
 起点课堂会员权益
起点课堂会员权益YC 今年最想投的两个赛道,被这个开源项目同时干了
开源项目 Scout 正试图解决企业知识管理的核心痛点——碎片化信息整合。这款由前 Airbnb、Facebook 工程师打造的 AI Agent,能在 Slack、Google Drive 等平台自由导航,实时构建公司知识图谱。它不仅颠覆了传统向量数据库方案,更通过「上下文提供者」架构实现了多系统无缝对接,或将重塑企业级 AI 应用的底层逻辑。

Ashpreet Bedi 昨天发了条帖子,标题七个字:Meet Scout. The open-source company brain。88,000 次浏览,不到 24 小时。
Ashpreet 现在是 Agno 的创始人,以前在 Airbnb、Facebook 做过工程。Scout 是 Agno 新推出的开源项目,定位是「上下文智能体」——一个能在 Slack、Google Drive、Linear 里自由穿梭、替你把碎片化知识拼起来的 AI Agent。
Scout:开源「公司大脑」,项目架构示意图
这件事有意思的地方在于,YC 2026 年夏季的「最想投赛道」清单里,有两个方向:其一是「公司大脑(Company Brain)」,其二是「AI 公司操作系统(AI Operating System for Companies)」。YC 对前者的描述是:把分散在 Slack、邮件、ticket 里的关键知识结构化,保持实时性,让 AI 能用它来行动。对后者的描述是:一个让公司默认对 AI 可查询的连接层,有闭环机制,能在决策发生后观察结果、持续调整。
这两个描述,Scout 都在指向。
Ashpreet 说,「大脑是数据层,操作系统是跑在上面的东西。这两件产品今天都不存在完整版,但积木都有了——模型能力、上下文提供者、智能体 SQL、MCP、持久记忆、定时执行。让我们来拼拼看。」

YC 2026 夏季 RFS 视频:关于「公司大脑」赛道的阐释
01 每家公司都在漏知识
你公司最关键的信息藏在哪?不是在文档里,不是在 Notion 里,是在某个去年离职的同事脑子里。是在一条三年前的 Slack 频道消息里,没有人记得这个频道还在。是在一封邮件链里,主题叫「Re: Re: Re: 关于 Q2 定价的讨论」,附件是一个 Excel,里面有一个被高亮的单元格,背后是当时所有人的共识,但没有任何人把这个共识写进正式文档。
这不是个别公司的问题。这是几乎所有公司的状态。
以前这没有太大关系,因为人类员工会自己建立这种隐性知识网络。新人来了,老员工带一带,很多东西就传下去了。当然会有遗漏,但大部分时候还能运转。
