
 起点课堂会员权益
起点课堂会员权益AI 时代的 PM 到底在做什么
AI 时代的产品经理正在经历价值重构。传统 PRD 正在被 benchmark 取代,PM 的核心职责转变为定义模型行为标准与设计评估体系。本文将深入剖析 AI 原生组织中 PM 的全新定位,揭示 L1(用户成功)与 L2(Agent 成功)双层结构的本质关联,以及为什么这项能力将成为 PM 在 AI 时代的分水岭。
PRD 已死,benchmark 永生。AI 时代,PM 的价值载体正在迁移:从写需求文档,到定义模型行为标准。
一个让我不安的现象
我在一家做 AI 外贸产品的创业公司当 PM。上个季度,我们接入的上游大模型又出了新版本,OpenAI、Anthropic、Google 还是国内那几家,都一样。新模型上线、接进产品的那天,整个产品团队没什么反应。
会议照开,需求照评,迭代照排。模型从 X 换成 X+1,产品形态一点没变。我们只是把一个更聪明的模型,塞进了一个早就定好的 workflow 里。
那天我意识到,我们公司不是 AI 原生组织,做的也不是 AI 原生产品。说白了,是一家把 AI API 包装成 SaaS 的传统软件公司。
这不是我们一家的毛病。今天绝大多数挂着「AI」招牌的中国创业公司,都是这个状态。而状态背后藏着一个问题,PM 行业还没怎么认真聊过:AI 时代的 PM,到底在做什么?
互联网时代,PM 用数据定义「好」
过去十年,字节式的 PM 方法论是中文互联网最成熟的一套产品体系。
它的核心很简单:用户行为产生数据,数据告诉你什么功能 work、什么不 work。A/B test、留存、DAU、ARPU,这套指标本质上是让用户用脚投票,反推什么叫「好产品」。
它厉害在哪?厉害在把「什么是好」从主观判断变成了客观测量。PM 不用靠经验、直觉、领导的喜好做决定,数据替你做。
