
 起点课堂会员权益
起点课堂会员权益当AI开始‘一本正经地胡说’:如何用数据工程给大模型划边界?
大模型落地医疗、法律等零容忍行业,最致命的是“不懂装懂”的伪专业幻觉。作为一线AI训练师,我发现堆算力根本消不掉幻觉。本文直接从工位视角出发,拆解大模型高频翻车的三种形态,并亮出死磕数万条SFT数据总结出的管控闭环,顺带复盘RAG与Agent的真实硬伤。垂直AI的底层壁垒从来不是堆知识量,而是弯腰死磕Badcase熬出来的精准“边界感”。

一、严肃领域容不下“一本正经的胡说”
很多人第一次接触大模型时,都会被它惊艳的表达能力所震撼。它可以写代码、整理资料、分析复杂问题,甚至能够完美模拟行业专家的专业口吻。这似乎给部分产品经理带来了一种错觉:既然模型已经吞下了海量的通用知识,进入垂直领域无非是把医疗指南或法律条文当成新数据喂给它,这能有多难?
只有带团队参与过模型训练和评测的人才会明白,深水区的规则完全不同。大模型落地高风险行业遇到的最大瓶颈,从来不是“它不知道”,而是“它不知道自己不知道”。
两年前我刚入行做AI训练师时,对“幻觉”的理解还停留在非黑即白的阶段,无非是模型在胡说八道。比如编造一个不存在的超链接、生成一篇子虚乌有的学术论文,或者是凭空捏造一个历史事件。这种错误在聊天娱乐或者文案场景里最多只是影响用户体验,并不会产生灾难性的后果。
但当真正涉足医疗和法律大模型的评测时,我才发现最危险的并不是那些一眼假的粗劣错误,而是大模型给出了一个听起来无懈可击,但在专业逻辑上完全不可靠的答案。
比如在医疗场景里,我看过一条关于“感冒能不能同时吃两种退烧药”的评测数据。模型表现得极其惊艳,甩出了一堆医学词汇,流畅地解释了成分和作用,最后还贴心地提醒用户“注意剂量”。在传统的语义评测里,这波回答绝对能拿满分。但如果让临床医生来看,这就是在草菅人命,药物联用必须死卡患者的年龄、基础疾病和肝肾功能,一个看似四平八稳的通用回答,极有可能误导患者吃出大问题。
在法律数据里这种坑同样高发。有用户来咨询“公司没签合同,劳动仲裁是不是包赢?”大模型能把劳动合同法倒背如流,给你把企业的违法成本算得明明白白。可真正跑过司法实践的人都知道,能不能赢不仅看那一纸法条,更取决于证据链卡得死不死、当地法院的判例倾向、甚至是事实劳动认定的各种抠细节。这种顺滑的“伪专业”,往往比直接报错更具欺骗性。
