
 起点课堂会员权益
起点课堂会员权益当 LLM 撞上天花板:世界模型将成为下一张船票
世界模型正成为AI领域的新风口,但背后隐藏着怎样的行业真相?从LLM的天花板到多模态架构的成熟,本文将深度剖析世界模型的技术路线、玩家布局及工程现实,揭示这场AGI竞赛中的真实挑战与战略赌局。

过去这一年,”世界模型”成了 AI 圈出现频率最高、含义最模糊的词。
巨头在发,巨头在开源,明星科学家在创业,资本在豪赌,开发者在围观。每一场发布会都把它和 AGI、空间智能、具身智能、范式革命绑在一起。看起来,这是 LLM 之后最确定的一站。
但真正在做这件事的人都明白,这件事远没有发布会上那么干净利落。它是真的在发生,但也藏着大量被刻意回避的工程现实。
我做世界模型项目这段时间,看着这股浪潮,既兴奋又警惕。这篇文章不是又一篇盘点贴,而是一份来自亲历者的判断:当下世界模型这个赛道里,谁在赌什么、技术路线之争的本质是什么、未来一两年会发生什么——包括那些不太好听的部分。
一、为什么是世界模型?一次范式的必然迁移
1.1 LLM 的天花板正在显形
要理解世界模型为什么突然变得重要,得先承认一件事:LLM(纯语言模型)这条路,正在逼近它的物理上限。

过去三年,scaling laws 的边际收益已经在肉眼可见地递减。从 GPT-4 到后续一众大模型,benchmark 上的提升越来越像是在挤毛巾。这不是某一家公司的问题,而是整个范式的天花板。当你训练数据已经接近”人类全部高质量文本”的总量,再大十倍的模型也只是在重复同一种智能形态。
在“语言模型是否足以通向 AGI”这个问题上,几位最有影响力的 AI 研究者,正在给出越来越清晰但不完全一致的答案。
首先是 Yann LeCun。他的立场几乎是这场讨论中最激进、也最一以贯之的:纯语言模型无法构成真正的智能系统。在他看来,LLM 缺乏对物理世界的理解能力,也无法支撑长期规划与因果推理,因此必须引入“世界模型”与 JEPA 这样的预测式架构,去补足对现实世界结构的建模能力。
相比之下,Fei-Fei Li的表达更克制,但指向同样关键。她并不直接否定语言模型的价值,而是不断将讨论从“语言能力”提升到“空间智能(Spatial Intelligence)”。在她的框架里,真正的通用智能,必须能够理解三维世界、进行空间推理,并在环境中行动——这实际上是在抬高 AGI 的问题定义,而不是简单评价 LLM 的优劣。