但这套方法有三个前提:你得有海量用户产生统计显著的数据;用户行为能被采集、被量化;行为分布还得相对稳定,不能今天 A 明天 B。
这三个前提,AI 产品一个都不满足。
AI 时代,用户体验和模型行为绑在了一起
互联网产品的体验是 UI 决定的。按钮放哪、流程怎么走、文案怎么写,都是 PM 拍板。模型在这套体系里只是后台一个组件,跟数据库、缓存没区别。
AI 原生产品不是这样。一个 AI 销售助手写的邮件好不好,一个代码 Agent 写的代码能不能跑,一个对话产品的回答有没有温度,这些都不是 UI 决定的,是模型每一次输出决定的。
换句话说,用户体验和模型行为耦合了。你没法再像传统 PM 那样,把「用户体验」和「技术实现」拆开谈。在 AI 原生产品里,这两件事就是同一件事。
耦合带来一个直接后果:PM 定义产品价值的「载体」变了。
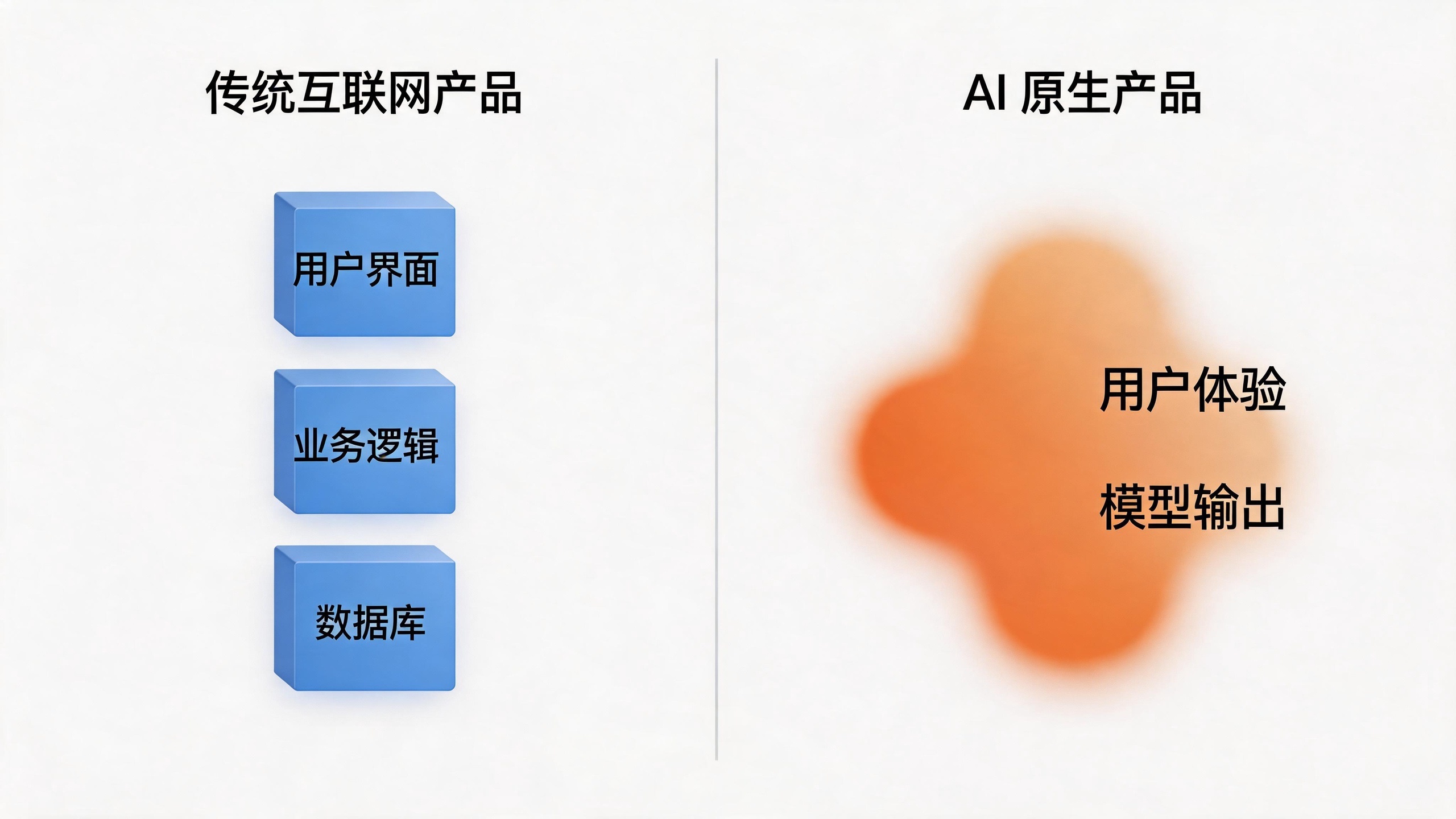
互联网时代,PM 靠 PRD 定义产品。PRD 是写给人看的,给设计师、给工程师、给老板。到了 AI 时代,PM 又靠什么定义产品?
答案是 benchmark
这个词听着像算法工程师的事。中文 AI 圈大部分 PM 把 benchmark 理解成「模型能力测试集」,觉得是研究员该操心的东西。
不对。在 AI 产品的语境里,benchmark 的本质,是把「什么是好产品」从主观判断变成机器能执行的规范。它不是测试集,是 PRD 的代码化形式。
给一个 AI 销售邮件功能写 benchmark,过程其实就是回答几个问题:
- 一封「好邮件」要满足哪些维度?相关性、个性化、说服力、合规性……
- 每个维度怎么打分?5 分长什么样,3 分长什么样?
- 边界情况怎么办?客户是欧洲人和东南亚人,标准一样吗?
- 哪些维度加权,最能预测「客户真的回复了」?
