
 起点课堂会员权益
起点课堂会员权益一只橘猫和扫地机,逼我砍掉了 1.2 万条训练数据
喂给AI一张“橘猫与扫地机”的图,它却只盯着地板看,准确率只有62%。这篇复盘不讲大道理,就讲我们怎么亮出底牌,一刀切砍掉1.2 万条写满主观小作文的垃圾数据,并在飞书上死卡一套“空间、面积、主次”的填表规范。最后,数据量减了24%,模型准确率反而飙到了84%。如果你也天天跟AI鸡同鸭讲,进来看看怎么用这套硬办法治好它的“眼神”吧。

大概是半年前的某一天,我坐在工位上盯着屏幕上两行文本,无语了很久。第一行是三个月前标注员写的,描述一张图:“一只可爱的橘猫正看着扫地机器人在木地板上工作,画面温馨。”第二行是同一个场景,我们的多模态模型对着同一张图输出的结果:“图里有高档实木地板,纹理是浅色多层复合板,表面有轻微划痕。”
那张图里确实有猫。一只橘色的、趴在地板上的猫,正偏着头看旁边转来转去的扫地机器人。但在 AI 眼里,那只猫根本不存在,它只看到了地板。这件事让我花了整整两周时间来接受一个事实:我们团队花了三个月、喂了五万条图文数据、烧了几十万的算力,结果训练出来的模型,最擅长的事情是——看地板。

更让我难受的是,这不是个例。我拿我们内部自建的多模态细节理解测试集做了三轮测试,发现模型的视觉主体识别准确率只有62%。也就是说,每三张图里就有一张,AI关注的重点和我们想要它看的完全不沾边。
这篇文章不讲大道理,就讲我们后来怎么把这摊烂账翻过来的。故事的起点,就是那只橘猫和那台扫地机。
一、谁才是主角?人和AI看同一张图,看到的完全不是一回事
先说清楚一个问题:为什么人写的描述是“一只可爱的橘猫”,AI输出的却是“浅色多层复合地板”?大多数人第一反应是——模型太差了,换更大的模型。我们一开始也这么想,但经过反复测试发现,换更大的基座模型、加更多的训练数据,问题照旧。一张图里如果有大面积背景,AI就一定会被带偏,不管模型多大。
后来我们做了个实验,才真正搞明白原因。我们把同一张图给团队里的五个人看,让他们用一句话描述看到了什么。五个人的回答分别是:“一只猫在看扫地机”、“橘猫趴在地板上”、“猫和扫地机器人”、“宠物和智能家居同框”、“猫的好奇心”。没有一个人提到地板,尽管地板占了画面70%的面积。
但当我们把图拆成像素块输入给AI,让它逐区域打分时,结果完全相反。AI给“浅色木纹区域”的注意力权重最高,给“猫的区域”的权重反而很低。原因简单到让人哭笑不得——在 AI 的视觉系统里,面积越大的区域,天然获得越高的注意力分数。地板占了70%,所以地板就是主角。
这件事暴露了一个被大多数团队忽视的认知错位。人类看图,靠的不是像素。人类的大脑具备一套极其强大的“显著性检测”机制。你扫一眼画面,大脑就会自动识别出有生物特征的物体、有运动趋势的区域、和新奇事物产生交互的对象,并且自动赋予它们“主角”身份。你会忽略大面积的地板、墙壁、天空,因为大脑告诉你这些是“背景”,不重要。
AI可没有这套机制。AI看到的是一堆均匀排列的图像块,每个图像块包含RGB数值、边缘梯度、纹理特征。AI不知道猫比地板重要,因为“重要性”这个概念在数学上并不存在。AI只能计算“哪个区域的信息量最大”,而信息量和面积正相关。