而 Demis Hassabis则代表另一种更偏工程化的路径。以 Google DeepMind为代表的体系,始终在推进一种融合式架构:将语言模型、强化学习、世界模型以及规划能力组合在一起。在他的表述中,语言模型依然是关键组成,但只是整个智能系统中的一个模块,而非终局形态。
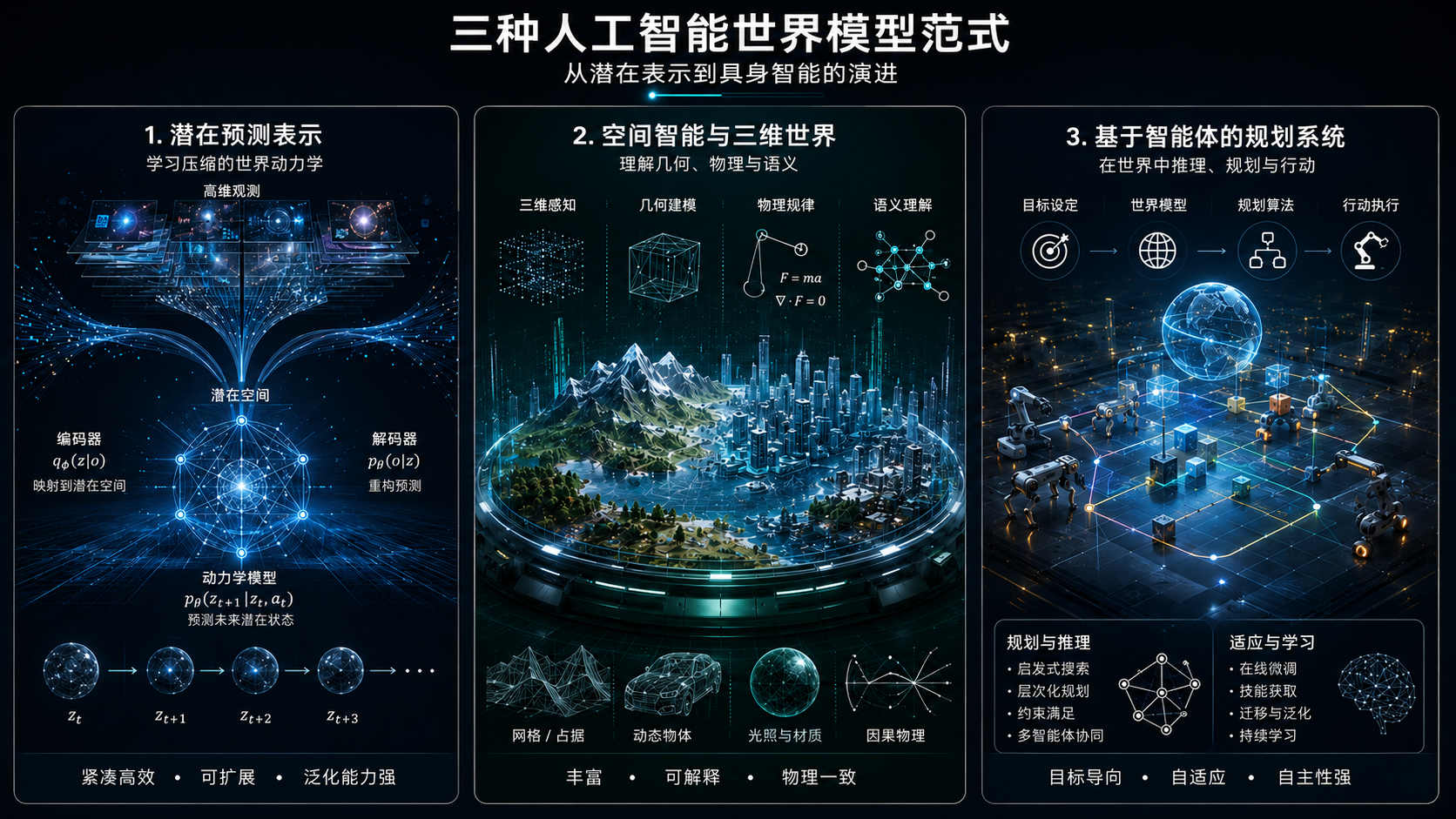
如果把三者放在一起看,会发现一个比“是否支持 LLM”更重要的共识正在形成:语言模型正在从“答案本身”,退回到“系统组件”。分歧依然存在——是在其之上构建世界模型,还是与之并行重构架构——但方向已经逐渐收敛:通往 AGI 的路径,不再是一条单一的语言扩展曲线。
这就是世界模型登场的逻辑起点。它不是 LLM 的延伸版,而是一次坐标系的切换。
1.2 什么是”世界模型”?一个被严重滥用的术语
要理解什么是”世界模型”(World Model),不妨先想想我们自己的大脑。当你看到一个杯子从桌边滑出,你会下意识地伸手去接——因为你”知道”它接下来会掉下去。这种对世界如何运作的内在理解,就是一种世界模型。
需要厘清的是,世界模型不等同于今天大家熟悉的大语言模型。语言模型学的是”词与词之间的关联”,而世界模型试图捕捉”事物与事物之间的因果与物理规律”。一个语言模型可以流畅地描述苹果落地,但未必”理解”重力;而一个真正的世界模型应当能预测:松手之后,苹果会向下坠落、加速、撞击地面。
李飞飞的 Marble,本质上是 3D 重建工具,能让你走进生成的房间,但你推不动里面的椅子。Genie 3 和 Happy Oyster 支持交互,但物理准确性禁不起严格推敲——把杯子推下桌子,它不会按真实物理碎裂。腾讯的 HY-World 2.0 输出静态 3D 资产,根本不涉及动态预测。
每家都选了一个能跑通、能商业化的切口,然后用”世界模型”这个时髦词把自己包装起来。这种命名通胀,让外界误以为这个领域已经接近成熟。事实远不是这样。
更精确的区分是这样的:视频生成做的是”电影”——一次性输出固定的画面序列;世界模型造的是”电影发生的那个空间”——一个能持续响应输入、保持一致性的环境。前者的输出是 artifact,后者的输出是 environment。这是本质差异。
1.3 为什么是现在?三个条件的同时成熟
世界模型不是新概念。1990 年代就有人在研究 model-based RL,DeepMind 也做了十多年的模拟环境。但为什么 2025-2026 年突然爆发?