把这些问题答完,产品也就定义完了。benchmark 写完,需求就完成了,剩下的是工程问题。
所以 Anthropic 的 CPO Mike Krieger 在一次访谈里说:
如果你来 Anthropic 面试 PM,我们想看你怎么思考 eval。这种人才不够多。
OpenAI 的 CPO Kevin Weil 说得更直接:
写 eval 会成为 PM 的核心技能之一。
benchmark 的两层结构
真正让我兴奋的,其实不是「PM 要会写 eval」,那只是表层。
更深的一点是:好的 AI benchmark 从来不是一个东西,是两层东西。
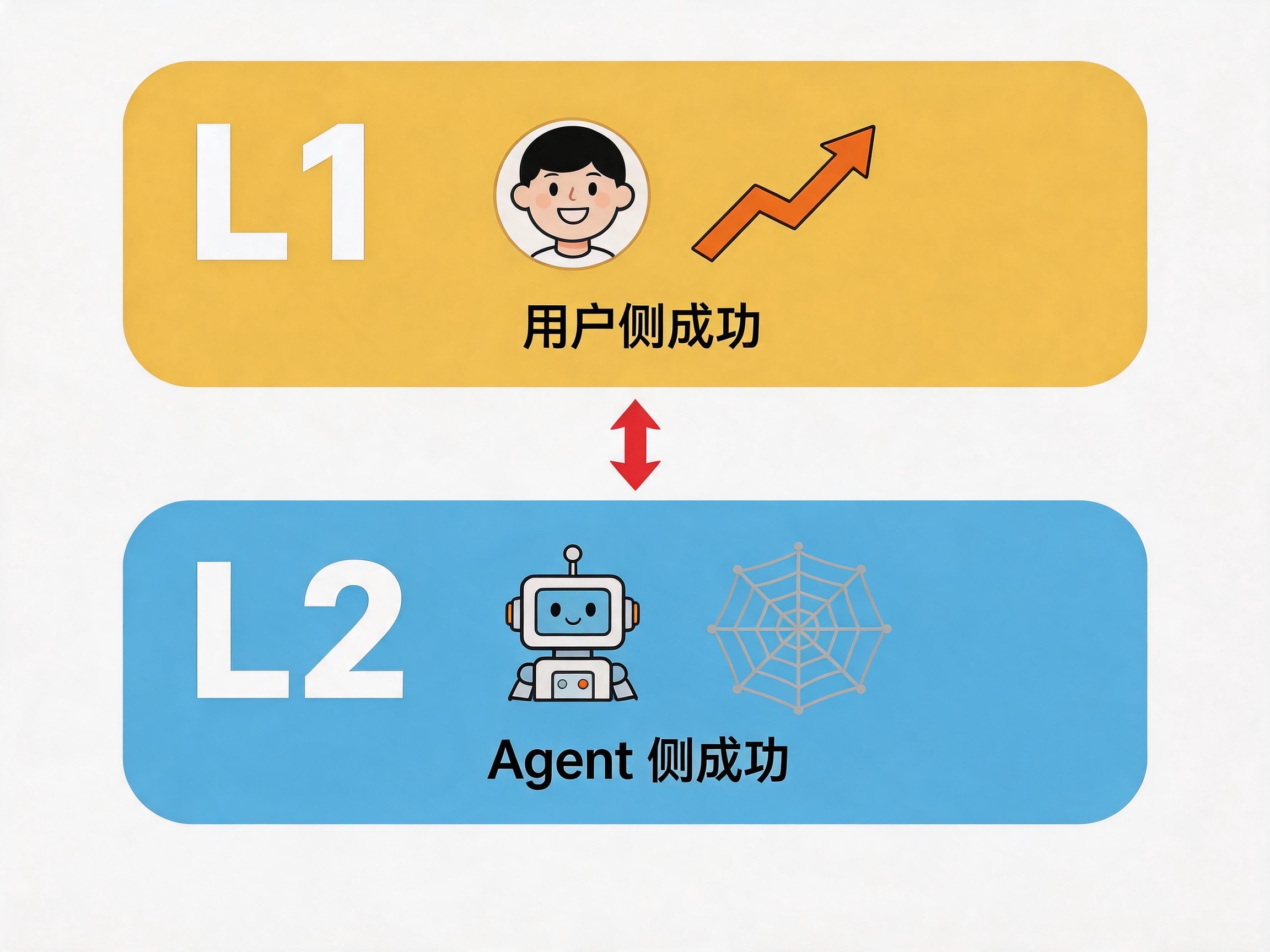
第一层,我叫它 L1,用户侧的成功。客户回复了、成交了、续费了、推荐给朋友了,这是产品在用户身上产生的最终效果。
第二层,L2,Agent 侧的成功。模型输出符合规范、信息完整、语气合适、没有幻觉,这是 Agent 在技术执行层面「做对了事」。
这两层经常错位,而且错位的方向很反直觉。
举个例子。一封 AI 生成的销售邮件,L2 维度可能全是满分,相关性 5 分、合规 5 分、语气 5 分,结果客户没回。也可能另一封 L2 有点瑕疵,却因为某句话戳中了客户的真实痛点,客户回了。
L2 是过程指标,L1 是结果指标。L2 近端、可拆解、可观测;L1 远端、整体、跨场景。再说白一点:L2 问的是「产品有没有正确地做事」,L1 问的是「产品有没有做正确的事」。
这个区别,德鲁克 60 年前就讲过。到了 AI 时代,它终于有了一个具体、可执行的载体,就是 benchmark 的双层结构。
这个翻译,为什么只有 PM 能做
你诚实地想一下:L1 和 L2 之间的翻译,该谁来做?有四个候选人。
算法工程师擅长 L2,他们本来就在写模型;但结构性地不擅长 L1,他们的训练里没有「深度理解用户、业务、场景」这一块。让算法定义 benchmark,结果就是只有 L2 没有 L1:技术指标很漂亮,用户不买单。不少大模型公司 benchmark 跑得飞高、产品却扑街,原因就在这儿。
用户研究员擅长 L1,他们就在研究用户;但不懂模型怎么工作,没法把「用户的成功」拆到 Agent 的可观测行为上。让用研定义 benchmark,就是只有 L1 没有 L2:标准说清了想要什么,工程不知道怎么落地。
领域专家擅长定义自己领域里的 L1,但通常摸不准 AI 的能力边界。要么定出模型根本做不到的标准,要么错过模型其实能做到的更高标准。
PM 不一样。这个角色从诞生到现在,唯一没变过的本质就是:理解用户,理解技术,翻译两者。
互联网时代,PM 把「用户需求」翻译成「产品功能」,交给工程师实现。AI 时代,PM 把「用户的成功」(L1)翻译成「Agent 的成功」(L2),交给算法和工程实现。