因此,严肃领域面临的本质问题,绝不是模型有没有知识,而是模型能不能理解“在什么边界下这些知识不能直接使用”。传统互联网产品习惯了“先上线,再通过用户反馈不断迭代”的碎步小跑模式。推荐算法推错了一首歌,智能客服答非所问了一次,企业承担的试错成本极低。但医疗和法律是容错率为零的赛道,用户是在拿着AI的回答去和自己的身体、财产做真实对赌。这正是大模型被卡住脖子的地方:当聊天体验的“幻觉”变成了高风险领域的“可靠性缺陷”,原有的产品思维必须彻底重建。
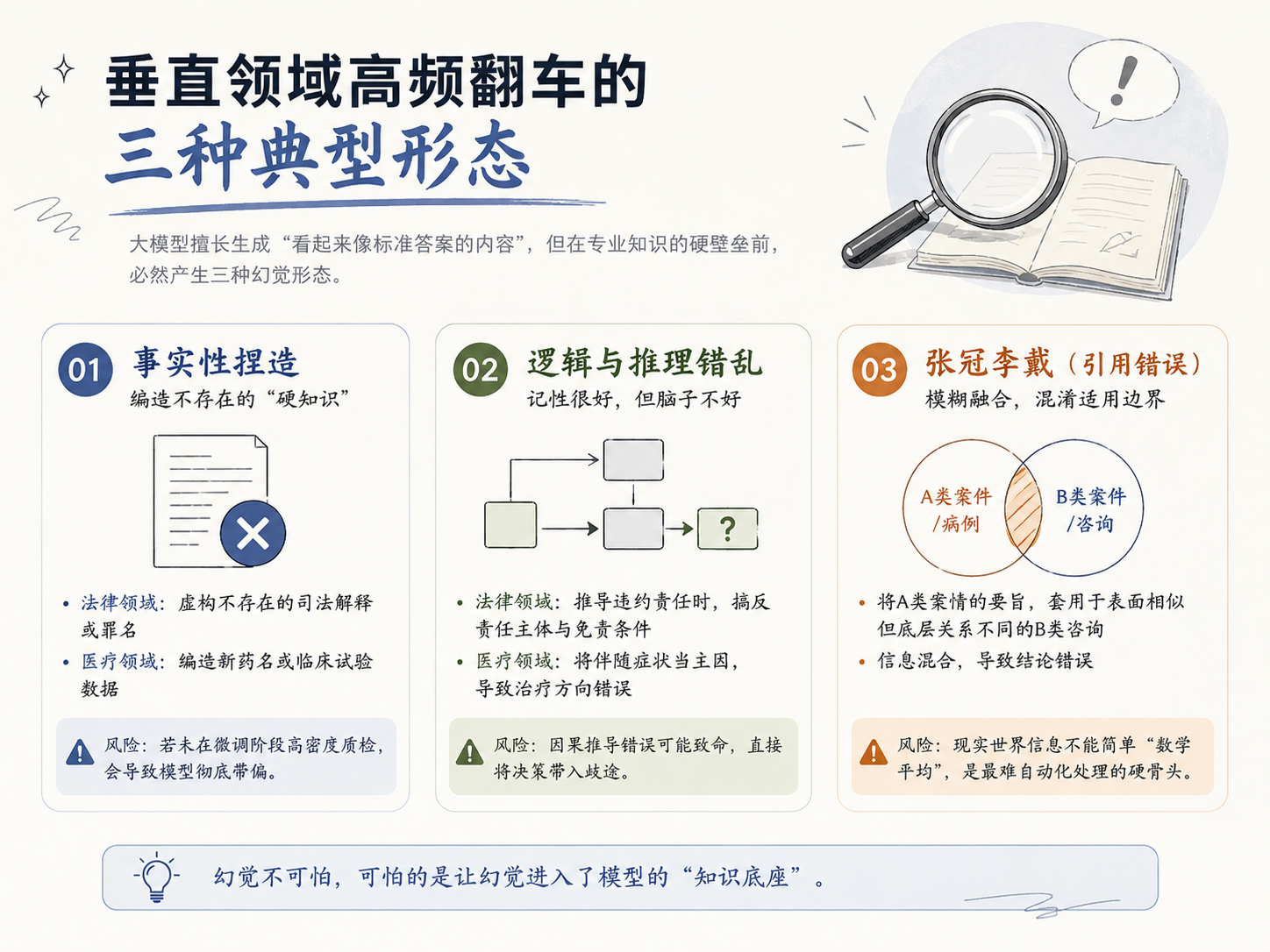
二、垂直领域高频翻车的三种典型形态
在日常的 SFT数据质检工作中,我们不能把幻觉当成一个虚无缥缈的技术缺陷去挂在嘴边,而是必须像医生诊断疾病一样,将其进行精细化的分类。从大模型的底层逻辑来看,它本质上是根据上下文预测下一个Token出现的概率。它天生擅长生成“看起来像标准答案的内容”,但这种概率预测的机制,也决定了它在面对专业知识的硬壁垒时,必然会产生以下三种难以规避的典型幻觉形态:
- 大家最熟的“事实性捏造”。在日常的SFT数据质检里,这种错误最容易把人血压看高。比如法律模型,它能言之凿凿地给你引用一条根本不存在的最高法司法解释,或者凭空发明一个听起来特别唬人、但法典里根本查无此项的罪名。到了医疗模型里,就变成闭眼编造一个新型药名或者临床试验数据。这类错误如果在微调阶段没有进行高密度的专业双盲交叉质检,一旦放任它们混进训练集,模型基本上就彻底带偏了。
- 更险的“逻辑与推理错乱”。这属于“大模型的记性很好,但脑子不好”的典型表现。模型把所有的硬知识都背下来了,却在因果推导的节点上开始闭眼翻车。比如审查一份复杂的商事合同,它能把所有的排他性条款全部揪出来,但一到推导违约责任时,硬生生把责任主体和免责条件给搞反了,整份法律意见书结论前后打架。这种逻辑倒装挪到医疗的临床路径推理里更是要命,它可能会把某种疾病的伴随症状错当成了主因,直接把治疗方向带进沟里。
- 最后是让我们头疼的“张冠李戴”,也就是引用错误。这时候大模型引以为傲的“泛化能力”,反而成了最大的副作用。模型在吞下了几万个判例或病例后,在生成答案时特别喜欢搞“模糊融合”。结果就是,它把A类案情下的裁判要旨,硬套在了表面相似但底层法律关系完全不同的B类咨询上。在严肃领域,现实世界的信息是绝对不能做简单数学平均的。这种把数据搅在一起的“混合幻觉”,也是自动化脚本最难跑通、最需要人工死磕的硬骨头。
三、怎么在几万条 SFT 数据里防死幻觉?聊聊我的一线管控闭环
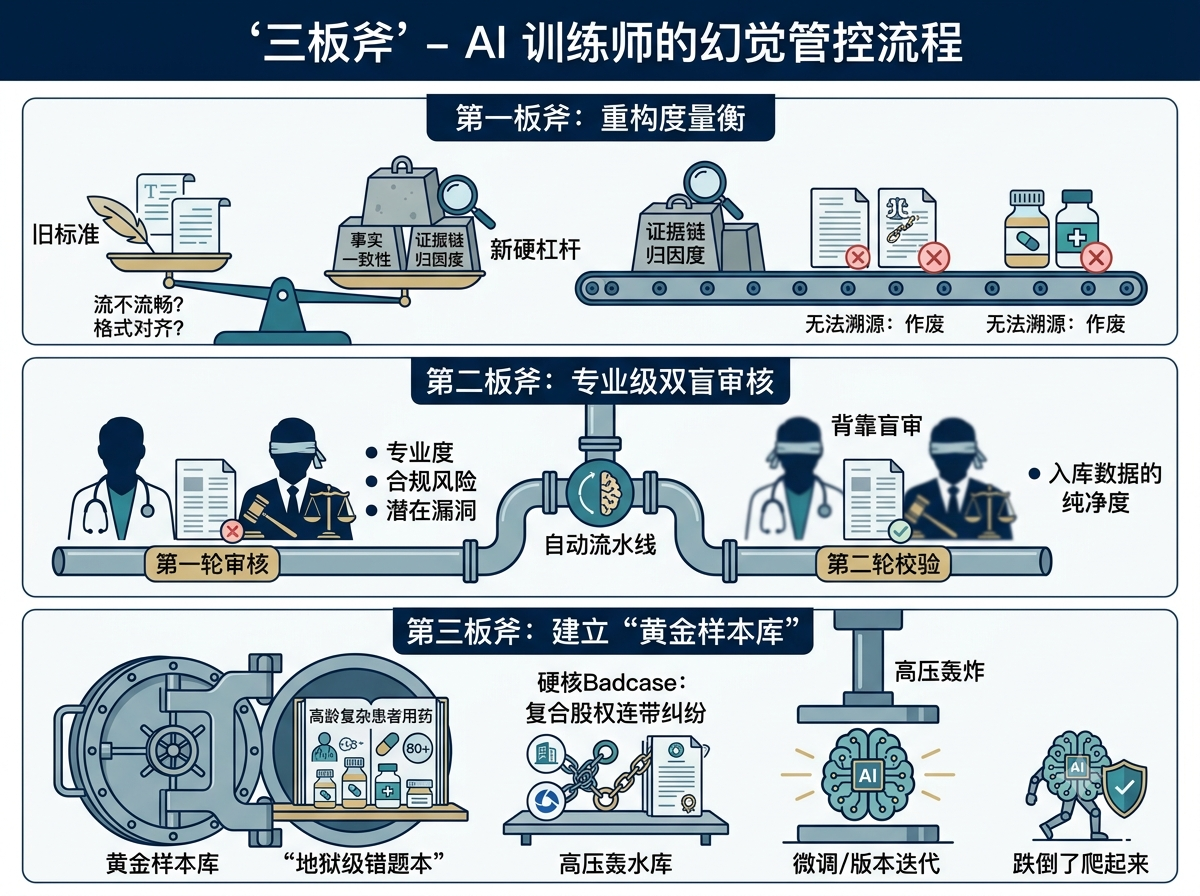
