
 起点课堂会员权益
起点课堂会员权益DeepSeek告别“孤胆英雄”时代
DeepSeek V4的发布不仅标志着其在Agent能力和推理技术上的重大突破,更揭示了这家中国AI独角兽从研究团队向基础设施级玩家的战略转变。面对训练成本飙升、人才争夺战和生态布局需求,DeepSeek正在与腾讯、阿里展开18亿美元融资谈判,这场关乎中国大模型未来格局的资本博弈背后,隐藏着技术路线与商业逻辑的深层抉择。

DeepSeek V4发布是确定的,而融资仍属于媒体报道和交易传闻阶段。
DeepSeek官网已经显示“DeepSeek-V4 Preview”上线,并称其具备更强Agent能力和顶级推理能力,已可在网页、App和API使用。
DeepSeek在4月24日开始预览V4,包含Pro和Flash两个版本,将接替2024年12月发布的V3。
融资这边,截至目前公开口径仍是“洽谈中”。腾讯、阿里正在洽谈投资DeepSeek,估值超过200亿美元;并强调DeepSeek、腾讯、阿里均未立即回应。

《财经》进一步报道称,DeepSeek正在洽谈融资,投资方为腾讯和阿里,两家预计合计投资18亿美元,估值约200亿美元,但交易方案尚未完全敲定。
01 V4发布意味着什么?
DeepSeek上一次真正改写行业叙事,是V3到R1那一轮。那时它同时打穿了几件事:低成本、高性能、开源权重、推理模型。
R1之后,DeepSeek面对的真正考验,是能不能继续交出下一代东西。
很多技术公司的高光时刻只有一次。一次爆款模型、一次舆论破圈、一次资本市场震动,都可能把一家公司推到聚光灯下。但真正难的,是聚光灯退去以后,还能不能继续迭代。
V4至少说明,DeepSeek没有停在R1时刻。它靠低成本奇袭打出过声量,也还在继续迭代旗舰模型。
而且这次V4的重点,已经从“便宜”继续往前走了一步。

根据DeepSeek官方Hugging Face页面,V4系列包括两个MoE模型:V4-Pro为1.6T总参数、49B激活参数;V4-Flash为284B总参数、13B激活参数;二者都支持100万token上下文。
这说明DeepSeek正在把竞争重点,从单纯的性价比,推向更复杂的任务场景。
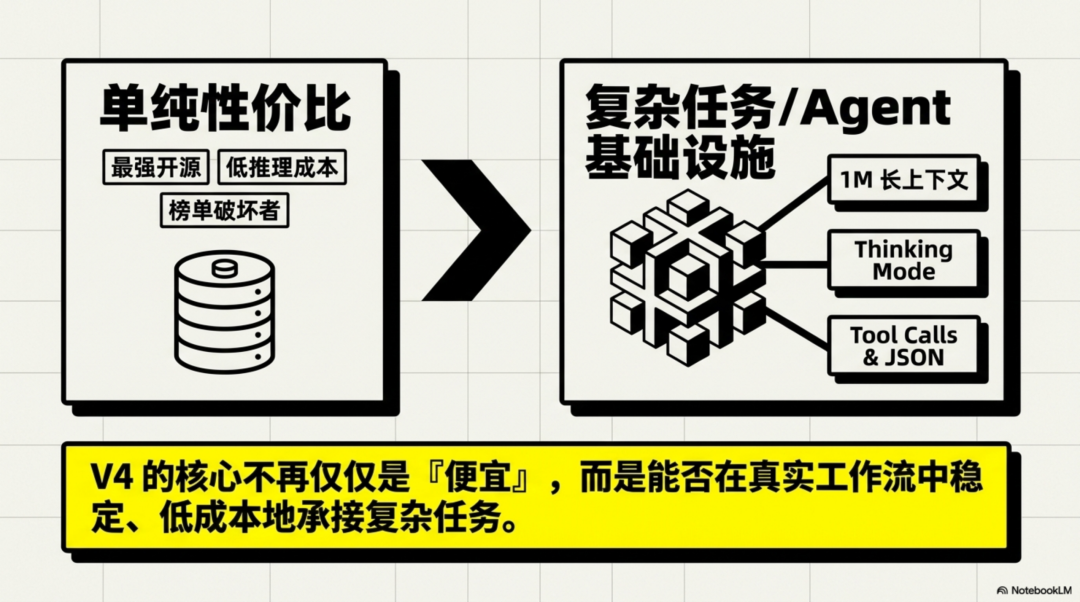
这些能力都指向同一个方向:更复杂的任务执行。长上下文让模型能处理更长资料和连续任务,Thinking Mode对应复杂推理,Tool Calls和JSON输出则更适合接入外部系统、被应用层稳定调用。这也是为什么V4会被放进Agent语境里讨论。
更进一步看,V4真正重要的地方,还在于DeepSeek仍然围绕“效率”做文章。DeepSeek既想让模型读得更长,也想让模型更便宜地读得更长。
大模型下一阶段的竞争,不会只发生在排行榜上。排行榜回答的是“谁更强”,但真实商业世界还要继续追问:谁能把这种能力稳定、低成本、大规模地交付出去?
