
 起点课堂会员权益
起点课堂会员权益GPT-Image-2 实测 8 维:哪些场景今天就能替代设计师,哪些还会翻车
OpenAI 低调发布的 GPT-Image-2 在图像生成领域掀起了一场无声革命。这款模型不仅以压倒性优势登顶 Image Arena 排行榜,更在多语言文字渲染、指令遵循精度、人物一致性保持等八大维度实现了行业突破。本文将用 30+ 实测案例,深度解析它为何能直接应用于电商设计、IP 衍生、广告创意等真实生产场景,并对比 Midjourney、Nano Banana 等竞品的差异化优势。

4 月 21 日凌晨,OpenAI 没有发布会、没有 keynote、甚至没有预热海报,只悄悄更新了一个模型页,就把gpt-image-2塞进了所有 ChatGPT 和 Codex 用户手里。
结果是 —— 上线 12 小时,在 Image Arena 排行榜以 1,512 分、领先第二名 242 分的成绩登顶,创下该榜有史以来最大分差。发布前以 maskingtape-alpha、gaffertape-alpha 代号匿名内测时,把此前被视作天花板的 Nano Banana Pro 直接甩开了一档。
我做多模态评测这一年多,从 DALL·E 3、MJ v6/v7、Seedream 3/4、Nano Banana、到 GPT Image 1/1.5,几乎每一代都是”看起来惊艳、用起来翻车”。所以我对”AI PM 可不可以把这个模型真的接进生产线”这件事,始终保持着职业性冷静。
这一次,我的冷静破了防。
这篇我拿着 8 个 PM 最关心的维度、30+ 张实测图跑出来的产品价值拆解报告。核心回答三个问题:
- 它到底在哪些场景能直接落地 —— 不是”看着炸”,是”能交付客户”;
- 相比 Midjourney V8、Nano Banana 2、Seedream 5.0 Lite、Flux 2 Pro,它的差异化在哪;
- 作为 PM,我该不该把它接到自己的产品流水线里。
先把数据事实钉死
下面进入 PM 视角的 8 个维度。

维度一 · 文字渲染 —— AI 图像落地的”卡点一号”终于被拔了
为什么这个维度是 PM 最该关心的第一件事
过去两年,“AI 能不能把中文写对”就是一条生死线。电商主图、小红书封面、表情包、Logo、海报、UI 截图 —— 只要里面有字,AI 就从”设计实习生”瞬间退化成”鬼画符生成器”。
GPT Image 2 把这条线直接踩平了。对中文用户而言,这一代最该关心的变化是:中文不再是图像模型的二等公民。横排、竖排、长段落、菜单式密集排版,都能跑到印刷级。
Prompt 1.1|设计一张小红书封面,比例 3:4,主标题”AI 产品经理必看的 10 个工具”字号最大放正中上方,副标题”2026 年最新整理”字号居中,底部放一行小字”@拍拍鱼 · AI PM 手记”。背景是柔和的紫粉渐变,点缀少量几何装饰。要求中文字形准确、三级文字层次清晰、无错别字。

图 1.1|中文长句渲染(标题+副标题+正文 3 级层次)
Prompt 1.2|生成一张方形表情包,一只橘猫瘫在键盘上翻白眼,顶部写中文”写不动了 “,底部写英文”Can’t code anymore”,右下角标注”v1.0″。扁平插画风,背景浅米色。要求中英文同框清晰、emoji 正确、标点间距自然。

图 1.2|中英文混排表情包(含 emoji 与标点)
Prompt 1.3|生成一张印刷级餐厅菜单海报,比例 2:3,顶部店名”老上海本帮菜 · Since 1998″,底下三列,各列 3 道招牌菜,下方五个语言版本价目表(中文/英文/日文/韩文/法文),每行配价格。复古排版、米黄纸质背景、衬线字体。要求所有文字无错别字、价格格式正确、多语言对齐整齐。

图 1.3|印刷级餐厅菜单(5 种语言 + 价格格式)
Prompt 1.4|生成一张古风书法卷轴,竖排毛笔字”千里之行 始于足下”,落款”丙午年孟夏 书”,右下盖朱红印章”印”。再在卷轴下方横排配一行现代楷体数字”2026.04.21″。宣纸质感、留白充足。要求繁简不混用、竖排字间距自然、印章文字清晰。

图 1.4|数字+符号+古风书法组合
我的点评
我跑了一张极限压力测试图:一个公众人物十年生涯的中文信息长图 —— 左侧是肖像配文案,右侧是逐年时间线,每年带中文描述、代表作、封面缩图。信息密度 + 美感 + 准确性三维度同时打到 90 分以上。