现在问题来了:AI Agent 没有「被老员工带一带」这个机制。它要工作,就必须通过明确的数据通道获取信息。你让它帮你写一份客户背景分析,它不知道这个客户三个月前发过一封投诉邮件,不知道上周销售跟他吃了顿饭说好了一个特殊条款,不知道技术团队已经给他做了一个定制集成。
这些信息不是不存在,是散在十几个地方,没有任何系统知道怎么把它们找出来。
「每家公司的关键知识散落在人们脑子里、旧 Slack 消息里、support ticket 里和各种数据库里,AI Agent 无法在这种情况下正常工作。我们认为,世界上每家公司都需要一个新的基础设施——一张关于公司如何运作的活的地图。」
—— Ashpreet Bedi,Agno 创始人
02 老方法的死穴
遇到「知识散落」这个问题,最直觉的解法是什么?向量数据库。
把 Slack 消息全量抓取,切成块,嵌入向量,存进一个大仓库。每次 Agent 需要找东西,用语义相似度搜出最相关的 top-k 条结果,拼成上下文,让模型回答。
这套方案听起来很美,实际上有四个根本性的漏洞。
第一,索引永远是过时的。你今天把所有 Slack 消息嵌入一遍,明天又有新消息了。你需要持续同步、持续重嵌入。公司越大,消息越多,同步周期越长,数据越陈旧。你问 Agent「刚才那个决定是什么」,它给你找的是上次同步时候的状态。
第二,切块切在错误的地方。一条 Slack 消息可能是接着上一条的,你单独看这条什么都看不懂。一封邮件可能引用了上周另一封邮件里的数字。向量切块没有「上下文感知」,它只是按长度切,切完之后每个块都有自己的嵌入向量,但可能是一段断了头或断了尾的片段。
第三,权限是个噩梦。把所有人的消息都抓进向量库,然后 Agent 检索的时候,怎么保证它不把 A 不该看到的内容给 B?你需要在向量库层面重新实现一套权限逻辑,而且这套逻辑要和 Slack 的权限系统保持同步。
第四,没有人真的会维护这个索引。Slack 里有几万条消息,大部分是噪音,少数是关键信息。有人真的会手动维护「哪些 Slack 消息值得被索引」这件事吗?不会的。
这四个问题,随便哪一个都能让这套方案在生产环境里跑不起来。
03 编程 Agent 早就想通了
解法不在向量库这条路上。Ashpreet 的核心观察来自一个有点偏门的角度:看看编程 Agent 是怎么理解代码库的。
Claude Code、Cursor、GitHub Copilot Workspace——这些工具在处理一个有几十万行代码的项目时,它们不是把所有代码塞进向量库然后检索。它们的做法更接近一个有经验的程序员是怎么在不熟悉的代码库里找东西的:先 ls 看目录结构,大概知道项目组织方式;然后 grep 关键函数名,定位到大概的文件;然后 cat 打开文件,读相关的部分;然后顺着 import 语句,跳到依赖模块里看看。
这是导航,不是搜索。
