
 起点课堂会员权益
起点课堂会员权益降本增效的终极悖论:为什么越聪明的 AI 越容易背叛公司?
这是一次针对企业知识库场景的 RAG 方案横评总结。我们在测试了十几个不同方案后发现了一个反直觉的现象:决定系统可靠性的关键,往往不是模型语言表达有多流畅,而是它在拿到正确资料后能否保持克制、严格服从知识库而不擅自发挥;对于严肃的企业级业务而言,这种“严谨的服从性”远比“聪明的创造力”更具商业信任价值。

一、 一次横评:同一套题,不同的回答
最近我们做了一次 RAG 方案横评,起因其实很简单。企业知识库已经上线运行了一段时间,团队一直有个问题没有明确答案:现在使用的 RAG 方案,到底是不是当前业务场景下相对合适的选择?市面上的 RAG 产品和方案越来越多,每家都在强调召回率、准确率和效果提升,但真正落到企业知识库场景里,情况往往没有宣传材料里那么简单。
于是我们决定做一次横评。测试对象是十几个不同的 RAG 方案,使用同一份知识库、同一批测试问题、同一套评估标准。原本以为最终会得到一张排名表。但真正跑完之后,我们发现了一件更值得讨论的事情:很多错误,并不是因为系统没找到答案,而是在找到答案之后发生的。而这个现象,也彻底改变了我们后来评估 RAG 方案的方式。
为了让测试结果具有可比性,我们尽量控制变量。所有方案使用同一份企业知识库,内容来自真实业务场景,经过脱敏处理,主要覆盖三类内容:FAQ 类问题、规则条款类内容、产品说明类内容。
问题集也保持统一,主要覆盖三种常见场景:直接查询类问题、规则判断类问题、知识冲突类问题。同时统一输出要求,避免因为回答篇幅、排版风格或者格式差异影响判断。
我们并不打算评出一个“冠军模型”。相比最终排名,我们更关心另一件事:面对同一个问题,不同模型到底会做出什么样的选择。因为对于企业知识库来说,真正影响系统可靠性的,往往不是模型有多会说,而是它依据什么说。
二、 一个反直觉的现象
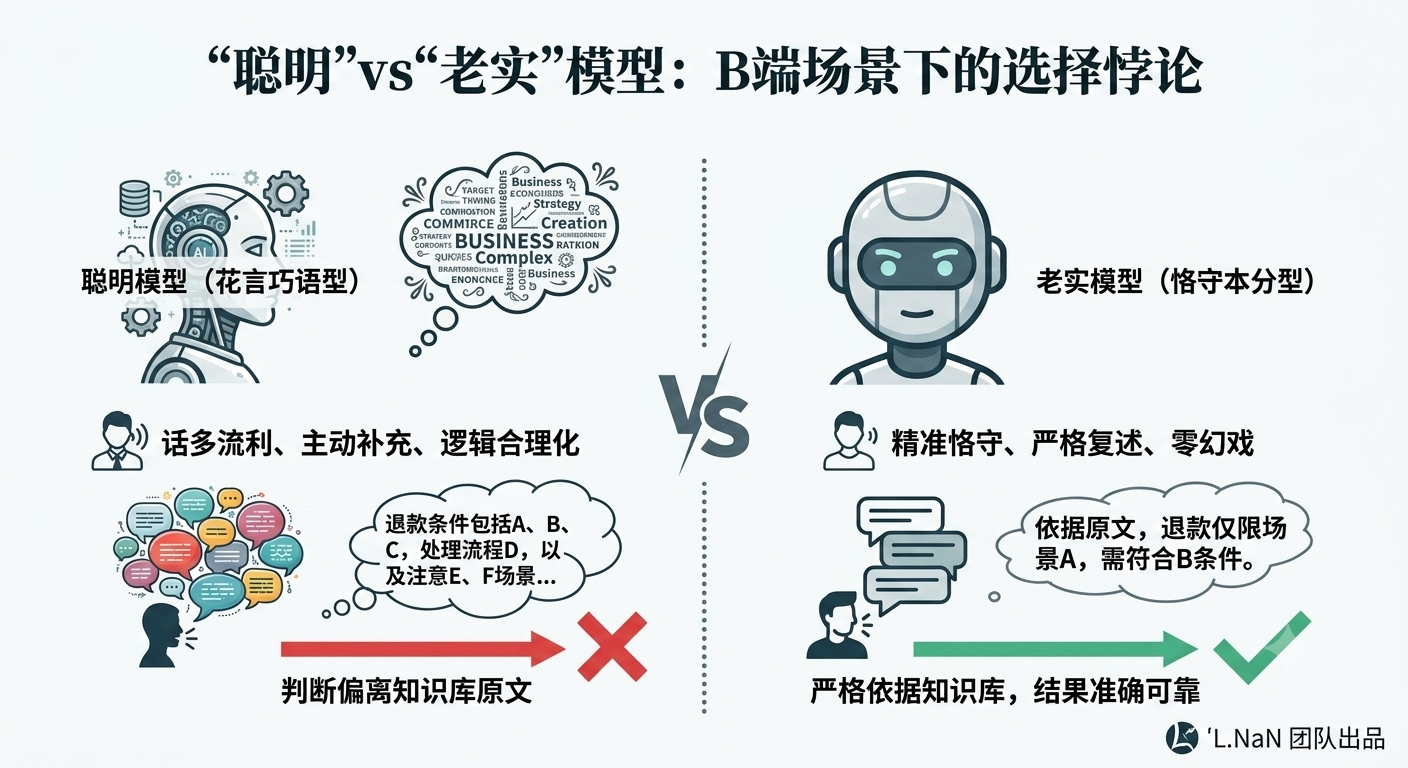