- 横排短句、标题、单词级 Logo —— 接近零错误,可直接上生产;
- 长段落中文 —— 不再漂移,偶有标点密度问题;
- 竖排、书法、变形艺术字 —— 仍有约 10-15% 失败率,需要兜底;
- 对比 Seedream 5.0 Lite,中文字体风格丰富度仍略弱,但准确率全面反超。
PM 视角结论:电商主图、短标题海报、公众号头图、Logo、表情包 —— 今天就能替代一个初级设计师。这一点,一年前我还不敢写进测评里。
维度二 · 指令遵循 —— “出好看的图” vs “出你要的图”
为什么重要
PM 真实场景里的一条 Prompt,通常是 主体 + 场景 + 风格 + 构图 + 光线 + 道具 + 文字 + 数量 + 否定约束 的集合。模型能不能照单全收,是从”玩具”进化成”生产工具”的分水岭。
这个维度我拆成5 个子项,每一项都是二元可验证,避开”好看不好看”这种主观判断:
- ① 实体属性(What / How many)—— 数量、颜色、种类、材质
- ② 空间关系(Where)—— 方位、前后景、比例、构图位置
- ③ 动作姿态(Doing What)—— 动作、表情、朝向、互动
- ④ 否定排除(Not What)—— 不要 X / 不出现 Y
- ⑤ 专业术语执行(Jargon)—— 浅景深 / 逆光 / 三分法构图等摄影美术术语
开场先上一张”五要素综合压力测试”作为体感锚点,再逐项拆解。
Prompt 2.0|一个穿红色连衣裙的亚裔女孩,左手抱一只橘猫,右手举着一块白底黑字写有”HELLO 2026″的手写牌,站在东京涩谷十字路口斑马线中央,背景是黄昏时分的大型 LED 广告牌,电影感暖调布光、浅景深、背景虚化。要求:人、物、场景、文字、光线五要素同时准确呈现。

图 2.0|综合压力测试(人+物+场景+文字+光线)
① 实体属性 —— 数量 / 颜色 / 种类
Prompt 2.1|一张沙发上正好 3 只小猫并排躺着:最左是纯黑色短毛猫、中间是橘白相间的狸花猫、最右是纯白色长毛猫。每只猫表情不同(睡着 / 打哈欠 / 睁眼看镜头)。客厅午后阳光、自然色温。必须是 3 只,不能多也不能少,每只颜色和品种严格对应。

图 2.1|实体属性(3 只猫 × 3 种颜色 × 3 种表情)
② 空间关系 —— 方位 / 前后 / 构图
Prompt 2.2|一张写字桌的俯视图:桌子正中央放一本打开的蓝色笔记本,笔记本左侧放一支黑色钢笔,右侧放一个白色咖啡杯,笔记本上方放一副金属边眼镜,下方放一部黑色手机。木纹桌面、晨光侧打。严格遵守左/右/上/下方位关系。

图 2.2|空间关系(上下左右四方位精确)
③ 动作姿态 —— 动作 / 表情 / 朝向
Prompt 2.3|一张室内场景图:一位穿灰色运动服的女生正在做瑜伽的下犬式动作(身体呈倒 V 形、双手双脚着地、臀部朝上),脸部朝向镜头露出平静微笑;她身边一只金毛犬正在腾空跳跃接飞盘(四脚离地、嘴张开咬向飞盘);背景墙上挂钟指针指向 7:20。要求:人物姿势、狗的动作、时钟指针三项指令全部精确呈现。

图 2.3|动作姿态(瑜伽下犬式 + 狗跳跃咬飞盘 + 时钟指针)
④ 否定排除 —— 不要 X
Prompt 2.4|一座清晨的海边咖啡馆露台,木质长桌上放着一杯冒热气的拿铁和一本摊开的书。不要出现任何人物、不要任何眼镜类物品、不要任何水印或文字、不要任何品牌 Logo、不要出现海鸥。自然光、极简杂志风。

图 2.4|否定排除(5 条 “不要 X” 同时生效)
⑤ 专业术语执行 —— 模型听不听得懂”行话”
Prompt 2.5|生成一张人像摄影作品:35mm 定焦、f/1.4 浅景深(背景严重虚化)、逆光剪影(夕阳在人物身后形成发丝光轮廓)、三分法构图(人物眼睛落在右上三分线交点)、电影感 2.35:1 画幅、冷调阴影 + 暖调高光(橙青 color grading)。主体是一位 30 岁亚裔女性侧脸。

