
 起点课堂会员权益
起点课堂会员权益面试题:AI产品经理如何进行大模型选型?
大模型选型绝非简单的性能对比赛,而是关乎产品成败的战略决策。从任务类型到成本控制,从工程化落地到风险规避,一套严谨的选型方法论正在成为AI产品经理的核心竞争力。本文深度拆解场景适配、模型对比、成本核算、部署验证四大关键维度,助你在面试和实战中做出精准判断。

面试AI产品经理,10个面试官有9个会问这个问题:
“如果让你给我们的产品选一个大模型,你会怎么做?”
很多人一上来就说:
“我会选GPT-5.4,因为它最强”,或者“我会选Qwen 3.5,因为它开源免费”。
如果你是这种回答,那直接就凉了。
因为大模型选型根本不是“谁强选谁”这么简单。
它是一个系统工程,需要综合考虑场景、性能、成本、工程化、风险等多个维度。
下面介绍一套大模型选型方法论,不管是面试还是实际工作,都能用得上。
01 先搞清楚你的场景到底需要什么
这是最容易被忽略,但也是最重要的一步。
很多人上来就对比模型参数,这完全是本末倒置。
记住:没有最好的模型,只有最适合你场景的模型。
你需要从三个维度拆解你的场景需求:
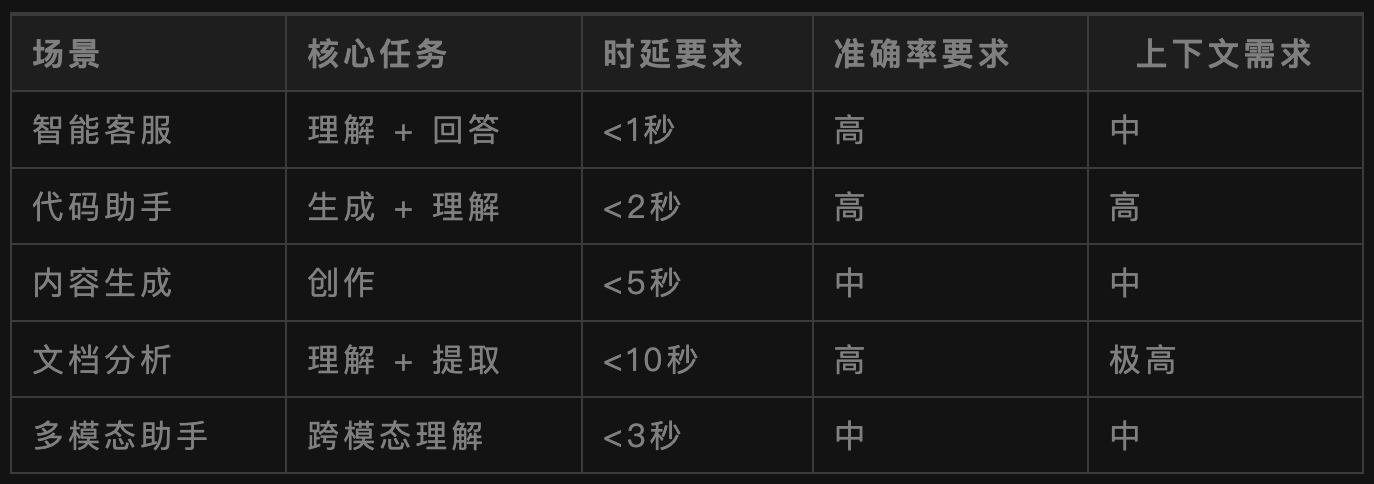
1、任务类型:生成、理解还是多模态?
