
 起点课堂会员权益
起点课堂会员权益Supabase:百亿美元估值,vibe coding 的默认后端?
Supabase 正凭借 Postgres 生态与 AI coding 浪潮的黄金交叉点改写 BaaS 赛道规则。从开源 Firebase 替代品到 agent-native 基础设施,其 OrioleDB 存储引擎与 Multigres 分片技术正突破传统数据库性能天花板。本文深度解析这家估值百亿美金的公司如何用技术收购和架构创新,重构开发者与 AI Agent 的后端体验。

Supabase 是一个几乎所有 vibe coder 都熟悉的产品。
它背后的公司创立于 2020 年,以 Postgres 为核心数据库,叠加 auth、storage、edge functions、vector 等能力打包成一站式后端提供给用户。其早期价值主张围绕“open-source Firebase”与“更简单易用和一站式的 Postgres”构建,目标是让开发者“Build in a weekend. Scale to millions”。
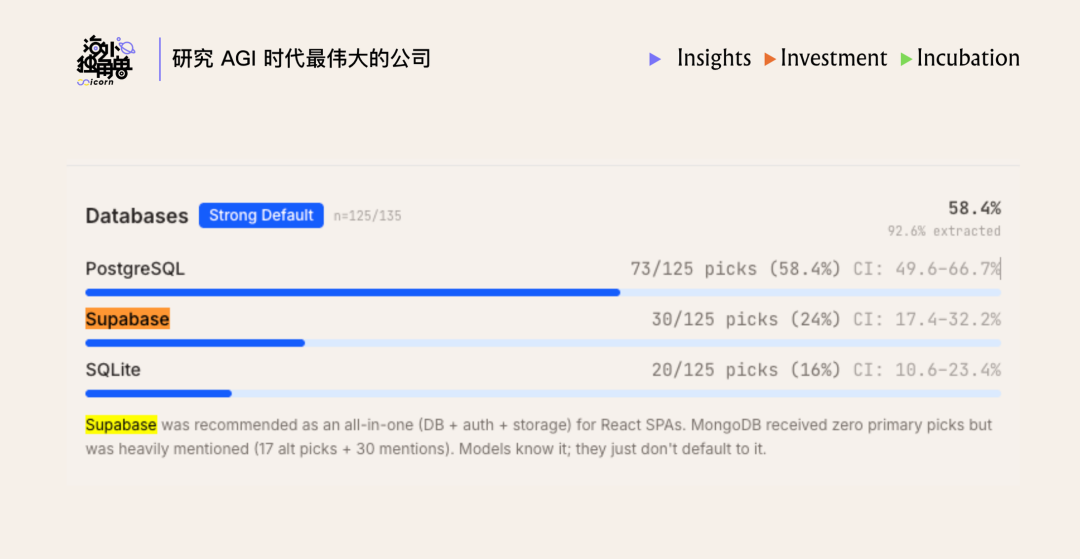
Supabase 的发展底座是 PostgreSQL。过去 20 年 Postgres 的官方文档、Stack Overflow 答复、GitHub 数据都成为了模型预训练数据的一部分,加上 Postgres 生态的多样性以及 pgvector 的成功,目前 AI agent 在“用什么数据库”这一问题上大多数时候默认推荐和选择 Postgres。Supabase 的 BaaS 平台提供了最开箱即用的 Postgres,承接了这一分发优势,目前已经成为 Lovable、Bolt 等第三方 harness 的默认集成以及 Codex、Claude Code 等 CLI agent 的 top 后端推荐。
Supabase 背后的另一个 wave 是 AI coding 能力的提升。Anthropic ARR 在 Opus 4.5 发布后三个月从 90 亿美元跳至 300 亿美元级别,run rate 两三年走完 Google Cloud 十八年的路。受益于 vibe coding 和 agentic engineering 的崛起,Supabase 的用户增长曲线也在 Opus 4.5 发布后完成新的加速。
目前 Supabase 接近完成 GIC 领投的 5 亿美元 F 轮融资,估值 100 亿美元。公司历史上重要的财务投资人还包括 YC、Accel、Coatue 等。截至 2026 年 Q1,Supabase 累计用户突破 700 万。我们预计 Supabase ARR 在 26 年末可以达到数亿美元。如果你对 agent-native 数据库或 Backend-as-a-Service 方向感兴趣,欢迎联系我们交流。
01.为什么要关注 Supabase
Coding Agent 是科技史上增速最快的新物种
1. Supabase 同时在两条 AI 时代的大势上,即 Postgres 作为 AI 的心智语言,以及 coding 作为 AI 需求的最大爆发点。
Coding 是 AI 目前最大的 wave 和绝对的主线,coding 能力大幅提升的 Opus 4.5 已经让 AI 从 chat 跨入 agent 时代。我们的判断是“coding agent 实现了,AGI 的 90% 就实现了”。
而 Postgres 已经成为 agent 的后端心智语言,最适合其理解和操作。得益于其瑞士军刀属性和 pgvector 的巨大成功,Postgres 非常适合 AI 时代的新型 workload。Supabase 成功打造了最流行和易用的 Postgres wrapper,位置在 Postgres 生态和 AI coding 趋势的交叉点上。
2. Supabase 的产品路线图已从“给人类开发者更好的体验”切换为“给 agent 更好的 Postgres capability”。
在 2024 年以前,Supabase 的主要价值是让人类更简单方便地用 Postgres,将 GoTrue(Auth)、PostgREST(API)、Phoenix Channels(Realtime)等已有开源组件打包成一站式体验,Dashboard 好看,文档清晰,能让开发者一键 setup。
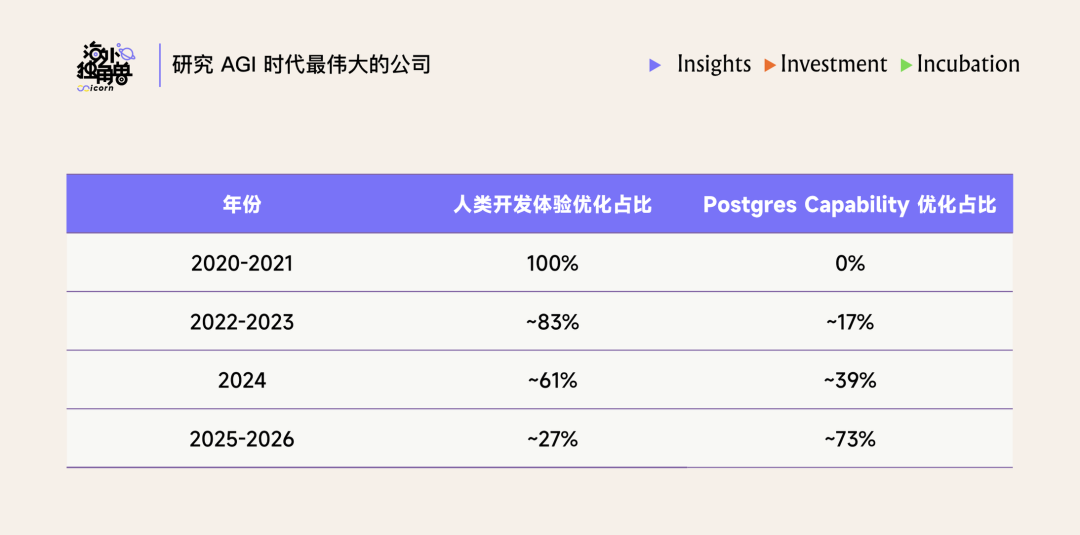
随着 2024 年收购 OrioleDB,Supabase 开始成为 Postgres 的改造者,其产品路线图聚焦点明显转移。我们统计了 20 年以来 Supabase 重要产品更新的方向分化:
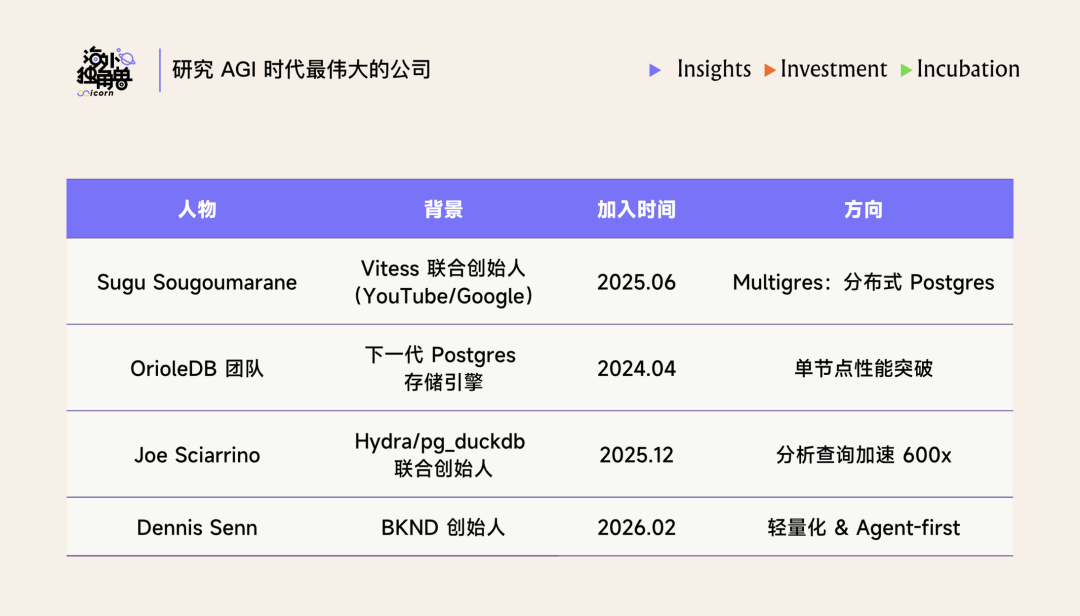
Supabase 还通过连续收购把 Postgres 最顶尖的人才聚拢到一家公司:
我们判断,人类开发体验的壁垒在 agent 时代是随时间递减的,而底层 capability 的壁垒是递增的。Agent 可以直接管理 infra 本身,并不在意 dashboard 清晰度和 setup 难度,但 capability 的强弱仍将重要。
3. 模型正在吃掉应用和垂类,BaaS 则处于吃掉向量搜索、状态持久化、auth 等其他 Infra 的绝佳位置上。
Supabase 处于 Infra 的中枢位置,叠加上 Postgres 的瑞士军刀属性以及 Supabase 在 Auth 等产品拓展上的高成熟度,有非常好的平台化机会。