这个认知错位,造成了多模态训练中一个系统性的问题:你给AI看一张“猫在看扫地机”的图,你以为你在教它理解动物和机器的互动关系。但实际上,你只是又强化了一次它对“浅色木纹材质”的识别能力。你不是在纠正它,你是在巩固它的错误。
我们后来在其他团队也验证了这个结论。我了解到,他们训练出来的模型,经常把模特穿的衣服描述成“大面积蓝色区域”,把产品本身漏掉。原因是商品图上衣服经常占最大面积。一家做医学影像的团队遇到类似问题:模型对骨骼X光片里的“大面积软组织区域”权重过高,反而忽略了病灶所在的小范围骨密度异常区域。
这不是某一个模型的问题,这是多模态训练中一个结构性的漏洞。而这个漏洞的根源,不在模型架构,不在训练算法,在数据标注那一关。
二、砍掉1.2万条数据那天,我们到底做了什么
找到问题之后,我们团队内部吵了快两周。有人说改模型结构,在注意力层加一个主体检测分支。算了一下,改完模型、重新训练、调参,至少两个月,还不确定效果。有人说用大模型做后处理,模型输出结果之后再过一层语义过滤。试了一下,治标不治本,原生的错误认知还在,后处理只是在堵漏。还有人说得最直白:继续喂数据,数据量上去了,总能覆盖到各种情况。这条建议差点被采纳——因为它听起来最省事。
但抽检数据的结果让我下决心换条路。我们拉了五万条原始图文数据做了一次质量抽检,发现了一个触目惊心的分布:大约30%的数据存在“主体占比低 + 主观抒情多”的双重问题。标注员写“温馨”、“可爱”、“高级”、“令人感动”这些词的频率非常高,但对“画面中主体在什么位置、占多大面积、在做什么、背景是什么”这些关键信息要么一笔带过,要么根本不写。
也就是说,我们拿着大量“跑题”的数据在训练模型,模型自然也就跑题了。我最终拍板做了一件看起来很不靠谱的事——砍数据。不是修,是砍。不是砍几百条,是准备砍上万条。团队里有人直接问我:“做了三个月的标注,你说砍就砍?”我说:“如果不砍,我们还要再多做三个月,然后发现效果还是一样。”

我带着一个实习生,用了一周时间写了一套自动化清洗脚本。核心逻辑极其简单粗暴:脚本读取每一条标注文本,用规则加另一个大模型去做检测。如果文本里包含“温馨”、“可爱”、“美丽”、“好看”、“高级”、“精美”、“漂亮”这类主观形容词,脚本就查一下这条数据里有没有明确写出主体占比或坐标信息。如果两个条件同时满足,有主观词、没有主体占比,这条数据就会被标记为“垃圾数据”,丢进待删除池。
就这样一刀切,我们砍掉了整整 1.2万条数据。砍完那天下午,办公室很安静。五万条变成了三万八千条。标注组长问我:“接下来怎么办?”我说:“剩下的,全部重写。”但同时我做了一个让标注团队差点炸锅的决定,把标注后台那个自由填写的文本框,直接砍掉。
原来的标注界面是这样的:一张图下面一个大文本框,标注员想写什么写什么。这是最常见的标注模式,几乎所有平台都这么用。但正是这个文本框,给了标注员写“小作文”的空间。他们觉得自己写的内容越丰富越好,实际上写的大量都是模型无法理解的主观情绪。