这两者的区别很根本。搜索是:我告诉你我要什么,你从仓库里找最接近的。导航是:我要找什么,我自己走过去取。搜索是静态的,依赖于索引有没有覆盖到。导航是动态的,每次都是实时的。
这个模式迁移到公司知识上,逻辑是一样的。Slack 有自己的「ls 和 grep」:列出频道、搜消息、按时间段过滤。Google Drive 有自己的:列目录、全文搜索、查修改历史。CRM 有,Linear 有,GitHub 有。每个系统都已经有了导航接口,你只需要让 Agent 去用这些接口,而不是先把内容复制到一个中央仓库。
实际效果的对比:
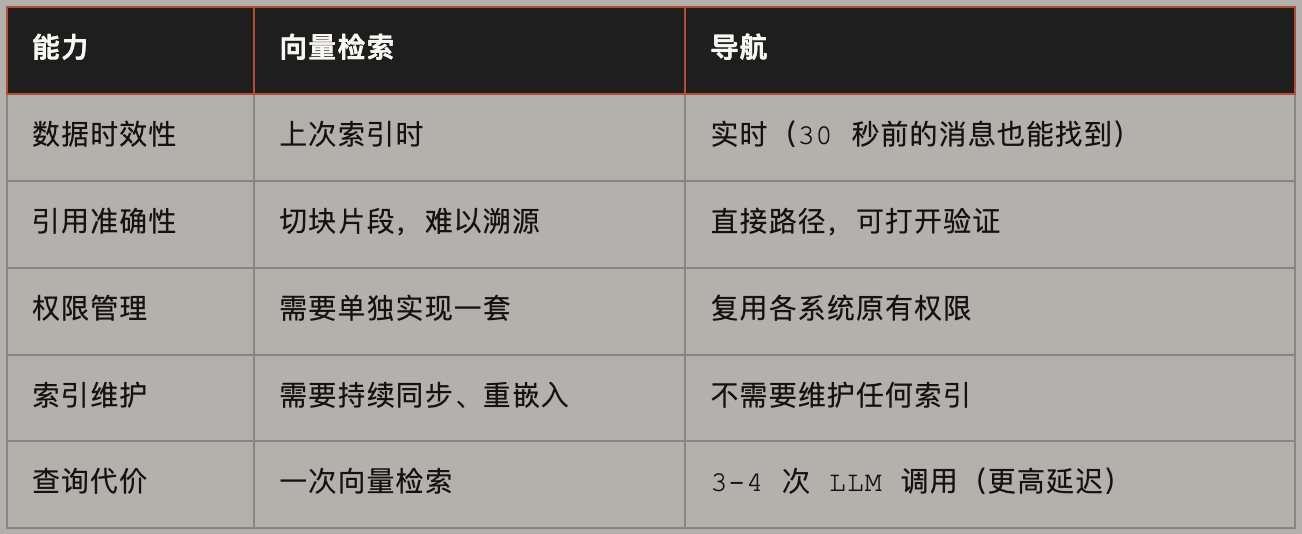
代价是有的:更多 LLM 调用,意味着更高的延迟和成本。这是一个真实的权衡,Ashpreet 没有回避它。但他的判断是:在知识的实时性和准确性比查询速度更重要的场景里,导航优先是正确的选择。
04 Context Provider:那层薄薄的中间层
明白了「导航而非搜索」之后,下一个工程问题来了:让 Agent 直接连接 Slack,它需要面对 Slack 的多少个 API?发消息、读消息、分页翻消息、查用户 ID、查频道列表、发私信、管理频道、查 reaction……轻松十几个。再加上 Google Drive,再加上 Linear,再加上 GitHub——一个 Agent 同时连接六个信息源,工具表里可能有七十个工具。
这会导致两个问题:第一,Agent 的上下文被工具说明书塞满了,能用来处理实际任务的空间越来越小;第二,工具之间有重叠的时候,Agent 不知道该用哪个,行为变得不可预测。

上下文提供者(Context Providers):Agent 与工具之间的缺失层
Scout 的解法是引入一个叫做「上下文提供者(Context Provider)」的中间层。每个信息源变成一个独立的上下文提供者,对主 Agent 只暴露两个工具:
• query_<来源> — 自然语言读取
• update_<来源> — 自然语言写入
主 Agent 不再直接面对 Slack 的十几个 API,它只看到 query_slack。
query_slack 背后是一个专门的子 Agent,它负责搞清楚 Slack 的所有细节:发私信之前先查用户 ID(不然 API 会报错),翻历史消息要用游标分页,查帖子里的回复要调用 conversations.replies 接口而不是普通的消息接口……这些针对具体 API 的操作技巧,全部封装在子 Agent 里,对主 Agent 不可见。
更重要的一点:子 Agent 跑了七八个 API 调用之后,最终返回给主 Agent 的只是一句话总结,或者一段结构化的结果。那七八个中间调用的细节,不会出现在主 Agent 的上下文里。主 Agent 的上下文保持干净。