三个条件第一次同时成熟。
- 多模态架构的成熟。Happy Oyster 的发布特别能说明问题——它原生支持音视频联合生成,文本、语音、图像都能作为输入。这不是把几个单模态模型拼接起来,而是真正在一个统一架构里处理多种模态。这种能力两年前还做不到。
- 算力红利的转移。当文本模型的 scaling 收益递减,资本和算力开始寻找下一个能消化巨量计算的场景。3D、时空、长程一致性,每一项都是算力黑洞。这反过来给世界模型的研发提供了前所未有的资源条件。NVIDIA 的 Cosmos 平台用 2000 万小时的真实视频数据训练,这种规模在三年前是不可想象的。
- 下游需求的点燃。具身智能、人形机器人、自动驾驶,这三个领域共同面临一个根本瓶颈:真实数据严重稀缺,并且无法靠“多采集”解决。机器人执行错误动作的成本太高,自动驾驶的长尾场景在真实道路上几乎遇不到。世界模型成了唯一可行的答案——它能生成无限的、可控的、低成本的训练环境。
需求侧的拉力 + 供给侧的成熟 + 算力的转移,三股力量同时压在一个点上。这才是 2026 年初这场爆发的真正动因。
二、玩家全景图:八家公司,五条路线
理解当下格局的关键,是看清每家在哪一层建模、最终输出什么、用户到底是谁。我把目前最值得关注的八个玩家放在下面这张表里,再逐一点评——重点不是它们做了什么,而是它们在赌什么。
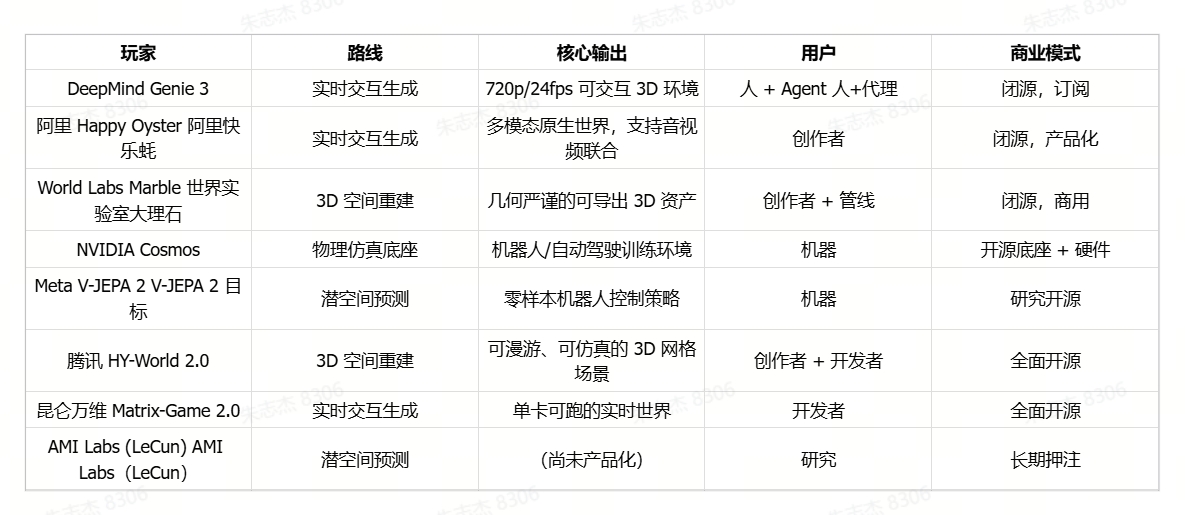
2.1 两条”实时交互”路线:Genie 3、Happy Oyster、Matrix-Game
这三家做的事情最像,但赌的东西完全不同。
Genie 3 是 DeepMind 在 2025 年 8 月公布的标杆产品,2026 年 1 月推向美国订阅用户。它的真正价值不在 720p/24fps 这些参数,而在叙事——把世界模型和 AGI、Agent 两个最大的概念绑在一起,定义为”训练 AI Agent 的无限课程表”。这是研究机构的打法:用愿景占位,不急着变现。
Happy Oyster 是阿里 ATH 团队 2026 年 4 月发布的产品。和 Genie 3 最大的差异是原生多模态——音频从一开始就在统一管线里,支持最长 3 分钟的连续输出,用户可以在任意时刻通过文字、语音、图像介入剧情。它的产品哲学不是”通往 AGI”,而是”创作即交互”。前者是研究叙事,后者是产品叙事,背后是中美两种生态的不同生存逻辑——美国的玩家有耐心讲长期故事,中国的玩家必须在产品形态上先活下来。
Matrix-Game 2.0 是昆仑万维 2025 年 8 月开源的方案,定位很直接——”开源版 Genie 3″。它在技术上不是最先进的,但它是这个赛道里唯一一个普通开发者能在自己机器上跑起来的实时交互世界模型:1.8B 参数、单卡可跑、25 FPS。Genie 3 闭源不可访问,HY-World 2.0 起步要 H100 + 40GB 显存。Matrix-Game 把”实时交互世界模型”从巨头垄断变成了人人可触达的工具——这件事的生态价值,比技术领先更重要。
2.2 两条”3D 重建”路线:Marble 与 HY-World