这两年的工作经验让我明白,指望通过单纯增加模型参数或扩大预训练数据集来自动消除幻觉,无异于缘木求鱼。要在一个有着几万条SFT训练数据的垂直项目中把幻觉率降下来,作为AI训练师,必须在数据工程的工位上生生熬出几套硬核的管控流程。我们目前在团队内部落地并跑通的方法,总结起来就是“防瞎话”的三板斧。
首先是重构我们的度量衡,把过去那种宽泛的评测标准全部推倒。过去判断模型好不好,大家主要看语言流不流畅、格式对齐没对齐、或者语义是不是相似。但进入深水区后,这些花架子根本不管用,我们团队直接引入了“事实一致性”和“证据链归因度”两条硬杠杆。在评估模型的输出时,我们会用脚本强行抽检它提到的每一条法条、每一个药名。每一步推理必须做到百分之百的溯源,只要有一处出现无法归因的模糊表述,整条数据在表格里直接点“作废”。
有了标准之后,紧接着要解决的是由谁来判卷的问题,我们搭建了一套专业级双盲审核。医疗和法律的对错标准具有极高的主观专业壁垒,普通的数据标注员无法把关。当时我们团队把真正的医生和律师拉进多维表格的协同流程里,设计了背靠背的盲审环节。第一轮专家只负责对模型的专业度、合规风险和潜在漏洞进行挑错、打标签;第二轮专家则在不看前人结论的前提下进行二次校验。通过这样的自动化流水线,由于专家个人经验差异带来的标准抖动被降到了最低,用严密的审核闭环来给入库数据的纯净度当“守门员”。
而最后,也是最核武器的一招,是建立专门用来折磨大模型的“黄金样本库”。我们在工作中发现,真正决定模型可靠性上限的,往往是那些只占总量一成左右的高难度、长尾、情况复杂的边界案例。比如同时患有三种基础病的高龄患者用药咨询,或者是涉及多层股权代持与连带担保责任的复合法律纠纷。我们把之前项目攒下来的所有硬核Badcase精心标注,编成了黄金样本库。每次模型进行微调或者版本迭代时,先不去测那些简单题,直接用这套“地狱级错题本”去高压轰炸它。只有在这个库里跌倒了还能自己爬起来的模型,我们才敢放心地让它进入到下一个产品环节。
四、RAG 与 Agent:垂直赛道的底牌与硬伤
当把目光从底层的数据标注扩展到整体的产品架构时,目前行业里为了压制幻觉,最推崇的两大主流技术路线就是知识检索增强(RAG)和多步骤任务处理(Agent)。在两年的项目摸爬滚打中,我见证了不同团队对这两项技术从盲目迷信到逐渐清醒的过程。它们确实是好用的技术,但也绝对不是万能的。
首先聊聊最常被用来当做“防盲药方”的RAG架构。以前大模型答题全凭预训练阶段的记忆,就像学生闭卷考试,极其容易因为记忆混乱而产生幻觉。现在接入RAG,相当于在模型旁边放了一个实时翻阅的权威知识库,让它开卷考试。