Ashpreet 专门解释了这和「Skills」的区别。Skills 是任务级别的指令,可以按需加载进主 Agent 的提示里。但是 Skills 加载进来之后,Slack 的那些 API 工具还是直接落在主 Agent 上,中间调用结果还是在主 Agent 的上下文里。加载两个都有搜索能力的 Skills,Agent 立刻不知道该用哪个,然后两个都调用,然后上下文爆了。Context Provider 从根本上把工具隔离了,这是质的不同。
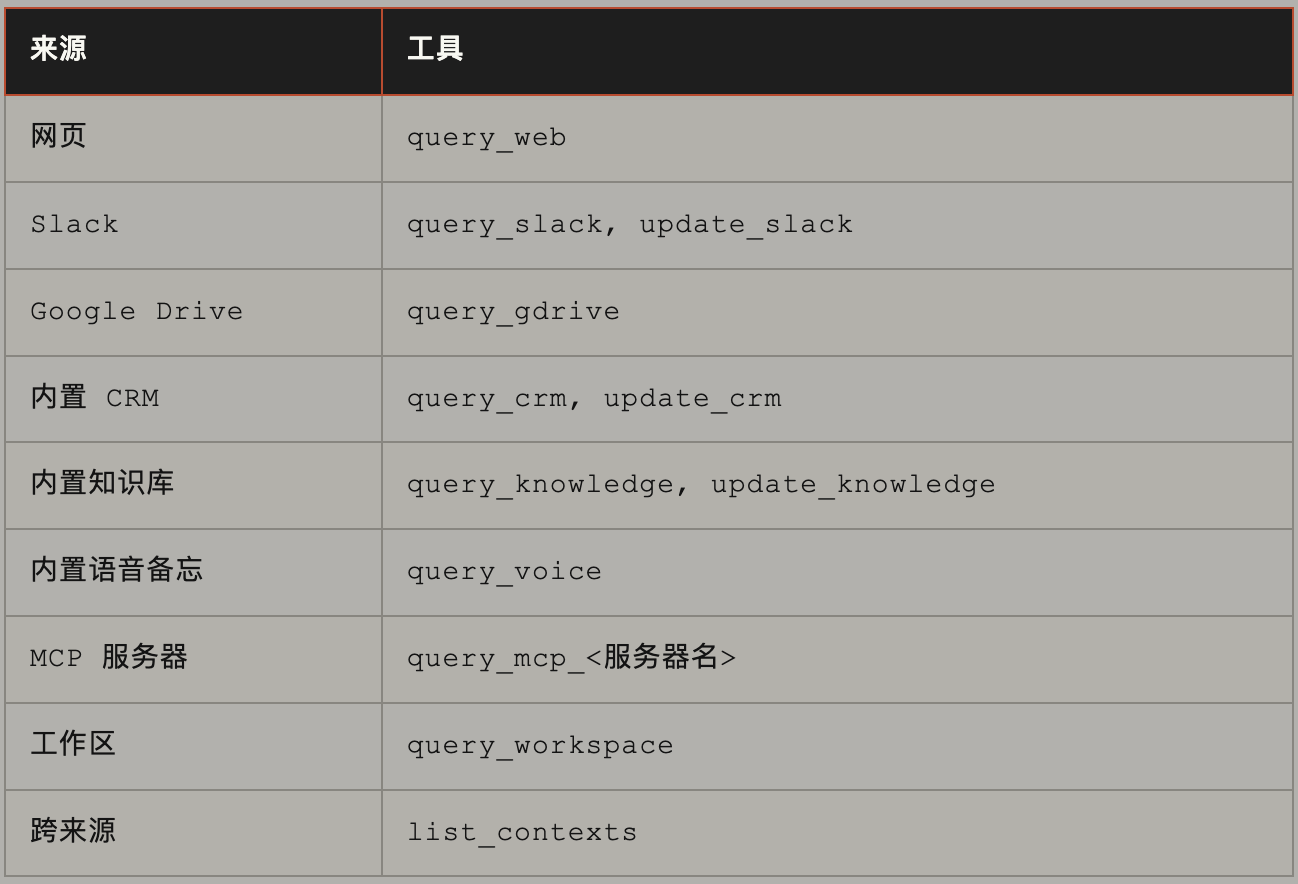
今天 Scout 支持的上下文提供者:
05 Scout 自己建 CRM 和知识库
有些知识没有「自然归属地」,这才是最难处理的部分。
「Josh 来自 Anthropic,上周分享了一篇 RLM 论文」——这条信息在哪?它可能被在一条 Slack 消息里顺带提了一嘴,但没有人会去 Slack 搜「Josh 是谁」,更不会在看这条消息的时候想到把它存进任何系统。它就这么漂了出去,消失在时间流里。
Scout 的解法是内置了两个知识存储:一个 CRM,一个知识库,边工作边往里写。
你告诉 Scout「Josh 来自 Anthropic,上周分享了一篇 RLM 论文」,Scout 会自动把 Josh 存进 CRM 的联系人表,把那篇论文解析之后作为一个知识条目存进知识库,并在 Josh 的联系人记录里加一条备注,把两个条目关联起来。下次有人问「Josh 是谁」,Scout 知道。下次有人问「最近有没有关于 RLM 的新论文」,Scout 也知道。
你告诉 Scout「v3 schema 迁移的方案还没定,下周二要讨论」,它会在 CRM 的待跟进表里记一条,打上日期标签。设一个每天的定时任务,让 Scout 每天早上浮出「今天有哪些待跟进」,那个闭环就形成了。
CRM 默认有四张表:scout_contacts(联系人)、scout_projects(项目)、scout_notes(备注)、scout_followups(待跟进)。超出这四张表的需求怎么办?写入子 Agent 会直接在数据库里创建新的 scout_* 表,列名和数据类型由模型根据需求推断。
你告诉 Scout「帮我追踪一下咖啡消费记录,第一杯:拿铁加一份浓缩」,它会创建 scout_coffee_orders 表,字段大概是:时间、品类、备注。然后把第一条记录写进去。
「如果你觉得 LLM 写 bash 已经很厉害了,等你看到它写 SQL 的时候。」
—— Ashpreet Bedi
这句话说对了一半——模型写 SQL 确实很好用,但更有价值的不是 SQL 语法本身,而是模型能根据语义需求自动设计表结构这件事。这不是「写代码」,这是「建模」。让 Agent 在工作过程中持续维护一个结构化的公司知识图谱,这才是「公司大脑」最核心的能力。
