
 起点课堂会员权益
起点课堂会员权益企业知识图谱如何正确分类?
当企业知识图谱遭遇分类困境,往往不是分得不够细,而是维度本身出了问题。本文通过通信运营商知识体系的真实案例,揭示树状分类在多维交叉场景中的结构性缺陷,并提出用标签体系替代传统分类的解决方案。从底层逻辑到实操方法,带你破解知识建模中最常见的'越分越乱'困局。

做企业知识图谱这半年,我踩过不少坑。但有一个坑,是几乎每个做知识建模的人都会撞、撞上了还经常不知道自己撞了什么——
分类做着做着,就乱了。
不是分得不够多,恰恰相反,是越分越多、越多越乱:条目互相重复、有些东西怎么归都不对、同一个东西放在 A 类也行放在 B 类也行。最后整个分类体系变成一团,谁来都理不清。
这篇想把这个坑讲清楚。如果你在做知识图谱、知识库、RAG 的知识组织,或者任何需要”给一堆东西分类”的工作,希望它帮你少走一段弯路。
一、先看一个具体的死结
我做的是某通信运营商的知识体系。一开始的任务很朴素:把业务知识分类,建立一套分类体系。
我们定了大概 70 个分类。listed 出来之后,问题立刻就来了。
举一个最典型的。我们有一个分类叫”政企产品”,又有一个分类叫”宽带产品”。看起来都没问题——直到出现一个东西:面向政企客户的宽带产品。
它该放哪?
放进”政企产品”?可它确实是宽带。放进”宽带产品”?可它确实是政企的。两个都放?那这条知识就在体系里重复了,以后一更新就要改两个地方,迟早不一致。
这不是个例。一旦你较真,就会发现这样的”两难”到处都是。你会本能地觉得是自己没想清楚、是分类还不够细——于是再去加分类、再去定规则。但越加越乱。
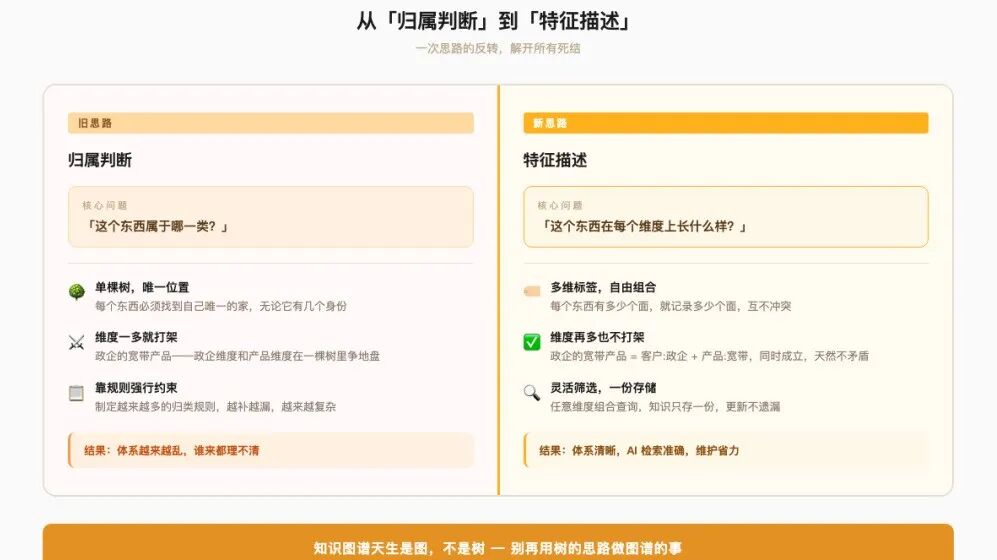
我卡了很久才意识到:问题根本不在”分得够不够细”,问题在分类的”维度”本身就错了。
二、为什么会死结:你把两个维度塞进了一棵树
把上面那个例子拆开看:
- “政企产品”——这是按客户类型分的(政企客户 / 家庭客户 / 个人客户)
- “宽带产品”——这是按产品形态分的(宽带 / 移动 / 语音 / IPTV)
「客户类型」和「产品形态」,是两个互相独立的维度。
一个产品,它在”客户维度”上有个位置,在”产品维度”上也有个位置,这两个位置是同时成立、互不冲突的。”面向政企的宽带”——它在客户维度是”政企”,在产品维度是”宽带”,本来一点都不矛盾。
矛盾是怎么来的?是因为你建了一棵树。
树状分类的本质是:每个东西只能挂在一根树枝上,只能有一个位置。可现实里这个产品有两个身份(政企的、宽带的),你却只给它一个位置——于是它必须二选一,于是就死结了。
你把两个维度,硬压进了一个单一维度的树里。这就是病根。