不同的任务对模型能力的要求天差地别。
- 生成类任务对模型的创造力和流畅度要求高,比如写文案、写代码、写报告。
- 理解类任务对模型的准确性和逻辑性要求高,比如分类、提取、总结、问答。
- 多模态任务需要模型具备跨模态理解能力,比如图文理解、视频分析、语音交互。
举个例子:
如果你要做一个智能客服,核心任务是理解用户问题并给出准确答案。
那么你应该优先选择理解能力强的模型,而不是生成能力强的模型。
2、性能指标:延时、准确率、安全
这三个指标是产品体验的核心,必须量化。
实时交互场景,如聊天机器人,要求延时<1秒。
非实时场景,如报告生成,可以接受几秒甚至几十秒的延时。
不同场景对准确率的要求不同。
比如医疗诊断场景要求准确率>99%,而普通聊天场景80%的准确率就可以接受。
金融、医疗、政务等敏感场景对内容安全要求极高,必须严格防范有害内容生成。
3、输入输出:文本长度、多语言支持
如果你的产品需要处理长文档(如合同、论文),那么模型的上下文窗口大小就非常重要。
目前主流模型的上下文窗口已经达到了256K-1M Tokens。
如果你的产品面向全球用户,那么需要选择多语言能力强的模型。
我给你一个简单的表格,帮你快速判断不同场景的核心需求:
02 模型参数与性能对比
