
 起点课堂会员权益
起点课堂会员权益AI 产品经理手记:badcase如何回流(下)
模型评测后的badcase处理是一门精细活,不是所有问题都该丢给模型训练。本文将拆解badcase五大分类法则,揭示知识库错误、行为模式、风格偏好等不同问题的处理策略,并分享如何构建金标集实现可追溯的模型迭代闭环。从业务视角出发,带你看懂如何让模型真正越变越好。

评测产出的 badcase 怎么真正喂回模型?哪些该训、哪些不该训、训了反而更糟的有哪些。
上一篇写了我怎么重做单轮和多轮的评测框架——L1 致命错误一票否决、L2/L3 分层扣分、多轮 M1~M5 五个专属维度。
但评测本身不创造价值,评测的产出必须能改进模型。否则就是每周开会打一遍分,模型迭代了一版又一版,业务侧还是觉得不行——大家都很忙,但产品没有变好。
这一篇讲的就是后半段:标完一堆 badcase 之后,怎么把它真正变成下一版模型的进步。这部分是我跟大数据团队磨合最久的——不是因为他们不配合,是因为一开始大家对“什么 badcase 该训模型”的理解就不一样。
一、闭环长什么样

这张图的核心信息只有一条:badcase 不是一个桶,是五个桶,每个桶的处理方式完全不同。
二、不是所有 badcase 都该训模型
2.1 知识库问题——绝对不能训进模型
包括:事实错误、链接不可用、信息过期
我专门拿了 10 条标了”事实错误”的 case 复盘,发现 7 条是 RAG 召回错了对应文档,2 条是知识库里那条数据本身就过期了,只有 1 条算是模型”自由发挥”。
如果把这些 case 直接 SFT 进模型,等于让模型学会了一份自信但错误的知识。后果有两个
- 知识库后续就算改对了,模型还是会按训进去的错版本回答
- 模型对自己学过的内容置信度更高,反而更不愿意触发 RAG 召回
正确做法:
- 召回错→ 优化 embedding / 加省份过滤 / 改 chunk 切分
- 知识库错→ 走数据治理流程,业务侧确认后修正源数据
- 模型自由发挥→ 极少,但确实可以 SFT,让它学“不确定就承认不知道”
2.2 行为模式问题——该 SFT 训
包括:暴力拒答、任务未闭环、无效反问、答非所问
这些是模型”行为习惯”层面的问题——它知道知识,但不知道该怎么用。这是 SFT 的经典题材。举个最典型的例子:
原回复(被打 0 分):
“我是 XX 的销售助手,很抱歉暂时未能找到与您的需求相关的信息。”
改写后目标回复:
“您说的这个我们没有直接对应的产品,不过类似需求可以看看 XX / 也可以转人工咨询,您要不要试试?”
收集 50~100 对这样的(原回复 / 改写后回复),做一轮针对性 SFT,效果会有明显改善。关键点:改写不是模型团队拍脑袋写,是业务侧来写。只有业务侧知道”在我们的业务体系里,这个场景的最优回复长什么样”。