测试开始不久,我们就注意到一个有些反直觉的现象:表达能力强,并不等于 RAG 效果好。有些模型的回答非常流畅。不仅能回答问题,还会主动补充背景知识、业务逻辑和相关说明。从阅读体验来看,几乎挑不出毛病。
但当我们把这些回答和知识库原文逐句对照时,却发现其中有不少内容根本不来自知识库。它们是模型自己补充进去的。而另一些模型恰恰相反。回答往往只有几句话,甚至显得有些“笨”。没有额外解释,没有延伸发挥。但几乎每一句话都能在知识库中找到对应依据。
测试过程中有一个比较典型的案例。这是一个退款规则相关的问题,涉及明确的时间限制和适用条件。其中一个模型给出了很长一段回答。它不仅解释了退款条件,还补充了退款原因、处理流程以及一些常见场景。整个回答读起来逻辑完整,甚至比知识库原文更容易理解。但问题在于,它最终给出的判断与知识库中的规定并不一致。另一个模型只回答了一句话,甚至看起来有些简单,但这句话与知识库原文几乎完全一致。
如果从用户体验角度看,前者显然更像一个“聪明模型”。但如果从企业知识库的角度看,后者反而更可靠。这让我们意识到:模型说得是否流畅,和它是否严格依据知识库回答,其实是两件完全不同的事情。
三、 为什么准确率解释不了这些差异
接下来,我们统计了所有模型的准确率。问题又出现了,有几组模型的最终得分非常接近。如果只看排行榜,它们几乎属于同一个水平。
但当我们逐条分析回答内容时,却发现这些模型的行为模式完全不同。有些模型属于“偶尔答对”。当问题刚好落在它熟悉的范围内时,表现不错;但换一种问法、增加一点干扰信息之后,回答就容易跑偏。另一些模型则属于“稳定答对”。即使用户换了表达方式,它们的回答依然能够落回知识库规定的范围内。从统计结果上看,两者可能只差几个百分点。但放到真实业务场景里,这种差异会被无限放大。
一个稳定答对的模型,可以比较放心地处理大量真实用户问题。而一个偶尔答对的模型,则意味着你永远不知道它下一次会不会自信地编出一个答案。也是从这里开始,我们逐渐意识到:准确率这个指标并没有错,但它解释不了问题。它只能告诉你结果是什么,却无法告诉你结果为什么会出现。而后者,恰恰才是评估 RAG 系统时更重要的部分。