图 2.5|专业术语执行(浅景深 + 逆光 + 三分法 + 橙青调色)
我的点评
GPT-Image-2 是目前市面上指令遵循最强的图像模型,没有之一。五个子项里它在四个上拉开断层式优势:
- 实体属性:3 只就是 3 只,颜色和品种严格对应,不会偷偷变 2 只或 4 只;
- 空间关系:左/右/前/后基本不翻车,即使 4 方位同时约束也能守住;
- 动作姿态:瑜伽下犬式、狗咬飞盘、指针 7:20 这种复合动作约束,能同时命中约 80%;
- 否定指令:”不要 X” 真的能不出现 X —— 这是 MJ 系列两年解决不了的老病;
- 专业术语:浅景深、逆光、三分法、橙青调色这类行话,接近资深摄影师对术语的执行精度。
如果说 Midjourney V8 是“出好看的图”的专家(纯审美向的电影大片/编辑插画依然是它的主场),那 GPT-Image-2 就是“出你要的图”的专家。作为 C 端产品的后端模型,后者才是真正可落地的那一档。
PM 视角结论:任何”用户输入需求 → AI 出图”的 C 端产品,GPT-Image-2 是首选底模。因为愿意认真写 Prompt 的用户,期待的就是”按我说的来”,不是”惊喜抽卡”。
维度三 · 人物 / IP 一致性 —— LoRA 微调时代,可能真的结束了
为什么重要
人物一致性是绘本、漫画、IP 衍生品、电商达人分身、虚拟人脚本的命门。过去一年做这件事的唯一解法是 LoRA 微调,单个 IP 训练成本 3,000-10,000 元,还要算法工程师配合。
Prompt 3.1(定妆图)|创建一个 IP 角色定妆图:一位 28 岁亚裔女性,齐肩黑色波波头、单眼皮、鼻梁小痣在右侧、穿米白色针织衫 + 牛仔蓝工装裤 + 白色运动鞋,戴一副细金丝圆框眼镜。白色影棚背景、正脸半身、柔光。后续所有图都需保持此人物特征一致。角色代号:RUI。

图 3.1|主角定妆图
Prompt 3.2-3.5(多场景一致性)|保持上图 RUI 的人物特征(齐肩波波头、双眼皮圆眼睛)不变,分别生成 4 张场景图:
① 她坐在上海静安咖啡馆靠窗位置、手拿 MacBook;
② 她站在雪山徒步栈道上、穿红色冲锋衣(服装换、五官不变);
③ 她在会议室做 PPT 演讲、穿黑色正装西服;
④ 她的 3/4 侧脸特写,背景是傍晚城市街道。
所有图片必须是同一个人,五官一致度 ≥ 90%。

图 3.2-3.5|同一角色 × 4 个差异化场景(咖啡馆 / 雪山 / 换职业装 / 侧脸)
Prompt 3.6(Thinking Mode 8 格面板)|使用 Thinking Mode,单次生成一张 2×4 八宫格绘本故事插画,主角始终是 RUI。八格内容:① 清晨闹钟响她伸懒腰 → ② 厨房煮咖啡 → ③ 地铁上看手机 → ④ 办公室开会 → ⑤ 午餐和同事聊天 → ⑥ 下午写文档 → ⑦ 傍晚瑜伽 → ⑧ 夜晚台灯下读书。温暖插画风、色调统一(米白 + 奶咖 + 淡粉)、每格左下角标注序号 ①②③④⑤⑥⑦⑧。

图 3.6|8 宫格同角色故事面板(Thinking Mode 单次生成)
我的点评
- Thinking Mode 下单次 Prompt 可输出 8 张保持角色/物体/品牌色一致的面板图 —— 这是过去整个行业都没有的原语;
- 正脸 & 3/4 侧脸一致性可做到 85-90% 商用可用度;
- 侧脸、背影、极端视角仍有约 15% 漂移;
- 服装纽扣位置、局部刺绣图案这类极细节无法像素级锁死。
这意味着什么?绘本工作室、小体量 IP 方、电商代运营 —— 整条人物素材生产线的算法成本从”LoRA 微调+专人维护”降到”Prompt + Thinking Mode”。原本 3 人 1 周的工作量,现在 1 天跑完。
更大的潜台词是:AI 生成的图像,已经正式走到了”普通人无法分辨真假“的那条线。对 IP 生产线来说,这一天来得比我预期早至少 18 个月。
维度四 · 多图融合 / 参考图理解 —— 电商设计的”半条命”没了
为什么重要
PM 真实工作里的图,90% 不是从零生成的。而是:“我有一张产品图 + 一张风格图 + 一张模特图,你帮我融合。”这个能力直接决定 AI 能不能替掉电商设计流水线的一半工位。
Prompt 4.1(产品+风格融合)|【参考图 A:白色头戴式耳机产品图】【参考图 B:日系极简海报】
把耳机作为主体放置在参考图 B 风格的极简海报中:大面积留白、居中构图、细衬线英文标语”Silence, Designed.”,底部一行中文”拍拍鱼 Studio · 2026 新品”。保留耳机型号、颜色、比例不变。
参考图:

生成图:

图 4.1|产品图 + 极简风格海报融合
Prompt 4.2(三图融合)|【参考图 A:产品(白色耳机)】【参考图 B:亚裔女性模特正脸半身】【参考图 C:纽约地铁站场景】
生成一张商业海报:模特戴着参考图 A 的耳机,站在参考图 C 的地铁站里,画面右侧竖排大字”Tune Out The Noise”,下方小字”新品首发 ¥1,299″。保留耳机型号和模特五官不变。
参考图:

