
 起点课堂会员权益
起点课堂会员权益医药AI,从哪下手?一个三年从业者的三段式判断法
医药行业与AI的结合正从实验室走向文档处理与项目管理,带来效率革命。从蛋白结构预测到注册文件翻译,从临床方案撰写到法规跟踪,AI正在重塑医药行业的工作方式。本文将深入剖析医药行业三大环节中AI的落地场景与商业机会,揭示那些看似不性感却最具商业价值的'铲子型'应用。

事情是这样的。
上个月,一个爱丁堡的大学同窗,现在在读博,突然在微信上问我,医药行业用AI,到底能搞点啥?
我说你等会儿,这个问题太大了,我得想想从哪说起。
他说不用那么严谨,就随便聊聊呗。
然后我发现,这个问题我最近被问了不下十次了。
问的人大概分两拨。一拨是我医药行业的老同行,他们看到ChatGPT火了、DeepSeek也火了,但回头看看自己手头那堆临床方案和注册文件,完全不知道AI跟自己有什么关系。另一拨是AI圈的朋友,想做垂直行业,觉得医药听着特别有想象空间,一脚踩进去发现全是ICH指导原则和FDA法规,满眼都是看不懂的缩写,根本不知道从哪下手。
这两个问题其实是同一个问题的两面。
医药行业那么大,AI不是哪都能用的。你得有个判断的抓手。
我自己在判断「医药行业哪个环节适合用AI」的时候,脑子里会自动把整个产品生命周期切成三段。这不是什么高深的理论框架,就是做了几年之后自然长出来的一个思维习惯。
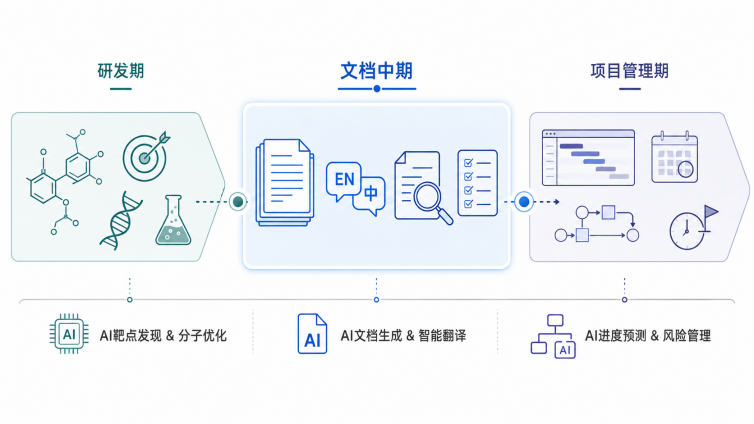
第一段,研发期。新药发现、靶点筛选、蛋白结构预测这些。
第二段我叫它文档中期。从研发结束到上市,临床方案、注册申报、法规跟踪、医学写作,全是跟文档打交道的活儿。
第三段,项目管理期。上市之后的运营、多国注册进度跟踪、客户沟通这些流程性的工作。
每一段,AI能做的事完全不一样,适合的人也不一样。
先说研发期。
这一段的AI应用其实已经走得很远了,但反而是很多医药同行没太意识到的。
AlphaFold2肯定听过吧?DeepMind靠这玩意拿了诺贝尔化学奖。蛋白结构预测这件事,在以前是要靠大量湿实验去一点点磨出来的。
我自己就亲身经历过那种磨。
硕士在爱丁堡生物学院做SCO4393,这是一个来自天蓝色链霉菌的蛋白,参与糖代谢通路。简单说就是研究这种细菌是怎么「吃」和「消化」GlcNAc的。听起来很冷门对吧?确实挺冷门的,全世界研究这一个蛋白的人估计两只手都数得过来。
但这就是搞基础研究的常态。你跟一个具体的小东西较劲几年,就为了把它的脾气搞清楚。
每天泡在实验楼里,做结合实验,跑TDA。
我当时的核心任务是搞清楚SCO4393能和哪些金属离子结合。日常就是配一组又一组不同的离子缓冲液,加到蛋白里,盯着热位移曲线一条一条慢慢跑出来,看Tm值有没有挪动。
我心里默念,这次的Tm往上挪一点啊,再挪一点。
一组实验等大半天到一天,结果出来之后再换下一组离子,再来一遍。
中间还要不停地养菌、纯化蛋白、跑跑胶。
把一个蛋白的脾气搞清楚,可能要磨上好几个月。中间还经常失败,得从头来过。
那种感觉怎么说呢,你知道答案就在那里,但就是要用时间一点一点把它抠出来。
后来试了AlphaFold2。输入序列,跑完预测。

省下来的时间是几个月级别的。
我当时就愣住了。不是愣在技术有多牛,而是突然意识到,我在实验室里那些日日夜夜等着链霉菌长大、等着结合实验跑出结果的日子,有一部分可能真的要被改写了。
当然蛋白结构预测只是研发期AI的一个点。靶点发现、药物设计这些更上游的环节,晶泰科技和英矽智能已经在用AI直接参与新药发现流程了。
还有文献检索这块。我早期用ChatGPT帮我做文献总结的时候,遇到过特别离谱的事。
它给我编造了一篇完全不存在的论文,也就是大家熟知的「幻觉」。
作者名字、期刊名称、发表年份,写得有模有样。我兴冲冲拿去Google Scholar搜,空的。再去PubMed搜,还是空的。
那一瞬间我是真的震惊。
不是因为它错。人都会错。是因为它那么自信地错。没有犹豫,没有「我不确定」的退让,就那么坦然地、有理有据地,把一篇根本不存在的论文塞给我了。
如果我没去查,我可能就引用它了。如果引用了它,我的dissertation就完了。