一个模型能读100万token是一回事,大量用户、开发者、企业客户能不能以可承受的价格调用,又是另一回事。
如果长上下文只停留在演示阶段,它更像技术秀肌肉;如果长上下文可以被压低成本,进入API、企业应用、Agent工作流,它才会变成基础设施能力。
所以V4延续了DeepSeek最核心的路线:不单纯堆参数,继续压榨系统效率。
V4-Pro更像能力上限版本,用来承担复杂推理、长上下文和更高难度任务;V4-Flash则更像规模化调用版本,用来覆盖速度、成本和高频场景。
这说明DeepSeek已经考虑不同用户、不同场景、不同成本结构下的服务形态。
Web、App、API同时推进;Pro和Flash同时出现;长上下文、推理、工具调用一起被强调。DeepSeek准备走向一个需要承接真实应用、真实调用和真实商业化压力的玩家。
02 为什么DeepSeek要融资?
更准确地说,是旧的资金结构已经不适配新的竞争阶段。
过去DeepSeek的特殊性在于,它背后有幻方量化/High-Flyer的资金、算力和工程积累,所以它可以长时间保持一种“非VC叙事”:不急着融资,不急着商业化,不急着讲增长故事。
有说法称,DeepSeek过去曾拒绝过中国顶级VC和科技巨头的多次融资提议。
但到了V4阶段,情况变了。
训练和推理成本都在上升。
V3时代,DeepSeek最震撼市场的是用极低训练成本做出强模型。V3技术报告称,DeepSeek-V3是671B总参数、37B激活参数的MoE模型,预训练数据为14.8T tokens,完整训练只用了2.788M H800 GPU hours。

但V4已经变成1.6T总参数、32T以上预训练tokens、百万上下文、Agent能力。
这个量级继续往前走,哪怕DeepSeek再擅长工程优化,也不可能完全摆脱资本开支。推理侧更是长期成本黑洞:用户越多,调用越多,API越便宜,亏损压力越明显。
还有一个不能忽略的变量,是国产算力适配。