2.3 风格偏好问题——该 DPO 训,不该 SFT
包括:冗余啰嗦、话术僵硬、排版混乱
直觉是”啰嗦了那就给它一个简洁版本去学”,但实际上 SFT 一个”简洁版”经常会带来模型整体表达能力的退化——它会矫枉过正地变成”惜字如金”,丢失原本好的引导性表达。
正确的做法是DPO(直接偏好优化):给模型同时看(啰嗦版 / 精炼版),让它学的是两个版本之间的偏好关系,而不是只学其中一个。这样模型保留了表达多样性,只是在”啰嗦 vs 精炼”这个维度上向你期望的方向倾斜。
我们目前积累了大约 200 对风格偏好对,分三类:
- 长度偏好(啰嗦版 / 精炼版)
- 语气偏好(公式化版 / 自然版)
- 结构偏好(流水账版 / 结构化版)
2.4 一张总结表
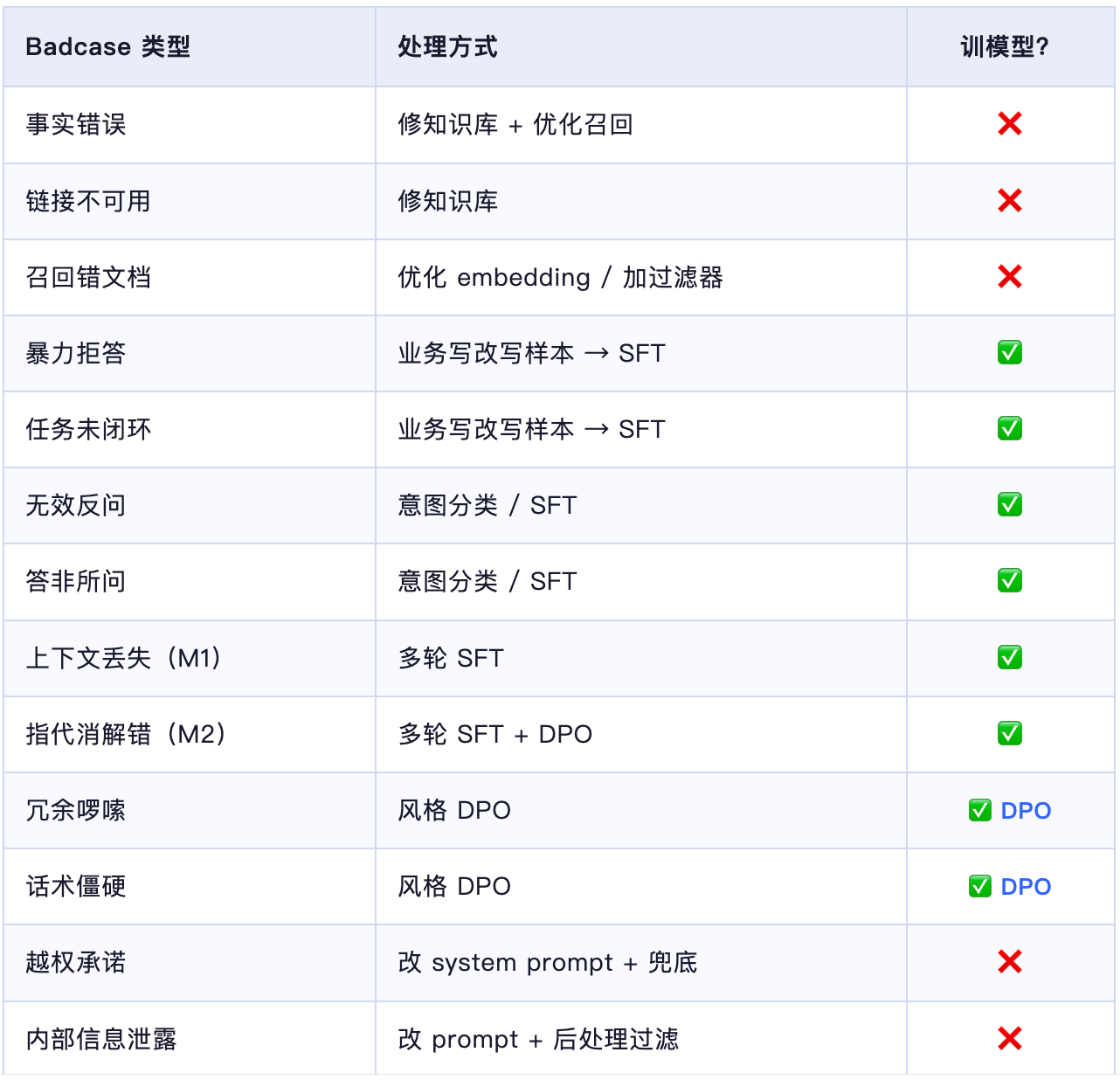
先对着这张表分类,然后才讨论怎么改。分类对了,处理方式自然就清楚了。
三、评测集必须固定一份”金标集”
每次新版模型出来,必须跑一遍 200~500 条的金标集,对比上一版各维度分数变化。
我的金标集是这么构造的:
- 30%高频简单问(FAQ 类,地板线)
- 40%中等业务场景(套餐/流量包/终端/增值业务,主战场)
- 20%多轮复杂场景(指代+意图切换混合,天花板)
- 10%故意刁难(错别字、超长、夹杂方言、恶意绕过)
金标集要定期更新,但绝对不能频繁更新。我们的节奏是每季度补充 10% 新 case、淘汰 5% 过时 case。如果每个月都换一批,回归测试就失去比较基准了——你永远不知道是模型变好了,还是题变简单了。
四、回归测试要看分项变化,不只看总分
新版上线前,不要看”总分提升了 3 分”,要看:
4.1 L1 致命错误是不是清零了
没清零不让上。这是死线。
一个版本如果总分提升了 5 分但 L1 错误还有 3 条,业务侧应该拒绝它。因为生产环境下,1 条 L1 错误(比如说错价格、伪造链接)的破坏力远大于 100 条 L2 错误。
4.2 L2 严重项的扣分分布有没有变化
比如”任务未闭环”从 38% 降到 20%——这是真正有意义的进步。
如果分布几乎没动,只是总分升高了,那很可能是金标集里简单题答得更好了、难题没动——这种“分数提升”是虚的。
4.3 有没有出现新的扣分类型
新错误比老错误更危险。
最常见的就是:为了治”暴力拒答”,模型学会了”什么都给你推荐两款产品”,结果”答非所问”的占比上来了。这种”按下葫芦浮起瓢”必须警觉。
4.4 多轮 M1~M5 五个维度不能 backward
很多模型微调单轮变好了,多轮反而崩了——必须分开看。
我见过一次很惨烈的:模型团队为了治单轮的”答非所问”,加强了模型的”主动话题引导”能力,结果多轮的”上下文继承”分数掉了 15 个百分点。因为模型变得太”主动”了,不再老老实实地围绕用户的上一轮回答。单轮和多轮的回归报告必须分开出。