但这导致很多人忽略了一个事实:RAG的上限取决于检索器的精度与知识库的质量。如果在第一步,系统因为长文本理解偏差,检索出了过期的地方法规或者并不完全对症的治疗指南,大模型在第二步哪怕展现出再完美的推理,也只是在一个完全错误的基石上,高效地生成一堆高质量的废话。
再来看年初被炒得很火的Agent模式。它的核心逻辑是把原来“用户提问,模型一句话直接给答案”的黑盒流程,拆解成可复核的多步骤任务流。
这种模式的真正价值,在于它把高风险的决策链路切碎了,让AI训练师能够精准地监控到模型是在哪一步、因为什么原因产生了幻觉。然而在实战中我们发现,Agent的多步链条往往会带来“错误级联”的副作用。一旦模型在第一步提取关键信息时因为泛化能力抖动,漏掉了一个不起眼的补充协议,这种微小的偏差就会在随后的检索、比对和推理步骤中被层层放大,最终导致输出的结论彻底南辕北辙。因此,工具箱越来越大,并不意味着系统会自动变得可靠,它只是把我们抓幻觉的战场,从单点的提示词优化变成了复杂的分布式链路排查。
五、长尾困境与被污染的“标准答案”
大模型在垂直深水区之所以容易掉链子,从我们AI训练师的底层视角来看,很多幻觉的种子在模型接触到训练代码之前,就已经在数据端被死死地埋下了。现在行业的最大痛点,在于低风险的通用数据满大街都是,而真正能决定严肃AI成败的高价值、长尾行业数据,正处于一种极度匮乏的状态。
我们在构建医疗问答模型时发现,如果训练集里充斥着“感冒有什么症状”这种高频通识数据,模型的表现会极其完美。但这根本没有解决业务的真实痛点。现实中真正会卡死产品上岗资格的,永远是那些发生概率极低、情况错综复杂的长尾场景。
比如一个具有多年哮喘病史的孕妇,在特定的季节性过敏期间出现了偶发性的心悸,应该如何调整当前的用药方案。这种问题在公开数据中极其稀缺。当模型从未真正见识过如此密集的复合变量时,一旦被用户问及,它的泛化本能就会战胜理智,开始用极其顺滑的语调去拼凑一个充满安全隐患的伪答案。
更难的是,垂直赛道的数据本身往往存在着严重的“不一致性”。医学在不断演进,五年前被写进教科书的疗法,今年可能已被明确指出存在毒副作用。法律领域更为具象,法条在修订,司法解释在更新,不同省份的高级法院在面对同一类纠纷时,甚至会给出完全不同的审判口径。