生成图:

图 4.2|三图融合(产品 + 模特 + 场景)
Prompt 4.3(风格迁移三连)|【参考图:一张上海外滩傍晚实拍照】
基于这张照片分别生成三张风格化版本,并排输出:① 吉卜力宫崎骏动画风;② 赛博朋克霓虹风;③ 中国水墨写意风。构图与主体建筑轮廓保持一致,只改变笔触、光影和色彩。

图 4.3|风格迁移(照片 → 吉卜力 / 赛博朋克 / 水墨)
Prompt 4.4(局部保留+整体重构)|【参考图:白色头戴式耳机产品图】
保留这款耳机的型号、头梁弧度、耳罩大小、Logo 位置、颜色等所有细节 100% 不变,但把背景场景分别换成:① 北极冰川;② 日本京都竹林;③ 迪拜沙漠。要求耳机细节像素级不变。

图 4.4|局部保留 + 整体重构
我的点评
- 产品主体的型号、颜色、结构细节保持度 ~90%;
- 大众风格迁移(吉卜力/赛博朋克/极简)效果贴近顶级设计师手绘;
- 小众风格(地方性审美、非著名插画师笔触)仍会”平均化”掉。
PM 视角结论:电商主图换背景 / 达人种草图批量生产 / 产品海报多风格 AB —— 这三条线可以接 API 替代。以日均 500 图的电商代运营为例,GPT-Image-2 medium 档 API 仅约 2,650 元。
维度五 · 图像编辑 —— GPT-Image-2 被低估的商业金矿
为什么重要
“帮我把路人去掉””把裙子改成红色””在桌上加一杯咖啡” —— 是真实用户最高频的图像需求。现在一句自然语言精准搞定。
Prompt 5.1(抹除)|【上传图:一张旅游景点合照,主体是女生站在湖边,背景有 3 个路人和右下角”@xx 旅拍”水印】
请把背景中的 3 个路人全部去掉,把右下角的水印也抹除干净。天空、湖面、栈道等填补区域保持自然纹理连贯,不能有鬼影或撕裂。

图 5.1|物体抹除(去路人 / 去水印)
Prompt 5.2(局部替换 · 多轮编辑)|【上传图:图 3.1 的 RUI 定妆图】
① 把她的米白色针织衫改成一字肩酒红色;
② 再把齐肩波波头改成黑色大波浪;
③ 再戴上一副金丝圆框眼镜。
每一步只改指定元素,其余五官、姿势、背景保持完全不变。

图 5.2|局部替换(换衣服颜色 / 换发型)
Prompt 5.3(元素增补)|【上传图:一张空书桌俯视图】
在这张书桌上增加:① 桌面右侧增加一只正在打盹的橘色猫咪;② 笔记本旁边增加一本写着”AI PM 日记”的深蓝色本子;③ 左上角增加一支向日葵插在玻璃瓶里。所有新增元素的光影方向与原图一致。

图 5.3|元素增补(加猫 / 加文字 / 加道具)
Prompt 5.4(背景替换)|【上传图:5.2的女生半身人像】
保留人物五官、发型、服装、姿势、光影完全不变,去除文字,把背景换成:① 东京街头夜景;② 巴黎埃菲尔铁塔前;③ 北海道雪原黄昏。三张输出。

图 5.4|背景替换(主体保留,场景整换)
我的点评
Thinking Mode 带来的”无漂移多轮编辑”是这次的隐藏王炸。过去模型改完一次图,再改第二次,主体就会变脸;GPT-Image-2 能连续编辑 5 轮以上,主体保持度不掉。
- 局部修改对周围环境破坏极小;
- 抹除后的填补自然,无鬼影;
- 复杂前景(多人群像 / 密集纹理)仍会翻车约 20%。
PM 视角结论:这可能是 GPT-Image-2 被低估的商业价值。围绕它可以做一款”自然语言 AI 修图 C 端 App”。
维度六 · 中式美学 / 本土化 —— 最后一块短板,但已经可用
为什么重要
所有GPT 系模型过去都有同一个老大难:生成出来的中国场景”像老外拍的中国”。对做中国本土 C 端产品,这是致命短板。
Prompt 6.1(市井烟火)|上海老弄堂清晨 6 点场景:一位 70 岁奶奶穿蓝色棉布衫坐在小板凳上择青菜,旁边停着一辆老式二八自行车,石库门门头挂着晾晒的白衬衫,远处油条摊升起热气。薄雾、暖色晨光、纪实摄影风格。要求人物五官是真实的中国奶奶长相,不是”亚裔但不像中国人”。