Marble 是李飞飞 World Labs 的首个商用产品,对应她那句”From Words to Worlds”宣言。它不试图实时生成动态世界,做的是几何严谨的 3D 重建——支持文本、图像、视频、3D 草图、全景图作为输入,输出 Gaussian Splats、Mesh、视频,可以直接进游戏引擎。
Marble 的优势和软肋都很清楚:它擅长重建空间长什么样,但对空间里会发生什么理解很弱。你能走进它生成的房间,但你推不动椅子,也碰不倒杯子。它是静态世界的复制者,不是动态物理的模拟器。李飞飞对此并不回避——她的判断是要让机器理解物理世界,必须从空间结构这一层开始打地基,动态预测会在这之上自然涌现。World Labs 在 2026 年初洽谈 5 亿美元、估值 50 亿美元的新一轮融资,资本市场认可这是一个长期主义但确定性高的押注。
HY-World 2.0 是腾讯 2026 年 4 月开源的版本,目前在斯坦福 WorldScore 开源榜排名第一,能力对标闭源的 Marble。技术路线是融合性的——全景图像合成 + 分层 3D 重建,输出标准 Mesh,无缝接入 Unity、Unreal、Blender。
腾讯走开源路线背后是清晰的战略考虑:在中美两套生态都拼命推闭源产品的时候,开源能快速建立开发者生态,把腾讯云绑定为事实上的部署底座。混元 3D 系列模型在社区累计下载超过 230 万次。这是”放弃即时变现、换取生态位”的赌局——而且赌赢的概率不低。
2.3 面向机器的两条路:Cosmos 与 V-JEPA 2
这两家做的世界模型,从一开始就不是给人用的。
NVIDIA Cosmos 是经典的卖铲人逻辑:不管上层哪条路线胜出,你都要用它的硬件,并且很可能基于它预训练好的基础模型 fine-tune。Cosmos 由三大模型族构成——Predict 做未来预测、Transfer 攻 Sim2Real 缺口、Reason 做物理推理。训练数据对应 2000 万小时真实世界视频,截至 2026 年初平台下载量已突破 200 万次。今天市面上几乎所有训练机器人的世界模型团队,都在用 Cosmos 作为参考或底座。
V-JEPA 2 是 Meta 2025 年 6 月发布的,是这一波浪潮里最被低估、但学术含金量最高的一个。它的工程做法分两阶段:第一阶段用超过 100 万小时互联网视频做自监督预训练,第二阶段只用 62 小时机器人交互视频就训出了能执行真实抓取任务的版本,然后直接在两个不同实验室的 Franka 机械臂上零样本部署。
100 万小时 vs 62 小时——这个比例几乎是颠覆性的。它意味着机器人领域那个”真实数据极度稀缺”的诅咒,可以靠”大规模视频预训练 + 极少量交互微调”的范式来打破。这是过去 20 年机器人学习领域一直在等的范式。
2.4 LeCun 的 10 年押注:AMI Labs
最后一个玩家是个异类。
LeCun 离开 Meta 创立 AMI Labs,融资 10.3 亿美元种子轮,公司选址巴黎。他的核心主张可以一句话概括:像素空间生成是死路,世界模型必须在潜空间里做预测。他甚至公开说过——硅谷被 GenAI 催眠了,要做这种新研究,必须离开硅谷。