4. Supabase 有极强的 distribution moat,第一阶段体现为 vibe coding 平台的官方集成,目前已经过渡到 agent 的主动推荐以及与 Anthropic 的官方合作。
Supabase 是 Bolt、Figma、Lovable 等平台的默认后端,构建了官方集成,成为 Lovable Cloud 等产品的白标服务商。
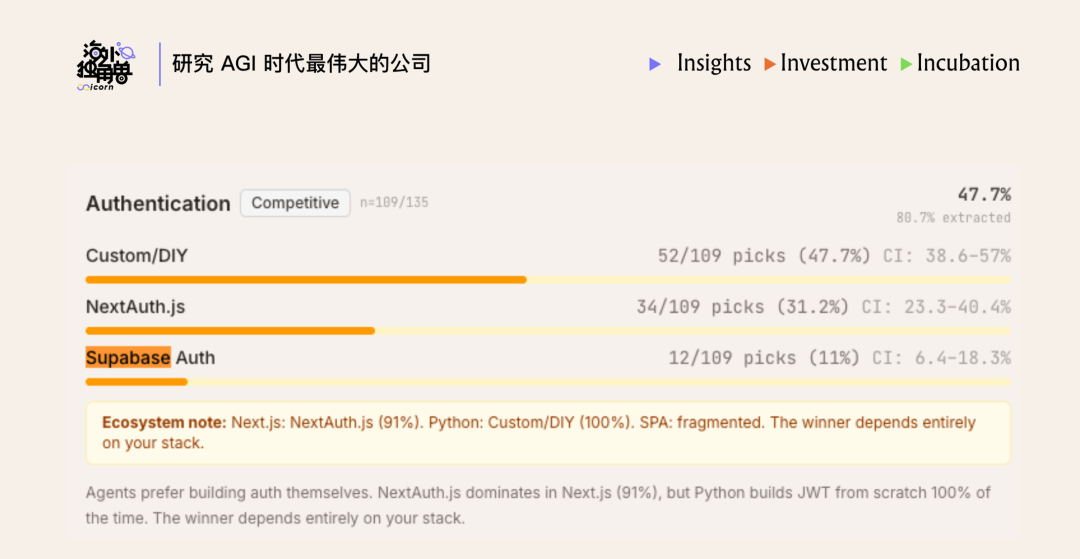
同时 AI coding 工具生成代码时选择 Supabase 不是因为有商务合作,而是 Supabase 的社区影响力、品牌知名度、代码示例密度都极强。Supabase 在数据库、auth、real time 等品类的 agent 推荐率都名列 top 3。Supabase 和 Anthropic 将合作推出 vibe coding platform 产品,会进一步加强这个 distribution moat。
02. Momentum
Supabase 在 2024 年 4 月才正式宣布 GA,开启了用户数和商业化的快速增长。在 2025 年 10 月宣布新一轮融资时,Supabase 的 ARR 已经突破 7000 万美元。我们预计其 Net New ARR 在 26 年将大幅加速,年底 ARR 将增长至数亿美元。
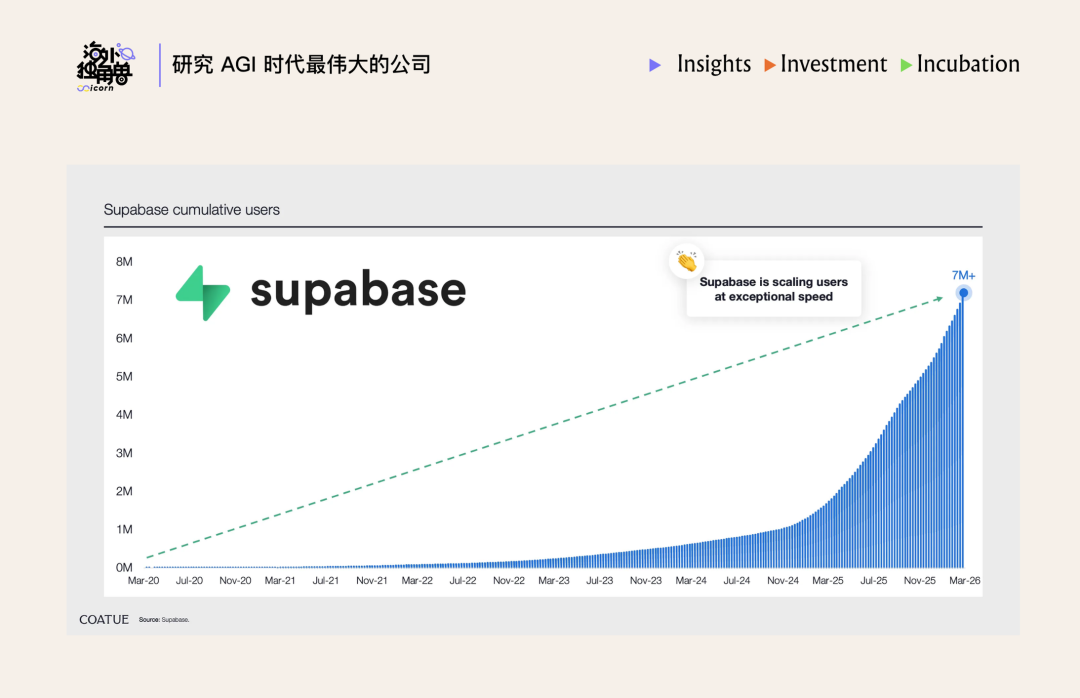
根据 Coatue 在 26 年 3 月发布的这张图片,Supabase 的累计用户数过去 16 个月 7x,已经超越 700 万:
03. Supabase 的产品路线路
Overview
每个 Supabase 项目都相当于一个独占 Postgres 数据库及 5 个同项目默认开好的服务(Auth / Storage / Realtime / Edge Functions / Vector)+ 自动生成的 REST & GraphQL API。这通常需要在 AWS 上拼 5–7 个服务才能做到,但在 Supabase 这里是一个 schema 和一套 auth 上下文里全部开好的默认。
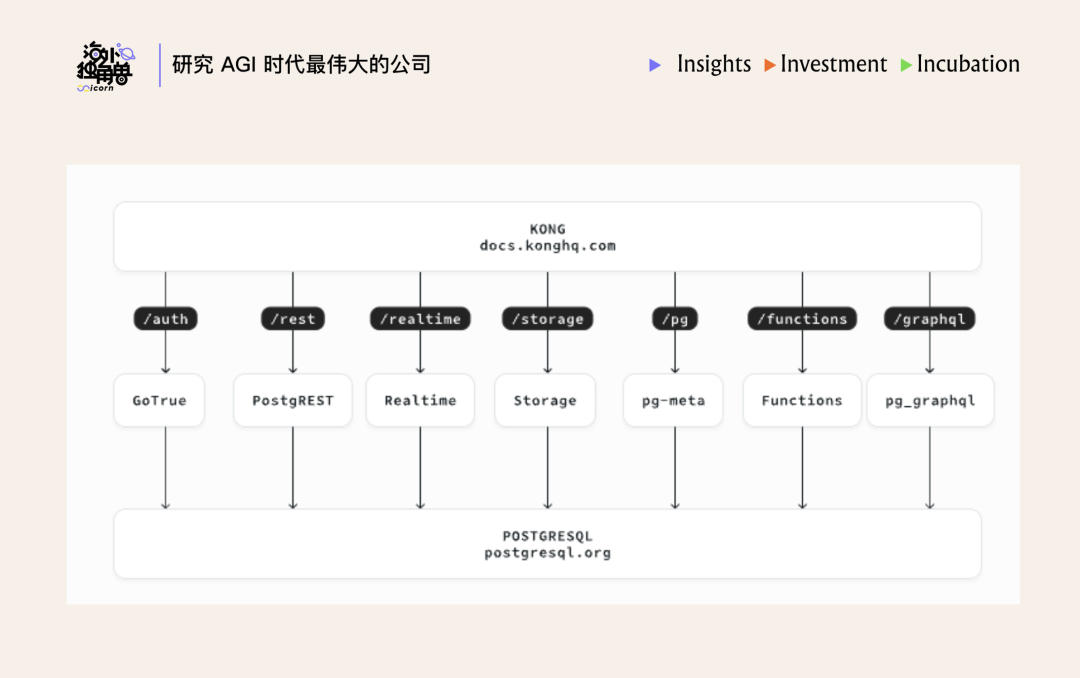
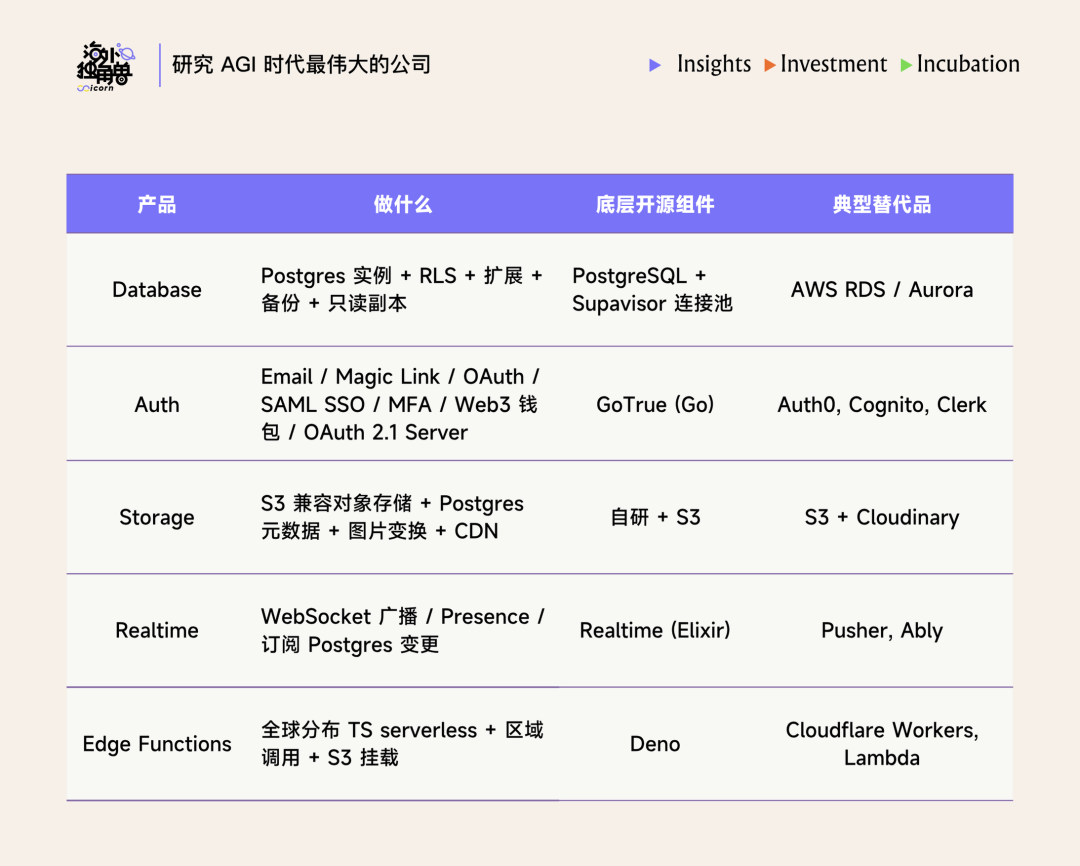
在大体上,我们可以把 Supabase 的产品分成 5 层来看:
1. Postgres 本身。每个项目一个完整的托管 Postgres(15/17),带 RLS、40+ 扩展(pgvector、pg_graphql、pg_cron、Vault、Foreign Data Wrappers 等)、daily backup 与 PITR、read replicas。
2. 6 个核心的 BaaS 组件产品,同时系统自动生成 REST API(PostgREST)和 GraphQL API(pg_graphql),schema 改了 API 可以立刻跟上:
3. 开发者 workflow:
• Studio Dashboard:完整可视化管理(Table Editor / SQL Editor / Auth Users / Storage Buckets / Logs / AI Assistant)
• CLI + Declarative Schemas + Branching:本地 dev → migrations → 给每个 PR 起一个隔离真实数据库环境(Vercel 式)
• MCP Server + supabase/agent-skills:18+ agent 兼容
• Management API + Terraform Provider:多项目 fleet 可编程管理
• Logs & Analytics + Log Drains:Datadog / Grafana / Sentry / S3 导出
4. 企业级安全、合规以及独占能力:
• Supabase ETL + Analytics Buckets (Iceberg/Parquet on S3) + S3 Tables
• Private Link(AWS VPC Lattice, 2026 年初 GA)
• 合规:SOC 2 Type 2 / HIPAA (with BAA) / ISO 27001 stage 2 尾声
• Foreign Data Wrappers(查外部数据源像 Postgres 表)
• Read Replicas + Dedicated Poolers + PITR
5. 前沿 bet:
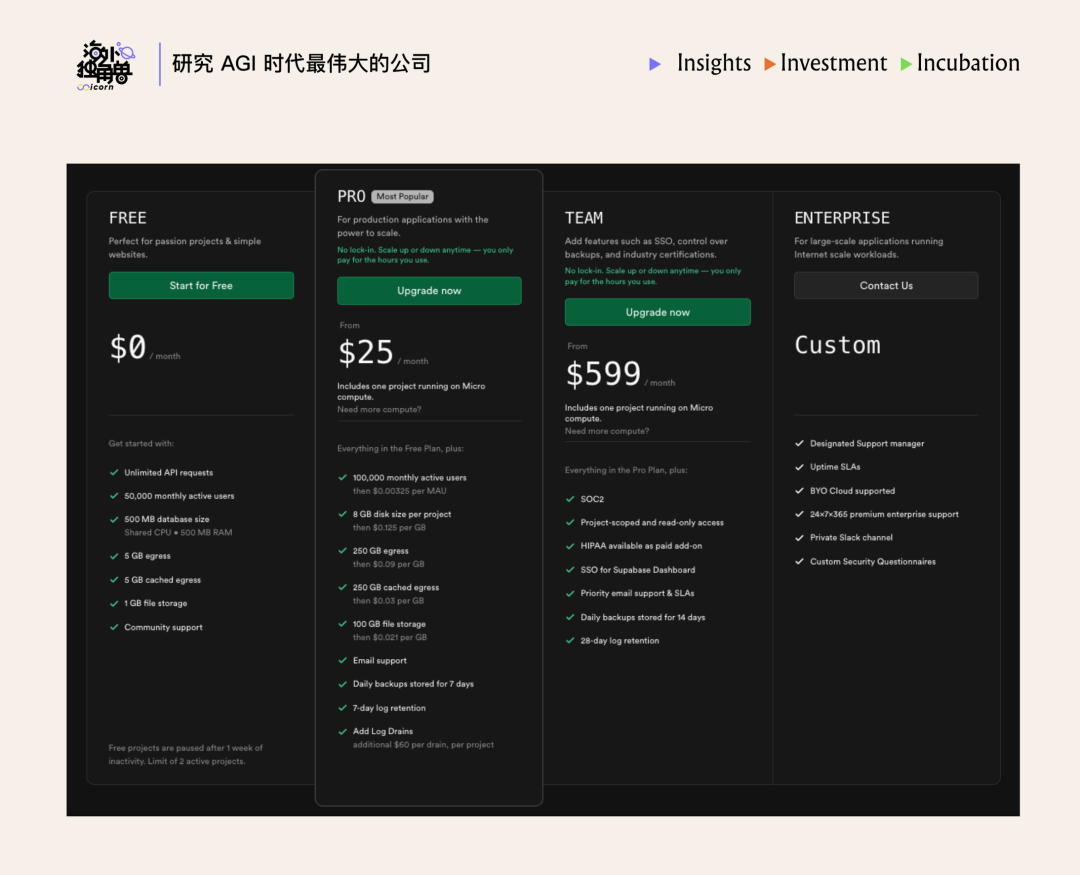
其产品定价为如下四档:
Agent-First Bets
Supabase 产品的很多历史优点主要体现在人类开发者的体验上。2025 H2 以来,coding agent 已成为新项目后端选型的主要决策者之一。与人类开发者相比,agent 在生成代码时表现出三项差异:
• 代码产出量较人类高约 1000x 以上
• 绝大多数产出符合 disposable 的概念,真正交付至最终用户的比例低
• Context retention 成为任务完成度的重要制约,agent 能力受限于 context window,难以同时协调超过 3–4 个外部服务的 API 形状