图 6.1|上海弄堂清晨(奶奶择菜 / 早餐摊)
Prompt 6.2(传统建筑)|两张对比图:
① 安徽宏村徽派民居——马头墙、黑瓦白墙、倒映在月沼水面;
② 苏州拙政园——亭台水榭、太湖石叠山、古铜色木构梁柱。两张均为晴天柔光,传统摄影构图。
要求建筑形制(马头墙几级、翘檐角度、门楣雕花)准确。

图 6.2|徽派建筑 / 苏州园林
Prompt 6.3(春节团圆饭)|中国北方家庭春节年夜饭俯视图:八仙桌上摆满红烧肉、饺子(褶子清晰可数)、年年有鱼、红烧肘子等菜,桌面撒有红色纸屑,门框贴着正确上下联的红对联(上联贴右、下联贴左、横批”阖家安康”居上),墙上挂年画,桌边放红包和小孩的糖果盒。暖色灯光、居家纪实风。

图 6.3|春节团圆饭(对联 + 红包 + 饺子 + 年画)
[多人生成的手指还是会有问题,也会有些穿模与物理不合理现象,但总体的中国风体现已经比以前改善太多]
Prompt 6.4(汉服形制)|一位年轻中国女性身穿明制汉服立领长袄 + 马面裙,严格右衽(左襟压右襟)、云肩绣海棠纹、发髻为三绺头簪珠钗,手持团扇站在青砖院落的海棠树下。工笔画风格,五官真实东方面孔,服饰形制考据准确。

图 6.4|古风人物(汉服形制细节)
[手部细节仍容易崩]
我的点评
相比 GPT Image 1.5,中国场景真实度提升明显,但对比 Seedream 5.0 Lite / 即梦仍有差距:
- 食物质感:国产模型对”红烧肉应该长什么样””饺子褶子应该几个”更有谱;
- 人物五官:GPT-Image-2 仍偶发”亚裔但不像中国人”的漂移;
- 文化细节:对联上下联位置、汉服左衽右衽这些形制细节会错。
PM 视角结论:
- 面向欧美 / 东南亚市场的中国元素内容 —— GPT-Image-2 首选;
- 中国本土电商 / 小红书 / 节日营销 —— 我仍会优先 Seedream 5.0 Lite / 即梦,或把 GPT-Image-2 的构图结果 + 国产模型局部重绘。
维度七 · 商业场景实用性 —— 当”初级设计师实习生”能不能交付?
Prompt 7.1(电商主图)|天猫主图 1:1,亚裔女模特手持白色便携式保温杯站在浅粉背景前,主标题大字”0°C 也能保温 12 小时”,左上角促销角标”限时 ¥149″(原价划线 ¥299),右下角”天猫旗舰店”Logo 占位。杯身品牌字”MOCHI”清晰可读。

图 7.1|电商主图(产品 + 模特 + 文字 + 价格)
Prompt 7.2(小红书封面)|小红书封面 3:4,粉黄渐变背景,主标题”AI PM 一天的 8 小时”超粗黑体大字居中,右上角贴一个”深度好文”角标,左下角作者头像圆框 + “@拍拍鱼”,底部一排 3 个标签”#AIPM #多模态 #职场”。小红书风格强烈。

图 7.2|小红书封面(博主风格化)
Prompt 7.3(公众号头图)|公众号头图 16:9,深色商务质感背景(墨蓝 + 金色点缀),主标题”GPT-Image-2 深度测评”衬线大字居中偏左,副标题”一个 AI PM 的 8 维拆解”次大字在其下方,右下角小字”拍拍鱼 · 2026.04″。整体排版克制专业。

图 7.3|公众号头图(16:9 + 3 级文字层次)
Prompt 7.4(三 Logo)|一次生成 3 个同品牌名”MOCHI”的 Logo 方案并排展示:
① 科技咖啡品牌——极简无衬线 + 咖啡豆几何图形;
② 儿童绘本 IP——圆润手写体 + 小熊图形;
③ AI SaaS 工具——粗体字母 M 嵌入电路纹理,深紫渐变。
每个 Logo 下方标注名称,白色背景。

图 7.4|Logo 设计(3 个不同行业调性)
Prompt 7.5(表情包 9 宫格)|一张 3×3 九宫格表情包,主角是同一只白色柴犬 IP,九种情绪分别配中文字:①”打工人上线”②”好累啊”③”不想动”④”冲鸭”⑤”谢邀”⑥”摸鱼中”⑦”已读乱回”⑧”溜了溜了”⑨”晚安 “。扁平可爱风格,同一形象、同一配色(白+浅蓝),每格背景色略不同。