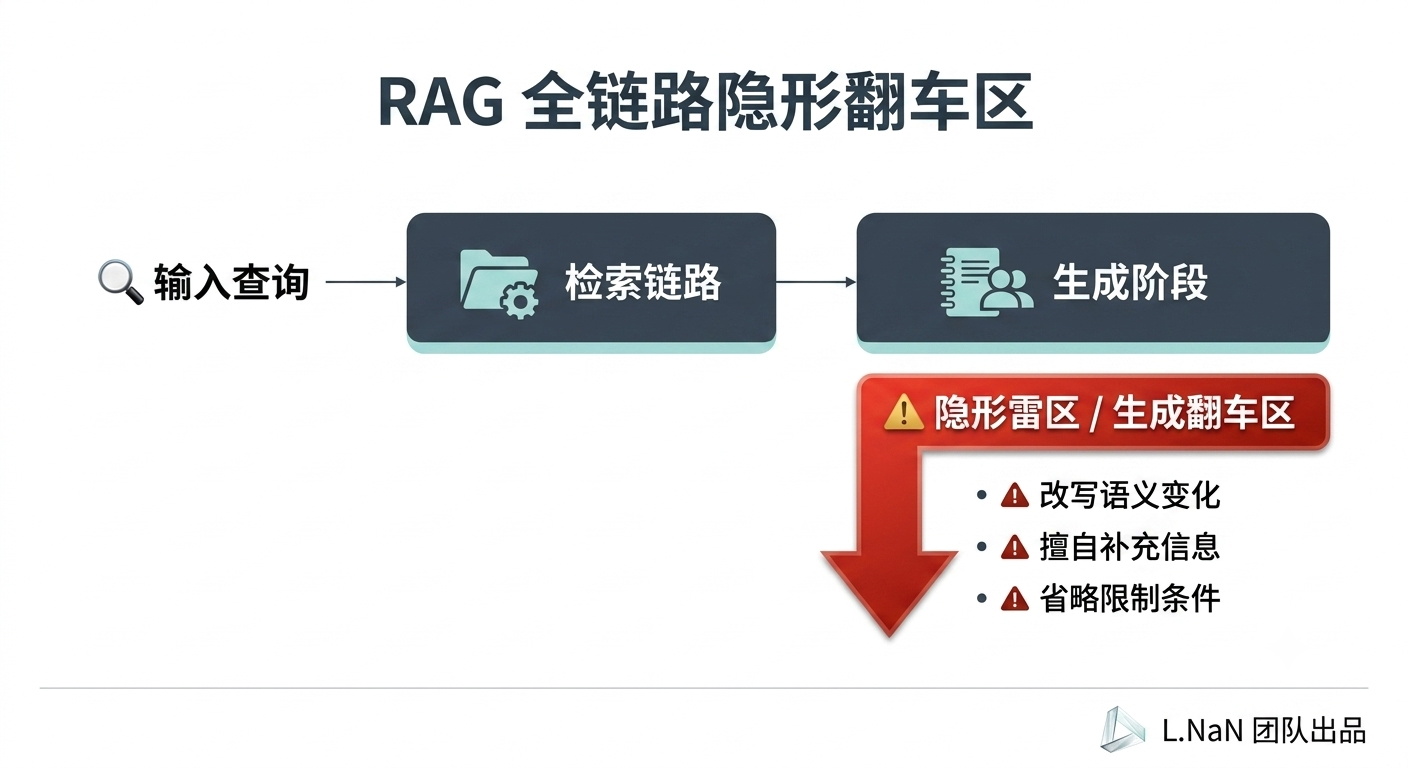
四、 我们把所有错误归成了三类
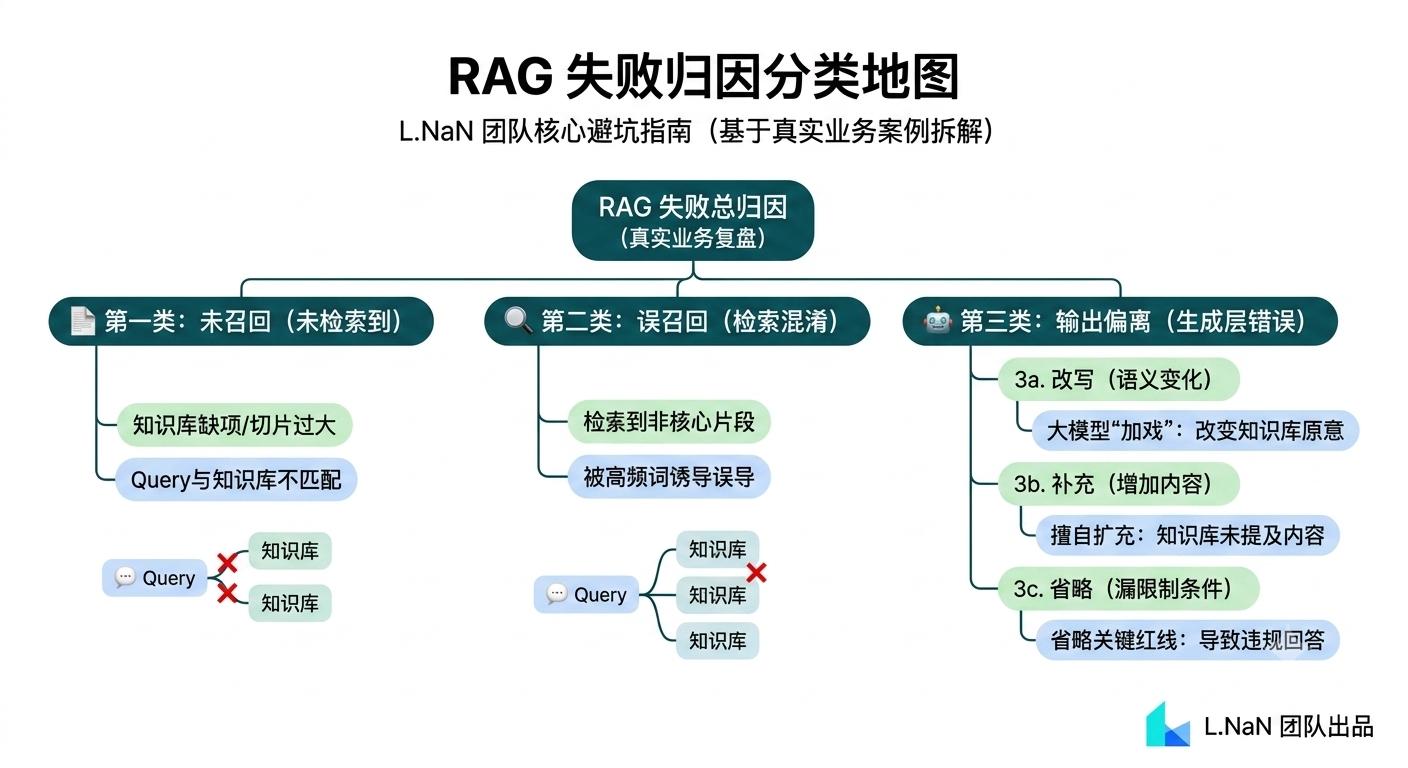
为了弄清楚问题究竟出在哪里,我们重新分析了所有错误案例。最后发现,大多数问题都可以归入三种典型模式。第一类是未召回。知识库里明明有答案,但检索阶段没有把相关内容找出来。模型实际上是在缺少上下文的情况下回答问题。这种情况通常与 Embedding 模型、文档切分策略或者 Rerank 环节有关,本质上属于检索链路问题。
第二类是误召回。系统找到了内容,但找错了内容。这种情况在企业知识库里并不少见。例如多个产品版本之间规则高度相似,但细节不同。或者 FAQ 库中存在大量长得很像的问题。比如“退款多久到账?”与“退货多久到账?”,两个问题只差一个字,但对应答案可能完全不同。如果检索环节把两者混淆,后续回答自然会出错。
第三类是正确召回,但输出偏离。这是整个测试过程中最值得关注的一类问题。因为检索链路没有出错,正确文档已经进入上下文,模型实际上已经看到了正确答案。但最终输出依然与知识库内容不一致。
这类问题往往有几种表现形式,一是改写,模型对知识库内容进行了重新表述,但改写过程中发生了语义变化。二是补充,模型主动加入知识库中没有出现的信息。三是省略,模型忽略了原文中的限制条件、适用范围或者特殊前提。例如知识库明确写着:“仅限首次购买用户适用。”模型在回答时却只保留了优惠政策本身,没有保留适用条件。
这样得到的回答看起来没错,但实际上已经偏离了原文含义。相比前两类问题,这类问题更加隐蔽。因为从系统链路上看,一切都正常。真正出现偏差的,是生成阶段。而这也是本次横评中,不同模型差异最大的地方。
五、 真正拉开差距的,不是检索
分析完所有案例后,我们发现一个有意思的现象。很多模型在检索阶段的表现其实没有特别大的差距。大家都能找到相当一部分正确内容。真正拉开差距的,是模型拿到正确资料之后会怎么处理。有些模型表现得非常克制,如果知识库写了一句话,它们大概率围绕这句话回答。如果知识库没有提到某个信息,它们通常不会主动补充,更像是在引用知识库。