以上三点共同决定:能够在这些 workload 下赢得默认地位的后端产品,必须同时满足三项条件:agent 能很好地针对该后端的代码、探索实验阶段不产生云成本、从原型到付费交付的升级路径能在同一供应商内闭环。
Supabase 在产品层面有 3 层的布局:
• supabase/agent-skills 仓库 & MCP server:skills 仓库汇集了官方校验过的 Supabase 代码 template,目前已经被 18+ 主流 coding agent 原生集成,让 agent 在生成 Supabase 代码时优先引用其 template,降低幻觉和错误。
• 轻量沙盒 PGlite:PGlite 是一个 3MB 的 WASM 构建 Postgres,可在浏览器、Node、Bun、Deno 内亚秒级冷启动运行,完整兼容 Postgres 语法但不依赖任何云资源。让用户可以 local-first 地快速地跟 agent 一起进行原型迭代,无需消耗任何的云资源。
• BKND 和 Supabase Lite:完全面向 agent 作为用户打造的独立产品。传统上 Supabase 需要人类用户自己完成域名、环境变量、auth 配置等编排。Supabase 于 2025 年底宣布收购 BKND 并引入其创始人 Dennis Senn 主导 Supabase Lite,目的是将该编排环节产品化:一个 agent 可直接调用的“最小可发布 Supabase 项目”,同时内置一条向完整 Supabase 项目升级的路径。这条产品线仍在建设中。目前 Supabase 对 Lite 的核心构想包括:
1) 针对沙盒环境的 trimmed-down experience
2) 面向 agentic workflow 的数据库架构
3) 更小、更便宜、更简单的数据库
目前看 Supabase Lite 还在探索阶段,如果 26 年能 GA 并且我们观察到 agent adoption 的 traction,可以大幅增强我们对 Supabase 在 agent-first 时代的信心。
Scalability Bets
Postgres 本身是一个单机数据库,在不进行存算分离等架构大改的基础上,天然有 scalability 的问题。根据 12 份 Supabase 客户的专家访谈,对单机 Postgres 在商业级生产负载下的实用上限为:写入吞吐 1-5 万 TPS(具体看 workload 类型)、单 instance 有效存储 ~10 TB 量级、VACUUM 维护成本在 5 TB 以上的表上显著恶化。对应的商业拐点(客户开始遭遇性能问题而评估迁移的时间点)约为 20-50 万美元 ARR / 5000+ 月活用户 / 5–50 TB 数据量。
通常来说,因为 scalability 问题而迁移出 Supabase 的客户会流向云厂商等解决方案,主流的选项是 AWS Aurora、Google AlloyDB、CockroachDB。这种迁移本身也耗时耗力,需要对 auth、storage、realtime 等关联服务做全部的重建,但为了更好的性能、容灾等能力,客户往往不得不迁移。
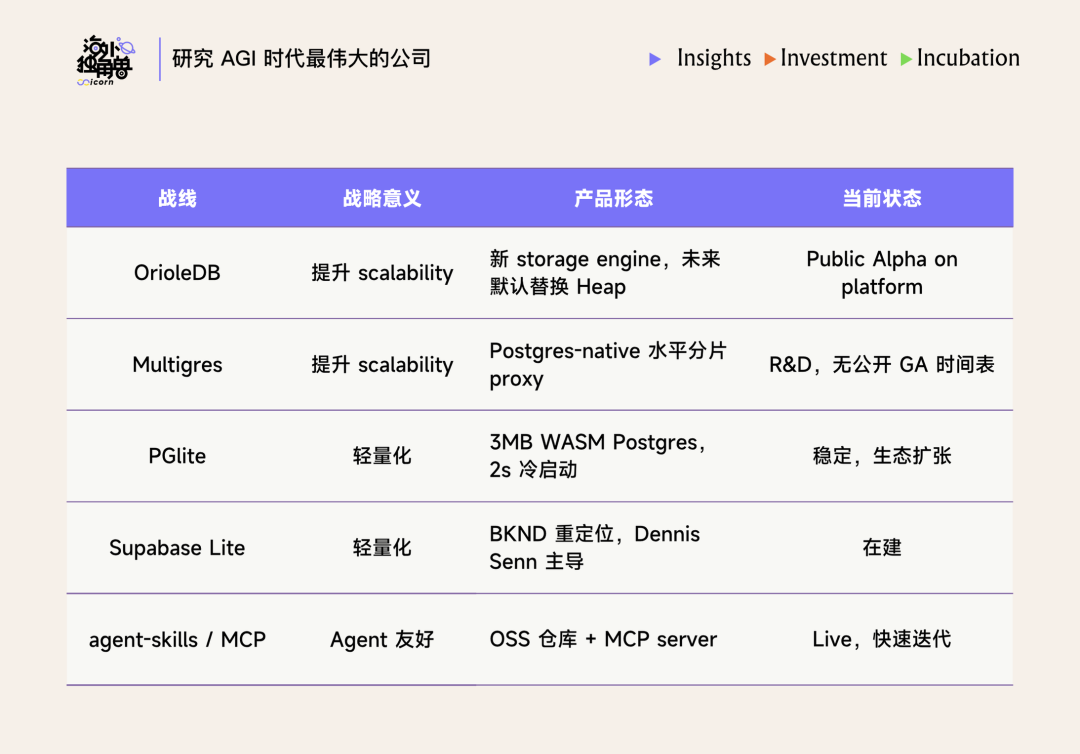
目前针对 scalability 的问题,Supabase 有两个核心的产品布局:
• OrioleDB。Supabase 于 2024 年收购 OrioleDB 项目并将其创始人 Alexander Korotkov 纳入核心团队。OrioleDB 是 Postgres 的一套替代存储引擎,针对原生 Heap 存储长期未能解决的两个问题,VACUUM 维护开销与 MVCC 导致的表膨胀。其技术实现采用 Copy-on-Write 与行级 WAL,在写密集负载下可将 VACUUM 开销压缩至可忽略区间。当前状态为 Supabase 云平台 Public Alpha,HNSW 向量索引尚未接入,GA 时间表未公开。
• Multigres。Supabase 于 2025 年聘请 Sugu Sougoumarane 主导 Multigres 项目。Sugu 为 Vitess(MySQL 水平分片中间件,在 YouTube、Slack、Square 等公司承载 exabyte 级负载)的联合创建者。Multigres 的目标是将 Vitess 的分片模型移植至 Postgres 生态,使客户在不切换 SQL 接口、不迁移 Auth / Storage 等关联服务的前提下获得水平扩展能力。当前状态为 R&D 阶段,无公开 GA 时间表。
这两个布局一个专注在存储、一个专注在分片改造 Postgres。对 Supabase 在客户规模的两端都有意义,一方面是吸引企业客户以及减少 graduation effect,另一方面是降低服务 vibe coder 的沉睡项目的云成本。同时,agent 时代后端的 workload 会有几个大的变化:
• 项目/数据库的创建速率极高
• 这些项目的冷热分布季度不均,大多数 disposable
• 爆款的突发性和爆发力极强
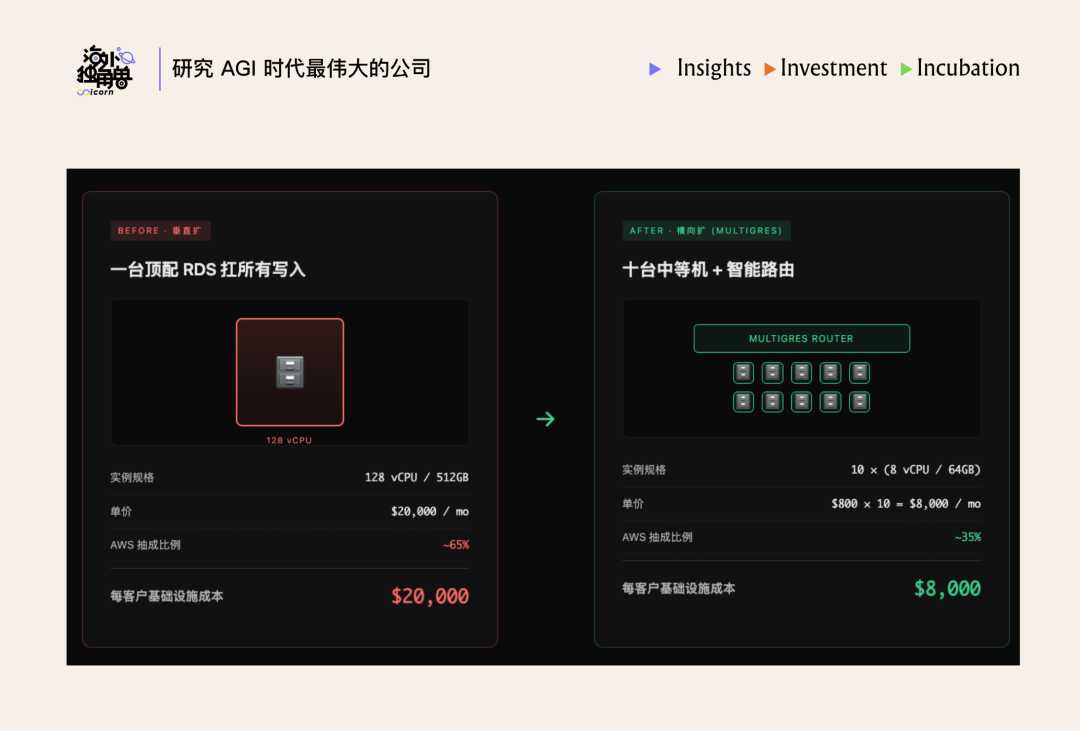
Multigres 和 OrioleDB 后续发展会决定 Supabase 在冷项目的成本控制和爆发项目/企业级 workload 上的弹性承接能力(下图为加机器扩容这一个变化带来的 UE 改善)。
Enterprise-Readiness