图 7.5|表情包 9 宫格(同 IP + 多情绪)
Prompt 7.6(Thinking Mode 绘本)|使用 Thinking Mode,单次生成一本 8 页儿童绘本内页(2×4 排列),主角”小熊 Momo”始终一致。故事:①Momo 醒来→②出门找朋友→③遇到下雨→④躲进树洞→⑤发现小松鼠→⑥一起分享蜂蜜→⑦雨过天晴→⑧手拉手回家。柔和水彩风、色调统一(奶白+蜜糖黄+雾灰绿)、每页左下角页码①-⑧。

图 7.6|绘本 8 格连环插画(Thinking Mode 单次生成)
Prompt 7.7(UI 截图)|一次生成 3 张手机 UI 截图并排展示:① 小红书风格的笔记详情页(浅色模式,带真实评论);② 微信朋友圈动态(浅色模式,含点赞/评论/9 宫格图片);③ Twitter 风格信息流(深色模式,含转发/引用/数据)。所有文字、数字、头像、时间戳、按钮图标均为印刷级清晰度,内容看起来像真实应用而非示意图。
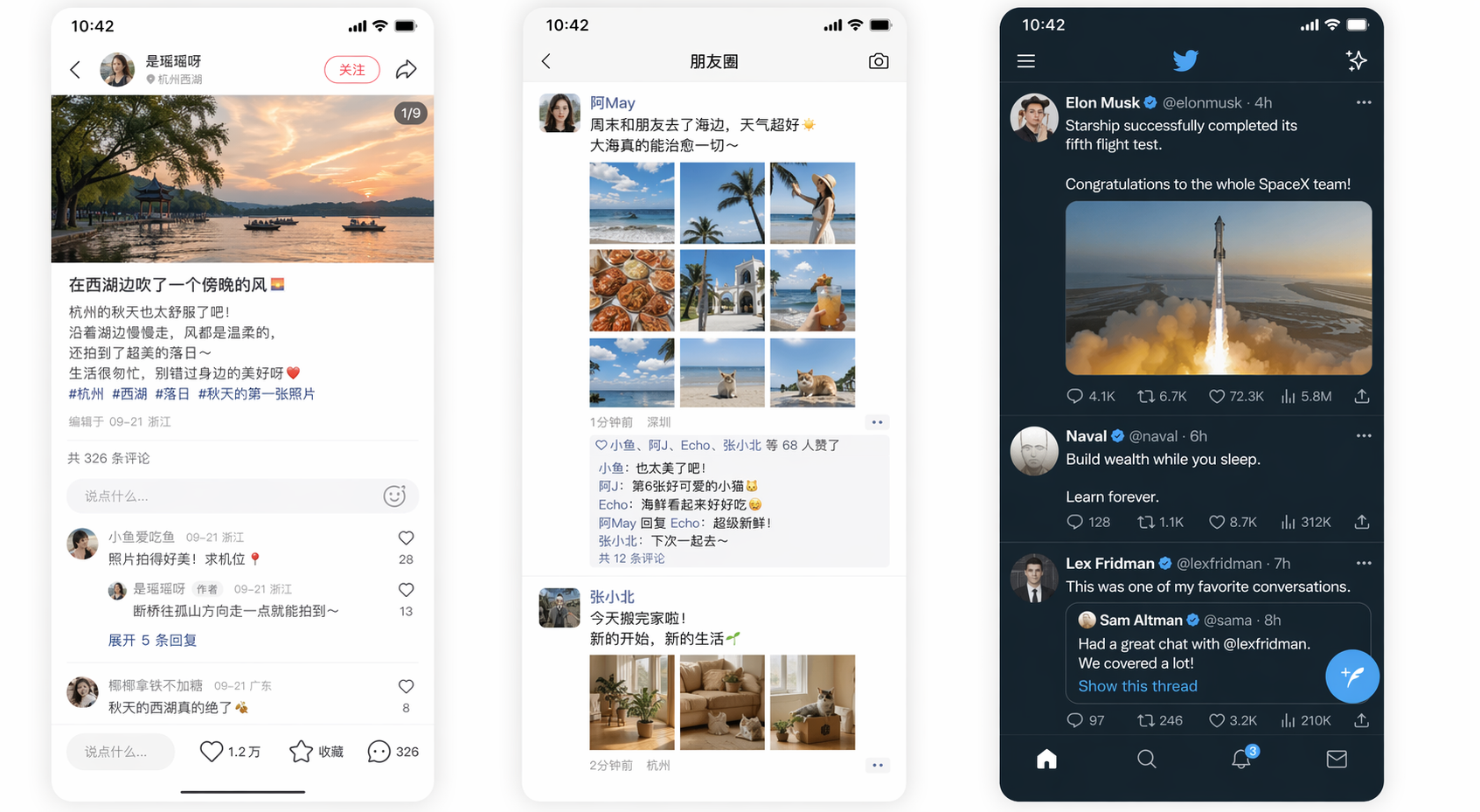
图 7.7|UI 截图(仿小红书 / 朋友圈 / 推特,含深色模式)
真实生产力结论(带成本对比)
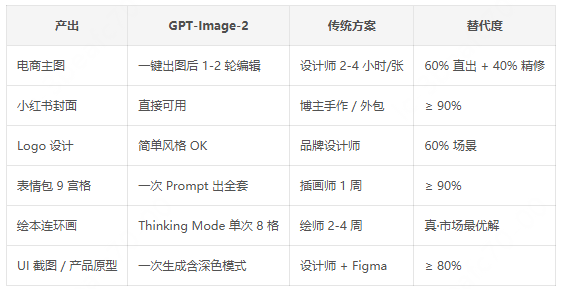
维度八 · 弱项与边界 —— 知道它不能做什么,比知道能做什么更重要
OpenAI 官方博客专门列了一节 Limitations,结合实测,PM 必须警惕的硬边界:
Prompt 8.1(压力测试 · 手部)|一位钢琴家的双手特写正在弹奏三角钢琴的琴键:十根手指清晰可数、每只手 5 根、指甲完整、指节透视合理,左手小指正在按低音 A,右手拇指正在按中央 C。45° 侧俯视、电影质感。