而另一些模型则倾向于重新组织内容。它们会先理解知识库内容,再用自己的方式重新表达。这种能力在很多场景下是优点。但放到企业知识库场景里,却未必如此。因为重新组织意味着重新解释。重新解释就意味着存在偏离原文的可能。
我们专门设计过一个冲突场景。知识库中的表述是典型的规则条款风格,而模型自身更习惯使用自然语言解释问题,结果出现了明显分化。一部分模型选择遵循知识库。即使表达显得有些生硬,也尽量保留原文结构和关键措辞。另一部分模型则会先“翻译”知识库内容,再输出给用户。
问题往往就出现在这个翻译过程中。尤其是一些限制条件、适用范围或者特殊前提,很容易被弱化甚至遗漏。同一个问题,第一个模型更像是在复述知识库,第二个模型更像是在理解后重新讲述。前者不一定讨喜,后者也不一定错误。但在企业知识库场景里,两者带来的风险完全不同。
测试做到这里,我们开始重新思考一个问题:那些表现最稳定的模型,到底稳在哪里?最初我们以为答案会是推理能力更强、参数规模更大或者语言能力更优秀。但最终看到的数据并不支持这些猜测。相反,所有表现稳定的模型几乎都有一个共同特点:它们愿意严格遵循知识库。当知识库内容和模型自身表达习惯发生冲突时,它们更倾向于选择知识库。
而表现不稳定的模型,则更容易选择自己的表达习惯。这时候,一个有意思的现象出现了。语言能力越强的模型,往往越擅长“合理化”。它会把自己补充的内容与知识库内容自然融合在一起。普通用户很难看出来哪些内容来自知识库,哪些内容来自模型自身。从体验角度看,这是一种能力。但从企业知识库角度看,这可能是一种风险。
所以我们后来得出了一个有些反直觉的结论:稳定性不是能力问题,而是服从性问题。决定一个 RAG 系统是否可靠的,不一定是模型有多聪明。而是当正确答案已经摆在面前时,它是否愿意严格按照这份答案来回答。
六、 后来我们不再只看分数