根据专家访谈,过去 5 年,企业 IT 采购对 Supabase 这类 PLG/self-serve 起家的后端平台的拒绝理由集中在四类:
• 跟企业现有 OLAP 的数据打通能力有限
• 无法满足数据库不得暴露于公网的网络隔离要求
• 缺少一些企业级合规证明
• 相比 Crunchy Data 等 Postgres 服务商,缺少正式的 enterprise sales 与迁移服务
Supabase 从 25H1 到 26Q1 有一系列改善这些情况的产品布局:
• OLAP 连接:有一系列重要发布,包括 Supabase ETL(Postgres WAL 到 Iceberg 的流式 CDC)、Analytics Buckets(基于 Iceberg 与 Parquet on S3 的托管对象存储)、Iceberg Foreign Data Wrapper、以及与 AWS S3 Tables 的合作,合计构成“OLTP + OLAP on open formats”的完整链路
• 网络隔离:PrivateLink 通过 AWS VPC Lattice 于 2026 年 1 月 GA,覆盖企业采购清单中“数据库不得暴露于公网”要求的 60%–70% 场景。剩余场景涉及 GCP 与 Azure 客户的同等私网连接能力,仍在建设中
• 合规:SOC 2 Type 2(已取得)、HIPAA with BAA(已取得)、ISO 27001 stage 2(接近尾声)。Trust Center 已上线。覆盖大部分商业 B2B 与医疗健康场景的合规准入
• Sales 与 advisory 团队:Strategic CSA(Customer Success Architect)团队在 AMER、EMEA、APAC 三地的招聘已启动,含 Team Lead 岗位;岗位 scope 明确包含对 Oracle 与 SQL Server 客户的迁移服务
目前还存在的 enterprise gap 包括:
• SCIM:Supabase 不提供开箱即用的 SCIM,客户需要使用 API、SQL、Webhooks 自行构建
• Managed BYOC:目前没有这项能力,很难卖给高监管行业和政府
• PCI DSS:目前没有但不必须,主要影响需要在数据库内处理信用卡数据的收付款场景
• FedRAMP:目前没有,但拓展联邦政府及国防客户需要拥有
我们判断 Supabase 的 Enterprise-ready 程度在 75% 左右,缺少 SCIM 和 BYOC 两个关键点,但基本的支柱都已经拥有或者在建设,需要重点突破的还是 scalability。
04. 增长 Driver
下面两个 growth driver 是 Supabase 在 2025 年至今能获得高速增长的主要原因,并且目前看继续延续 6-12 个月的确定性非常高:
Scale with startup
Supabase 的主要获客漏斗顶端为初创公司与个人开发者,计费模型为使用量驱动(database size、compute hours、active users、egress 等)。这意味着一旦客户进入 Supabase 生态,其对 Supabase 的营收贡献将随该客户自身规模扩张而线性甚至超线性增长。客户从零 ARR 启动项目,24–36 个月内若产品 PMF 成立,Supabase 对该单客户的 ARR 贡献可从零提升至数千到 50 万美元级别。目前有 65% 的 YC 公司是 Supabase 的客户。
Vibe coding
Vibe coding 对于 Supabase 的增长驱动有两方面:
• Rev-share:Lovable、v0、Bolt、Figma Make 等平台将 Supabase 作为默认 backend 内置,按用户 provisioning 的 database 向 Supabase 分成或反向采购 API quota。Supabase 让渡了一部分收益,但换来了更多的流量
• 非平台的 vibe coder:
1) 开发者选择后端的决策路径经历是:Hacker News 与技术博客(2010–2015)→ GitHub stars 与 Twitter(2015–2020)→ developer conferences 与 swag(2020–2024)→ coding agent 自动推荐(2024 至今)
2) Claude Code、Codex、Cursor、Windsurf 等通用 coding agent 本身不与 Supabase 有商业合作,但其生成代码或跟用户 Q&A 时倾向于推荐 Supabase
3) 这让 Supabase 几乎零获客成本地获得了大量流量
下图为第三方从数百个 Claude Code session 种统计的 agent 推荐比例,Supabase 在多个类目都位于 top3:
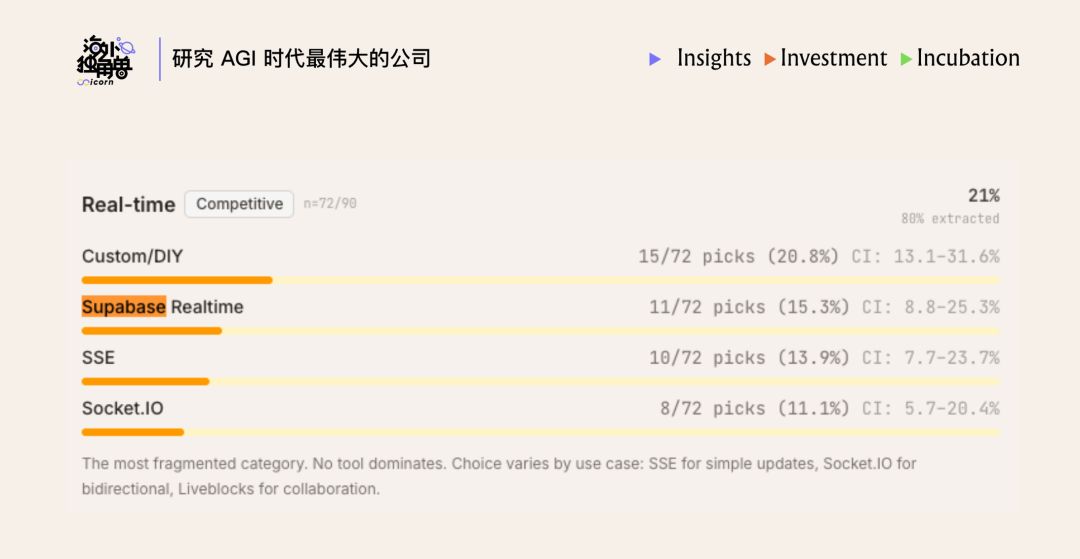
05. 关键挑战/Risk
竞争
我们判断 Supabase 目前有 3 个维度的竞争者:
• Postgres 生态内的云厂商和 Neon 等竞品,它们提供更纯粹的 Postgres 数据库,适合那些将 Supabase 平台化能力视作 vendor lock-in 的客户
• Convex 等架构差异化的 BaaS 竞争对手
• Insforge、db9 等 agent-first 竞争者以及 AI 继续发展的不确定性
云厂商原生 Postgres:Aurora DSQL、AlloyDB 等