06 加进 Slack 只要五分钟
Scout 完全开源,代码在 GitHub 的 agno-agi/scout 仓库。快速上手三行命令:
git clone https://github.com/agno-agi/scout && cd scout
cp example.env .env # 把 OPENAI_API_KEY 填进去
docker compose up -d –build
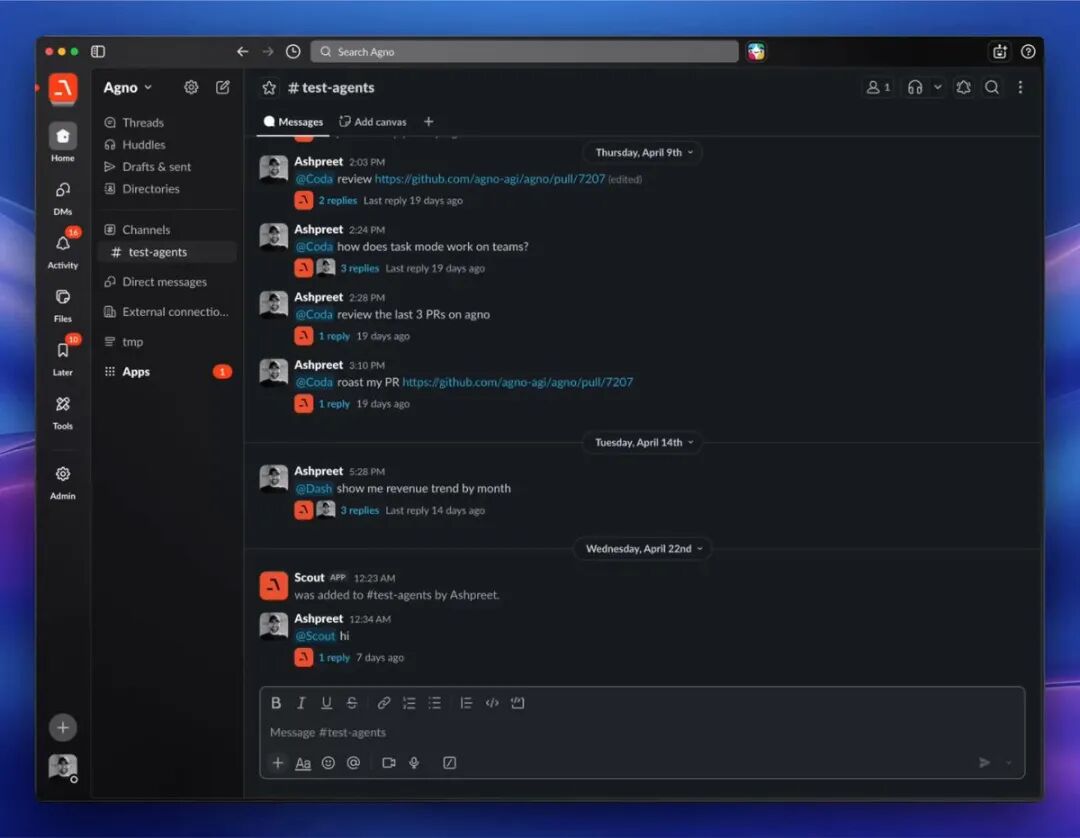
Scout 在 Slack 里的实际运行截图:作为团队成员加入频道,响应 @Scout 命令
本地跑起来之后,可以连接 Agno 的 AgentOS(os.agno.com):这是一个 UI 层,提供多用户会话、定时任务管理、和一个可以部署到任何支持 Docker 的地方的 FastAPI 应用。Scout 默认带上 Web、CRM、知识库、语音备忘、工作区五个上下文提供者,Slack 和 Google Drive 已经接好了接入方式,填上凭证就能用。
Slack 集成大概需要 5 分钟:跑一遍文档里的 SLACK_CONNECT.md,Scout 就会以一个 App 的身份加入你的 Slack 工作区。加进任何频道之后,@Scout 就会回应,每条帖子都是独立的会话,历史上下文全程保留。
官方建议了几个值得试的提示:
- 「你现在连接了哪些上下文?」——先摸清楚它能访问什么
- 「保存一条备注:Josh 来自 Anthropic,这周分享了一篇 RLM 新论文」——测试 CRM 写入
- 「v3 schema 迁移还没决定,下周二提醒我」——测试跟进记录
- 「创建一份事故响应手册——先呼叫值班,在 #incidents 发状态更新,边处理边记时间线」
最后这个提示我觉得最值得玩。「边处理边记时间线」——放在以前只能靠事后人工补写复盘,现在可以在事中自动记录。不是「AI 帮你写」,是「AI 跟你一起工作的时候顺带把流程记下来了」。
07 下一步在哪里

YC 2026 夏季 RFS 视频:关于「AI 公司操作系统」——最好的 AI 原生公司已经让整个公司对 AI 可查询
Ashpreet 在帖子里列出了下一步的路线图:
定时任务:让 Scout 定期浮出待跟进项,不需要人主动去查。这个功能做完之后,跟进事项就从「存进去、靠记忆翻出来」变成「存进去、时间到了自动提醒」。
每个来源的主动动作:每天定时跑 update_slack、update_github。这是往「主动观察」方向走的一步,Agent 不只是被问到了才查,而是会定期主动巡视。
GitHub、Gmail、日历接入:目前在侧支上测试。这三个接通之后,「把邮件里提到的决定记进 CRM」「把 PR 里的讨论关联到项目」这些工作流就自然打通了。