JEPA 路线的好处是计算高效、抓住因果结构而不被像素细节干扰;坏处是没法做出漂亮的 demo——你的输出是潜在向量,不是 4K 画面。AMI Labs 大概率不会在 2026、2027 年推出消费级产品。但如果 JEPA 这条路被证明走得通,整个世界模型领域的技术栈都会被重写。这是 10 年视角的押注,赌的是范式本身。
2.5 全景图
把这八家拉通看,能得出一个比单独看任何一家都重要的判断:没有一个全胜的玩家,只有一组在不同方向上同时推进的赌局。
如果非要画一张产业地图——美国玩家偏研究和长期愿景(DeepMind / World Labs / AMI / Meta),中国玩家偏开源和场景落地(阿里 / 腾讯 / 昆仑万维),NVIDIA 在底层吃所有人的红利。
每家都选了一个能跑通、能商业化的切口,然后用”世界模型”这个时髦词把自己包装起来。这种命名通胀让外界误以为这个领域已经接近成熟。事实远不是这样——这就是为什么下一章必须把表面的产品对比再往下挖一层。
三、祛魅:发布会之外的工程现实
把八家公司的赌局摊开来看,会得到一种乐观的印象:路线虽多,但每条都在前进,整个领域看起来正在加速逼近某种成熟形态。
这是发布会留下的错觉。
真正在一线做这件事的人都清楚,当下世界模型的实际能力,和宣传素材之间存在着系统性的落差。这种落差不是某一家公司刻意夸大造成的,而是这个领域的集体生存策略——每一家都在用最优条件下的最佳画面,去定义这项技术”能做什么”。久而久之,外界就形成了一种危险的认知泡沫:以为这些模型已经能造出”完美数字世界”,以为可交互就等于可仿真,以为 demo 里展示的能力是它的稳态表现。
这一章想做的事情很简单:把这层光鲜剥掉,看一看发布会不会告诉你的东西。我会从两个最容易被混淆的概念入手——”可交互”和”可仿真”是不是一回事,”大场景、高画质、流畅交互”能不能同时成立。这两个问题的答案,决定了你怎么判断一个世界模型产品的真实成色,也决定了它到底能不能拿去做严肃的下游应用。
3.1 选择性展示:一种行业默认的修辞
在进入具体的技术分歧之前,先说清楚一件事:你在发布会上看到的每一段世界模型 demo,几乎都经过了三层筛选——选过的场景、选过的时长、选过的镜头路径。这不是阴谋,是当前技术水平下唯一能拿出手的展示方式。
但这种展示方式带来一个副作用:外界很难分清”这家做到了什么”和”这家最好的情况下能做到什么”。Genie 3 演示里那几分钟的一致性,是它的能力上限还是平均表现?Happy Oyster 那段 3 分钟的连续输出,是稳定输出还是精挑细选的版本?Marble 生成的房间,换一个 prompt 还能这么干净吗?
这些问题在发布会上不会有答案。但当你真正想拿这些模型去做事——做游戏、训机器人、做仿真——它们就是你必须先回答的问题。
接下来两节要讨论的,正是这种”选择性展示”掩盖掉的两个最关键的工程现实。
3.2 “可交互”和”可仿真”完全不是同一件事
这一点是当下行业最大的认知盲区。
让用户能 WASD 控制镜头、能输入 prompt 改剧情,叫”可交互”。让物理量在模拟过程中保持守恒、让因果链在长时间尺度上稳定,叫”可仿真”。
Genie 3 和 Happy Oyster 都做到了前者。但它们能做到后者吗?把杯子推下桌子,它会按真实物理碎裂吗?同一个物体从不同角度看,质量是不是恒定的?两个物体碰撞,动量是不是守恒的?