V4发布前后,围绕DeepSeek与华为昇腾的消息明显增多。基于Ascend 950 AI芯片的昇腾Supernode将全面支持DeepSeek V4。
更深一层看,它关系到中国大模型下一阶段的安全垫:模型公司要继续迭代,就必须考虑国产算力、云服务和软件栈的适配问题。
另外,人才竞争变成硬成本。
《财经》报道里提到,DeepSeek开放融资的原因之一是防止人才流失。2025年之后,中国AI人才市场已经进入“核心研究员天价争夺”阶段。DeepSeek此前最强的是“小团队、高密度、研究导向”,但一旦行业巨头开始用现金、期权、算力、数据、产品落地机会来抢人,很难长期防守。
DeepSeek要保住模型迭代速度,就必须把人才激励从“项目荣誉+研究自由”升级到“长期利益绑定”。
DeepSeek也需要生态入口,而不只是模型能力。
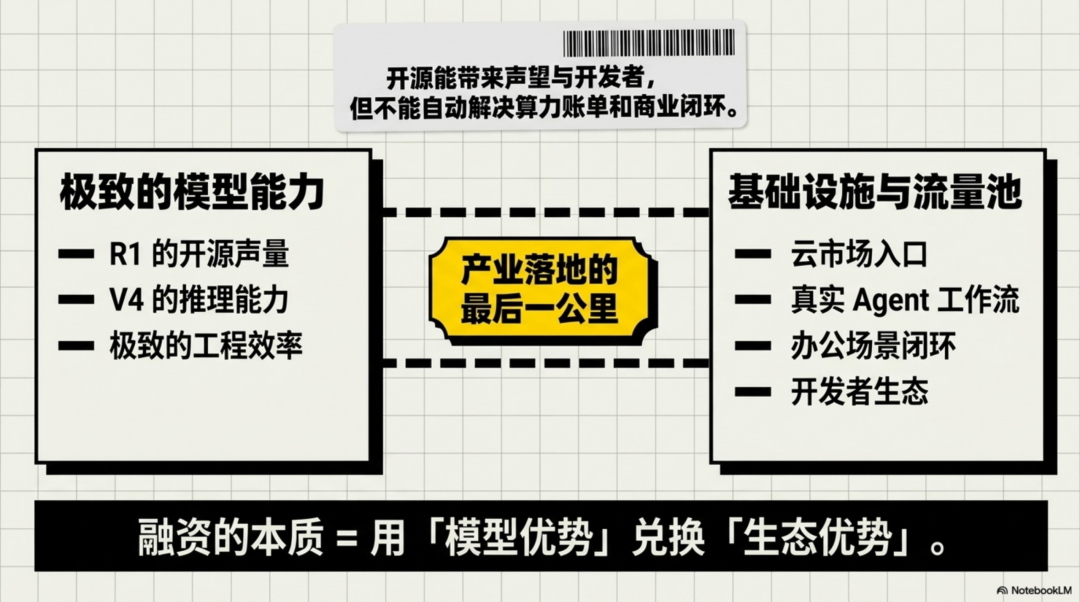
R1让DeepSeek出圈,但真正的问题是:出圈之后,流量、算力、API、开发者、企业客户、Agent应用、办公场景、云市场入口,谁来承接?
OpenAI背后有几乎所有大厂参与其中。Anthropic背后有亚马逊、谷歌。Gemini自身就是上市大厂谷歌旗下。xAI有马斯克系流量和资本。
国内大厂有自己的云、有App、有办公软件、有搜索、有支付、有内容生态、有企业客户。DeepSeek如果继续完全独立,它可以是最强开源模型之一,但很难独自完成从模型到产业基础设施的最后一公里。
DeepSeek需要把“模型优势”换成“生态优势”。
03 为什么是腾讯和阿里?
我在2025年2月分析过:如果DeepSeek必须拿大厂的钱,腾讯和阿里确实是最合理的两家。现在看,这个逻辑更强了。DeepSeek最终会拿谁的钱?
腾讯最适合做“低干预、高分发、高场景”的战略股东。
腾讯对DeepSeek的价值,在于三件事:入口、场景、组织耐心。