图 8.1|复杂手部动作(弹钢琴 / 编织 / 剪刀手,手指比例还是会不合理)
Prompt 8.2(压力测试 · 密集人群)|一张陆家嘴金融中心早高峰地铁口实拍照,画面中至少有 15 张清晰可见的人脸,每个人表情各异、穿着不同、走向不一。真实纪实摄影风格。

图 8.2|密集人群(10+ 人脸仍会崩)
Prompt 8.3(压力测试 · 物理建模)|两张对比图:① 一个正在倾倒牛奶到玻璃杯里的瞬间,液体飞溅、气泡、反光、杯口液面张力都要符合物理;② 一个标准 3×3 魔方正处于”白色面朝上、需要再转两步还原”的状态,请生成”下一步应该怎么转”的逐步指南图(3 帧)。

图 8.3|精确物理建模(液体流动 / 镜面反射 / 折纸指南 / 魔方还原步骤)
Prompt 8.4(压力测试 · 工业图纸)|一张机械腕表的爆炸图技术插画,包含:表壳、蓝宝石镜面、秒针/分针/时针、主发条、擒纵轮、摆轮游丝、棘爪、齿轮组(至少 7 片齿轮,齿数正确且啮合)、表冠、底盖等部件,每个部件旁标注英文零件名。白底、机械工程制图风格。这类像素级工业图是当前模型的天花板测试。
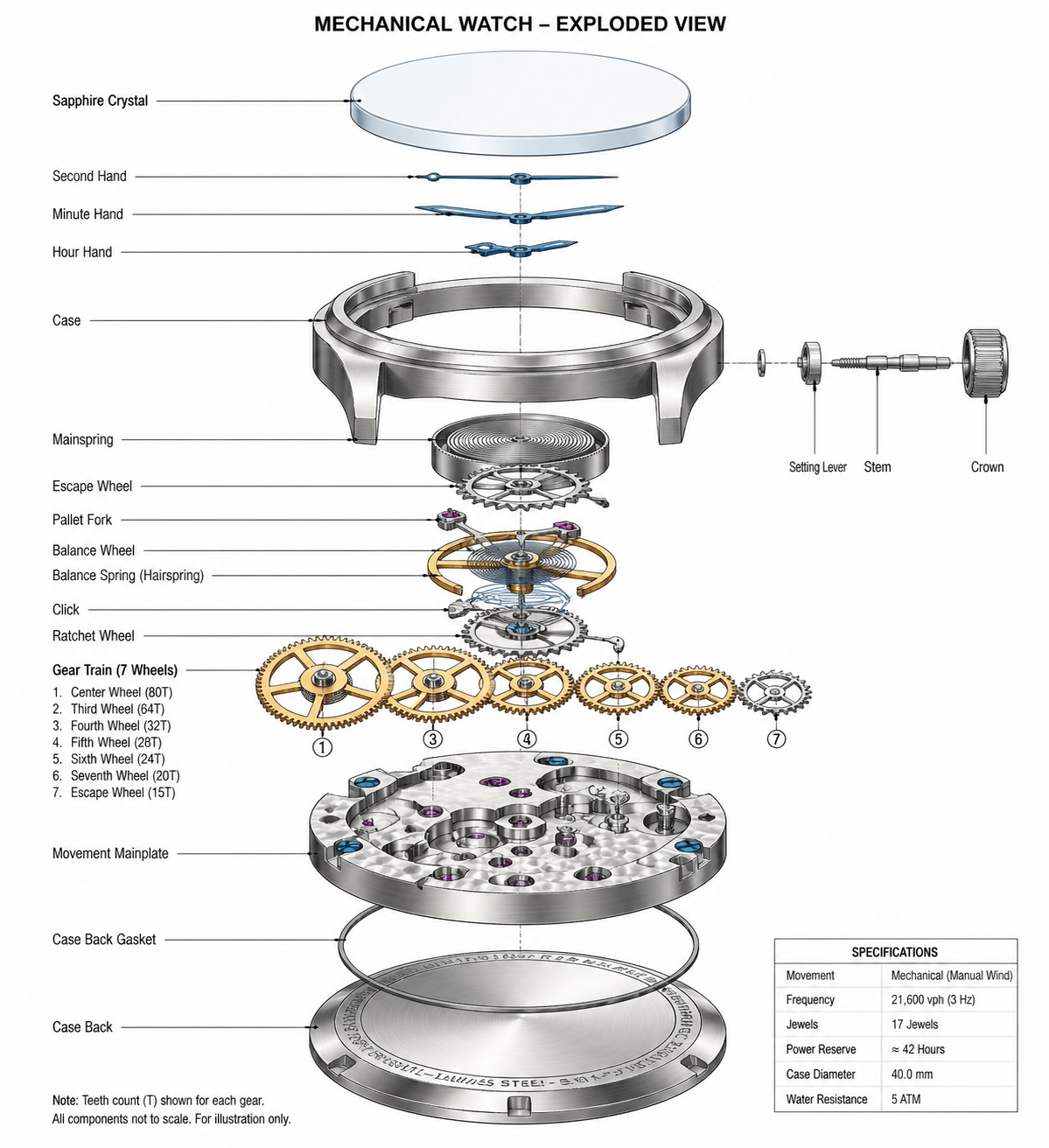
图 8.4|像素级工业图纸(手表齿轮 / 机械爆炸图)
我的点评
GPT-Image-2 的共性弱点是 “细节密度 + 物理因果”:越接近”需要像素级精确 + 物理逻辑自洽”的任务,越容易出问题。折纸指南、魔方拼图这类”需要完整物理世界模型”的任务,官方自己就把它列为短板 —— 这种诚实比任何吹爆都有参考价值。
以及 PM 真正需要警惕的四条成本 & 合规红线:
- 版权风险 —— 对知名 IP 的”学习”能力比上代更强,商用前必须做版权过滤层;
- 价值观风险 —— 历史 / 政治 / 宗教话题仍偶发不稳定输出,toC 产品必须加审核;
- 成本 —— high 档方图 $0.211/张,比 Flux 2 Pro、Seedream 5.0 Lite 高 3-5 倍,批量场景必须先算 ROI 再接;