我们改成了强约束的多维结构化表单。表单里只有三个必填项:

三个字段填完之后,系统会自动拼接成一段结构化文本。没有任何形容词,没有任何抒情,没有任何废话。直接作为SFT的黄金数据喂给模型。标注组长当时问我:“你这样搞,标注员觉得没意思,不想干了怎么办?”我说:“告诉她们,她们不需要写作文了。她们现在做的是数据工程师的活,精确描述画面的结构,而不是写一篇小学生看图写话。这比自由文本框有价值得多。”
三、黄金SOP——“空间、面积、主次”
改完标注流程之后,我们做的第一件事就是跑测试。结果出来那天,我把团队拉到会议室,投屏了一个数字:清洗前,视觉主体识别准确率62%;清洗后,84%。数据量减少了24%,但准确率直接涨了22个百分点。这个结果说实话连我自己都有点意外。我原本预期能涨到75%就不错了,84%是一个超出预期的数字。
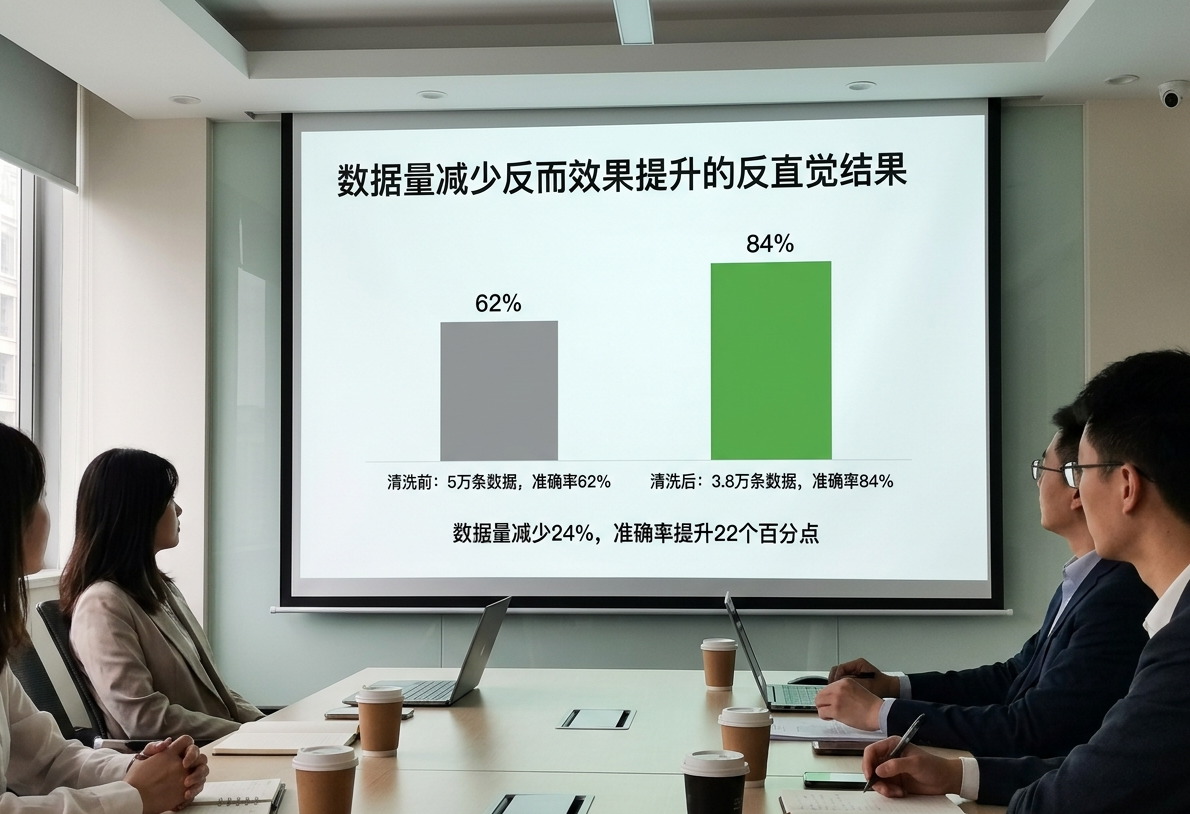
后来我们讨论为什么涨这么多,得出了一个结论:之前那1.2万条垃圾数据不只是“没用”,它们是在系统性地向模型灌输错误的知识。每当模型看到一个有大面积背景的画面,那些数据都在强化“关注大面积区域”的错误倾向。砍掉它们不只是去除了噪音,是移除了一个持续向模型发送错误信号的噪声源。
这让我们提炼出了一套“空间、面积、主次”三要素的方法论。回头复盘,这套方法论之所以有效,核心逻辑其实非常简单。它在数据标注阶段,替AI完成了一件 AI 自己做不到的事情:理解了什么才是“重要”。
首选必须告诉模型,画面里的核心主体在哪个位置、多大范围。模型自己会算注意力权重,但它的算法天生偏向大面积区域。你必须在数据层面手动给它一个“锚点”,告诉它“这一片,才是重点”。
为什么我们强制要求标注员写主体占比?因为面积是模型理解画面的底层变量。模型的视觉模型在处理图像时,本质上是在分析每个图像块的特征分布。一个占画面20%的物体和一个占画面70%的背景,在它的数学世界里天然就不在一个数量级上。你能做的最有效的事情,就是明确告诉模型:“这个20%的区域,优先级高于这个70%的区域。”这是一种显式的注意力重定向。
我们设计“背景噪点声明”这个字段的初衷,是让模型学会“忽略”。大多数训练管线只教模型“关注什么”,但没教过它该“忽略什么”。实际上让模型学会忽略某个信息,比让它学会关注某个信息,对准确率的提升更明显。因为模型天然的倾向是“什么都关注”,它的注意力不会自动聚焦。你必须在数据里告诉它:“那个占画面70%的地板,你不需要关心它的纹理颜色有没有划痕,它是背景。”
这三个要素组合在一起,就是一套完整的“替AI做显著性标注”的方法。不是让它自己去画面里猜重点,而是在数据阶段就把重点标好。
但这套方法不是万能的,我们在这上面翻过一个大跟头。后来团队把同样的框架迁移到“文创文生图”场景,就是那种用AI生成艺术风格的图片、需要大量“氛围感”描述的训练数据。我们按照同样的思路,把所有主观形容词砍掉,把构图要素结构化,然后训练模型。结果产出的图极其死板,毫无艺术感可言。画面的比例是准的,结构是对的,但就是不好看。