那是我第一次真切地理解什么叫「模型幻觉」。不是教科书里的术语,是真实坐在你面前、可能毁掉你毕业的那种东西。
后来学聪明了,用Elicit、Consensus这种基于真实文献库的AI搜索工具,效率确实能提升5到10倍,至少不会给你编论文了。。。
这次「被骗」后来反而成了我最大的财富。我现在做任何AI产品,第一反应都是「这个场景如果模型出错最坏会怎样」。条件反射就是从那次差点把假论文写进dissertation里养成的。
但研发期有一个很现实的门槛,你需要同时懂生物化学药学和AI。这两个领域的交叉人才到现在还是非常稀缺的。反过来说,门槛高也就代表着回报大,因为研发早期的一个判断,可能省下来的是上千万的实验成本。
如果你是生信、计算化学方向的在读研究生,说真的,你可能正站在一个很多人羡慕的位置上。
· · ·
再说文档中期。
这一段是我自己投入最多时间的地方,也是我觉得目前最容易跑出来落地产品的阶段。
很多朋友可能不知道,一个新药从做完研发到最终拿到批文上市,中间要经历多少跟文档较劲的活儿。临床方案撰写,注册文件翻译(中英、中欧、中日、中韩,各种语言对),FDA和EMA和NMPA的法规跟踪,医学综述、SOP、CSR的撰写,BD对接的商务邮件。。。
我有时候觉得,医药行业90%的工作量,就是在跟文档死磕。
AI在这一段能干嘛?我自己摸下来,核心就是三板斧。
第一板斧,RAG补充垂类知识。
通用大模型不懂医药行业的术语和规范。你直接问Claude「ICH E6(R3)跟E6(R2)的主要区别」,它大概率给你瞎编。但如果你把FDA指南、ICH指导原则、公司内部SOP这些文档灌进向量库,让模型回答的时候先检索再生成,幻觉率能降一半。
技术门槛不高,但对医药场景是刚需中的刚需。
第二板斧,LLM辅助写作。
注意,不是让AI完全代替人写,是让AI做初稿+校对+翻译润色,人来做关键判断。
我自己做的翻译Agent就是这个思路。把一份注册材料翻译从5天压到1到2天。
但这个事情没有想象的轻松。上线后我专门建了一个Bad Case池,每个翻译错误都要归因。比如有一次模型把临床报告编号「CR-2024-001」翻成了「临床报告2024之一」,差点直接发出去——这种事在注册场景就是事故。
修这种坑的过程就是Prompt一层一层加约束的过程。加数字校验规则、加关键字段强制保留、加独立审核模型做交叉检查。47条Bad Case一条一条修过来,才有了今天可以信赖的版本。
第三板斧,结构化信息抽取。
法规更新动辄上百页PDF。
举个真实例子。FDA每个月会更新Guidance Document,一份典型的PDF是80到120页。要让团队人工读一遍找「和我们产品相关的条款」,得花掉两三个人一整天。
让LLM读一遍、按「我们产品名 + 目标市场 + 生物类似药」做关键词筛选、再做分级提醒——10分钟搞定,准确率95%。
人不用再一页页翻了。
这三板斧听着好像也没什么高深的对吧。
嗯,就是没什么高深的。
但关键在于,文档中期这些场景天然满足一个黄金组合,高频、标准化、错误代价大。翻译错了一个术语可能导致注册被驳回,法规漏看了一条可能引发合规风险。这种场景下,企业是真的愿意为效率提升掏钱的。
而且这一段的技术门槛已经被拉得很低了。Coze、Dify、LangChain这些工具基本上把开发门槛降到了「会写Prompt就行」的程度。你作为医药行业的人,对场景的理解就是最大的护城河。你知道哪些术语绝对不能翻错,你知道哪些法规条款最容易变动,你知道临床方案里哪些部分是模板化的、哪些必须人工审核。。。
这些东西,一个纯做AI的人,可能花一年都摸不透。
你对场景的理解,就是你最大的壁垒。
这句话我想再说一遍。
最后说项目管理期。
到了这一段,关键词从「内容生成」变成了「流程编排」。
跨国注册项目的进度自动跟踪+风险预警,临床试验的Site进度监控+异常自动告警,客户邮件的自动分类+翻译+回复模板生成,多语种会议纪要自动整理。。。
AI在这段的形态不再是你问它它答了,而是Agent。主动监控,主动行动。