腾讯有微信、QQ、腾讯会议、企业微信、腾讯文档、腾讯云、游戏、内容和小程序生态。DeepSeek如果要做Agent,最难的不是模型本身,而是Agent能不能进入真实用户工作流。腾讯的场景是天然的Agent试验田。
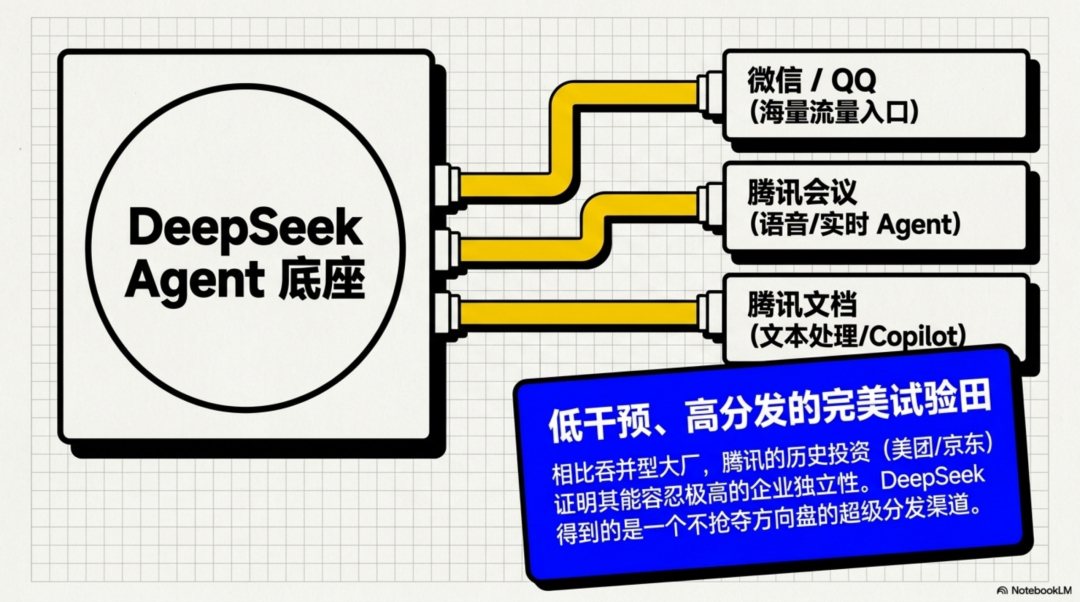
更重要的是,腾讯投资的历史口碑确实相对特殊。它不是没有战略诉求,但相比很多大厂,腾讯更习惯做“生态型投资”而不是“吞并型投资”。美团、京东、拼多多这些案例都说明,腾讯过去能接受被投企业保持相当独立性。
对DeepSeek这种极度重视研究文化和控制权的公司来说,这一点非常重要。
DeepSeek不需要和腾讯成为竞争对手。腾讯自己当然也做混元,但腾讯真正的强项是把最好的模型能力接入自己的应用和云生态。
如果DeepSeek拿腾讯的钱,是给自己找一个超级分发股东。
阿里最适合做“云+开源+开发者生态”的战略股东。
阿里对DeepSeek的价值则更偏基础设施。
阿里云是中国最重要的云计算平台之一,通义千问/Qwen又是国内开源模型生态最强的玩家之一。阿里此前在AI赛道是“买赛道”式布局:月之暗面、MiniMax、智谱、百川、零一万物等都曾进入阿里的投资版图。
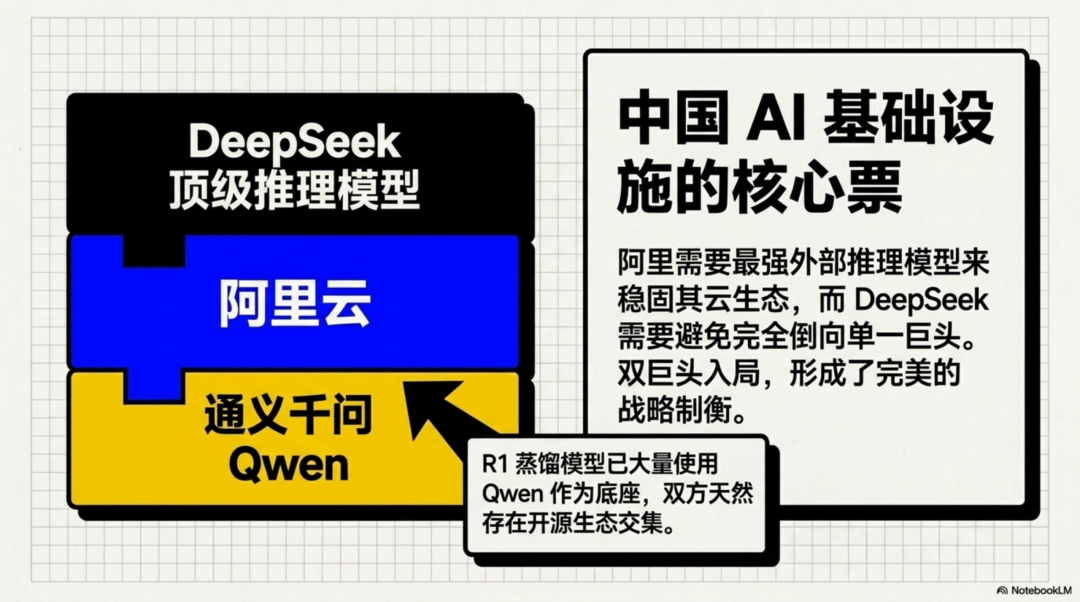
对阿里来说,DeepSeek如果持续强大,会带来几个价值:
- 增强阿里云在模型市场的吸引力;
- 补足阿里在最顶级推理模型上的外部生态;
- 和Qwen形成“自研+外部最强开源系”的双支点;
- 避免DeepSeek完全倒向腾讯或其他大厂。
DeepSeek R1发布时有一系列distill模型使用了Qwen和Llama作为底座,例如DeepSeek-R1-Distill-Qwen系列;这说明Qwen在国内开源生态里已经是重要基座。
DeepSeek的蒸馏模型体系曾使用Qwen作为重要底座之一,这让阿里与DeepSeek之间天然存在开源生态交集。
为什么不是字节?