搞清楚需求之后,就可以开始筛选模型了。
主流大模型可以分为两大类:闭源API模型和开源模型。
1、主流闭源模型对比
闭源模型的优势是开箱即用、性能稳定、更新及时。
劣势是成本高、数据不安全、定制化能力有限。
目前全球顶级闭源模型有四个:
OpenAI GPT-5.4 Pro、Anthropic Claude Opus 4.7、Google Gemini 3.1 Pro、字节跳动Doubao Seed 2.0 Pro。
国产旗舰闭源模型有:
通义千问 3.6 Plus、文心一言 5.0、GLM-5.1。
下面整理了2026年Q1各大模型性能对比数据:
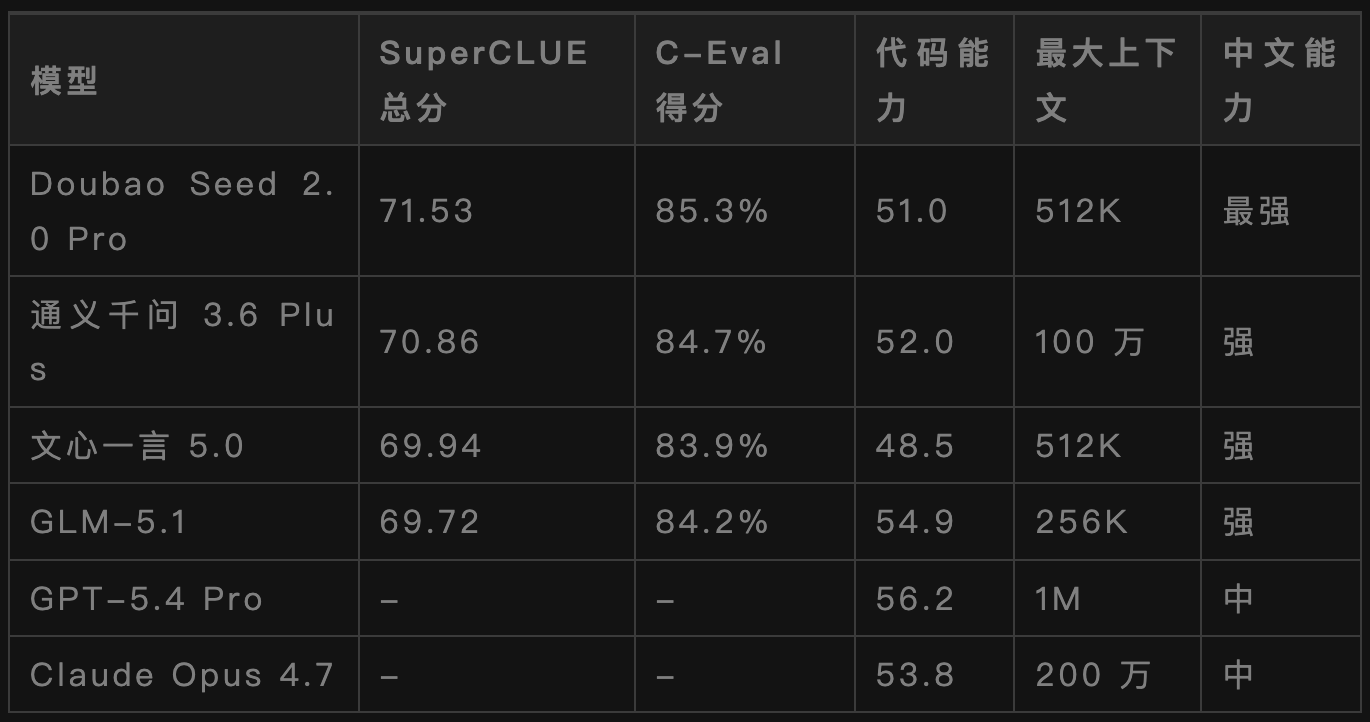
从数据可以看出,国产模型在中文理解能力上已经全面超越了海外模型,在代码能力上也不相上下。
2、主流开源模型对比
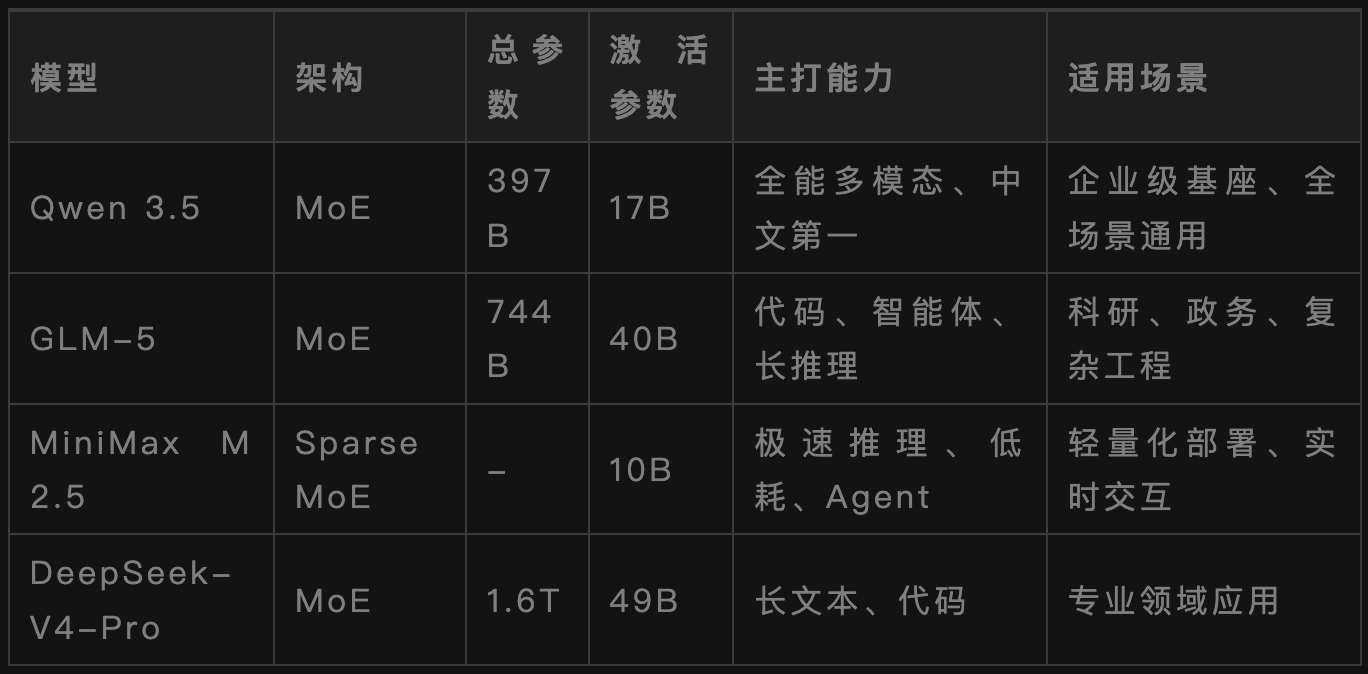
开源模型的优势是成本低、数据安全、可以自由定制。
劣势是部署复杂、需要专业的运维团队、性能略低于顶级闭源模型。
2026年最受欢迎的开源模型有:
Qwen 3.5、GLM-5、MiniMax M2.5、DeepSeek-V4-Pro。
3、领域适配度:是否需要垂直微调?