AWS 与 Google 具备将 Postgres 兼容层叠加于其分布式存储基础设施之上的工程能力,并可在单项 benchmark(吞吐、延迟、可用区容错)上超过 Supabase。已有 AWS commit 预算且仅需纯数据库能力的企业客户,默认选择 Aurora 或 AlloyDB,Supabase 在此场景中完全不占优。但在应用需要开箱即用后端的场景中,Supabase 占优。
Serverless Postgres:Neon 等
Neon 专注于存算分离、即时分支等技术方向,引领了 OrioleDV 之外的另一条路线。在海量的、短寿命的小数据库 workload 上,Neon 的架构更适合,它也的确有 Replit 作为客户。Databricks 于 2025 年完成对 Neon 的收购。
在 Neon 之上构建完整应用需客户再行拼接 Auth、Storage、Functions、Realtime 四个独立供应商。这导致 Neon 的 npm 下载量增长在过去 6 个月显著低于 Supabase 和 Convex。但仅需纯数据库能力的企业客户或者资深的开发者会选择 Neon 然后自行拼接其他服务。
NoSQL/Non-Postgres 的竞争对手:Convex
我们之前详细介绍过 Convex 的技术特点和潜在 TAM。对于 Reactive 的应用,Convex 的契合程度远高于 Supabase,它也是目前 vibe coder 社区中心智最强的 Supabase alternative。
AI 快速发展的不确定性
若 agent 的自主性提升至不再依赖训练语料中的语法习惯、品牌传播等,而是更自主独立地选择和改造现有后端方案,目前 Supabase 的 distribution moat 将受到结构性削弱。
UE
Supabase 虽然获客成本很低,但它的免费层产品有大量的沉睡数据库需要预留云资源,会限制其毛利和 UE 的上限。目前 Supabase 有 auto-pause 机制,但更用户友好的方案依赖于 Multigres、Supabase Lite 等产品押注的进展,毛利率和 UE 的趋势是后续和公司交流的重点。
TAM & 企业客户市场
目前 Supabase 拥有一些大型企业 logo,但仍然仅被用于其创新性的探索项目。以下为客户访谈中的一些案例:
• Cisco(VP Data Analytics & AI):仅限内部创新实验室 sandbox 使用,预算约 10 万美元且与 Firebase 共享,认为企业级还不成熟
• Thermo Fisher(Director IT Operations):仅用于轻量级移动应用,约 15 个 app,明确表示不适合 ERP 级别的关键系统
• Bloomberg(Head of CTO Compute Architecture):仅用于内部原型和 MVP,数据量 <100GB、花费 <20 万美元,认为太新不适合关键基础设施
若仅考虑应用开发者这一群体的扩张和 BaaS 在 AI 应用中的渗透,Supabase 所处的这一新兴市场的体量在 78 亿美元级别:
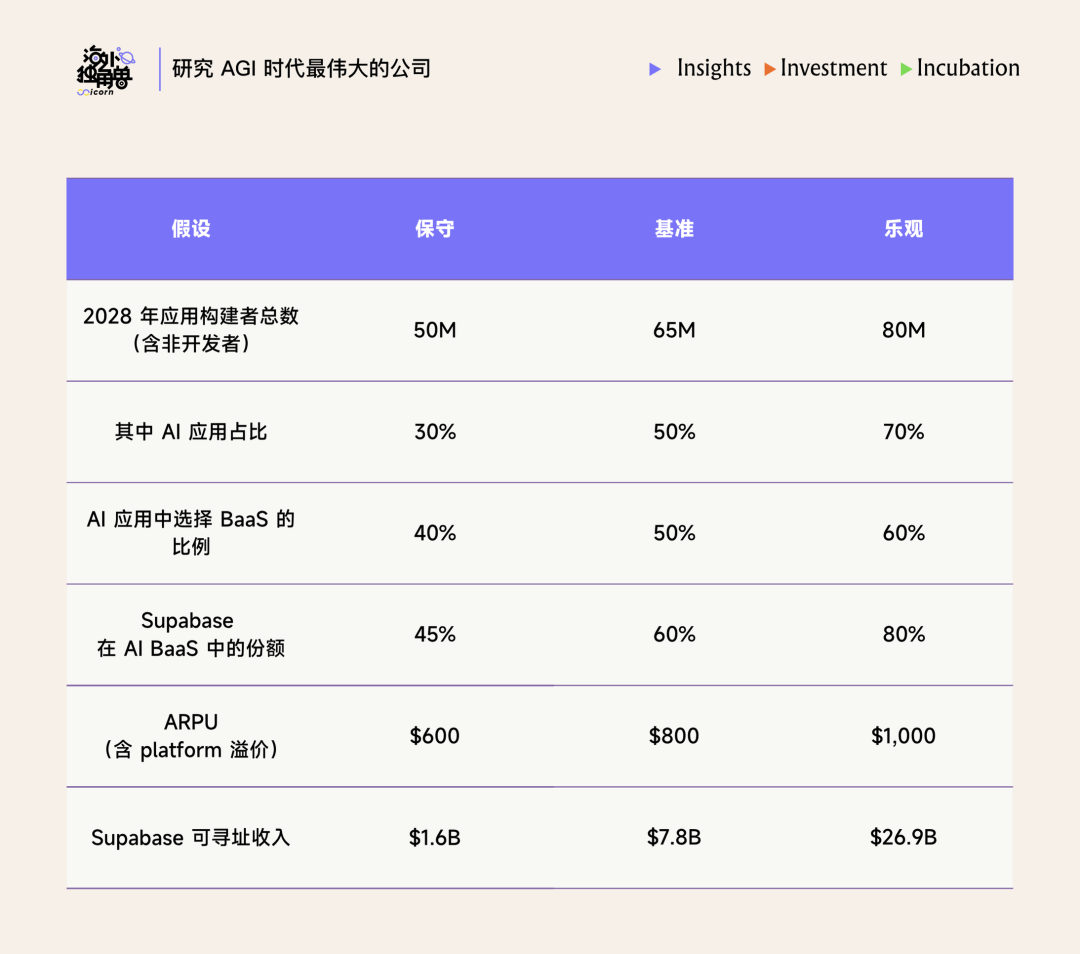
这一 TAM 和 Oracle 以及 Snowflake、Databricks 等已经完成平台化且主攻 Enterprise 的新兴数据平台公司的 TAM 对比,差距在 2-3 个数量级。因此 Supabase 在 Enterprise 市场的品牌接受度、scalability 拓展进度、GTM 能力构建对于其 TAM Expansion 都至关重要。
06. 团队
Paul Copplestone — CEO、联合创始人(2020 年至今)
• 履历:新西兰南岛 Kaikoura 农场背景。18 岁高中毕业后开始 tech contracting,本科就读于 University of Canterbury(2007 年获得 Bachelor’s degree),期间持续兼职开发。毕业后赴澳洲,首份全职工作在一家对冲基金做平台开发,随后加入 Accenture 澳洲(医疗与公共部门项目交付)做项目管理。意识到这条路径不是自己想要的之后转入创业:2015–2017 年在 Kuala Lumpur 担任 ServisHero(东南亚最大的家政服务市场之一)CTO/联合创始人;2018–2019 年创立 Nimbus for Work(办公管理平台)。2020 年 1 月通过 Entrepreneur First 新加坡项目与 Ant Wilson 匹配,共同创立 Supabase,同年进入 YC S20。
• 运营哲学:开源作为“不对称优势”(asymmetric advantage);“no-meetings”工程文化,全公司每周一次例会;全球远程团队,主动招聘前 founder;“playing startup vs. strategy”,区分“把创业当作扮演”和“把创业作为战略工具”;“收购已经做成过该事情的人,而非训练他人从头做”。
• 职能分工:资本分配、招聘哲学、对外叙事、开源战略。所有重大产品与组织决策经其本人输出。
Ant Wilson — CTO、联合创始人(2020 年至今)
• 履历:Imperial College London 软件工程硕士。先后在 Airsorted、Stylindex、Crypto Squad 等公司任工程岗位,经 Entrepreneur First 新加坡与 Techstars 伦敦两个加速器项目。与 Paul 在 EF 新加坡的 matching 阶段配对共同创立 Supabase