字节当然也有钱、有流量、有模型、有产品。但正因为它都有,反而不一定是DeepSeek最舒服的股东。
字节已经重注豆包,且豆包是非常强的C端AI产品。如果字节投DeepSeek,战略协同很强,但竞争张力也更强。DeepSeek要保持独立研究路线,未必愿意进入一个已有强自研模型和强C端产品的大体系里。
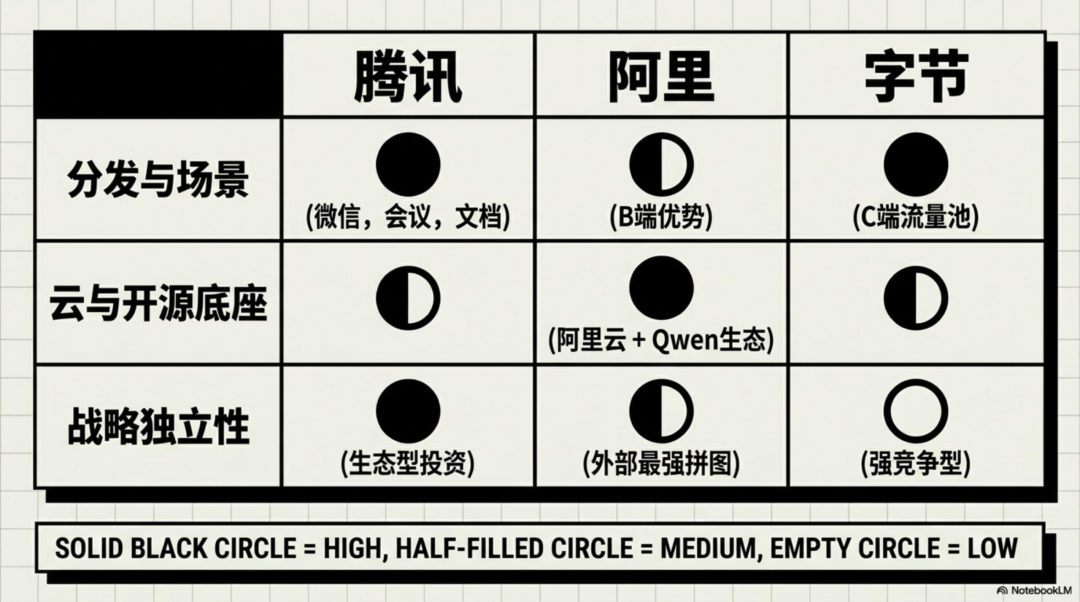
腾讯和阿里相比之下更像“互补型股东”:腾讯给入口和场景,阿里给云和开发者生态。字节则更像“强竞争型股东”:它能给很多,但也可能让DeepSeek的战略独立性变得更敏感。
04 这轮融资真正说明了什么?