我自己做的一个东西就是这种思路。FDA和EMA的监管情报工作流。每天自动爬取官网更新,用药物名+目标市场做双层筛选,LLM做摘要+影响分析,然后自动生成结构化周报发到团队。
以前这些活儿需要一个人每天花两三个小时盯着,现在一个Agent搞定了。
一个Agent承担1到2个人的工作量。这就是项目管理期AI的杠杆效应。特别适合那些「高人力消耗 + 模式化决策」的环节。
好,三段说完了。
但说真的,这篇文章真正想聊的,是接下来这段。
很多人想做医药AI的时候,第一反应是奔着研发期去的。
这太正常了。新药发现、蛋白设计、AI制药,每一个词都自带光环,听着就很诺贝尔奖,很Nature封面。投资人爱听,媒体爱写,社交场合讲出来逼格瞬间拉满。
我非常理解这种想法。
但我自己3年做下来的经验告诉我,最容易跑出落地产品的,反而是那个听起来最不性感的文档中期。
为什么呢。
数据更容易获取——FDA和EMA的指南都是公开的,公司内部SOP和模板也都齐全。不像研发期,你想做新药发现首先得有独家化合物库或临床数据集。
场景更标准化——临床方案有ICH GCP的固定结构,注册文件有CTD格式要求。同样的翻译模板我能用5年,同样的法规跟踪流程我能跑3年。
用户验证更快——同事拿你做的工具用一周,就能告诉你好不好使。不用等三年五年的临床终点出来。
商业模式更清晰——企业为人力效率提升掏钱,这个逻辑是过去30年企业SaaS的基本盘,不需要重新教育市场。
我自己的3个AI产品,翻译、评测、情报,全部集中在中期。
这不是巧合,是想清楚之后的主动选择。
作为一个有医药背景但AI经验还在积累中的人,中期就是我的「能力圈和增长圈的交集」。我不需要去跟计算化学的大牛拼研发期的技术深度,也不需要去跟互联网PM拼项目管理的工具熟练度。我只需要发挥我最独特的东西,我既懂医药场景,又能把AI工具用起来。
这个交集,就是我的位置。
想了想,这个道理好像不只适用于医药行业。
每一次技术浪潮来的时候,所有人的注意力都在最前沿、最酷炫的方向。AI制药、自动驾驶、量子计算,媒体和投资人追着跑的全是这些。但历史反复证明,真正最先跑通商业闭环的,往往是那些「不够性感但足够刚需」的中间环节。
就像淘金热的时候。
真正发财的不是那些拿着锄头下河淘金的人,是卖铲子的、卖帐篷的、开旅馆的。
这个故事被讲了无数遍了,但每一次技术革命来的时候,大家还是会本能地冲向金矿,而忽略铲子。
你想想看,在AI这一波浪潮里,翻译、文档处理、信息抽取、流程自动化,这些是不是也挺像「铲子」的?不够酷,不够性感,发不了Nature,上不了热搜。
但真的有人买。
如果你是医药行业的人,想试试做AI产品,从文档中期切入。门槛低,反馈快,能积累真实的产品经验。一开始可能会觉得这些东西不够酷,好像在做「脏活累活」。但坚持做下去你会发现,你积累的场景理解和用户反馈,才是最值钱的东西。
如果你是AI圈的人想做医药垂直,找一个有医药行业经验的合伙人。你做不了他能做的,他做不了你能做的。加起来,就是这个市场上最稀缺的复合视角。
回到最开始那场对话。
我把这套三段式说完之后,那个爱丁堡的同窗想了一会儿,回我一句,我还以为你会跟我聊什么AlphaFold3,什么AI从头设计蛋白呢。
我说,那些确实很酷。但那是别人的故事。
我能讲的,只有我自己做过的那些不够性感的事。
翻译。评测。情报。
听着确实不酷。
但你知道吗,3年前我在爱丁堡的实验室里,等着那一管链霉菌长起来的时候,完全没有想到,有一天我会坐在这里跟人聊怎么用AI写临床方案、怎么自动跟踪FDA法规更新。那时候我觉得研发才是正道,文档什么的,不就是打杂嘛。
后来我发现,这个世界上大部分真正创造价值的事情,从外面看都挺像打杂的。
大时代啊。
每个人都在找自己的位置。
不知道这些对你有没有用。可能有些想法还不成熟,但我已经把我知道的,毫无保留地摊出来了。
以上,既然看到这里了,如果觉得不错,随手点个赞、在看、转发三连吧,如果想第一时间收到推送,也可以给我个星标⭐~
谢谢你看我的文章,我们,下次再见。
本文由 @CyberHuck 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


