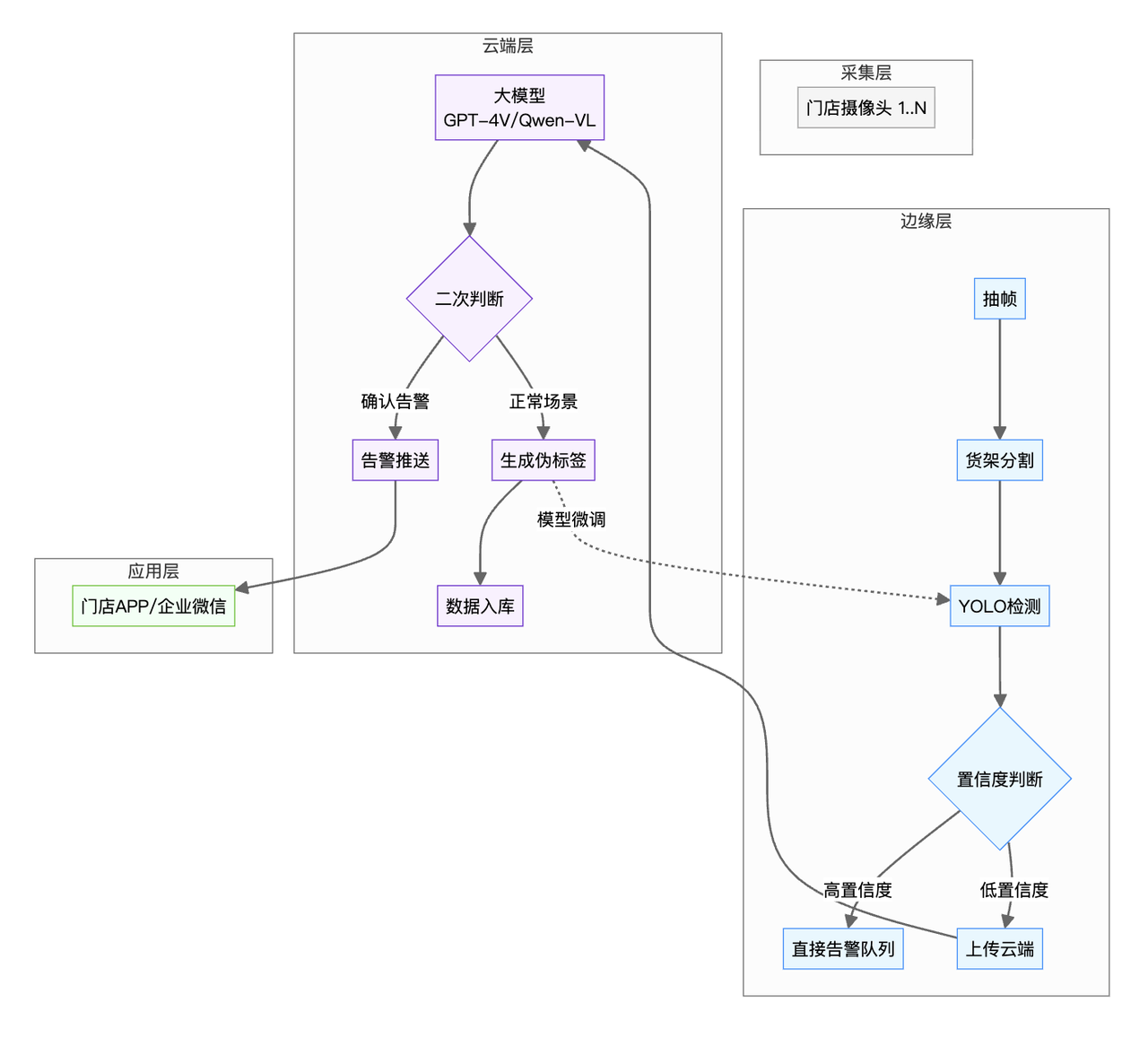
边缘端负责实时检测,低置信度样本上传云端大模型复核,伪标签数据回流持续优化边缘模型,实现端云协同闭环。
坦诚局:这套方法的“失效边界”在哪?
作为一名AI产品,我们必须承认没有万能的方案。这套“最小框法”在以下场景会遇到挑战:
- 极端大斜角监控:如果摄像头安装角度与货架平面夹角过小(近乎平行),纵深处的“最小框”会产生严重的透视缩减,导致检测失效。
- 货架材质干扰:部分透明/不锈钢货架在强光下会产生和白色包装一模一样的镜面反射,即便有 Loss 权重补偿,误报率依然会显著上升。
- 非标准化堆叠:对于那些像小山一样堆放的散装区,商品没有明显的“列”概念,这套逻辑的准确度会从 90%↑跌落至 70~80%。
结语
巡店项目的落地让我明白:AI 落地不是比谁的模型参数多,而是比谁更懂业务里的那点“琐碎事”。
通过对标注流程的微创新,配合anchor和权重函数的针对性调优,我们可以在算力受限的边缘端,跑出不亚于云端大模型的业务效果。
本文由 @嘻嘻李 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