这件翻译工作,在结构上只有 PM 的训练能接住。算法从技术往上看够不到 L1,用研从用户往下看够不到 L2,领域专家从业务横着看两头都够不到。PM 是唯一一个被训练成「同时看两层」的角色。
所以「AI PM 必须懂 eval」这句话,不是一次技能升级。它是 PM 这个角色的本质,在 AI 时代终于显形。

PM 行业正在悄悄分化
如果你认同上面这套推导,会得出一个不太舒服的结论:PM 这个职业正在分裂成两种,而且差距每个月都在拉大。
一种 PM,我叫它 Type A,还停在「提需求、跟进度、看数据」的老范式里。AI 在他眼里是个黑箱,他写一句「AI 要友好礼貌」,剩下的丢给算法。这种 PM 在 AI 包皮产品(SaaS 加个 AI 助手)里还能混,可到了真正的 AI 原生组织,会被边缘化。
另一种 PM,Type B,核心工作就是定义模型行为标准、设计 eval 体系。他不只是和模型打交道,他用模型的语言定义产品:能写 prompt,能设计 rubric,能用数据驱动算法决策。在 AI 原生组织里,这种人才是真正的产品负责人。
OpenAI 的 CPO 在访谈里下过一个判断:「这两层 PM 的差距每个月都在扩大。AI 公司需要 Type B,他们养不起靠 vibes 出活的人。」
我把这话翻译一下:再过 5 年,不懂 eval 的 PM 会像今天不懂 SQL 的 PM。还能找到工作,但已经不在主战场了。

你想做哪种 PM
我写这篇,不是为了给「AI PM」这个标签镀金。
老实说,我对这个标签本身没什么感情。我在意的是一件更具体的事:当你脑子里能把一个 AI 产品的好坏,清清楚楚拆成 L1 和 L2 两层,再用代码化的方式定义出来,你才算真正进了 AI 原生产品的设计语境。
不然,你做的还是 SaaS,只是塞了个模型进去。
我自己也才走到这条路的入口。在外贸公司每天做的 ToB Agent eval,硕士论文要做的中文工具调用 benchmark,业余写的 galgame skill,外人看是三件事,本质是同一件:把模糊的判断标准,变成可执行的指令和可衡量的指标。
这是 AI 时代 PM 真正的内功。
所以这篇不是答案,是一个邀请。你写过完整的 eval 吗?你能把自己产品的「好」拆成 L1 和 L2 吗?你的下一份工作,想做 Type A 还是 Type B?
如果你也在想这些,欢迎来聊。
本文由 @孙鑫 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自作者提供









L1在B端销售场景里,客户是否回复真的能完全归因到邮件质量吗?可能样本量、时机、产品本身都有影响,该如何剥离?
不能,这是复杂系统决定的,需要做比较多的消融实验;然后看不同内容的数据表现
传统PRD被benchmark取代,核心是定义模型行为标准。先点出AI产品用户体验与模型行为耦合,再提出L1(用户成功)与L2(Agent成功)双层结构,最后落到PM的翻译能力是分水岭。读下来对“AI原生”有了更具体的判断标准。