如果我们在准备数据时,没有极度严苛地对这批专业资料进行时效性标注和地域属性过滤,模型在进行概率预测时,就会不可避免地将新老法规、不同地区的审判逻辑进行混乱的语义缝合。这种由于数据源本身互相冲突而导致的“原生幻觉”,单靠算法端的策略几乎是无解的。它对我们训练师提出的要求,已经远远超出了简单的对错判断,而是要求我们必须具备极其深厚的行业背景,去帮模型决定哪些数据该留、哪些数据必须无情地干掉。
未来垂直 AI 的关键壁垒,是模型的“边界感”而非“知识量”
干了两年多AI训练师,我经历了这个行业从最疯狂的参数崇拜,到如今逐渐回归商业本质的冷静期。刚入行的时候,我认为一个优秀模型的勋章应该来自于它能回答多少刁钻的问题、覆盖了多少广阔的业务场景。但每天下班前合上电脑,看着表格里那一堆因为模型“不懂装懂”而引发的触目惊心的Badcase,我的认知也逐渐发生了解构。
在严肃的现实世界里,一个无所不知却偶尔掉链子害人的AI,永远比不上一个虽然知道得有限、但在关键时刻绝对不掉链子的AI。
大模型真正高阶的可靠性,不仅来自于无边无际的知识量,还要有极其精准的“边界感”。一个真正能够落地在法庭或诊室的成熟AI产品,其最高明的设计往往不是它如何妙笔生花地给出结论,而是它在什么时候学会闭嘴。
当面对缺失关键事实的用户描述、超出自身知识库覆盖的时效性问题,或者涉及重大合规风险的底层逻辑时,模型能够极其冷静地提示用户补充关键信息,或者直截了当地说出那句:“这个问题超出了我的处理边界。”
这种“认怂”的智慧,需要我们在训练阶段用成千上万个 Badcase 去高压轰炸,才能把这道安全红线刻进模型的逻辑底层。未来垂直赛道的竞争,大公司的算力优势与参数规模固然能筑起高墙,但在医疗、法律等对错误零容忍的现实行业里,核心壁垒是属于那些愿意弯下腰、把手弄脏,在工位上一条条清洗长尾数据、拆解业务逻辑、死磕Badcase的实战团队。用户最终需要的,从来不是一个永远在抢答、渴望证明自己聪明的 AI 小助手,而是一个在关乎人命与官司的关键抉择时刻,永远不会轻易误导自己的、值得托付的伙伴。
本文由 @L.NaN 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自作者提供









说RAG和Agent不是万能药这点很实在,但把RAG的上限完全归因于检索精度可能有点偏,上下文窗口扩大后模型本身对检索结果的整合能力也是瓶颈,两者得一起看。
确实,检索精度和模型整合能力都得抓,缺哪个都翻车
黄金样本库这个思路确实值得推广,用高难度badcase定向轰炸比盲目堆数据有效得多,相当于给模型划了条清晰的安全红线。
对,黄金样本库就是专门治”不懂装懂”的,比堆数据实在多了