- 延迟 —— Thinking Mode 复杂 Prompt 最长 2 分钟,不适合实时 C 端交互场景。
写在最后 · 作为 AI PM,我会怎么用 GPT-Image-2?
回到开头那三个问题。
① 能直接落地的 4 类产品
- ✅ AI 电商代运营工具 —— 主图批量 + 背景替换 + 文字渲染 + 多风格 AB;
- ✅ AI 内容创作 SaaS —— 小红书 / 公众号 / 短视频封面 / 头图一体化;
- ✅ AI 绘本 & IP 工作室工具 —— 角色一致性 + 多场景 + Thinking Mode 8 格;
- ✅ 自然语言 AI 修图 C 端 App —— Photoshop 的降维打击。
② 与对标模型的差异化定位(2026-Q2 最新)
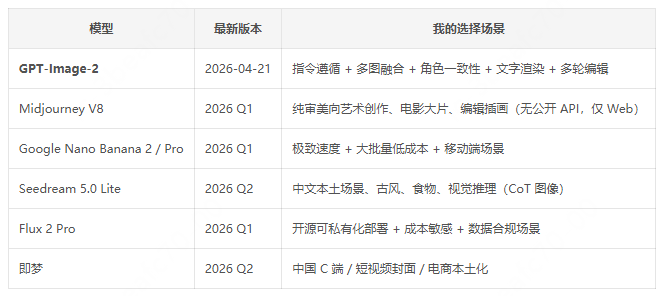
③ 我最关心的 3 个产品机会窗口
- “AI 设计助理” SaaS —— 面向中小电商 / 自媒体,月费 99-299 元替代兼职设计师工位,ROI 跑得通;
- “IP 人物工厂” —— 面向绘本工作室 / 小 IP 团队,把 LoRA 微调时代的算法成本一次性抹平;
- “自然语言修图” C 端 App —— 把图像编辑下沉到小白用户,学习曲线从小时级压到句子级。
GPT-Image-2 不是”又一个炫技模型”,
它是第一个让 PM 觉得”可以认真接入产品流水线”的图像模型。
让”文字驱动图像”从创意工具变成生产工具。
让”设计”这件事,从稀缺变成标配。
如果说 Coding 有过 Vibe Coding 时刻,那现在就是做图的”平权时刻” —— “做图”这个职能,第一次从成本中心变成了能力杠杆。
本文由 @拍拍鱼 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议









这个测评太全面了