过去DeepSeek像一个反常识样本:不融资、不营销、不卷商业化,靠一群年轻研究员和极致工程效率,突然打穿全球AI叙事。
但V4之后,它面对的是另一套规则:
V4之后,DeepSeek面对的是另一套规则:开源模型需要持续投入,低价API需要长期算力支撑,Agent能力需要场景闭环,百万上下文需要推理基础设施,顶级人才也需要资本化激励。更不用说,中国AI公司还要在芯片、云、监管和国际环境之间找平衡。
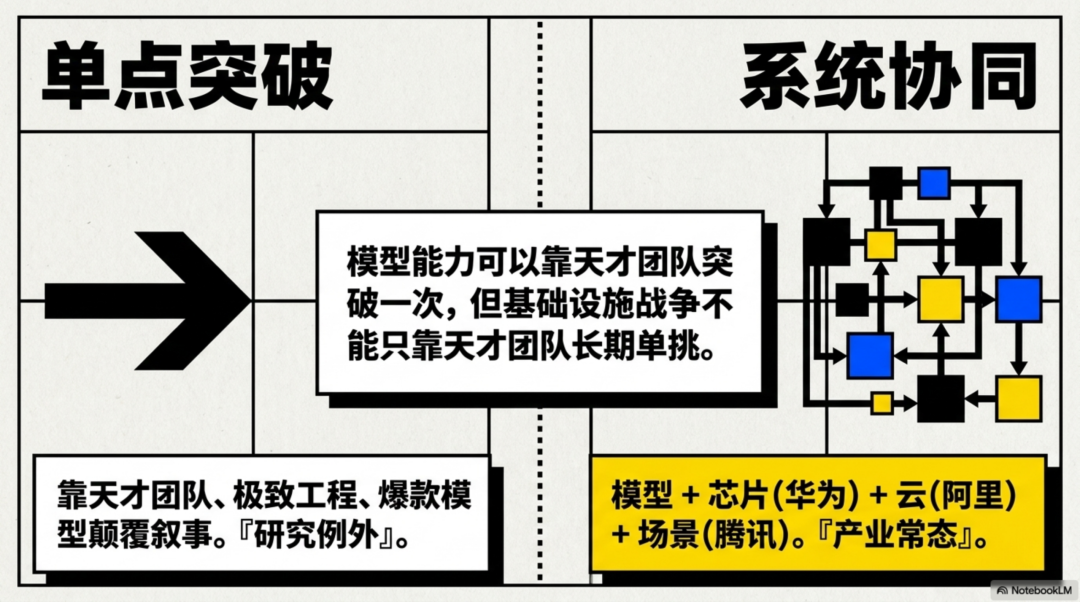
所以这轮融资如果落地,说明DeepSeek开始接受一个现实:模型能力可以靠天才团队突破一次,但基础设施战争不能只靠天才团队长期单挑。
DeepSeek要融资,也是在给自己补一套更稳的产业底座。模型越往后走,竞争就越不是单纯的算法竞赛,而是模型、芯片、云、框架和应用场景之间的系统协同。
腾讯和阿里能提供入口与云生态,华为昇腾则代表另一条国产算力路线。DeepSeek要成为基础设施级玩家,就不可能绕开这张产业网。
05 DeepSeek是怎么走到今天的?
DeepSeek的底色来自幻方量化。幻方长期把机器学习用于量化交易,这让梁文锋团队在DeepSeek成立之前,就已经习惯了一个高度依赖算法、算力和工程效率的环境。
所以DeepSeek一出来,气质就和很多AI创业公司不同。它不像典型VC驱动的模型公司,更像是从量化系统里长出来的AI研究组织。
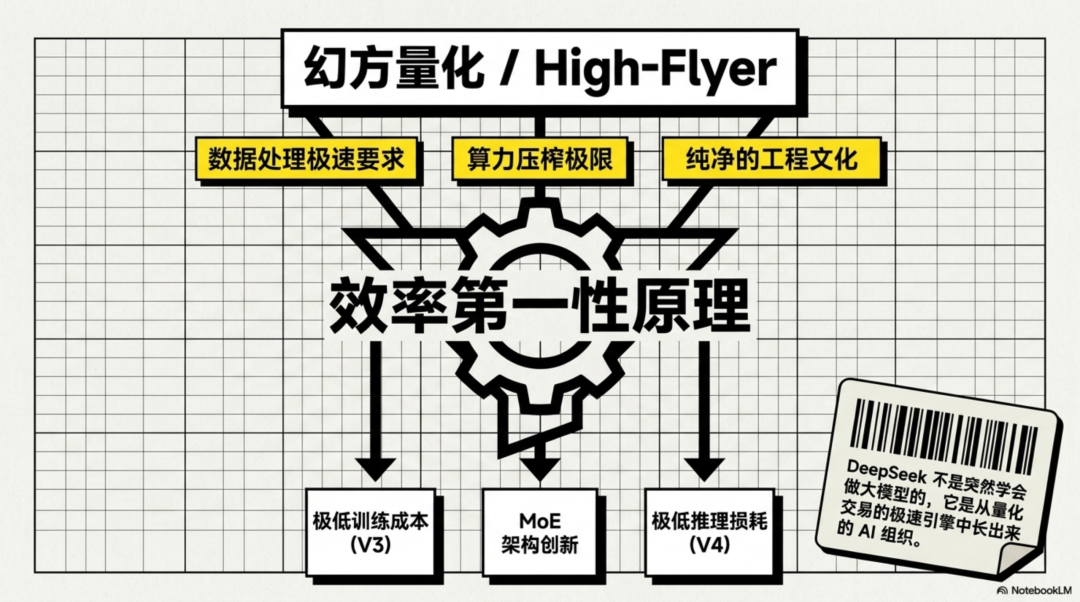
这种出身很重要。因为量化交易本身就是一个极度讲究效率的行业:同样的数据,谁处理得更快;同样的算力,谁压榨得更狠;同样的模型,谁能用更低成本跑出更好结果。这些东西,后来几乎都变成了DeepSeek做大模型时的核心方法论。
所以DeepSeek后来反复强调的“低成本”“高效率”“MoE架构”“更低推理成本”,并不是突然想出来的营销标签,而是它从幻方时代就继承下来的工程基因。
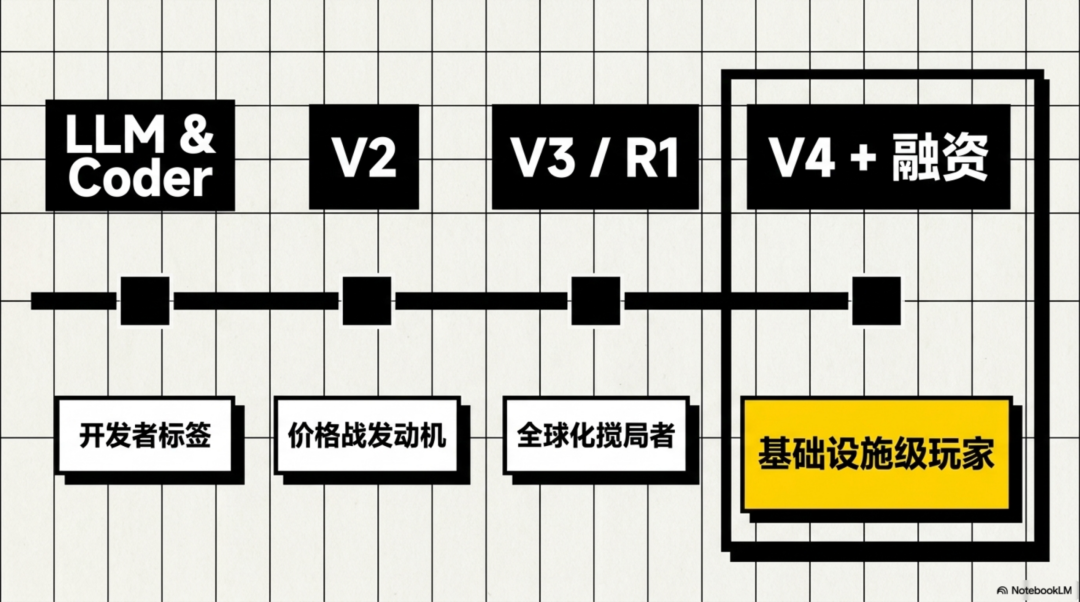
2023年DeepSeek正式成立之后,没有先做一个封闭的超级App,也没有先去铺天盖地做市场投放,而是选择了一个当时看起来没那么性感、但后来被证明很关键的方向:开源模型。