这个问题在知识工程里有个名字,叫多维交叉分类。它不是某个人没想清楚,它是”用树状结构去表达多维事物”时必然产生的结构性矛盾。你再聪明、再细致,只要还在用一棵树,这个结都解不开。
三、正确的解法:不要分类树,要多维标签
解法说出来其实很简单:别让一个东西只有一个位置,让它同时拥有多个维度的标签。
还是那个产品,正确的描述方式不是”它属于哪一类”,而是给它打一组标签:
- 客户维度:政企
- 产品维度:宽带
- 渠道维度:线上 / 线下
- 生命周期维度:在售 / 即将下架
这样一来:
“面向政企的宽带”不再需要二选一了——它就是客户=政企+产品=宽带,两个标签同时成立。
你想看”所有政企产品”,就筛客户=政企;想看”所有宽带”,就筛产品=宽带;两个条件一起筛,就是”政企的宽带”。
这条知识在系统里只存一份,更新一次就行,不会出现”改了 A 类忘了改 B 类”的不一致。
知识图谱本来就该是这样——图谱的”实体-属性”结构,天生适合多维标签。一个实体(产品),挂多个属性(客户类型、产品形态、渠道、生命周期),这才是图谱该有的样子。
“非要给它建一棵唯一归属的分类树”,是在用图谱做关系型分类该做的事,是用错了工具。
四、那”分类”就完全不要了吗?
也不是。这里要讲一个分寸,否则容易从一个极端走到另一个极端。
树状分类不是没用,它适合“天然单维、天然有层级”的东西。比如组织架构(公司-部门-科室)、行政区划(省-市-区),这些本来就是一棵树,用树就对了。
多维标签适合“多维、交叉、需要灵活组合查询”的东西。企业的产品体系、知识体系,绝大多数属于这一类。
判断方法也很简单,给你一个可以直接用的检验动作:
当你定下一套分类,挑几个最”难归类”的条目去套它。如果你发现某个条目”放这也行、放那也行”,或者”哪都不太对”——这不是你没想清楚,这是一个信号:你正在用单维的树,去装多维的东西。
这个”难归类的条目”,不是麻烦,是体系在向你报警。别去硬归它,要回头看是不是维度错了。
五、为什么这件事,比看起来重要
你可能觉得这只是个”分类技巧”。但在知识图谱、RAG 这类项目里,它的影响是底层的。
知识的组织方式,直接决定了上层 AI 的检索效果。如果底层是一棵打满补丁、到处重复、自相矛盾的分类树,那么:
检索时,同一个东西因为存了多份、归类不一致,召回会混乱
知识更新时,一处改动要同步多个地方,时间一长必然出现冲突的知识
冲突、过时的知识被 AI 检索出来,就是幻觉和错误回答的源头之一
一个看似”上层”的 AI 回答质量问题,根子可能在最底层的分类维度上。知识建模这一步看着不起眼、不性感,但它是地基。地基的维度错了,上面盖什么都会歪。
回到我自己。我现在每天还在做这套知识体系,还在和那些”难归类”的条目打交道。
但和半年前不一样的是——现在每当我遇到一个”放哪都不对”的东西,我不再急着替它找个位置了。我会先停下来问一句:
是这个东西难归类,还是我的维度错了?大多数时候,答案是后者。
这是本人「企业 AI 落地观察」系列的知识图谱标签构建方面所想,主页还有更多实战经验,欢迎大家评论互动。
本文由 @是AD 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自 unsplash,基于CC0协议









这个思路其实也适用于个人知识管理——强行给笔记分“工作/生活/学习”的树,不如用“项目/时间/类型”的标签组合。
说白了就是:一个东西有好几个属性,别硬把它塞进一个分类框里,给它打上多个标签就行。
随着大模型普及,知识组织方式会越来越往细粒度、多维度走。标签体系是匹配这个趋势的,但工具链成熟度还不够,很多平台对多标签检索优化有限。
用标签代替树状分类这个方向是对的,但现实中很多团队连维度清理都做不好,直接上标签反而可能制造更多混乱。标签体系对元数据治理的要求其实更高。