通用大模型在垂直领域的表现往往不尽如人意。
如果你的产品是面向特定行业的(如医疗、法律、金融),那么你需要考虑模型是否经过了垂直领域的微调。
比如:
- 医疗领域:可以选择经过医疗数据微调的Med-PaLM 3或者国内的医联大模型
- 法律领域:可以选择北大法宝大模型或者法大的法大模型
- 金融领域:可以选择同花顺大模型或者恒生电子的金融大模型
03 成本对比:算清楚这笔账
大模型的成本是很多公司最关心的问题。
你需要从两个方面对比成本:推理成本和算力成本。
1、推理成本:API调用 vs 自建GPU集群
这是最核心的成本对比,我给你算一笔账:
假设你的产品每天需要处理5万次复杂的业务请求,平均单次请求包含1000输入Tokens + 500输出Tokens,一个月总计消耗约22.5亿Tokens。
方案一:调用公有云顶级API
前期投入:¥0
Token/计算运行费:约¥55万/年(按实际流量计费)
机房托管与网络:¥0
运维与调优人力:0.2FTE(仅需应用层开发人员,约¥5万/年)
年总成本:¥60万
方案二:自建私有化机房(70B开源模型,单台8卡H200服务器)
前期投入:约¥200万(硬件及网络采购)
Token/计算运行费:约¥9万/年(电费+制冷费)
机房托管与网络:约¥12万/年
运维与调优人力:2FTE(需要专业大模型部署、推理优化工程师,约¥70万/年)
年总成本:约¥91万/年(不含前期硬件投入)
从这个对比可以看出:
当流量较小时,调用API更划算,因为没有前期投入和运维成本
当流量足够大时,自建集群更划算,因为边际成本很低
2、算力成本:模型参数量与GPU显存关系
模型参数量越大,需要的GPU显存就越多,成本也就越高。
一个简单的对应关系:
- 7B模型:单张H200 GPU
- 13B模型:单张H200 GPU
- 34B模型:需要2-4张H200 GPU
- 70B模型:需要4-8张H200 GPU
- 175B模型:需要16-32张H200 GPU
目前单张英伟达H200 GPU的月租金约6.0-6.6万元人民币。
可以根据这个数据估算自建集群的算力成本。
3、成本优化技巧
这里分享几个行业内常用的成本优化方法:
智能路由
简单任务用小模型,复杂任务用大模型。
比如普通的文本分类用7B模型,复杂的推理用70B模型。
这样可以在不牺牲体验的前提下,降低80%的成本。
结果缓存
缓存常见查询的结果,避免重复计算。
模型量化
将FP32模型量化为FP16或INT8,可以降低显存占用,提升推理速度,同时精度损失很小(通常<1%)。
批量处理
对于非实时任务,可以批量处理请求,提高GPU利用率。
04 工程化评估:能不能落地才是关键
一个模型再好,如果不能稳定、高效地部署到生产环境,那也没用。
需要从三个方面进行工程化评估:
1、部署验证:精度损失与性能
当把模型从训练环境部署到生产环境时,通常需要进行格式转换和优化。
最常用的格式是ONNX(开放神经网络交换格式)。
这时需要做以下几点验证:
精度损失
将模型转化为ONNX标准格式后,精度损失是否在可接受范围内。
一般来说,FP16量化的精度损失<0.2%,INT8量化的精度损失<1%。
推理性能
在生产环境下,模型的推理速度和吞吐量是否满足要求。
显存占用
模型在运行时的显存占用是否在你的硬件资源范围内。
2、工具链完整性
如果一个模型没有配套的工具链,那么你需要自己开发,这会大大增加工程化的难度和成本。
一个完整的大模型工具链应该包括:
- 提示工程工具:帮助你编写和优化提示词
- 评估体系:自动评估模型的性能和效果
- 模型自动更新:持续训练Pipeline,让模型不断学习新的数据
- 监控告警:实时监控模型的运行状态、性能和成本
3、风险审查:这些坑一定要避开
大模型应用有很多潜在的风险,你必须在选型阶段就考虑到:
最大并发请求量
你的系统能否承受峰值流量?
如果不能,需要设计限流和降级机制。
训练数据来源合法
模型的训练数据是否有版权问题?
如果有,可能会面临法律风险。
商用限制
- 有些开源模型有商用限制,比如不能用于商业用途,或者需要付费。
- 有害内容概率及防护有效性
- 模型生成有害内容的概率有多大?
- 是否有有效的防护措施?
特别是内容安全问题,在金融、医疗、政务等敏感领域,这是一票否决项。
最后
针对面试问题,如果你能按照这个框架来回答,面试官一定会对你刮目相看。
因为这说明你不是一个只会纸上谈兵的产品经理,而是一个真正懂技术、懂业务、能落地的AI产品经理。
AI产品经理的核心价值不是懂多少技术术语,而是能够在复杂的技术和业务之间找到平衡点,做出最优的决策。
本文由人人都是产品经理作者【伍德安思壮】,微信公众号:【时间之上】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。









智能路由的阈值怎么定?如果用户请求是混合任务,比如既需要理解又需要生成,路由到不同模型会不会出现上下文割裂?
场景拆解那一步确实最容易被跳过。很多人拿着模型就上,结果回头发现生成能力过剩、理解能力不够,白花钱。
选型不是比参数,是把场景、成本、工程和风险串起来做权衡。思路清晰,尤其是成本对比那笔账,很实在。