DeepSeek LLM、DeepSeek Coder这些早期模型,真正的意义是DeepSeek开始在开发者社区里建立一种标签:这个团队不是只会写论文,也不是只会讲中国版OpenAI故事,它是真的愿意把模型拿出来,让开发者用,让市场测,让同行比较。
代码模型尤其关键。代码能力好不好,开发者很快能试出来。DeepSeek早期通过Coder系列进入开发者视野,也为后来的R1爆发积累了第一批技术口碑。
真正让行业开始警觉的,是2024年的DeepSeek-V2。
V2不是一个大众爆款,但它在行业内部影响很大。因为它把DeepSeek的效率路线第一次打得非常清楚:MoE架构、低训练成本、低推理成本、高吞吐,最后直接引发国内大模型价格战。
这对行业的冲击很大。因为在此之前,大模型竞争基本默认是巨头游戏:谁有更多钱、更多卡、更多数据中心,谁就更接近终局。但DeepSeek-V2证明,工程效率本身也可以是一种战略武器。
到了2024年底,DeepSeek-V3发布,事情开始变得不一样。
V3把DeepSeek从国内技术圈推向全球模型竞争的核心位置。它用相对有限的训练资源,做出了一个足以和全球一线模型放在同一张表里比较的模型。
这就触碰到了全球AI行业最敏感的一根神经:如果一个中国团队可以用更低成本做出接近顶级闭源模型的开源模型,那么过去那套“只有极少数美国巨头才能玩得起大模型”的叙事,就会被动摇。
所以V3是DeepSeek的第一个全球信号。
真正让DeepSeek成为全球事件的,是2025年1月的R1。它让市场意识到,推理模型也可能被开源路线冲击。R1之后,DeepSeek不再只是开发者社区里的技术黑马,而变成了全球AI产业链都会关注的变量。
但爆火之后,DeepSeek遇到的反而是更难的问题。
一个研究型团队最擅长的是突破。可是当它变成全球关注的基础模型公司之后,要面对的就不只是模型能力了。用户会涌进来,API调用会增加,企业客户会提出稳定性要求,开发者会期待生态支持,同行会快速追赶,巨头会加码,人才会被争抢,监管和国际环境也会变得更复杂。
于是,DeepSeek原来那种“低调、独立、研究导向”的模式,开始遇到新的压力。