• 职能分工:工程文化、Postgres-native 架构、分布式系统、存储与 HA 设计。与 Paul 的分工在六年三次平台级转型(YC 产品 → 开源项目 → 云 SaaS)过程中保持稳定。Paul 称其非常善于和投资人沟通
07. 附录
Supabase 的四笔收购解读
Supabase 当前的成本结构问题很直白:每个用户项目对应一个独立的 managed Postgres 实例。Free tier 用户占了大量实例但不付钱。Pro 用户每月只付 25 美元,但 Supabase 要为每个实例付 AWS 的 compute + storage 费用。这意味着其毛利在被基础设施成本侵蚀。
它的四次收购都在从不同角度解决这个根本问题。
OrioleDB(2024.04)—— 用更少的资源做更多的事
OrioleDB 是一个 PostgreSQL 的替代存储引擎。Postgres 默认的存储引擎叫 Heap,从 1986 年用到现在。OrioleDB 通过 Postgres 12 引入的 Table Access Method(TAM)接口,提供了一个全新的存储层。你可以在同一个数据库里,某些表用 Heap,某些表用 OrioleDB,就像 MySQL 的 InnoDB 和 MyISAM 可以共存一样。
Postgres Heap 存储引擎有三个众所周知的“wicked problems”
• 问题 1:Table bloat(表膨胀)。 Postgres 的 MVCC 实现方式是:每次 UPDATE 一行,不是修改原来的行,而是创建一条新行。如果一行数据被 UPDATE 了 10,000 次,表里就有 10,000 行旧版本。这些旧版本就是 bloat。Bloat 占用磁盘空间、拖慢查询、增加 I/O。
• 问题 2:VACUUM 依赖。 为了清理 bloat,Postgres 需要定期运行 VACUUM。VACUUM 本身消耗 CPU 和 I/O,如果配置不当会导致性能下降甚至数据库中断。这是 managed Postgres 运维成本的主要来源之一。
• 问题 3:Buffer pool 瓶颈。 Postgres 的 shared buffer pool 需要维护一个 buffer mapping(内存页 → 磁盘页的映射),在高并发下成为锁竞争的瓶颈。
OrioleDB 的解决方案
• MVCC 基于 Undo Log:不创建新行,而是原地更新,把旧版本存到 undo log 里。这从根本上消除了 bloat。不需要 VACUUM。
• Index-organized tables:数据直接存在索引结构里(类似 Oracle 的 IOT),消除了 Heap 层的额外开销,主键查询直接命中数据。
• 消除 buffer mapping:内存页直接链接到存储页,不需要 buffer mapping,读取时不需要原子操作(lock-less)。
• Copy-on-write checkpoints + Row-level WAL:checkpoint 只写修改过的数据,WAL 按行而非按页记录,更紧凑,更容易并行化。
• 内置压缩:页级数据压缩,典型场景下数据库体积缩小 4-5 倍。
性能数据
• 只读测试:比 Postgres Heap 快 4x 以上
• 读写测试:比 Postgres Heap 快 4.5x 以上
• TPC-C benchmark(50GB 数据):比 Heap 快 5.5x
• 存储空间:压缩后缩小 4-5x
对 Supabase 商业模型的影响
• 这直接改善 gross margin。 如果同一台机器可以处理 4-5 倍的事务量,Supabase 就可以:
• 在同样的 AWS 实例上服务更多用户 → 单位基础设施成本下降
• 减少 VACUUM 相关的运维复杂度 → 运营成本下降
• 存储压缩 4-5x → 存储成本下降
• 为 agent workload 的高频 UPDATE 场景提供可行方案(传统 Heap 下 agent 的频繁 state 更新会产生严重 bloat)
• 同时创造了定价权。 OrioleDB 不是开箱即用的,它需要对 Postgres 核心打约 20 个 patch。这意味着只有 Supabase(以及少数自己 build 的团队)能提供 OrioleDB 的性能。用户不能在 AWS RDS 或 Neon 上使用 OrioleDB。这是一个 只有 Supabase 有的能力。
当前状态
• Beta 7 已发布(2024 年底)
• Supabase 已在文档中提供 OrioleDB 使用指南
• 目标是将 patch 上游到 PostgreSQL 核心(Postgres 18+ 可能成为纯 extension)
• 当前限制:仅支持 B-tree 索引(不支持 pgvector 的 HNSW),仅支持 ICU/C/POSIX collation
Multigres / Sugu Sougoumarane(2025.06)—— 突破单机限制
Multigres 是 Vitess 的 Postgres 改编版。Vitess 是 YouTube/Google 为了把 MySQL 扩展到全球级别而构建的分布式中间件,目前仍然支撑着 YouTube 的数据库层。Sugu Sougoumarane 是 Vitess 的联合创始人。