这些问题的答案目前都是”差不多但不严格”。视觉上看起来对,但在严格的物理量层面经不起推敲。这意味着这些模型可以拿来做创作工具、做娱乐应用、做影视前期,但不能拿来训练机器人,也不能拿来验证自动驾驶。
机器人和自动驾驶不接受”看起来对”,只接受”算得对”。这是 demo 级世界模型和 robotics 级世界模型的真正分水岭,也是这个领域接下来 3 年里最大的技术跨越。
3.3 不可能三角:大场景、高画质、流畅交互
这是行业里没人愿意公开承认的硬约束。
Marble 的 1.1 版本画质好,但空间范围有限;Plus 版本能生成大场景,但画质明显模糊。昆仑万维的 Matrix-Game 3.0 能在 720P 下做到 40FPS 实时生成,但演示场景的风格和复杂度都很受限。Genie 3 维持几分钟一致性已经是当前 SOTA,但这个时长在真实应用里远远不够。
大场景、高画质、流畅交互——这三件事在当前算力条件下,无法同时全部满足。每家都在某个维度做了取舍,然后只在最优条件下展示自己最好看的那一面。
这种选择性展示正在催生一种危险的认知泡沫:外行看了发布会以为这些模型已经接近”完美数字世界”,实际上它们的稳态表现和宣传素材之间存在巨大落差。
我自己评估一个世界模型产品的方法很简单:追问它在非选优条件下的表现。给它一个 demo 里没出现过的场景描述,让它跑足够长的时间,让它处理边界 case。它的真实能力会立刻显形。
四、世界模型与具身智能:从虚拟世界到物理世界的最后一公里
前面讨论的所有路线,最终都要回答一个问题:这些模型造出来,是给谁用的?
答案不是人类,是机器。
4.1 具身智能的瓶颈不是算法,是数据
过去 5 年,机器人领域出现了一种奇怪的”算法过剩”现象。Transformer、Diffusion Policy、VLA(Vision-Language-Action)模型一个接一个被提出,论文越写越漂亮。但量产部署的进度远远跟不上算法迭代的速度。
原因不在算法,在数据。

LLM 的训练数据是整个互联网的人类文本——百万亿 tokens 量级。机器人训练数据呢?最大的开源具身数据集(Open X-Embodiment)也就几百万条轨迹,覆盖的物体和场景极其有限。这中间差着 6 个数量级。
而且机器人数据无法靠”多采集”解决。每一条轨迹都需要真实硬件、真实场景、真实操作员,成本是文本数据的几百万倍。这是一个用钱也砸不快的瓶颈。
世界模型恰恰是这个困局的答案。一个能生成无限可控、物理一致的 3D 环境的世界模型,等于把机器人训练数据的”可获得性”从硬件限制中解放出来。从此训练机器人不再需要等真实硬件,只需要等显卡。
Meta 的 V-JEPA 2 已经把这件事从理论变成了实证。100 万小时互联网视频 + 62 小时机器人交互数据,就训出了一个能在两个不同实验室、面对从未见过的物体做零样本抓取的世界模型。这两个数字的对比是颠覆性的——它意味着机器人领域那个”训练数据极度稀缺”的诅咒,可以靠”大规模视频预训练 + 极少量交互微调”的范式来打破。这是过去 20 年机器人学习领域一直在等的范式。
这就是为什么 NVIDIA 押 Cosmos、为什么 Meta 押 V-JEPA、为什么特斯拉自己在做 Dojo、为什么所有头部机器人公司都在内部组建世界模型团队。具身智能的下一波突破,必须由世界模型来打底。
4.2 Sim2Real 缺口:世界模型必须迈过的物理关卡
但这条路不是免费的。
机器人在仿真里学得再好,最终要跑在真实物理世界里。如果仿真和真实之间有”reality gap”——比如摩擦系数不准、关节力学不准、视觉光照不真——那么仿真训练的策略部署到真机上就会崩。
这是 Sim2Real 问题,机器人界研究了 20 年仍然没有彻底解决。