2025年2月之后,DeepSeek继续强化开源姿态,甚至释放更多代码库,试图巩固自己的技术社区。但从产业角度看,开源越成功,成本压力反而越大。因为开源可以带来声望、开发者、生态和扩散速度,却不能自动解决算力账单、推理成本、人才激励和商业闭环。
这就解释了为什么到了2026年4月,V4发布和融资传闻几乎同时出现。
V4说明DeepSeek还在往前冲,而且冲向的是更重的方向:百万token上下文、Agent能力、更强推理、更复杂的模型结构。这些能力都不是轻资产游戏。它们需要更大的训练投入、更强的推理基础设施,也需要更稳定的云资源和分发场景。
融资传闻的出现,恰恰说明DeepSeek正在从一个“能打仗的研究团队”,进入一个“要长期守城的基础设施公司”。
过去DeepSeek可以靠效率奇袭。
但到了V4阶段,它要面对的是持久战。
持久战不能只靠天才团队,也不能只靠幻方过去积累的资源。它需要资本,需要云,需要入口,需要开发者生态,也需要和中国最重要的科技平台建立某种战略连接。
所以,如果说V2证明了DeepSeek的效率,V3证明了DeepSeek的全球竞争力,R1证明了DeepSeek的破圈能力,那么V4和融资传闻共同说明的是:
DeepSeek正在告别“孤胆英雄”阶段。
它正在变成一个必须处理商业化、生态化、资本化和平台关系的玩家。
这也是DeepSeek故事最有意思的地方。
它一开始像是大模型时代的反叛者:不靠巨头,不靠VC,不靠铺天盖地的营销,而是靠模型本身把牌桌掀了一下。
但现在,它也不得不承认,AI战争越往后,越不是单点突破,而是系统竞争。
DeepSeek V4的发布,说明它仍然有单点突破的能力。
而腾讯、阿里的融资传闻,则说明它开始补上系统竞争的另一半。
所以DeepSeek的发展历程,一边是模型迭代线:LLM、Coder、V2、V3、R1、V4。

另一边是身份变化线:
从幻方量化的AI副线→独立的开源模型团队→
中国大模型价格战的发动机→到全球AI叙事的搅局者→
再到今天可能被华为、腾讯和阿里共同押注的基础设施级公司。
这是DeepSeek走到今天的两条路。
本文由人人都是产品经理作者【吴怼怼】,微信公众号:【吴怼怼】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自作者提供






- 目前还没评论,等你发挥!