Multigres 不是修改 Postgres 本身,而是在 Postgres 前面加一层智能代理,让多个 Postgres 实例在应用看来像一个数据库。
Supabase 目前是单节点 Postgres。这意味着:
• 写入瓶颈:所有写入必须经过同一个 Postgres primary。无论 instance 多大,单节点的写入 TPS 有物理上限。对于 agent 高频写入 state 的场景,这是硬性约束。
• 垂直扩展的成本曲线:当用户需要更多性能时,唯一的选择是升级到更大的实例(Micro → Small → Medium → Large → XL → 16XL)。但 AWS 的实例成本不是线性增长——16XL 的成本可能是 Micro 的 100 倍,但性能不会是 100 倍。垂直扩展的单位经济在恶化。
• Enterprise 客户的天花板:大型企业的数据量和并发量可能超过单节点能力。这直接限制了 Supabase 的 enterprise ACV 天花板。
Multigres 的架构
• MultiGateway:接收客户端连接,按 database name 路由到正确的后端
• MultiPooler:每个数据库一个 Postgres 实例 + 连接池
• MultiOrch:管理复制、failover、consensus
• TableGroup:表可以跨多个 Postgres 实例分布,每个 TableGroup 独立分片
• 在线 migration:跨数据库和 Postgres 版本的无停机迁移
• Consensus 协议:保证 leader election 和 failover 自动化
对 Supabase 商业模型的影响
• 解锁 enterprise-scale workload = 解锁高 ACV 客户。 如果一个 enterprise 客户的数据库可以横向扩展到 10 个节点而不是升级到一个超大实例,Supabase 的 enterprise 定价可以从“一个大实例的价格”变成“一个集群的价格”——收入上限被根本性地提高。
• 改善多租户效率。 Multigres 的多数据库管理模式(一个 MultiGateway 后面挂多个 MultiPooler)可以让 Supabase 更高效地管理大量小型数据库。这对 free-tier 和 Pro 用户的成本结构有重大改善——大量小数据库可以被更高效地打包到更少的物理资源上。
• 为 agent 的 write-heavy workload 扫清障碍。 Agent 每一步都写 state、checkpoint、memory——这是高频写入。单节点有 TPS 上限,分片后写入可以分散到多个节点。这是 Supabase 从开发者体验公司升级为 agent-native 基础设施的技术前提。
• 创造独家定价权。在 Postgres 生态中,只有 Citus(被 Microsoft 收购,现在是 Azure 专属)和 Supabase 的 Multigres 提供 Postgres-native 分布式能力。Neon 做了 compute/storage 分离但没有做分片。这意味着需要分布式 Postgres 的客户选择极少,让 Supabase 有定价权。
当前状态
• Early development 阶段
• 有 design partners(具体名单未公开)
• Sugu 和 Deepthi 将在 2026.04 Postgres Conference 演讲
• 正在招聘 Multigres 工程师(Go Kubernetes operator、networking)
• Apache 2.0 开源
Hydra / pg_duckdb(2025.12)—— 让 Postgres 做分析
Hydra 团队联合开发了 pg_duckdb,一个让 DuckDB(列式分析引擎)在 Postgres 内部运行的 extension。简单说:你发一个复杂的分析查询,pg_duckdb 自动判断这个查询适合用列式引擎处理,然后用 DuckDB 执行——而不是用 Postgres 的行式引擎。对用户来说,体验没有区别(同样的 SQL、同样的 Postgres 连接),但速度提升了数十乃至数百倍。
同时,Supabase 推出了 Analytics Buckets(基于 Apache Iceberg + AWS S3 Tables),提供 Postgres 接口下的列式存储。
它解决什么问题
• 混合负载的资源竞争。 传统 Postgres 里,如果你同时跑 OLTP(事务处理)和 OLAP(分析查询),分析查询会抢走 OLTP 的 CPU 和 I/O,导致 app 变慢。用户的选择通常是:要么不在 Postgres 里做分析(导出到 Snowflake/BigQuery),要么忍受性能下降。
• Supabase 客户的 ARPU 天花板。 如果用户的分析需求必须通过导出到外部数据仓库来满足,那这部分收入就流向了 Snowflake 而不是 Supabase。Supabase 的 ARPU 被限制在“纯 OLTP”的范围内。
对 Supabase 商业模型的影响
• 打开 upsell 通道。 Analytics Buckets + Warehouse 让 Supabase 可以向同一个客户同时收 OLTP 费用(Database)和 OLAP 费用(Analytics Buckets + Warehouse)。一个原来只付 $25/月的 Pro 用户,如果开始用分析功能,可能变成 $100-500/月。