随着测试深入,我们调整了整个评估框架。过去使用的 Accuracy 指标,把所有错误都统计为一次“答错”。但实际上,未召回导致的错误、误召回导致的错误、正确召回却输出偏离导致的错误,完全不是同一种问题。对应的优化方式也完全不同。因此后来我们增加了三个独立维度:第一,是否成功召回正确内容;第二,回答是否严格依据召回内容生成;第三,在知识库内容和模型表达习惯发生冲突时,模型是否保持一致行为。从这个角度看,我们关注的不再只是结果,而是行为模式。对于一个需要长期在线运行的企业知识库系统来说,行为模式往往比最终得分更有参考价值。因为团队最终面对的不是一次测试,而是未来成千上万次真实用户提问。
基于这次测试经验,我们认为选型时至少应该关注以下几点:

这次横评结束后,我们最大的收获并不是找到了一份排名,而是换了一种看待 RAG 的方式。以前我们关注的是模型有多聪明,现在我们更关注的是:当正确答案已经摆在面前时,它能不能忍住不去加工它。
对于企业知识库来说,这种克制有时候比聪明更重要。因为用户需要的不是一个擅长创作的模型,而是一个值得信任的答案。
本文由 @L.NaN 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自作者提供









如果知识库本身写得不够清晰或存在矛盾,模型严格服从反而会放大问题。这种情况下,是优先提升知识库质量,还是允许模型做一些合理的冲突消解?
这就属于典型的垃圾进,垃圾出了。我会坚决优先改知识库,因为一旦放开限制让模型自己去消冲突,它就会开始胡说八道了,而且包装得贼合逻辑,更难查出来。我认为在企业级业务里,宁可让它复述一段说不清的原文,也绝不能让它擅自脑补
非常认同“正确召回后输出偏离”这个隐蔽问题。之前做客服知识库时就发现,模型改写的优惠条件经常漏掉“仅限新用户”这类限制。这种风险在金融、医疗场景尤其致命。
金融医疗场景要是漏掉个“仅限”或者“特殊情况除外”,法务和合规真能直接提刀过来哈哈。模型最可怕的地方就在于它越聪明越会装,把漏掉限制条件的错答案写得跟真的一样。我现在选型,宁可要个老老实实复述的笨蛋模型,也不敢要乱改写的了