世界模型解决了 Sim2Real 的一部分(生成视觉真实的环境),但远远没有解决全部。视觉真实不等于物理真实。一个能生成漂亮厨房场景的世界模型,未必能准确模拟刀切番茄时的力反馈和形变。
这就是为什么我前面强调”可仿真”和”可交互”的本质区别。面向消费者的 Genie 3、Happy Oyster 可以在物理上”差不多对”,因为它们的用户是人,人对物理细节的容忍度很高;但面向机器人训练的世界模型必须”严格对”,否则训练出来的策略一上真机就报废。
NVIDIA Cosmos 里的 Transfer 模型族就是为了攻这个缺口——专门做仿真到现实的桥接。但坦白说,这个问题的彻底解决需要把神经渲染、物理引擎、可微仿真深度融合,没有一家公司单独完成了这件事。
4.3 双向馈送:机器人是世界模型最好的”老师”
更深的关系是:机器人不仅是世界模型的用户,也是世界模型的训练数据来源。
人形机器人在物理世界中执行任务,会持续产生大量”动作-观察-结果”三元组数据。这种数据包含真实物理因果关系,是从视频里看不到的。一个搬箱子的机器人能学到”箱子有多重”,一个倒水的机器人能学到”水的粘性如何影响流动”。这些信息在被动的视觉数据中是不可见的。
这就形成了一个飞轮:世界模型训练机器人 → 机器人在真实世界产生数据 → 数据回流改进世界模型 → 下一代世界模型训练更强的机器人。
这个飞轮一旦转起来,会形成自我强化的数据壁垒。这也是为什么硅谷的顶级实验室都在抢”具身基础模型 + 世界模型”的双栈布局——它们不是两个独立产品,是同一个技术体系的两端。
4.4 谁会赢得具身智能 + 世界模型的双栈竞赛?
我的判断是:赢家不会是纯软件公司。
纯软件公司可以做出 Genie 3 这样的现象级产品,但他们拿不到机器人飞轮的真实数据。能赢的玩家必须同时具备三件东西:底层世界模型能力、机器人硬件部署能力、足够规模的真实场景数据回流。
按这个标准看,全球范围内具备完整双栈能力的公司不超过 10 家。中国的字节、阿里、腾讯、华为,美国的特斯拉、Google DeepMind、NVIDIA、Meta、World Labs(如果他们做硬件合作),加上一两家头部的具身智能创业公司。这是这个领域真正的最终牌桌。
五、结语:从单词到世界
回到李飞飞那句话:From Words to Worlds。
我做世界模型这件事一段时间了。越做越觉得,这不是一个新模型的发布,是 AI 对世界的”对焦方式”正在改变。过去 5 年,我们让机器学会了读和写;接下来 10 年,要让机器学会看和构建。
这个过程不会像 LLM 那样在两三年内出现”ChatGPT 时刻”。世界模型涉及到的物理、几何、动力学、感知、规划,每一项都是几十年积累的硬骨头。它不会有那种戏剧性的爆发,会是一种更缓慢、更艰难、更深刻的进化。
作为做这件事的人,我既兴奋于它的可能性——一个能模拟物理世界的 AI 意味着机器第一次真正”理解”世界——也警惕于它的炒作。这两种心态必须同时存在,少了哪一种都会做错事。
当你下次看到某家公司又发布了一个”颠覆性”的世界模型 demo,记住几个简单的提问:它的物理一致性如何?它在非选优条件下表现怎样?它能跑多长时间不崩?它的用户是人还是机器?
这些问题的答案,比发布会的标题重要得多。
我们正在建造的,不只是一个模型,而是机器理解物理世界的第一只眼睛。这只眼睛现在还很模糊,看不远,看不细,看一会儿就累。但它已经睁开了。这就是 2026 年世界模型最真实的状态——不是 AGI 的前夜,而是一段漫长征程的起点。
睁开眼之后,路还很长。
本文由 @北辰 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Pexels,基于CC0协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务






- 目前还没评论,等你发挥!