• 减少数据出逃。 如果分析可以直接在 Supabase 里做,用户就不需要把数据导出到 Snowflake。数据留在 Supabase = 收入留在 Supabase。
• 降低分析场景的资源消耗。 pg_duckdb 用列式引擎做分析查询,比 Postgres 的行式引擎高效得多——同样的分析查询消耗更少的 CPU 和 I/O。这改善了 Supabase 的 per-query 成本。
• 为 AI/RAG 场景打基础。 Vector Buckets(embedding 冷存储)+ Analytics Buckets(结构化数据分析)+ ETL(一键数据流转)的组合,让 Supabase 可以成为 AI 应用的完整数据栈,从 OLTP(app 数据)到分析(用户行为)到 AI(向量检索)全覆盖。这比 pgvector 单打独斗的价值大得多。
当前状态
• Analytics Buckets: Public Alpha (2025.12)
• Vector Buckets: Public Alpha (2025.12)
• ETL (Postgres → Iceberg + Vector) : Private Alpha (2025.12)
• Supabase Warehouse(Hydra 主导):开发中
BKND(2026.02)—— 服务新型用户
BKND 是一个轻量级的通用后端系统,基于 Web Standards 构建,可以在任何地方运行(Next.js、Cloudflare Workers、Bun、Node、AWS Lambda 等)。BKND 的创始人 Dennis Senn 加入 Supabase 后,在为 Supabase 构建面向 agentic workloads 的 Lite 产品。
BKND 的核心特征:内置数据管理、认证、媒体存储、workflow builder,支持 MCP server,支持 agent state 管理,支持多种数据库和存储后端。
Agent workload 和传统 web app 的需求差异。 Agent 不需要 Dashboard、不需要漂亮的 UI、不需要文档写得好。Agent 需要的是:轻量(快速启动、低 overhead)、可编程(API-first、SDK-first)、state 管理(agent 的对话历史、任务进度、checkpoint)、MCP 集成(agent 通过 MCP 直接操作后端)。
传统的 Supabase 对 agent 来说太“重”了,一个 managed Postgres 实例 + Dashboard + PostgREST + Realtime + 所有 feature 的 overhead,对于一个只需要“存一下 agent 的状态然后继续”的场景来说,是杀鸡用牛刀。
Free-tier 的成本问题。 如果每个 agent 需要一个完整的 Supabase 实例,成本模型不成立,一个用户可能有 10 个 agent,每个 agent 的后端不可能各用一个独立的 managed Postgres。
对 Supabase 商业模型的影响
• 开辟新的用户类型。 Supabase 现在的用户是人类开发者。BKND Lite 让 Supabase 可以服务 agent 作为用户。如果每个人有 3-10 个 personal agent,每个 agent 需要一个轻量后端,这个 TAM 是现有市场的数倍。
• 优化 agent 场景的资源消耗。 Lite 意味着更少的 resource overhead per agent。Supabase 可以在同样的基础设施上服务更多的 agent workload,改善 agent 场景下的 unit economics。
• 补全 MCP 生态。 BKND 内置 MCP server,意味着 Supabase 的 agent 产品不是给 Postgres 加一个 MCP 接口,而是一个 agent-native 的轻量后端,底层连着 Supabase 的数据和认证。这更符合 agent 开发者的心理模型。
• 为 scale-to-zero 铺路。 BKND 的轻量架构天然适合 scale-to-zero,agent 不活跃时不消耗资源。Supabase 的 AI Builders 白标方案已经提供 scale-to-zero 能力。BKND Lite 和 scale-to-zero 结合,可以让 Supabase 以极低的 marginal cost 服务大量间歇性的 agent workload。
当前状态
• 开发中(Dennis Senn 2026.02 加入)
• BKND 本身是开源的(Apache 2.0),将保持开源
• 具体产品形态和发布时间未公开
客户访谈反馈分析
我们使用 8 个维度对 12 个不同的 Supabase 客户访谈进行了分析,以下是可视化概览:
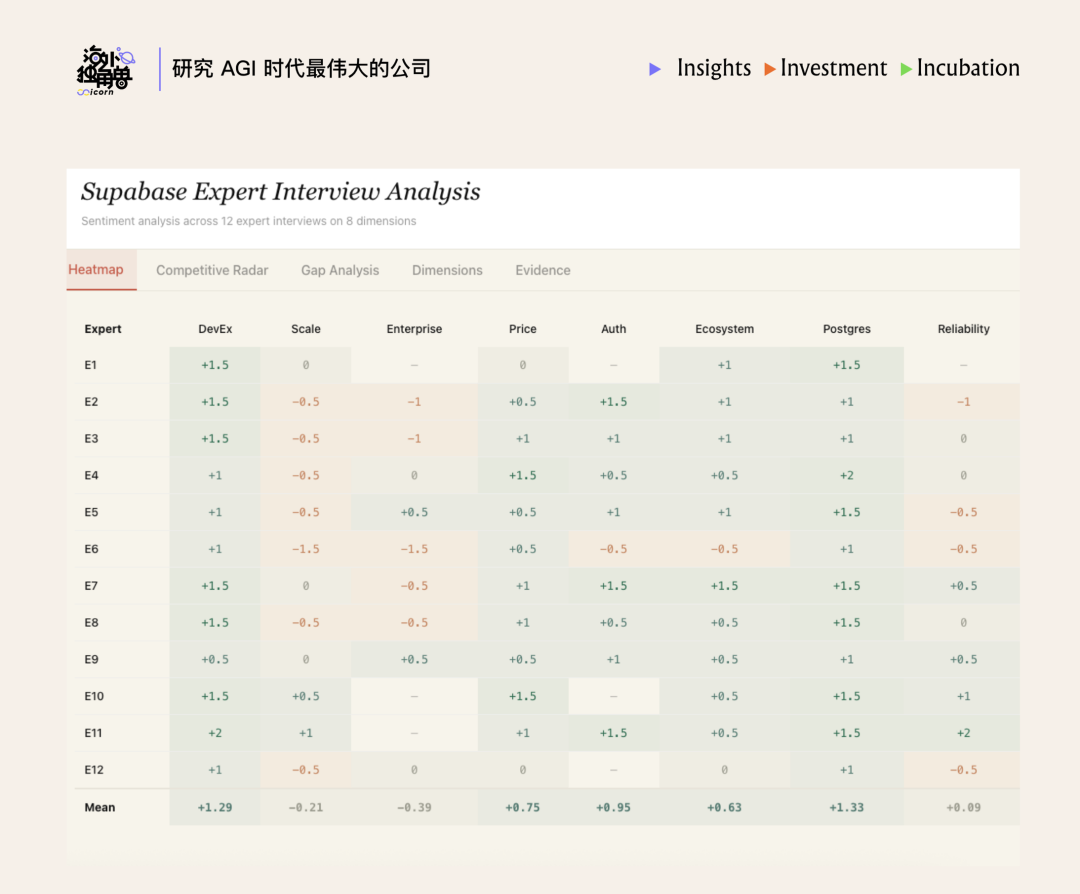
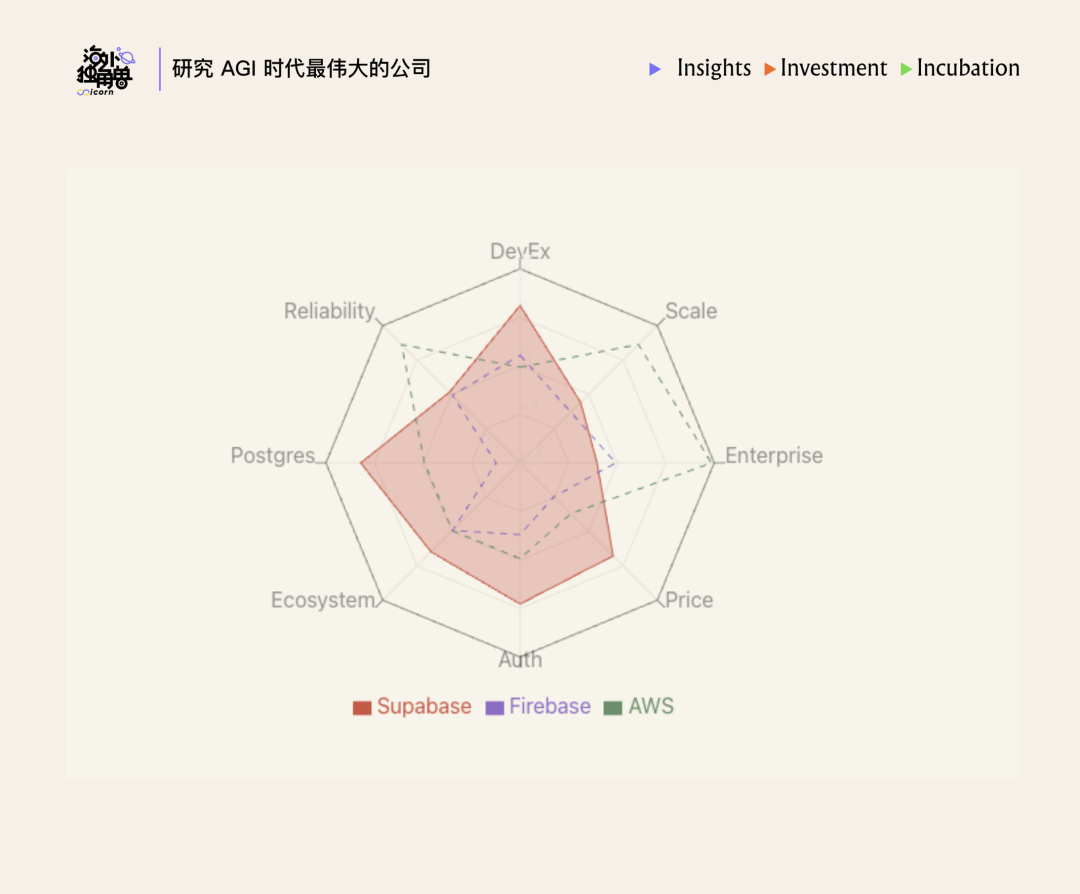
作者:Patrick
本文由人人都是产品经理作者【海外独角兽】,微信公众号:【海外独角兽】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。






- 目前还没评论,等你发挥!