后来复盘,问题出在场景差异。识别类任务需要的“客观事实描述”,和生成类任务需要的“氛围感表达”,完全是两回事。在视觉理解场景下,“温馨”、“可爱”这些词是有害的,因为它们模糊了主体。但在创意生成场景下,“温馨”、“赛博朋克”、“蒸汽波”恰恰是最有价值的信息。它们是风格的定义要素,不是干扰项。
所以这套SOP的适用范围其实很明确:所有追求“客观事实准确描述”的多模态理解任务,商品识别、医学影像、图像搜索、视觉问答都适用。但如果场景换了,需要的是创意表达或艺术风格,这套方法反而会帮倒忙。
知道一套方法在什么场景下不能用,和知道它在什么场景下能用,同样重要。
四、Skills 不是概念,是那个你用来保存方法论的文件夹
做到这一步之后,我们团队内部做了一次复盘。复盘会上有人提了一个问题:如果三个月后我们换了一个新项目、新场景、新团队,这套方法论还能不能带过去?这个问题让我想了很久。
我们这套SOP,本质上是一个飞书共享文档,加上嵌入标注系统后台的一个结构化表单模板。它不是一行代码,不是一个Git仓库,不是一套复杂的系统架构。它就是一个文档加一个表单。但就是这个简单到有点寒碜的东西,让我们的视觉准确率从62%涨到了84%。
后来我看到Anthropic团队的一个分享,里面有句话让我印象特别深。他们说:“技能(Skills)的本质就是一个打包了可组合程序性知识的文件夹。”不是什么高大上的平台,不是什么复杂的框架,就是一个文件夹。因为你把程序性知识组织成文件、放进文件夹之后,它能被Git管理、能被压缩传输、能被不同团队复用。工具层越简单,知识的流动性越好。
这个观点和我们团队的实践高度重合。我们的“黄金SOP”可以被复制到任何新的项目里:把飞书文档的链接发过去,把结构化表单模板导入标注后台,改一下场景关键词,就能跑起来。后来我们在电商图文理解和医学影像报告标注两个场景里成功迁移了这个方法,几乎不需要额外磨合。这件事让我重新理解了“技能”这个概念。它不是某种神秘的能力,不是某个复杂的模型,它就是你把做成一件事的方法整理好、封装好、放到别人也能拿到的地方。就这么简单。
但做到不容易。因为大多数人不习惯“整理”这一步。他们习惯的是:问题来了,临时解决,解决完了,下次再来还是重新解决一遍。这就像你电脑桌面上堆满了临时文件,每次找个文档都要翻半天。把它整理成文件夹,放好标签,这一步动作本身不产生价值,但它让后续的所有操作都变得高效。
这也解释了为什么传统AI总是显得“健忘”。每次交互都从头开始,它无法从过去的经验里沉淀任何东西。而把做成功的方法保存成一个“技能”,就是在AI建立一种可积累的记忆——不是记录每一次聊天的内容,而是固化那些可以被反复使用的程序性知识。
我后来在想一个问题:如果你明天入职一家新公司、带一个新团队、做一个新的多模态项目,你手里必须留下的是什么?我的答案是那个飞书文档,和那张只有三个字段的结构化表单。不是模型权重,不是代码仓库,就是那个“文件夹”。因为模型会迭代,代码会重构,但能持续产生优质训练数据的方法,才是长期有价值的东西。
那只橘猫后来怎么样了?