这三个方向放在一起,指向的是从「被动回答」走向「主动维护」。公司大脑不只是被问的时候才工作,它在后台一直在运行,一直在更新它对公司状态的理解。
08 对我们意味着什么
我读完 Ashpreet 这篇帖子,停下来想了一会儿。
有一件事我觉得他说准了:这个问题不是 AI Agent 时代才出现的,是 AI Agent 时代让它变得无法回避了。知识散落在每个公司已经有很多年了,以前靠「有经验的老员工记着」勉强凑合。现在 Agent 要工作,它没有「经验」,它只有数据通道。离职一个老人,就会有一段历史消失。新人要花三个月才能搞清楚某个决定是怎么来的。AI Agent 把这个问题放大了,因为 Agent 没有那个「资深员工的脑子」托底。
「导航而非搜索」这个观察,值得多想一下。它背后有一个更大的立场:不要试图把所有数据拷贝到一个中央仓库,让 Agent 去数据所在的地方工作。这和 2010 年代微服务时代「每个服务管理自己的数据库」的哲学有相似之处——数据不应该脱离它的系统语境被集中管理,因为一旦脱离了,权限、时效性、语义完整性都会出问题。
Context Provider 这层抽象我也觉得挺有意思。它本质上是在说:给每个工具做封装,把复杂性藏起来,让上层保持干净。这不是一个新想法,这是经典的分层设计。新的地方是,以前这一层是程序员来写的,现在里面住的是一个子 Agent,它自己来处理那些工具的奇怪行为。
Scout 能不能成为那个「公司大脑」,现在还说不准。开源项目的成败取决于很多和技术无关的因素。
但它提出的那几个设计决策——导航优先、上下文提供者、边工作边建 CRM——我觉得是指向正确方向的。
有一件更实际的事:现在你可以 fork 它,改成你自己需要的样子。这是开源的意义所在——你不需要等它做到完美,你可以从今天能用的部分开始,逐步加上你自己的上下文提供者。
我不确定公司知识管理这个方向最终会不会出现一个大赢家,还是会被嵌进每家公司自己的基础设施里。可能都会发生。
但这件事本身,已经是 AI Agent 下一阶段必须解决的问题了。

来源:Ashpreet Bedi (@ashpreetbedi) on X
原帖:https://x.com/ashpreetbedi/status/2049180168200106150
Scout GitHub:https://github.com/agno-agi/scout
Agno AgentOS:https://os.agno.com
本文由人人都是产品经理作者【深思SenseAI】,微信公众号:【深思SenseAI】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自作者提供






- 目前还没评论,等你发挥!