五、回流节奏:不要每周训,要按版本节奏走
- 频繁微调会让模型不稳定——每周一个版本,业务侧根本来不及做回归
- 小批量训练样本噪声大——30 条样本里如果有 5 条标注有偏差,影响会被放大
- 没法定位是哪批数据起的作用
现在的节奏:

这个节奏走下来,每次新版本上线,业务侧能清楚地说出来”这版相比上版,在哪些维度提升了多少、有没有新引入的问题”。而不是模型团队说”我们又训了一版,你看看”,业务侧凭感觉点头或摇头。
六、回到那个原始问题
写这两篇文章之前,我问过自己一个问题:作为业务侧,我到底想要什么?
答案是:我想要一套可以让模型迭代真正变好的机制。不是评测漂亮的报告,不是 95% 的准确率,是一套能让”用户体验”这件事可被衡量、可被改进、可被追溯的工程闭环。
这个机制的两个支柱:
- 上一篇:一套业务能看懂、能扣分、能 challenge 的评测框架
- 这一篇:一套从评测产出到模型迭代的回流路径
两个加在一起,才是完整的”业务侧主导 AI 产品质量”的工作流。少了任何一个,要么是评了不改、要么是改了不知道有没有变好。
我在做企业 AI 落地的过程记录和产品思考,会持续把这种”battle 出来的东西”写下来。下一篇大概率会写:RAG 召回评测怎么和模型评测分开做,以及为什么知识库的脏数据是 AI 客服上线的最大隐形成本。感兴趣的可以关注我。
本文由 @是AD 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自 unsplash,基于CC0协议






- 目前还没评论,等你发挥!