我们用新方法重新标注了它那张图。
标注员填的表单长这样:
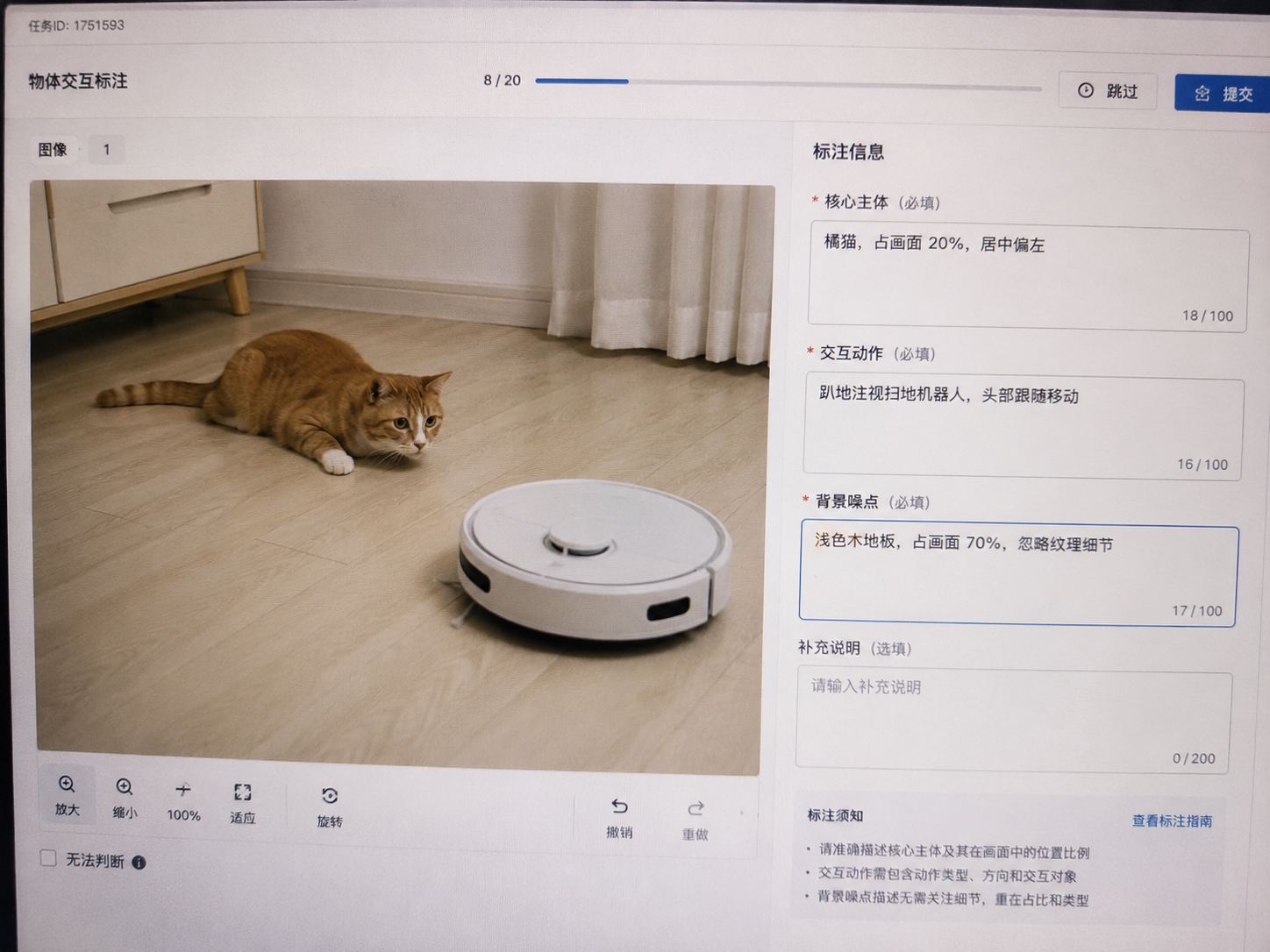
拼接出来的结构化文本不再有“可爱”和“温馨”。它朴实、精确、毫无感情。但就是这样的文本,让模型终于学会了“看猫,不要看地板”。
后来我把这张图单独拿出来做了一次测试。新模型输出:“图里有一只橘色的猫,正趴在地板上看着一个扫地机器人在旁边移动。”准确、完整、没有跑偏。看起来平平无奇的一句话,但我们几个盯着屏幕看了很久。因为三个月前的版本输出的是高档复合地板的板材分析。
多模态赛道上每天都有新模型、新框架、新基准冒出来。大家都在追更大的模型、更多的数据、更强的算力。但我们团队的这段经历让我越来越确认一件事:在相当多的场景里,制约AI能力上限的不是模型架构,不是算力规模,而是你喂进去的数据里藏着多少你自己都没意识到的结构性错误。
如果你手里也有一堆“看起来没问题、但模型表现就是不对劲”的数据,不妨想想这个问题:你给你的AI看的那张图,它看到的,真的是你给它的那张图吗?
也许它看到的只是一块地板而已。
本文由 @L.NaN 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议









那个“背景噪点声明”字段的设计挺聪明。大多数训练只教模型关注什么,很少教它忽略什么,而这个字段直接帮模型做减法。如果能在结构化表单里再加一个“与主体交互的物体”字段,可能对动态场景更有帮助。
砍掉主观形容词的做法虽然见效快,但有点一刀切。识别任务确实需要客观事实,可如果场景里需要模型理解“温馨”“可爱”这类概念,零容忍反而可能限制能力边界。文章自己也在文创场景里吃了亏,说明这套SOP不是万能模板。